
home-assistant-datasets
This package is a collection of datasets for evaluating AI Models in the context of Home Assistant.
Stars: 182
This package provides a collection of datasets for evaluating AI Models in the context of Home Assistant. It includes synthetic data generation, loading data into Home Assistant, model evaluation with different conversation agents, human annotation of results, and visualization of improvements over time. The datasets cover home descriptions, area descriptions, device descriptions, and summaries that can be performed on a home. The tool aims to build datasets for future training purposes.
README:
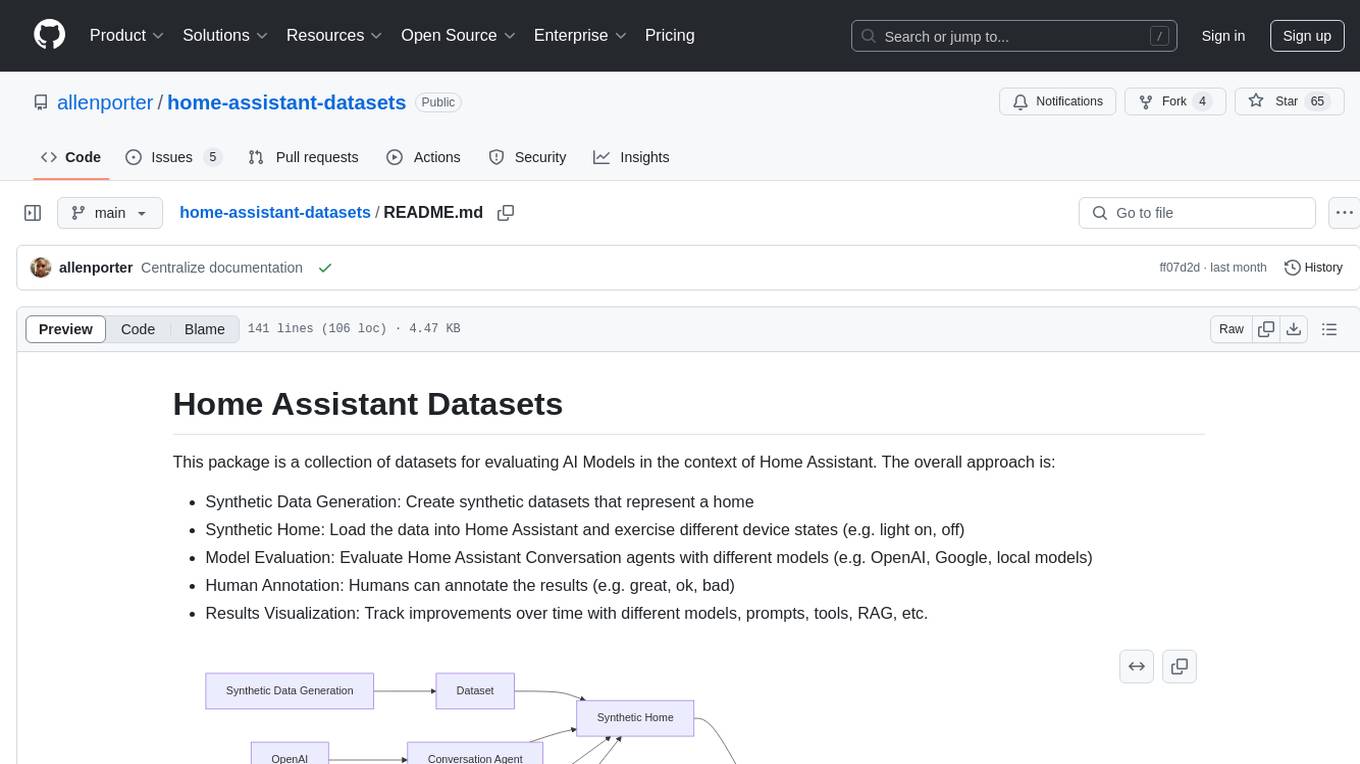
This package is a collection of datasets for evaluating AI Models in the context of Home Assistant. The overall approach is:
- Synthetic Data Generation: Create synthetic datasets that represent a home
- Synthetic Home: Load the data into Home Assistant and exercise different device states (e.g. light on, off)
- Collect Model Outputs: Run the datasets with Home Assistant Conversation agents with different models (e.g. OpenAI, Google, local models) to generate model outputs (e.g. tool calls, responses)
- Evaluate Results: Evaluate the model outsputs with the groundtruth (e.g. is the action correct), or humans can annotate the results (e.g. great, ok, bad)
- Visualize Results: Track improvements over time with different models, prompts, tools, RAG, etc.
graph LR;
A[Synthetic Data Generation]
B[Dataset]
C[Collect Model Outputs]
D[Synthetic Home]
F[Evaluate Results]
G[Visualize Results]
H[OpenAI]
I[Conversation Agent]
J[Local LM]
K[Conversation Agent]
L[Google]
M[Conversation Agent]
A --> B
B --> D
D --> C
C --> F
F --> G
H --> I
J --> K
L --> M
I --> C
K --> C
M --> C
I --> D
K --> D
M --> DSee the datasets README for details on the available datasets including Home descriptions, Area descriptions, Device descriptions and summaries that can be performed on a home.
The device level datasets are defined using the Synthetic Home format including its device registry of synthetic devices.
See the generation README for more details on how synthetic data generation using LLMs works. The data is generated from a small amount of seed example data and a prompt, then is persisted.
The synthetic data generation is run with Jupyter notebooks.
classDiagram
direction LR
Home <|-- Area
Area <|-- Device
Device <|-- EntityStates
class Home{
+String name
+String country_code
+String location
+String type
}
class Area {
+String name
}
class Device {
+String name
+String device_type
+String model
+String mfg
+String sw_version
}
class EntityState {
+String state
}
You can use the generated synthetic data in Home Assistat and with integrated conversation agents to produce outputs for evaluation.
Model evaluation is currently performed with pytest, Synthetic Home, and any conversation agent (Open AI, Google, custom components, etc)
See [docs/eval.md] for instructions on how run an evaluation and update the leaderboard.
The most commonly used evaluation is for the Home Assistant conversation agent actions for integrating with the assist pipeline. See the following dataset directories for more information on running an evaluation:
- datasets/assist - Dataset with a set of corner cases meant to challenge models on voice actions, but with a medium size home.
- datasets/assist-mini - A much simpler dataset set of tasks for smaller models using very limited number of entities.
