
awesome-synthetic-datasets
awesome synthetic (text) datasets
Stars: 169
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.
README:
Generating datasets using large language models
Synthetic data refers to artificially generated data that usually aims to mimic real-world data. This data is created algorithmically, often using models or simulations, rather than collected from real-world sources. Synthetic data has been used for a long time in machine learning. Since the advent of LLMs, there has been increasing use of LLMs for producing synthetic data and for using synthetic data for training LLMs.
This repository aims to organize resources focused on helping people (including myself) get started with building synthetic datasets. As a result, it will only cover some things and will focus on pragmatic and practical resources for the most part.
- Synthetic data: save money, time and carbon with open source: shows how to use an open-source LLM to create synthetic data to train your customized model in a few steps.
TinyStories, a synthetic dataset of short stories that only contain words that a typical 3 to 4-year-olds usually understand, generated by GPT-3.5 and GPT-4. We show that TinyStories can be used to train and evaluate LMs that are much smaller than the state-of-the-art models (below 10 million total parameters), or have much simpler architectures (with only one transformer block), yet still produce fluent and consistent stories with several paragraphs that are diverse and have almost perfect grammar, and demonstrate reasoning capabilities.
The Open Hermes 2.5 dataset is a continuation of the Open Hermes 1 dataset, at a much larger scale, much more diverse, and much higher quality compilation, reaching 1M, primarily synthetically generated instruction and chat samples.
Cosmopedia is a dataset of synthetic textbooks, blogposts, stories, posts and WikiHow articles generated by Mixtral-8x7B-Instruct-v0.1.The dataset contains over 30 million files and 25 billion tokens, making it the largest open synthetic dataset to date.
A reproduction of Textbooks Are All You Need. More detail in this blog post
WebSight is a large synthetic dataset containing HTML/CSS codes representing synthetically generated English websites, each accompanied by a corresponding screenshot.
More details in this blog post.
gretelai/synthetic_text_to_sql is a rich dataset of high quality synthetic Text-to-SQL samples, designed and generated using Gretel Navigator, and released under Apache 2.0. Please see our release blogpost for more details.
A dataset of 60,000 generated function-calling examples across 21 categories and 3,673 APIs.
This list isn't compressive and tries to focus on either actively developed libraries or libraries/code examples that demonstrate a particular approach well.
⚗️ distilabel is a framework for synthetic data and AI feedback for AI engineers that require high-quality outputs, full data ownership, and overall efficiency.
This is a very flexible library that is actively being developed and improved. It supports a large number of LLM providers. It includes many common synthetic data generation techniques from papers such as Self-Instruct and EvolInstruct.
Manage scalable open LLM inference endpoints in Slurm clusters
This library is primarily focused on scaling synthetic text generation using Slurm clusters. This library was used to generate Cosmopedia
This is a project to bootstrap the creation of domain-specific datasets for training models. The goal is to create a set of tools that help users to collaborate with domain experts. Includes a UI tool for creating a pipeline for generating a synthetic dataset focused on a particular domain.
A framework for prompt tuning using Intent-based Prompt Calibration
This framework aims to help you automatically generate high-quality, detailed prompts. It uses a refinement process, where it iteratively builds a dataset of challenging edge cases and optimizes the prompt accordingly. This approach aims to reduce the manual effort in prompt engineering and reduce prompt sensitivity.
Self-Contrast is an innovative method that offers an annotation-free approach for aligning with human preference.
This is the code accompanying the Starling team's paper "Extensive Self-Contrast Enables Feedback-Free Language Model Alignment". The "Nectar" synthetic dataset is used to train a reward model, which is then used to train a large language model by Reinforcement Learning with AI Feedback (RLAIF).
Some important papers about synthetic data generation. Note I'm not trying to add every possible paper on the topic, but rather focus on those that introduced important techniques or had a big impact (particularly "in the wild"). I am collecting a longer list of papers in this Hugging Face Collection.
- Textbooks Are All You Need
- TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
- Self-Instruct: Aligning Language Model with Self Generated Instructions
- WizardLM: Empowering Large Language Models to Follow Complex Instructions (Also check out the other Wizard papers i.e. WizardCoder: Empowering Code Large Language Models with Evol-Instruct).
- Improving Text Embeddings with Large Language Models
- Extensive Self-Contrast Enables Feedback-Free Language Model Alignment (From the Starling team).
- Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-synthetic-datasets
Similar Open Source Tools
awesome-synthetic-datasets
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.

ManipVQA
ManipVQA is a framework that enhances Multimodal Large Language Models (MLLMs) with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. It addresses the deficiency of conventional MLLMs in understanding affordances and physical concepts crucial for manipulation tasks. By infusing robotics-specific knowledge, including tool detection, affordance recognition, and physical concept comprehension, ManipVQA improves the performance of robots in manipulation tasks. The framework involves fine-tuning MLLMs with a curated dataset of interactive objects, enabling robots to understand and execute natural language instructions more effectively.

raft
RAFT (Retrieval-Augmented Fine-Tuning) is a method for creating conversational agents that realistically emulate specific human targets. It involves a dual-phase process of fine-tuning and retrieval-based augmentation to generate nuanced and personalized dialogue. The tool is designed to combine interview transcripts with memories from past writings to enhance language model responses. RAFT has the potential to advance the field of personalized, context-sensitive conversational agents.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.
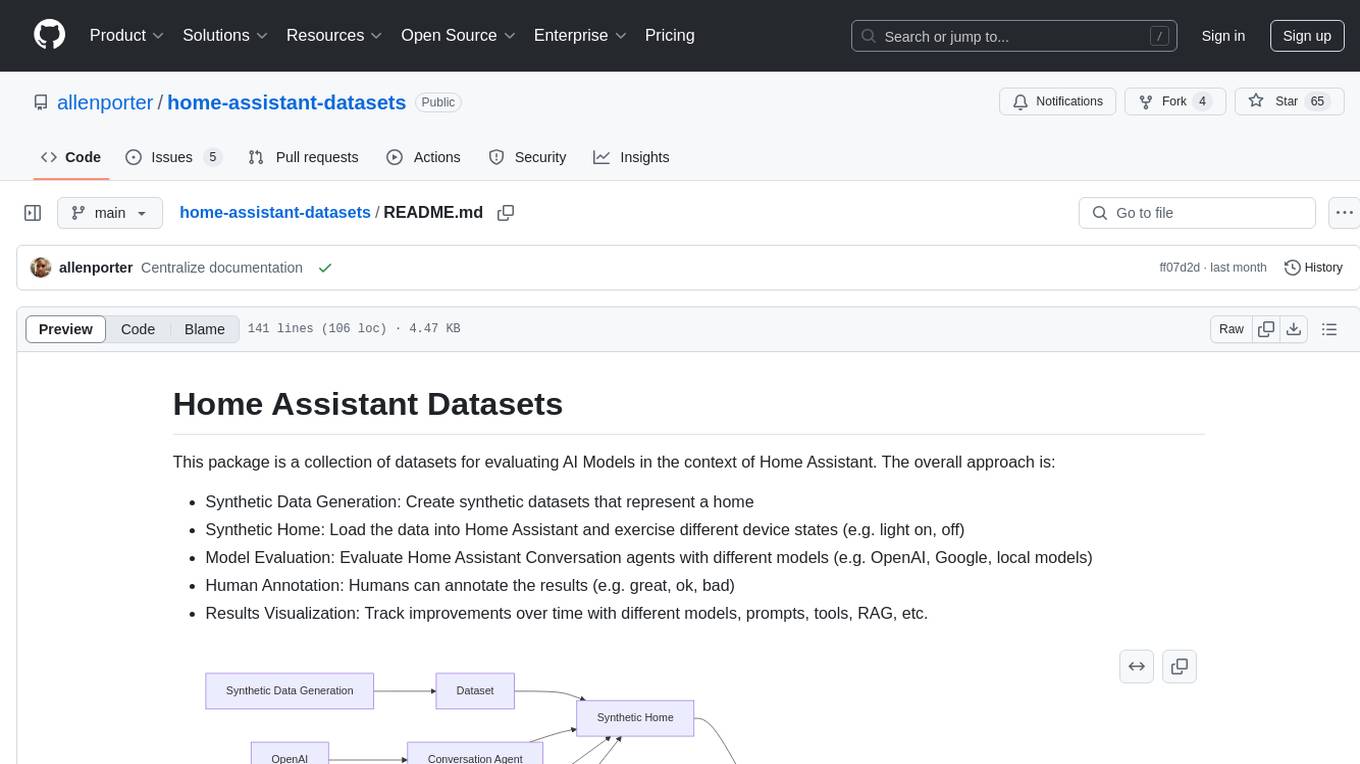
home-assistant-datasets
This package provides a collection of datasets for evaluating AI Models in the context of Home Assistant. It includes synthetic data generation, loading data into Home Assistant, model evaluation with different conversation agents, human annotation of results, and visualization of improvements over time. The datasets cover home descriptions, area descriptions, device descriptions, and summaries that can be performed on a home. The tool aims to build datasets for future training purposes.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.

