
llm-self-correction-papers
List of papers on Self-Correction of LLMs.
Stars: 69

This repository contains a curated list of papers focusing on the self-correction of large language models (LLMs) during inference. It covers various frameworks for self-correction, including intrinsic self-correction, self-correction with external tools, self-correction with information retrieval, and self-correction with training designed specifically for self-correction. The list includes survey papers, negative results, and frameworks utilizing reinforcement learning and OpenAI o1-like approaches. Contributions are welcome through pull requests following a specific format.
README:
This repository contains a list of papers on self-correction of large language models (LLMs).
The list is maintained by Ryo Kamoi. If you have any suggestions or corrections, please feel free to open an issue or a pull request (refer to Contributing for details).
This list is based on our survey paper. If you find this list useful, please consider citing our paper:
@article{kamoi2024self-correction,
author = {Kamoi, Ryo and Zhang, Yusen and Zhang, Nan and Han, Jiawei and Zhang, Rui},
title = "{When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs}",
journal = {Transactions of the Association for Computational Linguistics},
volume = {12},
pages = {1417-1440},
year = {2024},
month = {11},
issn = {2307-387X},
doi = {10.1162/tacl_a_00713},
url = {https://doi.org/10.1162/tacl\_a\_00713},
eprint = {https://direct.mit.edu/tacl/article-pdf/doi/10.1162/tacl\_a\_00713/2478635/tacl\_a\_00713.pdf},
}Self-correction of LLMs is a framework that refines responses from LLMs using LLMs during inference. Previous work has proposed various frameworks for self-correction, such as using external tools or information, or training LLMs specifically for self-correction.

In this repository, we focus on inference-time self-correction, and differentiate it from training-time self-improvement of LLMs, which uses their own responses for improving themselves only during training.
We also do not cover generate-and-rank (or sample-and-rank), which generate multiple responses and rank them using LLMs or other models. In contrast, self-correction refines their own responses, not only selecting the best one from multiple responses.
- Survey Papers of Self-Correction
- Intrinsic Self-Correction
- Self-Correction with External Tools
- Self-Correction with Information Retrieval
- Self-Correction with Training Designed for Self-Correction
- Self-Correction of Vision Language Models
- Contributing
- License
- Automatically Correcting Large Language Models: Surveying the Landscape of Diverse Automated Correction Strategies. Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, and William Yang Wang. TACL. 2024. [paper] [paper list]
- When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs. Ryo Kamoi, Yusen Zhang, Nan Zhang, Jiawei Han, and Rui Zhang. TACL. 2024. [paper]
- A Survey on LLM Inference-Time Self-Improvement. Xiangjue Dong, Maria Teleki, James Caverlee. Preprint. 2024. [paper]
Intrinsic self-correction is a framework that refines responses from LLMs using the same LLMs without using external feedback or training designed for self-correction.
- Constitutional AI: Harmlessness from AI Feedback. Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosuite, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas Schiefer, Noemi Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, and Jared Kaplan. Preprint. 2022. [paper]
- [Self-Refine] Self-Refine: Iterative Refinement with Self-Feedback. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. NeurIPS. 2023. [paper]
- [CoVe] Chain-of-Verification Reduces Hallucination in Large Language Models. Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. Preprint. 2023. [paper]
- [RCI] Language Models can Solve Computer Tasks. Geunwoo Kim, Pierre Baldi, and Stephen McAleer. Preprint. 2023. [paper]
- [Reflexion] Reflexion: language agents with verbal reinforcement learning. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. NeurIPS. 2023. [paper]
It has been reported that intrinsic self-correction does not work well in many tasks.
- Large Language Models Cannot Self-Correct Reasoning Yet. Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. ICLR. 2024. [paper]
- [CRITIC] CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing. Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. ICLR. 2024. [paper]
- When is Tree Search Useful for LLM Planning? It Depends on the Discriminator. Ziru Chen, Michael White, Raymond Mooney, Ali Payani, Yu Su, and Huan Sun. ACL. 2024. [paper] [code]
Previous work has proposed self-correction frameworks that use external tools, such as code executors for code generation tasks and proof assistants for theorem proving tasks.
