
Awesome-LLM-Strawberry
A collection of LLM papers, blogs, and projects, with a focus on OpenAI o1 🍓 and reasoning techniques.
Stars: 6281
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
README:



This is a collection of research papers & blogs for OpenAI Strawberry(o1) and Reasoning.
And the repository will be continuously updated to track the frontier of LLM Reasoning.
- [OpenAI] o3 preview & o3 mini
- [OpenAI] Introducing ChatGPT Pro
- [Google DeepMind] Gemini 2.0 Flash Thinking
- [Ilya Sutskever] AI with reasoning power will be less predictable
- [SemianAlysis] Scaling Laws – O1 Pro Architecture, Reasoning Training Infrastructure, Orion and Claude 3.5 Opus “Failures”
- [DeepSeek] DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power!
- [Moonshoot] 数学对标o1系列,搜索再次进化,Kimi 新推理模型与你一起拓展智能边界
- [Moonshoot] Kimi 发布视觉思考模型 k1,多项理科测试行业领先
- [InternLM] 强推理模型书生InternThinker开放体验:自主生成高智力密度数据、具备元动作思考能力
- [新智元] 万字独家爆光,首揭o1 pro架构!惊人反转,Claude 3.5 Opus没失败?
- [OpenAI] Learning to Reason with LLMs
- [OpenAI] OpenAI o1-mini Advancing cost-efficient reasoning
- [OpenAI] Finding GPT-4’s mistakes with GPT-4
- [ARC-AGI] OpenAI o3 Breakthrough High Score on ARC-AGI-Pub
- [Anthropic] Building effective agents
- [Tibor Blaho] Summary of what we have learned during AMA hour with the OpenAI o1 team
- [hijkzzz] Exploring OpenAI O1 Model Replication
- [hijkzzz] A Survey of Reinforcement Learning from Human Feedback (RLHF)
- [Nathan Lambert] OpenAI’s Strawberry, LM self-talk, inference scaling laws, and spending more on inference
- [Nathan Lambert] Reverse engineering OpenAI’s o1
- [Andreas Stuhlmüller, jungofthewon] Supervise Process, not Outcomes
- [Nouha Dziri] Have o1 Models Cracked Human Reasoning?
- [Rishabh Agarwal] Improving LLM Reasoning using Self-generated data: RL and Verifiers
- [Wei Shen] Generalization Progress in RLHF: Insights into the Impact of Reward Models and PPO
- [Dominater069] Codeforces - Analyzing how good O1-Mini actually is
- [hijkzzz] o1 复现以及关于 REINFORCE & GRPO 的碎碎念
- [Noam Brown] Parables on the Power of Planning in AI: From Poker to Diplomacy
- [Noam Brown] OpenAI o1 and Teaching LLMs to Reason Better
- [Hyung Won Chung] Don't teach. Incentivize.
- [DeepLearning.AI] Reasoning with o1
OpenAI Developers
Noam Brown
Jason Wei
Others
- [Alibaba Qwen Team] QwQ
- [Alibaba Qwen Team] QvQ
- [DeepSeek] DeepSeek R1
- [OpenO1 Team] Open-Source O1
- [NovaSky] Sky-T1
- [GAIR-NLP] O1 Replication Journey: A Strategic Progress Report
- [Tencent] DRT-o1
- [Skywork] Skywork o1 Open model series
- [Alibaba] Marco-o1
- [CUHK-SZ] HuatuoGPT-o1
- [Steiner] A Small Step Towards Reproducing OpenAI o1: Progress Report on the Steiner Open Source Models
- [OpenRLHF Team] OpenRLHF
- [OpenRLHF Team] REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models | Code
- [openreasoner] OpenR
- [Maitrix.org] LLM Reasoners
- [bklieger-groq] g1: Using Llama-3.1 70b on Groq to create o1-like reasoning chains
- [o1-chain-of-thought] Transcription of o1 Reasoning Traces from OpenAI blog post
format:
- [title](paper link) [links]
- author1, author2, and author3...
