
meridian
Meridian cuts through news noise by scraping hundreds of sources, analyzing stories with AI, and delivering concise, personalized daily briefs.
Stars: 513
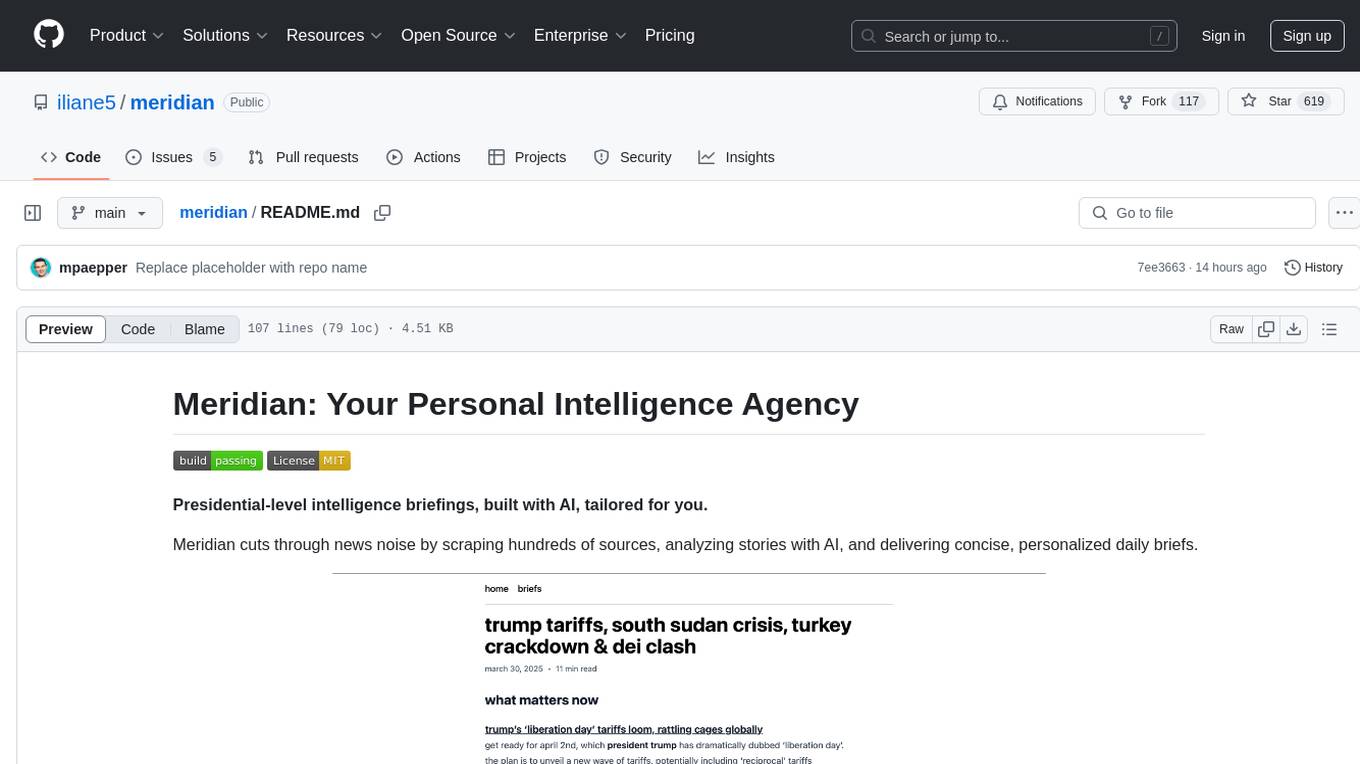
Meridian is a tool that provides personalized daily intelligence briefings by scraping news from hundreds of sources, analyzing stories with AI, and delivering concise briefs. It offers key global events, context, implications analysis, and open-source transparency. Built for the curious who seek in-depth news beyond headlines without spending too much time. The tool uses multi-stage LLM processing for article and cluster analysis, smart clustering techniques to group related articles, and a web interface powered by Nuxt 3. The workflow involves scraping RSS feeds, processing articles with Gemini for relevance, clustering articles, and generating a final brief. The project leverages AI models like Gemini, multilingual embeddings, UMAP, and HDBSCAN for analysis. The tech stack includes Turborepo, Cloudflare services, TypeScript, PostgreSQL, and Nuxt 3 with Vue 3 and Tailwind for the frontend.
README:

Presidential-level intelligence briefings, built with AI, tailored for you.
Meridian cuts through news noise by scraping hundreds of sources, analyzing stories with AI, and delivering concise, personalized daily briefs.