- [Reflexion] Reflexion: language agents with verbal reinforcement learning. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. NeurIPS. 2023. [paper]
- [SelfEvolve] SelfEvolve: A Code Evolution Framework via Large Language Models. Shuyang Jiang, Yuhao Wang, and Yu Wang. Preprint. 2023. [paper]
- [Logic-LM] Logic-LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning. Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. Findings of EMNLP. 2023. [paper]
- [Self-Debug] Teaching Large Language Models to Self-Debug. Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. ICLR. 2024. [paper]
- [CRITIC] CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing. Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. ICLR. 2024. [paper]
- [CodeRL] CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning. Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. NeurIPS. 2022. [paper]
- [Self-Edit] Self-Edit: Fault-Aware Code Editor for Code Generation. Kechi Zhang, Zhuo Li, Jia Li, Ge Li, and Zhi Jin. ACL. 2023. [paper]
- [Baldur] Baldur: Whole-Proof Generation and Repair with Large Language Models. Emily First, Markus Rabe, Talia Ringer, and Yuriy Brun. ESEC/FSE. 2023. [paper]
Previous work has proposed self-correction frameworks that use information retrieval during inference.
- [RARR] RARR: Researching and Revising What Language Models Say, Using Language Models. Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, and Kelvin Guu. ACL. 2023. [paper]
- [Verify-and-Edit] Verify-and-Edit: A Knowledge-Enhanced Chain-of-Thought Framework. Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, and Lidong Bing. ACL. 2023. [paper]
- A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation. Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu. Preprint. 2023. [paper]
- Improving Language Models via Plug-and-Play Retrieval Feedback. Wenhao Yu, Zhihan Zhang, Zhenwen Liang, Meng Jiang, and Ashish Sabharwal. Preprint. 2023. [paper]
- [CRITIC] CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing. Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. ICLR. 2024. [paper]
- [FLARE] Active Retrieval Augmented Generation. Zhengbao Jiang, Frank Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. EMNLP. 2023. [paper]
This section includes self-correction frameworks that train LLMs specifically for self-correction, but do not use external tools or information retrieval during inference.
It has been reported that LLMs often can self-correct their own mistakes when fine-tuned on ground-truth feedback (e.g., human annotated or generated by stronger models).
- Self-critiquing models for assisting human evaluators. William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. Preprint. 2022. [paper]
- [Re3] Re3: Generating Longer Stories With Recursive Reprompting and Revision. Kevin Yang, Yuandong Tian, Nanyun Peng, and Dan Klein. EMNLP. 2022. [paper]
- [SelFee] SelFee: Iterative Self-Revising LLM Empowered by Self-Feedback Generation. Seonghyeon Ye, Yongrae Jo, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, and Minjoon Seo. Blog post. 2023. [blog]
- [Volcano] Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision. Seongyun Lee, Sue Park, Yongrae Jo, and Minjoon Seo. NAACL. 2024. [paper]
- [REFINER] REFINER: Reasoning Feedback on Intermediate Representations. Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. EACL. 2024. [paper]
- [GLoRe] GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements. Alex Havrilla, Sharath Raparthy, Christoforus Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, and Roberta Raileanu. Preprint. 2024. [paper].
There are studies that attempt to improve self-correction without using ground-truth feedback because human annotation for self-correction is costly.
- [Self-corrective learning] Generating Sequences by Learning to Self-Correct. Sean Welleck, Ximing Lu, Peter West, Faeze Brahman, Tianxiao Shen, Daniel Khashabi, and Yejin Choi. ICLR. 2023. [paper]
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Preprint. 2024. [paper].
- [Meta-Reflection] Meta-Reflection: A Feedback-Free Reflection Learning Framework. Yaoke Wang, Yun Zhu, Xintong Bao, Wenqiao Zhang, Suyang Dai, Kehan Chen, Wenqiang Li, Gang Huang, Siliang Tang, Yueting Zhuang. Preprint. 2024. [paper]
Reinforcement learning is another approach to improve self-correction without using human annotated feedback.