- publisher
- code
- experimental environments and datasets
Relevant Paper from OpenAI o1 contributors
-
Deliberative alignment: reasoning enables safer language models
- OpenAI
-
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
- Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, Aleksander Mądry
-
Training Verifiers to Solve Math Word Problems
- Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, John Schulman
-
Generative Language Modeling for Automated Theorem Proving
- Stanislas Polu, Ilya Sutskever
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
-
Self-Consistency Improves Chain of Thought Reasoning in Language Models
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, Denny Zhou
-
Let's Verify Step by Step
- Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, Karl Cobbe
-
LLM Critics Help Catch LLM Bugs
- Nat McAleese, Rai Michael Pokorny, Juan Felipe Ceron Uribe, Evgenia Nitishinskaya, Maja Trebacz, Jan Leike
-
Self-critiquing models for assisting human evaluators
- William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, Jan Leike
-
Scalable Online Planning via Reinforcement Learning Fine-Tuning
- Arnaud Fickinger, Hengyuan Hu, Brandon Amos, Stuart Russell, Noam Brown.
-
Improving Policies via Search in Cooperative Partially Observable Games
- Adam Lerer, Hengyuan Hu, Jakob Foerster, Noam Brown.
-
From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond
- Scott McKinney
-
Kimi k1.5: Scaling Reinforcement Learning with LLMs
- MoonShot
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via
Reinforcement Learning
- DeepSeek AI
-
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
- Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, Mao Yang
-
Evolving Deeper LLM Thinking
- Kuang-Huei Lee, Ian Fischer, Yueh-Hua Wu, Dave Marwood, Shumeet Baluja, Dale Schuurmans, Xinyun Chen
-
The Lessons of Developing Process Reward Models in Mathematical Reasoning
- Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin
-
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
- Violet Xiang, Charlie Snell, Kanishk Gandhi, Alon Albalak, Anikait Singh, Chase Blagden, Duy Phung, Rafael Rafailov, Nathan Lile, Dakota Mahan, Louis Castricato, Jan-Philipp Franken, Nick Haber, Chelsea Finn
-
PRMBENCH: A Fine-grained and Challenging Benchmark for Process-Level Reward Models
- Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, Yu Cheng
-
Virgo: A Preliminary Exploration on Reproducing o1-like MLLM
- Yifan Du, Zikang Liu, Yifan Li, Wayne Xin Zhao, Yuqi Huo, Bingning Wang, Weipeng Chen, Zheng Liu, Zhongyuan Wang, Ji-Rong Wen
-
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
- Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vulić, Furu Wei
-
LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs
- Omkar Thawakar, Dinura Dissanayake, Ketan More, Ritesh Thawkar, Ahmed Heakl, Noor Ahsan, Yuhao Li, Mohammed Zumri, Jean Lahoud, Rao Muhammad Anwer, Hisham Cholakkal, Ivan Laptev, Mubarak Shah, Fahad Shahbaz Khan, Salman Khan
-
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- Charlie Snell, Jaehoon Lee, Kelvin Xu, Aviral Kumar
-
An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models
- Yangzhen Wu, Zhiqing Sun, Shanda Li, Sean Welleck, Yiming Yang
-
Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
- Hritik Bansal, Arian Hosseini, Rishabh Agarwal, Vinh Q. Tran, Mehran Kazemi
-
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
- Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, Azalia Mirhoseini
-
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems
- Yingqian Min, Zhipeng Chen, Jinhao Jiang, Jie Chen, Jia Deng, Yiwen Hu, Yiru Tang, Jiapeng Wang, Xiaoxue Cheng, Huatong Song, Wayne Xin Zhao, Zheng Liu, Zhongyuan Wang, Ji-Rong Wen
-
Training Language Models to Self-Correct via Reinforcement Learning
- Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, Aleksandra Faust
-
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
- Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, Dong Yu
-
MEDEC: A Benchmark for Medical Error Detection and Correction in Clinical Notes
- Asma Ben Abacha, Wen-wai Yim, Yujuan Fu, Zhaoyi Sun, Meliha Yetisgen, Fei Xia, Thomas Lin
-
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
- An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, Zhenru Zhang
-
Does RLHF Scale? Exploring the Impacts From Data, Model, and Method
- Zhenyu Hou, Pengfan Du, Yilin Niu, Zhengxiao Du, Aohan Zeng, Xiao Liu, Minlie Huang, Hongning Wang, Jie Tang, Yuxiao Dong
