
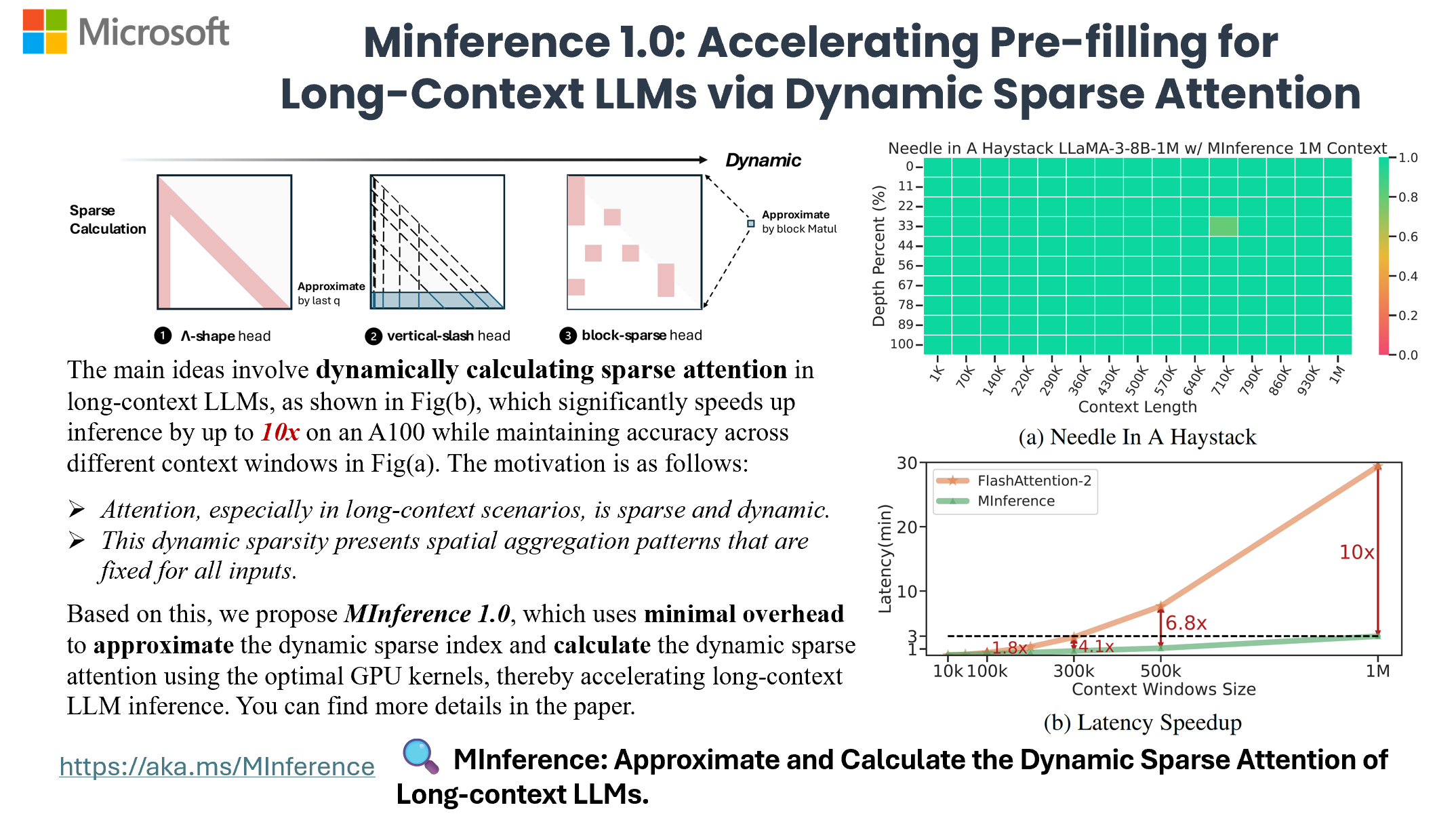
MInference
[NeurIPS'24 Spotlight] To speed up Long-context LLMs' inference, approximate and dynamic sparse calculate the attention, which reduces inference latency by up to 10x for pre-filling on an A100 while maintaining accuracy.