Presidents get tailored daily intelligence briefs. Now with AI, you can too. Meridian delivers:
- Key global events filtered by relevance
- Context and underlying drivers
- Analysis of implications
- Open-source transparency
Built for the curious who want depth beyond headlines without the time sink.
- Source Coverage: Hundreds of diverse news sources
- AI Analysis: Multi-stage LLM processing (Gemini) for article and cluster analysis
- Smart Clustering: Embeddings + UMAP + HDBSCAN to group related articles
- Personalized Briefing: Daily brief with analytical voice and continuity tracking
- Web Interface: Clean Nuxt 3 frontend
graph TD
A[RSS Feed URLs] --> B(Scraper Workflow CF);
B --> C[Article Metadata DB];
C --> D(Article Processor Workflow CF);
D -- Fetches --> E{Content Extraction};
E -- Standard --> F[Direct Fetch];
E -- Complex/Paywall --> G[Browser Rendering API];
F --> H[LLM Article Analysis];
G --> H;
H --> I[Processed Articles DB];
I --> J(Brief Generation Python);
J -- Embeddings --> K[UMAP/HDBSCAN Clustering];
K --> L[LLM Cluster Review];
L --> M[LLM Deep Analysis JSON];
M --> N[Markdown Summary Generation];
O[Previous Day TLDR DB] --> P{Final Briefing LLM};
N --> P;
P --> Q[Final Brief Markdown];
Q --> R[Reports DB];
R --> S(Frontend API CF);
S --> T[Frontend UI Nuxt];- Scraping: Cloudflare Workers fetch RSS feeds, store metadata
- Processing: Extract text, analyze with Gemini for relevance and structure
- Brief Generation: Cluster articles, generate analysis, synthesize final brief
- Frontend: Display briefs via Nuxt/Cloudflare
- Infrastructure: Turborepo, Cloudflare (Workers, Workflows, Pages)
- Backend: Hono, TypeScript, PostgreSQL, Drizzle
- AI/ML: Gemini models, multilingual-e5-small embeddings, UMAP, HDBSCAN
- Frontend: Nuxt 3, Vue 3, Tailwind
Prerequisites: Node.js v22+, pnpm v9.15+, Python 3.10+, PostgreSQL, Cloudflare account, Google AI API key
git clone https://github.com/iliane5/meridian.git
cd meridian
pnpm install
# Configure .env files
pnpm --filter @meridian/database db:migrate
# Deploy via Wrangler, run Python briefing notebook manually- ✅ Core Pipeline: Scraping, processing, analysis working
- ⏳ Top Priority: Automate brief generation (currently manual Python notebook)
⚠️ Monitoring: Improve scraping robustness- 🔜 Future: Add testing, newsletter distribution
This project benefited significantly from AI assistance:
- Claude 3.7 Sonnet: Contributed to early architecture brainstorming, generated browser js scraping scripts, refined prompts, and called me out when I was overthinking or overengineering.
- Gemini 2.5 Pro: Excelled with long-context tasks - comparing outputs across different prompt variants, reviewing the entire codebase before opensourcing, and nailing the analytical tone for briefs
- Gemini 2.0 Flash: The true unsung hero of this project - blazing fast, dirt cheap, and surprisingly capable when prompted well. It's the workhorse that makes running meridian economically viable without sponsors or grants. Essentially free intelligence at scale.
The first two compressed months of dev work into days and made building this way more fun. But Flash isn't just a time-saver—it's the engine that makes Meridian possible at all. No human is reading 2000+ articles daily and analyzing 100+ story clusters. Having AI peers for brainstorming felt like cheating; having AI workers for the actual intelligence pipeline feels like living in the future.
MIT License - See LICENSE file for details.
Built because we live in an age of magic, and we keep forgetting to use it.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for meridian
Similar Open Source Tools
meridian
Meridian is a tool that provides personalized daily intelligence briefings by scraping news from hundreds of sources, analyzing stories with AI, and delivering concise briefs. It offers key global events, context, implications analysis, and open-source transparency. Built for the curious who seek in-depth news beyond headlines without spending too much time. The tool uses multi-stage LLM processing for article and cluster analysis, smart clustering techniques to group related articles, and a web interface powered by Nuxt 3. The workflow involves scraping RSS feeds, processing articles with Gemini for relevance, clustering articles, and generating a final brief. The project leverages AI models like Gemini, multilingual embeddings, UMAP, and HDBSCAN for analysis. The tech stack includes Turborepo, Cloudflare services, TypeScript, PostgreSQL, and Nuxt 3 with Vue 3 and Tailwind for the frontend.