- [RL4F] RL4F: Generating Natural Language Feedback with Reinforcement Learning for Repairing Model Outputs. Afra Feyza Akyurek, Ekin Akyurek, Ashwin Kalyan, Peter Clark, Derry Tanti Wijaya, and Niket Tandon. ACL. 2023. [paper]
- [RISE] Recursive Introspection: Teaching Language Model Agents How to Self-Improve. Yuxiao Qu, Tianjun Zhang, Naman Garg, and Aviral Kumar. Preprint. 2024. [paper]
- [SCoRe] Training Language Models to Self-Correct via Reinforcement Learning. Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. Preprint. 2024. [paper]
OpenAI o1 is a framework focusing on improving the reasoning capabilities of LLMs trained with reinforcement learning to explore multiple reasoning processes and correct their own mistakes during inference. After the release of OpenAI o1, several papers or projects have proposed frameworks similar to OpenAI o1.
- [OpenAI o1] Learning to Reason with LLMs. OpenAI. Blog post. 2024. [blog] [system card]
- Evaluation of OpenAI o1: Opportunities and Challenges of AGI. Tianyang Zhong, Zhengliang Liu, Yi Pan, Yutong Zhang, Yifan Zhou, Shizhe Liang, Zihao Wu, Yanjun Lyu, Peng Shu, Xiaowei Yu, Chao Cao, Hanqi Jiang, Hanxu Chen, Yiwei Li, Junhao Chen, Huawen Hu, Yihen Liu, Huaqin Zhao, Shaochen Xu, Haixing Dai, Lin Zhao, Ruidong Zhang, Wei Zhao, Zhenyuan Yang, Jingyuan Chen, Peilong Wang, Wei Ruan, Hui Wang, Huan Zhao, Jing Zhang, Yiming Ren, Shihuan Qin, Tong Chen, Jiaxi Li, Arif Hassan Zidan, Afrar Jahin, Minheng Chen, Sichen Xia, Jason Holmes, Yan Zhuang, Jiaqi Wang, Bochen Xu, Weiran Xia, Jichao Yu, Kaibo Tang, Yaxuan Yang, Bolun Sun, Tao Yang, Guoyu Lu, Xianqiao Wang, Lilong Chai, He Li, Jin Lu, Lichao Sun, Xin Zhang, Bao Ge, Xintao Hu, Lian Zhang, Hua Zhou, Lu Zhang, Shu Zhang, Ninghao Liu, Bei Jiang, Linglong Kong, Zhen Xiang, Yudan Ren, Jun Liu, Xi Jiang, Yu Bao, Wei Zhang, Xiang Li, Gang Li, Wei Liu, Dinggang Shen, Andrea Sikora, Xiaoming Zhai, Dajiang Zhu, and Tianming Liu. Preprint. 2024. [paper].
- [Skywork-o1] Skywork-o1 Open Series. Skywork-o1 Team. Models. 2024. [models].
- [LLaVA-CoT] LLaVA-CoT: Let Vision Language Models Reason Step-by-Step. Guowei Xu, Peng Jin, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Preprint. 2024. [paper].
- [Marco-o1] Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions. Yu Zhao, Huifeng Yin, Bo Zeng, Hao Wang, Tianqi Shi, Chenyang Lyu, Longyue Wang, Weihua Luo, and Kaifu Zhang. Preprint. 2024. [paper]
- [QwQ] QwQ: Reflect Deeply on the Boundaries of the Unknown. Qwen Team. Blog post. 2024. [blog]
For more papers related to OpenAI o1, please also refer to the following repositories.
- [Volcano] Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision. Seongyun Lee, Sue Park, Yongrae Jo, and Minjoon Seo. NAACL. 2024. [paper]
- [VISCO] VISCO: Benchmarking Fine-Grained Critique and Correction Towards Self-Improvement in Visual Reasoning. Xueqing Wu, Yuheng Ding, Bingxuan Li, Pan Lu, Da Yin, Kai-Wei Chang, and Nanyun Peng. Preprint. 2024. [paper].