Stars: 853

MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.
README:
![]()
| Project Page | Paper | HF Demo | SCBench |
https://github.com/microsoft/MInference/assets/30883354/52613efc-738f-4081-8367-7123c81d6b19
Now, you can process 1M context 10x faster in a single A100 using Long-context LLMs like LLaMA-3-8B-1M, GLM-4-1M, with even better accuracy, try MInference 1.0 right now!
- 🍩 [24/12/13] We are excited to announce the release of our KV cache-centric analysis work, SCBench, which evaluates long-context methods from a KV cache perspective.
- 🧤 [24/09/26] MInference has been accepted as spotlight at NeurIPS'24. See you in Vancouver!
- 👘 [24/09/16] We are pleased to announce the release of our KV cache offloading work, RetrievalAttention, which accelerates long-context LLM inference via vector retrieval.
- 🥤 [24/07/24] MInference support meta-llama/Meta-Llama-3.1-8B-Instruct now.
- 🪗 [24/07/07] Thanks @AK for sponsoring. You can now use MInference online in the HF Demo with ZeroGPU.
- 📃 [24/07/03] Due to an issue with arXiv, the PDF is currently unavailable there. You can find the paper at this link.
- 🧩 [24/07/03] We will present MInference 1.0 at the Microsoft Booth and ES-FoMo at ICML'24. See you in Vienna!
MInference 1.0 leverages the dynamic sparse nature of LLMs' attention, which exhibits some static patterns, to speed up the pre-filling for long-context LLMs. It first determines offline which sparse pattern each head belongs to, then approximates the sparse index online and dynamically computes attention with the optimal custom kernels. This approach achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy.
-
MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention (NeurIPS'24 spotlight, ES-FoMo @ ICML'24)
Huiqiang Jiang†, Yucheng Li†, Chengruidong Zhang†, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu
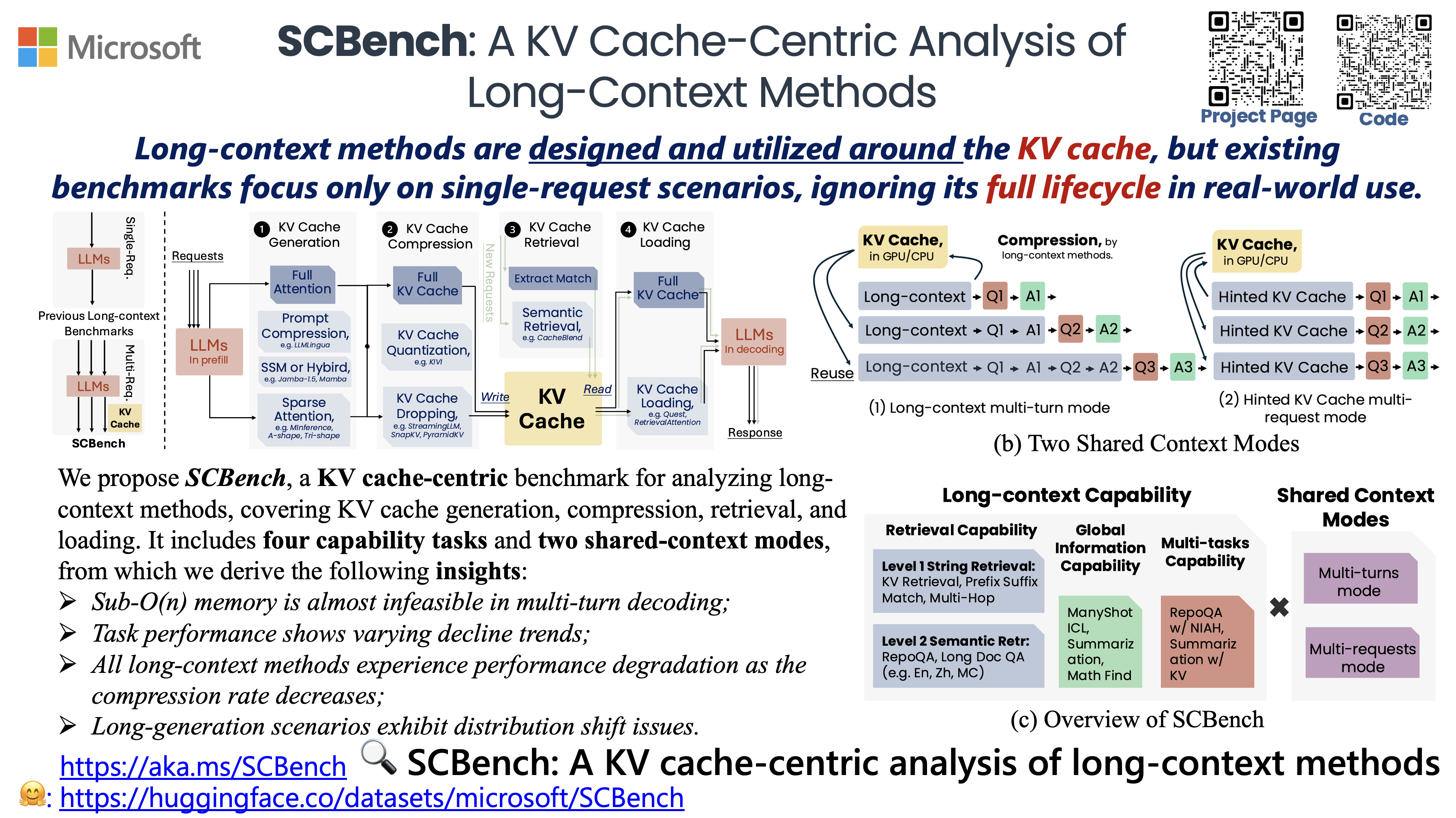
SCBench analyzes long-context methods from a KV cache-centric perspective across the full KV cache lifecycle (e.g., KV cache generation, compression, retrieval, and loading). It evaluates 12 tasks under two shared context modes, covering four categories of long-context capabilities: string retrieval, semantic retrieval, global information, and multi-task scenarios.
-
SCBench: A KV Cache-Centric Analysis of Long-Context Methods (Under Review, ENLSP @ NeurIPS'24)
Yucheng Li, Huiqiang Jiang, Qianhui Wu, Xufang Luo, Surin Ahn, Chengruidong Zhang, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang and Lili Qiu
- Torch
- FlashAttention-2 (Optional)
- Triton
- Transformers >= 4.46.0
To get started with MInference, simply install it using pip:
pip install minferenceYou can get the complete list of supported efficient methods by running the following code:
from minference import MInferenceConfig
supported_attn_types = MInferenceConfig.get_available_attn_types()
supported_kv_types = MInferenceConfig.get_available_kv_types()Currently, we support the following long-context methods:
- [① KV Cache Generation]: MInference, FlexPrefill, A-shape, Tri-shape, MInference w/ static, Dilated, Strided
- [② KV Cache Compression]: StreamingLLM, SnapKV, PyramidKV, KIVI
- [③ KV Cache Retrieval]: CacheBlend
- [④ KV Cache Loading]: Quest, RetrievalAttention
For more details about the KV cache lifecycle, please refer to SCBench. Note that some modes are supported by vLLM, while all modes are supported by HF.
General MInference supports any decoding LLMs, including LLaMA-style models, and Phi models. We have adapted nearly all open-source long-context LLMs available in the market. If your model is not on the supported list, feel free to let us know in the issues, or you can follow the guide to manually generate the sparse heads config.