-
Search, Verify and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering
- Xinyan Guan, Yanjiang Liu, Xinyu Lu, Boxi Cao, Ben He, Xianpei Han, Le Sun, Jie Lou, Bowen Yu, Yaojie Lu, Hongyu Lin
-
Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective
- Zhiyuan Zeng, Qinyuan Cheng, Zhangyue Yin, Bo Wang, Shimin Li, Yunhua Zhou, Qipeng Guo, Xuanjing Huang, Xipeng Qiu
-
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
- Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, Noah D. Goodman
- https://github.com/ezelikman/quiet-star
-
Enhancing LLM Reasoning via Critique Models with Test-Time and Training-Time Supervision
- Zhiheng Xi, Dingwen Yang, Jixuan Huang, Jiafu Tang, Guanyu Li, Yiwen Ding, Wei He, Boyang Hong, Shihan Do, Wenyu Zhan, Xiao Wang, Rui Zheng, Tao Ji, Xiaowei Shi, Yitao Zhai, Rongxiang Weng, Jingang Wang, Xunliang Cai, Tao Gui, Zuxuan Wu, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Yu-Gang Jiang
- https://mathcritique.github.io/
-
On Designing Effective RL Reward at Training Time for LLM Reasoning
- Jiaxuan Gao, Shusheng Xu, Wenjie Ye, Weilin Liu, Chuyi He, Wei Fu, Zhiyu Mei, Guangju Wang, Yi Wu
-
Generative Verifiers: Reward Modeling as Next-Token Prediction
- Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, Rishabh Agarwal
-
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
- Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, Aviral Kumar
-
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
- Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, Abhinav Rastogi
-
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
- Peiyi Wang, Lei Li, Zhihong Shao, R.X. Xu, Damai Dai, Yifei Li, Deli Chen, Y.Wu, Zhifang Sui
-
Planning In Natural Language Improves LLM Search For Code Generation
- Evan Wang, Federico Cassano, Catherine Wu, Yunfeng Bai, Will Song, Vaskar Nath, Ziwen Han, Sean Hendryx, Summer Yue, Hugh Zhang
-
PROCESSBENCH: Identifying Process Errors in Mathematical Reasoning
- Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin
-
AFlow: Automating Agentic Workflow Generation
- Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, Chenglin Wu
-
Interpretable Contrastive Monte Carlo Tree Search Reasoning
- Zitian Gao, Boye Niu, Xuzheng He, Haotian Xu, Hongzhang Liu, Aiwei Liu, Xuming Hu, Lijie Wen
-
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
- Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, Rafael Rafailov
-
Mixture-of-Agents Enhances Large Language Model Capabilities
- Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, James Zou
-
Uncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models
- Zhiyuan Hu, Chumin Liu, Xidong Feng, Yilun Zhao, See-Kiong Ng, Anh Tuan Luu, Junxian He, Pang Wei Koh, Bryan Hooi
-
Advancing LLM Reasoning Generalists with Preference Trees
- Lifan Yuan, Ganqu Cui, Hanbin Wang, Ning Ding, Xingyao Wang, Jia Deng, Boji Shan et al.
-
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
- Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, and Dong Yu.
-
AlphaMath Almost Zero: Process Supervision Without Process
- Guoxin Chen, Minpeng Liao, Chengxi Li, Kai Fan.
-
ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
- Dan Zhang, Sining Zhoubian, Yisong Yue, Yuxiao Dong, and Jie Tang.
-
Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search
- Huanjin Yao, Jiaxing Huang, Wenhao Wu, Jingyi Zhang, Yibo Wang, Shunyu Liu, Yingjie Wang, Yuxin Song, Haocheng Feng, Li Shen, Dacheng Tao
-
Insight-V: Exploring Long-Chain Visual Reasoning with Multimodal Large Language Models
- Yuhao Dong, Zuyan Liu, Hai-Long Sun, Jingkang Yang, Winston Hu, Yongming Rao, Ziwei Liu
-
MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time
- Jikun Kang, Xin Zhe Li, Xi Chen, Amirreza Kazemi, Qianyi Sun, Boxing Chen, Dong Li, Xu He, Quan He, Feng Wen, Jianye Hao, Jun Yao.
-
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
- Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh.
-
When is Tree Search Useful for LLM Planning? It Depends on the Discriminator
- Ziru Chen, Michael White, Raymond Mooney, Ali Payani, Yu Su, Huan Sun
-
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems
- Zhiyuan Li, Hong Liu, Denny Zhou, Tengyu Ma.
-
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
- Zayne Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, Greg Durrett
-
Do Large Language Models Latently Perform Multi-Hop Reasoning?