We welcome contributions! If you’d like to add a new paper to this list, please submit a pull request. Ensure that your commit and PR have descriptive and unique titles rather than generic ones like "Updated README.md."
Kindly use the following format for your entry:
* [Short name (if exists)] **Paper Title.** *Author1, Author2, ... , and Last Author.* Conference/Journal/Preprint/Blog post. year. [[paper](url)] [[code, follow up paper, etc.](url)]If you have any questions or suggestions, please feel free to open an issue or reach out to Ryo Kamoi ([email protected]).
Please refer to LICENSE.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-self-correction-papers
Similar Open Source Tools
llm-self-correction-papers
This repository contains a curated list of papers focusing on the self-correction of large language models (LLMs) during inference. It covers various frameworks for self-correction, including intrinsic self-correction, self-correction with external tools, self-correction with information retrieval, and self-correction with training designed specifically for self-correction. The list includes survey papers, negative results, and frameworks utilizing reinforcement learning and OpenAI o1-like approaches. Contributions are welcome through pull requests following a specific format.
AI-PhD-S24
AI-PhD-S24 is a mono-repo for the PhD course 'AI for Business Research' at CUHK Business School in Spring 2024. The course aims to provide a basic understanding of machine learning and artificial intelligence concepts/methods used in business research, showcase how ML/AI is utilized in business research, and introduce state-of-the-art AI/ML technologies. The course includes scribed lecture notes, class recordings, and covers topics like AI/ML fundamentals, DL, NLP, CV, unsupervised learning, and diffusion models.
AI-PhD-S25
AI-PhD-S25 is a mono-repo for the DOTE 6635 course on AI for Business Research at CUHK Business School. The course aims to provide a fundamental understanding of ML/AI concepts and methods relevant to business research, explore applications of ML/AI in business research, and discover cutting-edge AI/ML technologies. The course resources include Google CoLab for code distribution, Jupyter Notebooks, Google Sheets for group tasks, Overleaf template for lecture notes, replication projects, and access to HPC Server compute resource. The course covers topics like AI/ML in business research, deep learning basics, attention mechanisms, transformer models, LLM pretraining, posttraining, causal inference fundamentals, and more.

Time-LLM
Time-LLM is a reprogramming framework that repurposes large language models (LLMs) for time series forecasting. It allows users to treat time series analysis as a 'language task' and effectively leverage pre-trained LLMs for forecasting. The framework involves reprogramming time series data into text representations and providing declarative prompts to guide the LLM reasoning process. Time-LLM supports various backbone models such as Llama-7B, GPT-2, and BERT, offering flexibility in model selection. The tool provides a general framework for repurposing language models for time series forecasting tasks.
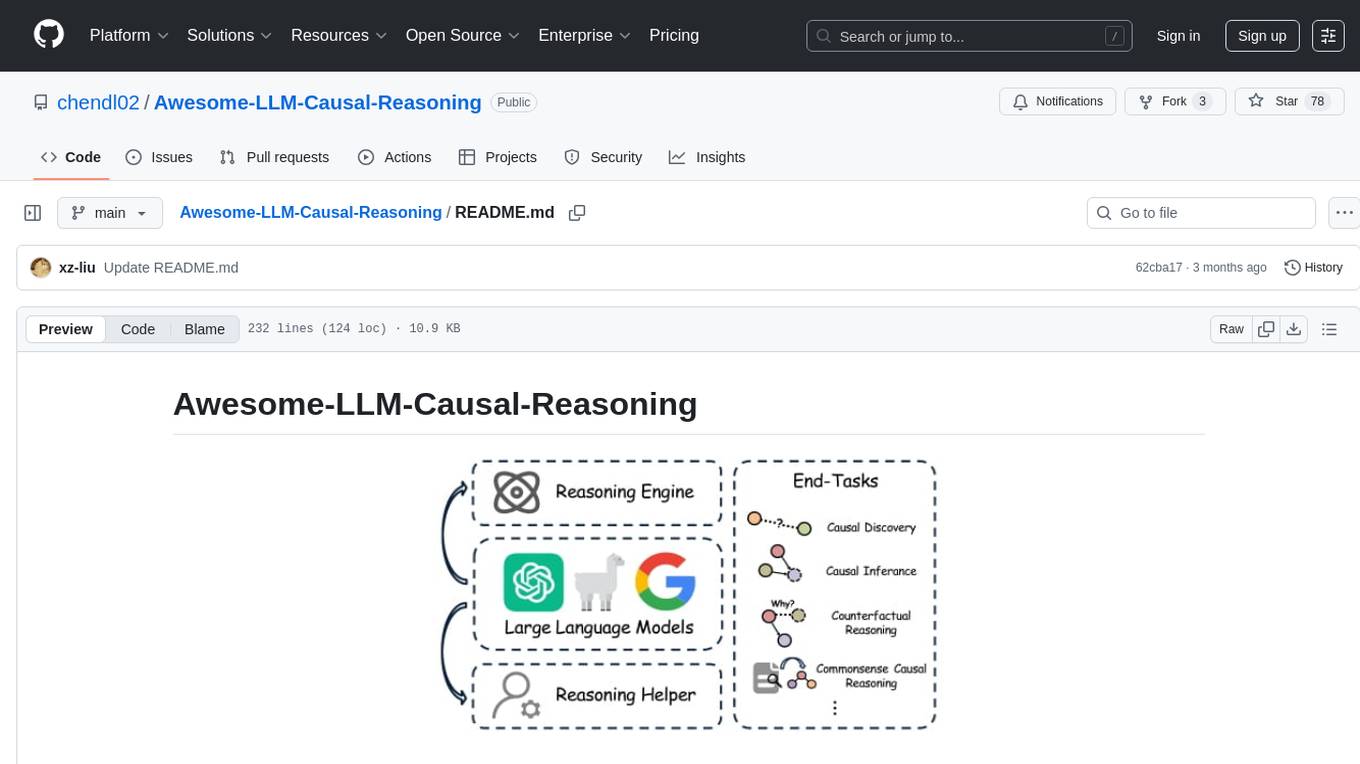
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.
awesome-ai-llm4education