- datasets/intents - A dataset based on the home assistant intents repository unit tests that are used for the NLP model. These have a very large home.
Models are configured in models/.
We have an experimental dataset for zero show blueprint and automation creation, set up in a similar in style to a Software Engineer Benchmark. Each record contains a README with a description of the problem and expected results and a test eval that loads the blueprints generated by a model and exercises to verify if the solution is correct. See the dataset directory for more information:
- datasets/automations - Dataset for blueprint and automation creation.
There are additional datasets for human evaluation of summarization tasks. These were the initial use case for this repo. It works something like this:
- Configure the Synthetic Home and devices
- Configure the conversation agent and prompt ("summarize this area")
- Ask the conversation agent to summarize:
- Each area of the home
- For each interesting device state in the area (e.g. lights on, lights off)
- Record the results
These can be used for human evaluation to determine the model quality. In this phase, we take the model outputs from a human rater and use them for evaluation.
Human rater (me) scores the result quality:
- 1: Low: Bad, incorrect, misleading, etc.
- 2: Medium: Solid, not incorrect, though perhaps a missed opportunity
- 3: High: Good
See the script/ directory for more details on preparing the data for human eval procedure using Doccano.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for home-assistant-datasets
Similar Open Source Tools
home-assistant-datasets
This package provides a collection of datasets for evaluating AI Models in the context of Home Assistant. It includes synthetic data generation, loading data into Home Assistant, model evaluation with different conversation agents, human annotation of results, and visualization of improvements over time. The datasets cover home descriptions, area descriptions, device descriptions, and summaries that can be performed on a home. The tool aims to build datasets for future training purposes.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
LLMs-World-Models-for-Planning
This repository provides a Python implementation of a method that leverages pre-trained large language models to construct and utilize world models for model-based task planning. It includes scripts to generate domain models using natural language descriptions, correct domain models based on feedback, and support plan generation for tasks in different domains. The code has been refactored for better readability and includes tools for validating PDDL syntax and handling corrective feedback.
intelligence-toolkit
The Intelligence Toolkit is a suite of interactive workflows designed to help domain experts make sense of real-world data by identifying patterns, themes, relationships, and risks within complex datasets. It utilizes generative AI (GPT models) to create reports on findings of interest. The toolkit supports analysis of case, entity, and text data, providing various interactive workflows for different intelligence tasks. Users are expected to evaluate the quality of data insights and AI interpretations before taking action. The system is designed for moderate-sized datasets and responsible use of personal case data. It uses the GPT-4 model from OpenAI or Azure OpenAI APIs for generating reports and insights.