You can get the complete list of supported LLMs by running:
from minference import get_support_models
get_support_models()Currently, we support the following LLMs:
- LLaMA-3.1: meta-llama/Meta-Llama-3.1-8B-Instruct
- LLaMA-3: gradientai/Llama-3-8B-Instruct-262k, gradientai/Llama-3-8B-Instruct-Gradient-1048k, gradientai/Llama-3-8B-Instruct-Gradient-4194k, gradientai/Llama-3-70B-Instruct-Gradient-262k, gradientai/Llama-3-70B-Instruct-Gradient-1048k
- GLM-4: THUDM/glm-4-9b-chat-1m
- Yi: 01-ai/Yi-9B-200K
- Phi-3: microsoft/Phi-3-mini-128k-instruct
- Qwen2: Qwen/Qwen2-7B-Instruct
for HF,
from transformers import pipeline
+from minference import MInference
pipe = pipeline("text-generation", model=model_name, torch_dtype="auto", device_map="auto")
# Patch MInference Module,
# If you use the local path, please use the model_name from HF when initializing MInference.
+minference_patch = MInference("minference", model_name)
+pipe.model = minference_patch(pipe.model)
pipe(prompt, max_length=10)for vLLM,
For now, please use vllm>=0.4.1
from vllm import LLM, SamplingParams
+ from minference import MInference
llm = LLM(model_name, enforce_eager=True, max_model_len=128_000, enable_chunked_prefill=False)
# Patch MInference Module,
# If you use the local path, please use the model_name from HF when initializing MInference.
+minference_patch = MInference("vllm", model_name)
+llm = minference_patch(llm)
outputs = llm.generate(prompts, sampling_params)for vLLM w/ TP,
- Copy
minference_patch_vllm_tpandminference_patch_vllm_executorfromminference/patch.pyto the end of theWorkerclass invllm/worker/worker.py. Make sure to indentminference_patch_vllm_tp. - When calling VLLM, ensure
enable_chunked_prefill=Falseis set. - Refer to the script in https://github.com/microsoft/MInference/blob/hjiang/support_vllm_tp/experiments/benchmarks/run_e2e_vllm_tp.sh
from vllm import LLM, SamplingParams
+ from minference import MInference
llm = LLM(model_name, enforce_eager=True, max_model_len=128_000, enable_chunked_prefill=False, tensor_parallel_size=2)
# Patch MInference Module,
# If you use the local path, please use the model_name from HF when initializing MInference.
+minference_patch = MInference("vllm", model_name)
+llm = minference_patch(llm)
outputs = llm.generate(prompts, sampling_params)using only the kernel,
from minference import vertical_slash_sparse_attention, block_sparse_attention, streaming_forward
attn_output = vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
attn_output = block_sparse_attention(q, k, v, topk)
attn_output = streaming_forward(q, k, v, init_num, local_window_num)for a local gradio demo

git clone https://huggingface.co/spaces/microsoft/MInference
cd MInference
pip install -r requirments.txt
pip install flash_attn
python app.pyFor more details, please refer to our Examples and Experiments. You can find more information about the dynamic compiler PIT in this paper and on GitHub.
[!Note]
- datasets >= 2.15.0
You can download and load the SCBench data through the Hugging Face datasets (🤗 HF Repo):
from datasets import load_dataset
datasets = ["scbench_kv", "scbench_prefix_suffix", "scbench_vt", "scbench_repoqa", "scbench_qa_eng", "scbench_qa_chn", "scbench_choice_eng", "scbench_many_shot", "scbench_summary", "scbench_mf", "scbench_summary_with_needles", "scbench_repoqa_and_kv"]
for dataset in datasets:
data = load_dataset("microsoft/SCBench", dataset, split="test")All data in SCBench are standardized to the following format:
{
"id": "Random id for each piece of data.",
"context": "The long context required for the task, such as repo-code, long-document, and many-shot.",
"multi_turns": [{"input": "multi-turn question.", "answer": "multi-turn reference answer."}],
}We implement Multi-Turn and Multi-Request modes with HF and vLLM in GreedySearch and GreedySearch_vllm two class. Please refer the follow scripts to run the experiments.