The 'awesome-ai-llm4education' repository is a curated list of papers related to artificial intelligence (AI) and large language models (LLM) for education. It collects papers from top conferences, journals, and specialized domain-specific conferences, categorizing them based on specific tasks for better organization. The repository covers a wide range of topics including tutoring, personalized learning, assessment, material preparation, specific scenarios like computer science, language, math, and medicine, aided teaching, as well as datasets and benchmarks for educational research.
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.

awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
xgen
XGen is a research release for the family of XGen models (7B) by Salesforce AI Research. It includes models with support for different sequence lengths and tokenization using the OpenAI Tiktoken package. The models can be used for auto-regressive sampling in natural language generation tasks.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
CodeGen
CodeGen is an official release of models for Program Synthesis by Salesforce AI Research. It includes CodeGen1 and CodeGen2 models with varying parameters. The latest version, CodeGen2.5, outperforms previous models. The tool is designed for code generation tasks using large language models trained on programming and natural languages. Users can access the models through the Hugging Face Hub and utilize them for program synthesis and infill sampling. The accompanying Jaxformer library provides support for data pre-processing, training, and fine-tuning of the CodeGen models.
IvyGPT
IvyGPT is a medical large language model that aims to generate the most realistic doctor consultation effects. It has been fine-tuned on high-quality medical Q&A data and trained using human feedback reinforcement learning. The project features full-process training on medical Q&A LLM, multiple fine-tuning methods support, efficient dataset creation tools, and a dataset of over 300,000 high-quality doctor-patient dialogues for training.
For similar tasks
companion
Companion is a generative AI-powered tool that serves as a private tutor for learning a new foreign language. It utilizes OpenAI ChatGPT & Whisper and Google Text-to-Speech & Translate to enable users to write, talk, read, and listen in both their native language and the selected foreign language. The tool is designed to correct any mistakes made by the user and can be run locally or as a cloud service, making it accessible on mobile devices. Companion is distributed for non-commercial usage, but users should be aware that some of the APIs and services it relies on may incur charges based on usage.
llm-self-correction-papers
This repository contains a curated list of papers focusing on the self-correction of large language models (LLMs) during inference. It covers various frameworks for self-correction, including intrinsic self-correction, self-correction with external tools, self-correction with information retrieval, and self-correction with training designed specifically for self-correction. The list includes survey papers, negative results, and frameworks utilizing reinforcement learning and OpenAI o1-like approaches. Contributions are welcome through pull requests following a specific format.