Mira
Mira is an agentic AI library designed for automating company research by gathering information from various sources like company websites, LinkedIn profiles, and Google Search. It utilizes a multi-agent architecture to collect and merge data points into a structured profile with confidence scores and clear source attribution. The core library is framework-agnostic and can be integrated into applications, pipelines, or custom workflows. Mira offers features such as real-time progress events, confidence scoring, company criteria matching, and built-in services for data gathering. The tool is suitable for users looking to streamline company research processes and enhance data collection efficiency.
OpenAnalyst
OpenAnalyst is an open-source VS Code AI agent specialized in data analytics and general coding tasks. It merges features from KiloCode, Roo Code, and Cline, offering code generation from natural language, data analytics mode, self-checking, terminal command running, browser automation, latest AI models, and API keys option. It supports multi-mode operation for roles like Data Analyst, Code, Ask, and Debug. OpenAnalyst is a fork of KiloCode, combining the best features from Cline, Roo Code, and KiloCode, with enhancements like MCP Server Marketplace, automated refactoring, and support for latest AI models.

deepnote
Deepnote is a data notebook tool designed for the AI era, used by over 500,000 data professionals at companies like Estée Lauder, SoundCloud, Statsig, and Gusto. It offers a human-readable format, block-based architecture, reactive notebook execution, and effortless conversion between .ipynb and .deepnote formats. Deepnote extends Jupyter with features like native AI agent, Git integration, cloud compute, and native database & API connections. The repository contains reusable packages and libraries for Deepnote's notebook, runtime, and collaboration features.

ai
Jetify's AI SDK for Go is a unified interface for interacting with multiple AI providers including OpenAI, Anthropic, and more. It addresses the challenges of fragmented ecosystems, vendor lock-in, poor Go developer experience, and complex multi-modal handling by providing a unified interface, Go-first design, production-ready features, multi-modal support, and extensible architecture. The SDK supports language models, embeddings, image generation, multi-provider support, multi-modal inputs, tool calling, and structured outputs.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.
meeting-minutes
An open-source AI assistant for taking meeting notes that captures live meeting audio, transcribes it in real-time, and generates summaries while ensuring user privacy. Perfect for teams to focus on discussions while automatically capturing and organizing meeting content without external servers or complex infrastructure. Features include modern UI, real-time audio capture, speaker diarization, local processing for privacy, and more. The tool also offers a Rust-based implementation for better performance and native integration, with features like live transcription, speaker diarization, and a rich text editor for notes. Future plans include database connection for saving meeting minutes, improving summarization quality, and adding download options for meeting transcriptions and summaries. The backend supports multiple LLM providers through a unified interface, with configurations for Anthropic, Groq, and Ollama models. System architecture includes core components like audio capture service, transcription engine, LLM orchestrator, data services, and API layer. Prerequisites for setup include Node.js, Python, FFmpeg, and Rust. Development guidelines emphasize project structure, testing, documentation, type hints, and ESLint configuration. Contributions are welcome under the MIT License.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.

cleanlab
Cleanlab helps you **clean** data and **lab** els by automatically detecting issues in a ML dataset. To facilitate **machine learning with messy, real-world data** , this data-centric AI package uses your _existing_ models to estimate dataset problems that can be fixed to train even _better_ models.