for all methods,
cd scbench
# Single-GPU, in Multi-Turn Mode
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 CUDA_VISIBLE_DEVICES=0 VLLM_WORKER_MULTIPROC_METHOD=spawn bash scripts/run_all_tasks.sh meta-llama/Llama-3.1-8B-Instruct 1 multi-turn
# Multi-GPU, in Multi-Turn Mode
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 CUDA_VISIBLE_DEVICES=0,1 VLLM_WORKER_MULTIPROC_METHOD=spawn bash scripts/run_all_tasks.sh meta-llama/Llama-3.1-8B-Instruct 2 multi-turn
# Multi-GPU, in Multi-Request Mode
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 CUDA_VISIBLE_DEVICES=0,1 VLLM_WORKER_MULTIPROC_METHOD=spawn bash scripts/run_all_tasks.sh meta-llama/Llama-3.1-8B-Instruct 2 scdqfor single methods,
cd scbench
# Single-GPU, in Multi-Turn Mode, using attn_type: vllm, kv_type: dense
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 CUDA_VISIBLE_DEVICES=0 VLLM_WORKER_MULTIPROC_METHOD=spawn bash scripts/run_single_method.sh meta-llama/Llama-3.1-8B-Instruct 1 multi-turn vllm dense
# Multi-GPU, in Multi-Turn Mode, using attn_type: vllm, kv_type: dense
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 CUDA_VISIBLE_DEVICES=0,1 VLLM_WORKER_MULTIPROC_METHOD=spawn bash scripts/run_single_method.sh meta-llama/Llama-3.1-8B-Instruct 2 multi-turn vllm dense
# Multi-GPU, in Multi-Request Mode, using attn_type: vllm, kv_type: dense
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 CUDA_VISIBLE_DEVICES=0,1 VLLM_WORKER_MULTIPROC_METHOD=spawn bash scripts/run_single_method.sh meta-llama/Llama-3.1-8B-Instruct 2 scdq vllm denseMore details about attn_type and kv_type, please refer to this section: Supported Efficient Methods.
For more insights and answers, visit our FAQ section.
Q1: How to effectively evaluate the impact of dynamic sparse attention on the capabilities of long-context LLMs?
To evaluate long-context LLM capabilities using models like LLaMA-3-8B-Instruct-1M and GLM-4-9B-1M, we tested: 1) context window with RULER, 2) general tasks with InfiniteBench, 3) retrieval tasks with Needle in a Haystack, and 4) language model prediction with PG-19.
We found traditional methods perform poorly in retrieval tasks, with difficulty levels as follows: KV retrieval > Needle in a Haystack > Retrieval.Number > Retrieval PassKey. The main challenge is the semantic difference between needles and the haystack. Traditional methods excel when this difference is larger, as in passkey tasks. KV retrieval requires higher retrieval capabilities since any key can be a target, and multi-needle tasks are even more complex.
We will continue to update our results with more models and datasets in future versions.
Q2: Does this dynamic sparse attention pattern only exist in long-context LLMs that are not fully trained?
Firstly, attention is dynamically sparse, a characteristic inherent to the mechanism. We selected state-of-the-art long-context LLMs, GLM-4-9B-1M and LLaMA-3-8B-Instruct-1M, with effective context windows of 64K and 16K. With MInference, these can be extended to 64K and 32K, respectively. We will continue to adapt our method to other advanced long-context LLMs and update our results, as well as explore the theoretical basis for this dynamic sparse attention pattern.
Q3: Does this dynamic sparse attention pattern only exist in Auto-regressive LMs or RoPE based LLMs?
Similar vertical and slash line sparse patterns have been discovered in BERT[1] and multi-modal LLMs[2]. Our analysis of T5's attention patterns, shown in the figure, reveals these patterns persist across different heads, even in bidirectional attention.
[1] SparseBERT: Rethinking the Importance Analysis in Self-Attention, ICML 2021.
[2] LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference, 2024.