graphrag
The GraphRAG project is a data pipeline and transformation suite designed to extract meaningful, structured data from unstructured text using LLMs. It enhances LLMs' ability to reason about private data. The repository provides guidance on using knowledge graph memory structures to enhance LLM outputs, with a warning about the potential costs of GraphRAG indexing. It offers contribution guidelines, development resources, and encourages prompt tuning for optimal results. The Responsible AI FAQ addresses GraphRAG's capabilities, intended uses, evaluation metrics, limitations, and operational factors for effective and responsible use.
Awesome-Latent-CoT
This repository contains a regularly updated paper list for Large Language Models (LLMs) reasoning in latent space. Reasoning in latent space allows for more flexible and efficient thought representation beyond language tokens, bringing AI closer to human-like cognition. The repository covers various aspects of LLMs, including pre-training, supervised finetuning, analysis, interpretability, multimodal reasoning, and applications. It aims to showcase the advancements in reasoning with latent thoughts and continuous concepts in AI models.

ERNIE
ERNIE 4.5 is a family of large-scale multimodal models with 10 distinct variants, including Mixture-of-Experts (MoE) models with 47B and 3B active parameters. The models feature a novel heterogeneous modality structure supporting parameter sharing across modalities while allowing dedicated parameters for each individual modality. Trained with optimal efficiency using PaddlePaddle deep learning framework, ERNIE 4.5 models achieve state-of-the-art performance across text and multimodal benchmarks, enhancing multimodal understanding without compromising performance on text-related tasks. The open-source development toolkits for ERNIE 4.5 offer industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.

LLM-KG4QA
LLM-KG4QA is a repository focused on the integration of Large Language Models (LLMs) and Knowledge Graphs (KGs) for Question Answering (QA). It covers various aspects such as using KGs as background knowledge, reasoning guideline, and refiner/filter. The repository provides detailed information on pre-training, fine-tuning, and Retrieval Augmented Generation (RAG) techniques for enhancing QA performance. It also explores complex QA tasks like Explainable QA, Multi-Modal QA, Multi-Document QA, Multi-Hop QA, Multi-run and Conversational QA, Temporal QA, Multi-domain and Multilingual QA, along with advanced topics like Optimization and Data Management. Additionally, it includes benchmark datasets, industrial and scientific applications, demos, and related surveys in the field.

MemoryBear
MemoryBear is a next-generation AI memory system developed by RedBear AI, focusing on overcoming limitations in knowledge storage and multi-agent collaboration. It empowers AI with human-like memory capabilities, enabling deep knowledge understanding and cognitive collaboration. The system addresses challenges such as knowledge forgetting, memory gaps in multi-agent collaboration, and semantic ambiguity during reasoning. MemoryBear's core features include memory extraction engine, graph storage, hybrid search, memory forgetting engine, self-reflection engine, and FastAPI services. It offers a standardized service architecture for efficient integration and invocation across applications.

together-cookbook
The Together Cookbook is a collection of code and guides designed to help developers build with open source models using Together AI. The recipes provide examples on how to chain multiple LLM calls, create agents that route tasks to specialized models, run multiple LLMs in parallel, break down tasks into parallel subtasks, build agents that iteratively improve responses, perform LoRA fine-tuning and inference, fine-tune LLMs for repetition, improve summarization capabilities, fine-tune LLMs on multi-step conversations, implement retrieval-augmented generation, conduct multimodal search and conditional image generation, visualize vector embeddings, improve search results with rerankers, implement vector search with embedding models, extract structured text from images, summarize and evaluate outputs with LLMs, generate podcasts from PDF content, and get LLMs to generate knowledge graphs.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.