skypilot
SkyPilot is a framework for running LLMs, AI, and batch jobs on any cloud, offering maximum cost savings, highest GPU availability, and managed execution. SkyPilot abstracts away cloud infra burdens: - Launch jobs & clusters on any cloud - Easy scale-out: queue and run many jobs, automatically managed - Easy access to object stores (S3, GCS, R2) SkyPilot maximizes GPU availability for your jobs: * Provision in all zones/regions/clouds you have access to (the _Sky_), with automatic failover SkyPilot cuts your cloud costs: * Managed Spot: 3-6x cost savings using spot VMs, with auto-recovery from preemptions * Optimizer: 2x cost savings by auto-picking the cheapest VM/zone/region/cloud * Autostop: hands-free cleanup of idle clusters SkyPilot supports your existing GPU, TPU, and CPU workloads, with no code changes.
obsidian-llmsider
LLMSider is an AI assistant plugin for Obsidian that offers flexible multi-model support, deep workflow integration, privacy-first design, and a professional tool ecosystem. It provides comprehensive AI capabilities for personal knowledge management, from intelligent writing assistance to complex task automation, making AI a capable assistant for thinking and creating while ensuring data privacy.
shandu
Shandu is an advanced AI research system that automates comprehensive research processes using language models, web scraping, and iterative exploration to generate well-structured reports with citations. It features intelligent state-based workflow, deep exploration, multi-source information synthesis, enhanced web scraping, smart source evaluation, content analysis pipeline, comprehensive report generation, parallel processing, adaptive search strategy, and full citation management.
memU
MemU is an open-source memory framework designed for AI companions, offering high accuracy, fast retrieval, and cost-effectiveness. It serves as an intelligent 'memory folder' that adapts to various AI companion scenarios. With MemU, users can create AI companions that remember them, learn their preferences, and evolve through interactions. The framework provides advanced retrieval strategies, 24/7 support, and is specialized for AI companions. MemU offers cloud, enterprise, and self-hosting options, with features like memory organization, interconnected knowledge graph, continuous self-improvement, and adaptive forgetting mechanism. It boasts high memory accuracy, fast retrieval, and low cost, making it suitable for building intelligent agents with persistent memory capabilities.
neptune-client
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.
For similar tasks
meridian
Meridian is a tool that provides personalized daily intelligence briefings by scraping news from hundreds of sources, analyzing stories with AI, and delivering concise briefs. It offers key global events, context, implications analysis, and open-source transparency. Built for the curious who seek in-depth news beyond headlines without spending too much time. The tool uses multi-stage LLM processing for article and cluster analysis, smart clustering techniques to group related articles, and a web interface powered by Nuxt 3. The workflow involves scraping RSS feeds, processing articles with Gemini for relevance, clustering articles, and generating a final brief. The project leverages AI models like Gemini, multilingual embeddings, UMAP, and HDBSCAN for analysis. The tech stack includes Turborepo, Cloudflare services, TypeScript, PostgreSQL, and Nuxt 3 with Vue 3 and Tailwind for the frontend.
AIDailyNews
AIDailyNews is a tool that allows users to deploy their personalized daily news overview using GPT3 and Gemini Pro models. It collects content from RSS feeds every morning at 9 am, analyzes and summarizes it using GPT, and generates a daily report. Users can customize the RSS feeds they want to subscribe to and configure data collection environment variables for Github Action scheduled tasks. The tool supports AI services like GLM, OpenAI, and Google Gemini, allowing users to choose the AI provider, GPT model name, API key, and base URL. It also provides instructions for deploying the tool on Vercel for daily content summaries.
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.
awesome-ai-newsletters
Awesome AI Newsletters is a curated list of AI-related newsletters that provide the latest news, trends, tools, and insights in the field of Artificial Intelligence. It includes a variety of newsletters covering general AI news, prompts for marketing and productivity, AI job opportunities, and newsletters tailored for professionals in the AI industry. Whether you are a beginner looking to stay updated on AI advancements or a professional seeking to enhance your knowledge and skills, this repository offers a collection of valuable resources to help you navigate the world of AI.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
For similar jobs

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

SemanticFinder
SemanticFinder is a frontend-only live semantic search tool that calculates embeddings and cosine similarity client-side using transformers.js and SOTA embedding models from Huggingface. It allows users to search through large texts like books with pre-indexed examples, customize search parameters, and offers data privacy by keeping input text in the browser. The tool can be used for basic search tasks, analyzing texts for recurring themes, and has potential integrations with various applications like wikis, chat apps, and personal history search. It also provides options for building browser extensions and future ideas for further enhancements and integrations.

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

Agently-Daily-News-Collector
Agently Daily News Collector is an open-source project showcasing a workflow powered by the Agent ly AI application development framework. It allows users to generate news collections on various topics by inputting the field topic. The AI agents automatically perform the necessary tasks to generate a high-quality news collection saved in a markdown file. Users can edit settings in the YAML file, install Python and required packages, input their topic idea, and wait for the news collection to be generated. The process involves tasks like outlining, searching, summarizing, and preparing column data. The project dependencies include Agently AI Development Framework, duckduckgo-search, BeautifulSoup4, and PyYAM.