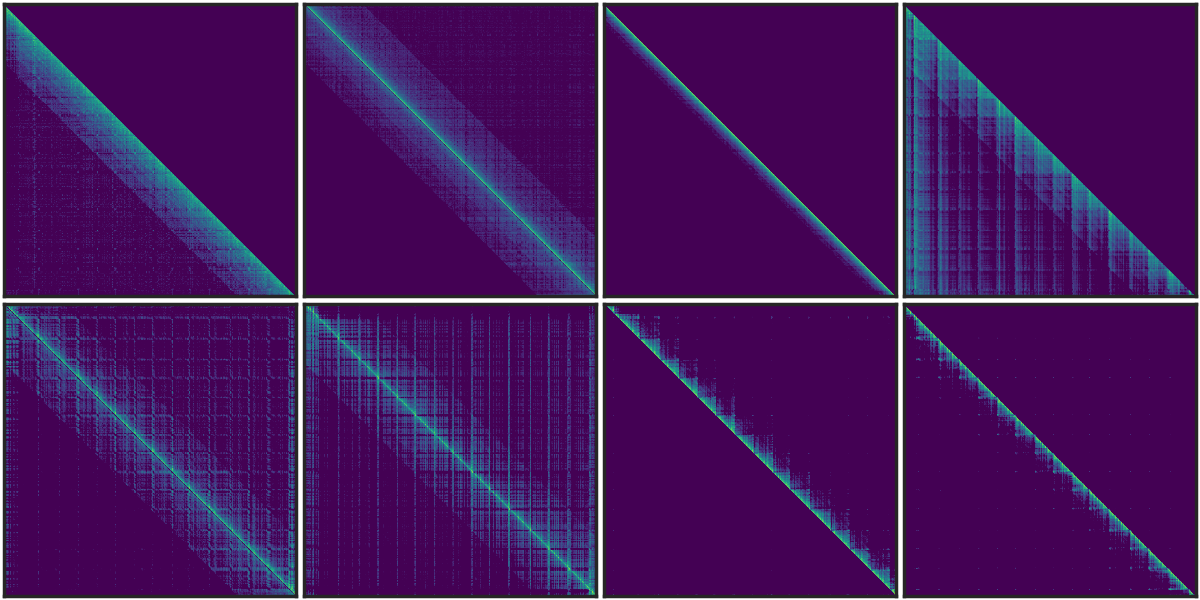
Figure 1. The sparse pattern in T5 Encoder.
Q4: What is the relationship between MInference, SSM, Linear Attention, and Sparse Attention?
All four approaches (MInference, SSM, Linear Attention, and Sparse Attention) efficiently optimize attention complexity in Transformers, each introducing inductive bias differently. The latter three require training from scratch. Recent works like Mamba-2 and Unified Implicit Attention Representation unify SSM and Linear Attention as static sparse attention, with Mamba-2 itself being a block-wise sparse method. While these approaches show potential due to sparse redundancy in attention, static sparse attention may struggle with dynamic semantic associations in complex tasks. In contrast, dynamic sparse attention is better suited for managing these relationships.
If you find MInference useful or relevant to your project and research, please kindly cite our paper:
@article{jiang2024minference,
title={MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention},
author={Jiang, Huiqiang and Li, Yucheng and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Han, Zhenhua and Abdi, Amir H and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili},
journal={arXiv preprint arXiv:2407.02490},
year={2024}
}This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MInference
Similar Open Source Tools
MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

LightAgent
LightAgent is a lightweight, open-source Agentic AI development framework with memory, tools, and a tree of thought. It supports multi-agent collaboration, autonomous learning, tool integration, complex task handling, and multi-model support. It also features a streaming API, tool generator, agent self-learning, adaptive tool mechanism, and more. LightAgent is designed for intelligent customer service, data analysis, automated tools, and educational assistance.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

swiftide
Swiftide is a fast, streaming indexing and query library tailored for Retrieval Augmented Generation (RAG) in AI applications. It is built in Rust, utilizing parallel, asynchronous streams for blazingly fast performance. With Swiftide, users can easily build AI applications from idea to production in just a few lines of code. The tool addresses frustrations around performance, stability, and ease of use encountered while working with Python-based tooling. It offers features like fast streaming indexing pipeline, experimental query pipeline, integrations with various platforms, loaders, transformers, chunkers, embedders, and more. Swiftide aims to provide a platform for data indexing and querying to advance the development of automated Large Language Model (LLM) applications.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

AgentCPM
AgentCPM is a series of open-source LLM agents jointly developed by THUNLP, Renmin University of China, ModelBest, and the OpenBMB community. It addresses challenges faced by agents in real-world applications such as limited long-horizon capability, autonomy, and generalization. The team focuses on building deep research capabilities for agents, releasing AgentCPM-Explore, a deep-search LLM agent, and AgentCPM-Report, a deep-research LLM agent. AgentCPM-Explore is the first open-source agent model with 4B parameters to appear on widely used long-horizon agent benchmarks. AgentCPM-Report is built on the 8B-parameter base model MiniCPM4.1, autonomously generating long-form reports with extreme performance and minimal footprint, designed for high-privacy scenarios with offline and agile local deployment.