kdbai-samples
KDB.AI is a time-based vector database that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. It supports multiple index types, distance metrics, top-N and metadata filtered retrieval, as well as Python and REST interfaces. The repository contains samples demonstrating various use-cases such as temporal similarity search, document search, image search, recommendation systems, sentiment analysis, and more. KDB.AI integrates with platforms like ChatGPT, Langchain, and LlamaIndex. The setup steps require Unix terminal, Python 3.8+, and pip installed. Users can install necessary Python packages and run Jupyter notebooks to interact with the samples.
AgroTech-AI
AgroTech AI platform is a comprehensive web-based tool where users can access various machine learning models for making accurate predictions related to agriculture. It offers solutions for crop management, soil health assessment, pest control, and more. The platform implements machine learning algorithms to provide functionalities like fertilizer prediction, crop prediction, soil quality prediction, yield prediction, and mushroom edibility prediction.

ollama-grid-search
A Rust based tool to evaluate LLM models, prompts and model params. It automates the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results. The tool assumes the user has Ollama installed and serving endpoints, either in `localhost` or in a remote server. Key features include: * Automatically fetches models from local or remote Ollama servers * Iterates over different models and params to generate inferences * A/B test prompts on different models simultaneously * Allows multiple iterations for each combination of parameters * Makes synchronous inference calls to avoid spamming servers * Optionally outputs inference parameters and response metadata (inference time, tokens and tokens/s) * Refetching of individual inference calls * Model selection can be filtered by name * List experiments which can be downloaded in JSON format * Configurable inference timeout * Custom default parameters and system prompts can be defined in settings

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

eureka-ml-insights
The Eureka ML Insights Framework is a repository containing code designed to help researchers and practitioners run reproducible evaluations of generative models efficiently. Users can define custom pipelines for data processing, inference, and evaluation, as well as utilize pre-defined evaluation pipelines for key benchmarks. The framework provides a structured approach to conducting experiments and analyzing model performance across various tasks and modalities.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.

PromptAgent
PromptAgent is a repository for a novel automatic prompt optimization method that crafts expert-level prompts using language models. It provides a principled framework for prompt optimization by unifying prompt sampling and rewarding using MCTS algorithm. The tool supports different models like openai, palm, and huggingface models. Users can run PromptAgent to optimize prompts for specific tasks by strategically sampling model errors, generating error feedbacks, simulating future rewards, and searching for high-reward paths leading to expert prompts.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.

aligner
Aligner is a model-agnostic alignment tool designed to efficiently correct responses from large language models. It redistributes initial answers to align with human intentions, improving performance across various LLMs. The tool can be applied with minimal training, enhancing upstream models and reducing hallucination. Aligner's 'copy and correct' method preserves the base structure while enhancing responses. It achieves significant performance improvements in helpfulness, harmlessness, and honesty dimensions, with notable success in boosting Win Rates on evaluation leaderboards.

LLMonFHIR
LLMonFHIR is an iOS application that utilizes large language models (LLMs) to interpret and provide context around patient data in the Fast Healthcare Interoperability Resources (FHIR) format. It connects to the OpenAI GPT API to analyze FHIR resources, supports multiple languages, and allows users to interact with their health data stored in the Apple Health app. The app aims to simplify complex health records, provide insights, and facilitate deeper understanding through a conversational interface. However, it is an experimental app for informational purposes only and should not be used as a substitute for professional medical advice. Users are advised to verify information provided by AI models and consult healthcare professionals for personalized advice.
For similar tasks
home-assistant-datasets
This package provides a collection of datasets for evaluating AI Models in the context of Home Assistant. It includes synthetic data generation, loading data into Home Assistant, model evaluation with different conversation agents, human annotation of results, and visualization of improvements over time. The datasets cover home descriptions, area descriptions, device descriptions, and summaries that can be performed on a home. The tool aims to build datasets for future training purposes.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.
For similar jobs

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.
AlignBench
AlignBench is the first comprehensive evaluation benchmark for assessing the alignment level of Chinese large models across multiple dimensions. It includes introduction information, data, and code related to AlignBench. The benchmark aims to evaluate the alignment performance of Chinese large language models through a multi-dimensional and rule-calibrated evaluation method, enhancing reliability and interpretability.

LiveBench
LiveBench is a benchmark tool designed for Language Model Models (LLMs) with a focus on limiting contamination through monthly new questions based on recent datasets, arXiv papers, news articles, and IMDb movie synopses. It provides verifiable, objective ground-truth answers for accurate scoring without an LLM judge. The tool offers 18 diverse tasks across 6 categories and promises to release more challenging tasks over time. LiveBench is built on FastChat's llm_judge module and incorporates code from LiveCodeBench and IFEval.

evalchemy
Evalchemy is a unified and easy-to-use toolkit for evaluating language models, focusing on post-trained models. It integrates multiple existing benchmarks such as RepoBench, AlpacaEval, and ZeroEval. Key features include unified installation, parallel evaluation, simplified usage, and results management. Users can run various benchmarks with a consistent command-line interface and track results locally or integrate with a database for systematic tracking and leaderboard submission.
home-assistant-datasets
This package provides a collection of datasets for evaluating AI Models in the context of Home Assistant. It includes synthetic data generation, loading data into Home Assistant, model evaluation with different conversation agents, human annotation of results, and visualization of improvements over time. The datasets cover home descriptions, area descriptions, device descriptions, and summaries that can be performed on a home. The tool aims to build datasets for future training purposes.
Evaluator
NeMo Evaluator SDK is an open-source platform for robust, reproducible, and scalable evaluation of Large Language Models. It enables running hundreds of benchmarks across popular evaluation harnesses against any OpenAI-compatible model API. The platform ensures auditable and trustworthy results by executing evaluations in open-source Docker containers. NeMo Evaluator SDK is built on four core principles: Reproducibility by Default, Scale Anywhere, State-of-the-Art Benchmarking, and Extensible and Customizable.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.