Chinese-Tiny-LLM
Chinese-Tiny-LLM is a repository containing procedures for cleaning Chinese web corpora and pre-training code. It introduces CT-LLM, a 2B parameter language model focused on the Chinese language. The model primarily uses Chinese data from a 1,200 billion token corpus, showing excellent performance in Chinese language tasks. The repository includes tools for filtering, deduplication, and pre-training, aiming to encourage further research and innovation in language model development.

Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
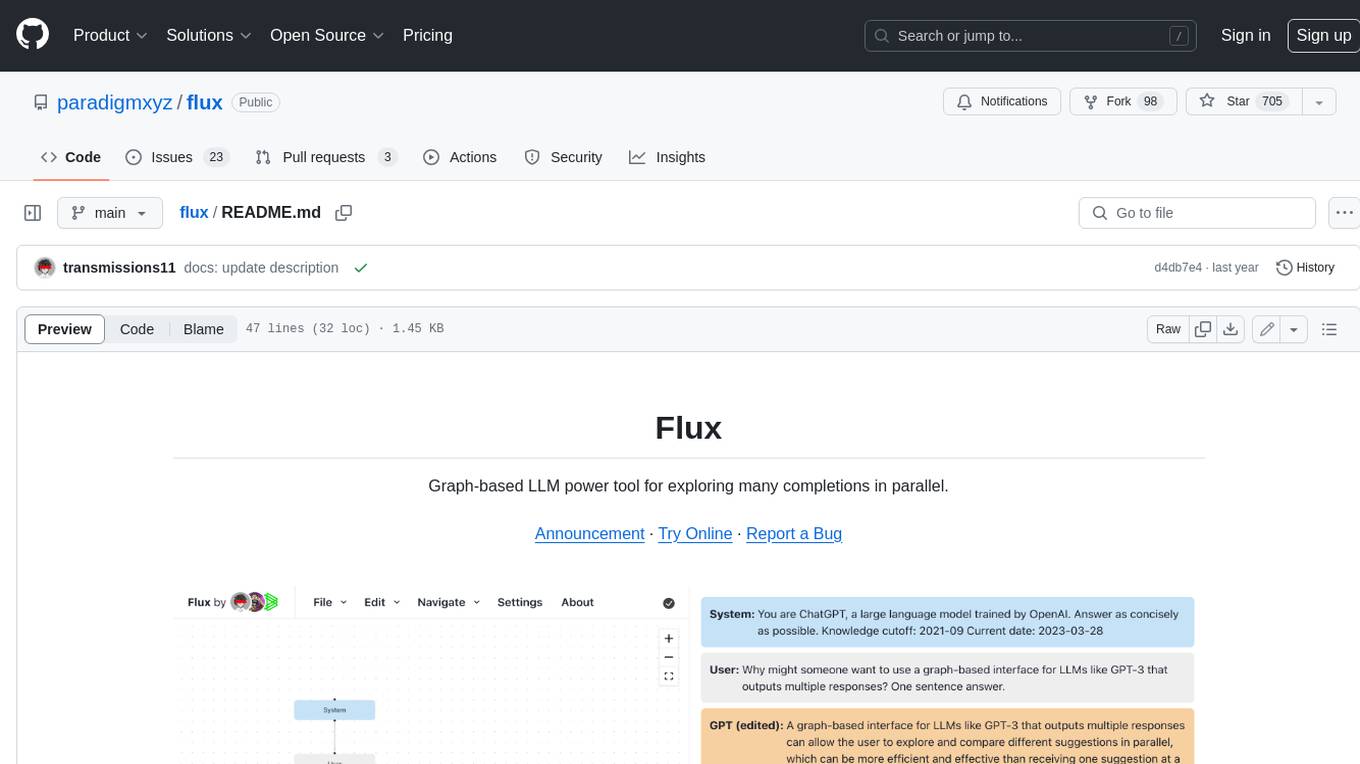
flux
Flux is a powerful tool for interacting with large language models (LLMs) that generates multiple completions per prompt in a tree structure and lets you explore the best ones in parallel. Flux's tree structure allows you to get a wider variety of creative responses, test out different prompts with the same shared context, and use inconsistencies to identify where the model is uncertain. It also provides a robust set of keyboard shortcuts, allows setting the system message and editing GPT messages, autosaves to local storage, uses the OpenAI API directly, and is 100% open source and MIT licensed.