FlashRank
FlashRank is an ultra-lite and super-fast Python library designed to add re-ranking capabilities to existing search and retrieval pipelines. It is based on state-of-the-art Language Models (LLMs) and cross-encoders, offering support for pairwise/pointwise rerankers and listwise LLM-based rerankers. The library boasts the tiniest reranking model in the world (~4MB) and runs on CPU without the need for Torch or Transformers. FlashRank is cost-conscious, with a focus on low cost per invocation and smaller package size for efficient serverless deployments. It supports various models like ms-marco-TinyBERT, ms-marco-MiniLM, rank-T5-flan, ms-marco-MultiBERT, and more, with plans for future model additions. The tool is ideal for enhancing search precision and speed in scenarios where lightweight models with competitive performance are preferred.

embodied-agents
Embodied Agents is a toolkit for integrating large multi-modal models into existing robot stacks with just a few lines of code. It provides consistency, reliability, scalability, and is configurable to any observation and action space. The toolkit is designed to reduce complexities involved in setting up inference endpoints, converting between different model formats, and collecting/storing datasets. It aims to facilitate data collection and sharing among roboticists by providing Python-first abstractions that are modular, extensible, and applicable to a wide range of tasks. The toolkit supports asynchronous and remote thread-safe agent execution for maximal responsiveness and scalability, and is compatible with various APIs like HuggingFace Spaces, Datasets, Gymnasium Spaces, Ollama, and OpenAI. It also offers automatic dataset recording and optional uploads to the HuggingFace hub.

chromem-go
chromem-go is an embeddable vector database for Go with a Chroma-like interface and zero third-party dependencies. It enables retrieval augmented generation (RAG) and similar embeddings-based features in Go apps without the need for a separate database. The focus is on simplicity and performance for common use cases, allowing querying of documents with minimal memory allocations. The project is in beta and may introduce breaking changes before v1.0.0.

CogAgent
CogAgent is an advanced intelligent agent model designed for automating operations on graphical interfaces across various computing devices. It supports platforms like Windows, macOS, and Android, enabling users to issue commands, capture device screenshots, and perform automated operations. The model requires a minimum of 29GB of GPU memory for inference at BF16 precision and offers capabilities for executing tasks like sending Christmas greetings and sending emails. Users can interact with the model by providing task descriptions, platform specifications, and desired output formats.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

LongBench
LongBench v2 is a benchmark designed to assess the ability of large language models (LLMs) to handle long-context problems requiring deep understanding and reasoning across various real-world multitasks. It consists of 503 challenging multiple-choice questions with contexts ranging from 8k to 2M words, covering six major task categories. The dataset is collected from nearly 100 highly educated individuals with diverse professional backgrounds and is designed to be challenging even for human experts. The evaluation results highlight the importance of enhanced reasoning ability and scaling inference-time compute to tackle the long-context challenges in LongBench v2.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.

YuE
YuE (乐) is an open-source foundation model designed for music generation, specifically transforming lyrics into full songs. It can generate complete songs in various genres and vocal styles, ensuring a polished and cohesive result. The model requires significant GPU memory for generating long sequences and recommends specific configurations for optimal performance. Users can customize the number of sessions for memory usage. The tool provides a quickstart guide for generating music using Transformers and includes tips for execution time and tag selection. The project is licensed under Creative Commons Attribution Non Commercial 4.0.
For similar tasks
MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.