suql
SUQL (Structured and Unstructured Query Language) is a tool that augments SQL with free text primitives for building chatbots that can interact with relational data sources containing both structured and unstructured information. It seamlessly integrates retrieval models, large language models (LLMs), and traditional SQL to provide a clean interface for hybrid data access. SUQL supports optimizations to minimize expensive LLM calls, scalability to large databases with PostgreSQL, and general SQL operations like JOINs and GROUP BYs.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.
HybridAGI
HybridAGI is the first Programmable LLM-based Autonomous Agent that lets you program its behavior using a **graph-based prompt programming** approach. This state-of-the-art feature allows the AGI to efficiently use any tool while controlling the long-term behavior of the agent. Become the _first Prompt Programmers in history_ ; be a part of the AI revolution one node at a time! **Disclaimer: We are currently in the process of upgrading the codebase to integrate DSPy**

GrAIdient
GrAIdient is a framework designed to enable the development of deep learning models using the internal GPU of a Mac. It provides access to the graph of layers, allowing for unique model design with greater understanding, control, and reproducibility. The goal is to challenge the understanding of deep learning models, transitioning from black box to white box models. Key features include direct access to layers, native Mac GPU support, Swift language implementation, gradient checking, PyTorch interoperability, and more. The documentation covers main concepts, architecture, and examples. GrAIdient is MIT licensed.
For similar tasks
awesome-synthetic-datasets
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.
For similar jobs
Detection-and-Classification-of-Alzheimers-Disease
This tool is designed to detect and classify Alzheimer's Disease using Deep Learning and Machine Learning algorithms on an early basis, which is further optimized using the Crow Search Algorithm (CSA). Alzheimer's is a fatal disease, and early detection is crucial for patients to predetermine their condition and prevent its progression. By analyzing MRI scanned images using Artificial Intelligence technology, this tool can classify patients who may or may not develop AD in the future. The CSA algorithm, combined with ML algorithms, has proven to be the most effective approach for this purpose.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.
awesome-synthetic-datasets
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.
ROSGPT_Vision
ROSGPT_Vision is a new robotic framework designed to command robots using only two prompts: a Visual Prompt for visual semantic features and an LLM Prompt to regulate robotic reactions. It is based on the Prompting Robotic Modalities (PRM) design pattern and is used to develop CarMate, a robotic application for monitoring driver distractions and providing real-time vocal notifications. The framework leverages state-of-the-art language models to facilitate advanced reasoning about image data and offers a unified platform for robots to perceive, interpret, and interact with visual data through natural language. LangChain is used for easy customization of prompts, and the implementation includes the CarMate application for driver monitoring and assistance.
AIBotPublic
AIBotPublic is an open-source version of AIBotPro, a comprehensive AI tool that provides various features such as knowledge base construction, AI drawing, API hosting, and more. It supports custom plugins and parallel processing of multiple files. The tool is built using bootstrap4 for the frontend, .NET6.0 for the backend, and utilizes technologies like SqlServer, Redis, and Milvus for database and vector database functionalities. It integrates third-party dependencies like Baidu AI OCR, Milvus C# SDK, Google Search, and more to enhance its capabilities.

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.
MetaAgent
MetaAgent is a multi-agent collaboration platform designed to build, manage, and deploy multi-modal AI agents without the need for coding. Users can easily create AI agents by editing a yml file or using the provided UI. The platform supports features such as building LLM-based AI agents, multi-modal interactions with users using texts, audios, images, and videos, creating a company of agents for complex tasks like drawing comics, vector database and knowledge embeddings, and upcoming features like UI for creating and using AI agents, fine-tuning, and RLHF. The tool simplifies the process of creating and deploying AI agents for various tasks.