- Sohee Yang, Elena Gribovskaya, Nora Kassner, Mor Geva, Sebastian Riedel
-
Chain-of-Thought Reasoning Without Prompting
- Xuezhi Wang, Denny Zhou
-
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers
- Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, Mao Yang
-
Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs
- Xuan Zhang, Chao Du, Tianyu Pang, Qian Liu, Wei Gao, Min Lin
-
ReFT: Reasoning with Reinforced Fine-Tuning
- Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, Hang Li
-
VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment
- Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, Nicolas Le Roux
-
Stream of Search (SoS): Learning to Search in Language
- Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, Noah D. Goodman
-
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
- Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, Mehrdad Farajtabar
-
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
- Tianyang Zhong, Zhengliang Liu, Yi Pan, Yutong Zhang, Yifan Zhou, Shizhe Liang, Zihao Wu, Yanjun Lyu, Peng Shu, Xiaowei Yu, Chao Cao, Hanqi Jiang, Hanxu Chen, Yiwei Li, Junhao Chen, etc.
-
Evaluating LLMs at Detecting Errors in LLM Responses
- Ryo Kamoi, Sarkar Snigdha Sarathi Das, Renze Lou, Jihyun Janice Ahn, Yilun Zhao, Xiaoxin Lu, Nan Zhang, Yusen Zhang, Ranran Haoran Zhang, Sujeeth Reddy Vummanthala, Salika Dave, Shaobo Qin, Arman Cohan, Wenpeng Yin, Rui Zhang
-
On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
- Kevin Wang, Junbo Li, Neel P. Bhatt, Yihan Xi, Qiang Liu, Ufuk Topcu, Zhangyang Wang
-
Not All LLM Reasoners Are Created Equal
- Arian Hosseini, Alessandro Sordoni, Daniel Toyama, Aaron Courville, Rishabh Agarwal
-
LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench
- Karthik Valmeekam, Kaya Stechly, Subbarao Kambhampati
-
A Comparative Study on Reasoning Patterns of OpenAI's o1 Model
- Siwei Wu, Zhongyuan Peng, Xinrun Du, Tuney Zheng, Minghao Liu, Jialong Wu, Jiachen Ma, Yizhi Li, Jian Yang, Wangchunshu Zhou, Qunshu Lin, Junbo Zhao, Zhaoxiang Zhang, Wenhao Huang, Ge Zhang, Chenghua Lin, J.H. Liu
-
Thinking LLMs: General Instruction Following with Thought Generation
- Tianhao Wu, Janice Lan, Weizhe Yuan, Jiantao Jiao, Jason Weston, Sainbayar Sukhbaatar
-
Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning Through Trap Problems
- Jun Zhao, Jingqi Tong, Yurong Mou, Ming Zhang, Qi Zhang, Xuanjing Huang
-
V-STaR: Training Verifiers for Self-Taught Reasoners
- Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, Rishabh Agarwal
-
CPL: Critical Plan Step Learning Boosts LLM Generalization in Reasoning Tasks
- Tianlong Wang, Junzhe Chen, Xueting Han, Jing Bai
-
RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
- Tianhao Wu, Janice Lan, Weizhe Yuan, Jiantao Jiao, Jason Weston, Sainbayar Sukhbaatar
-
Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
- Chaojie Wang, Yanchen Deng, Zhiyi Lyu, Liang Zeng, Jujie He, Shuicheng Yan, Bo An
-
Training Chain-of-Thought via Latent-Variable Inference
- Du Phan, Matthew D. Hoffman, David Dohan, Sholto Douglas, Tuan Anh Le, Aaron Parisi, Pavel Sountsov, Charles Sutton, Sharad Vikram, Rif A. Saurous
-
Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training
- Xidong Feng, Ziyu Wan, Muning Wen, Stephen Marcus McAleer, Ying Wen, Weinan Zhang, Jun Wang
-
OVM, Outcome-supervised Value Models for Planning in Mathematical Reasoning
- Fei Yu, Anningzhe Gao, Benyou Wang
-
Reasoning with Language Model is Planning with World Model
- Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, Zhiting Hu
-
Don’t throw away your value model! Generating more preferable text with Value-Guided Monte-Carlo Tree Search decoding
- Liu, Jiacheng, Andrew Cohen, Ramakanth Pasunuru, Yejin Choi, Hannaneh Hajishirzi, and Asli Celikyilmaz.
-
Certified reasoning with language models
- Gabriel Poesia, Kanishk Gandhi, Eric Zelikman, Noah D. Goodman
-
Large Language Models Cannot Self-Correct Reasoning Yet
- Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, Denny Zhou
-
Chain of Thought Imitation with Procedure Cloning
- Mengjiao Yang, Dale Schuurmans, Pieter Abbeel, Ofir Nachum.
-
STaR: Bootstrapping Reasoning With Reasoning
- Eric Zelikman, Yuhuai Wu, Jesse Mu, Noah D. Goodman
-
Solving math word problems with processand outcome-based feedback
- Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, Irina Higgins
-
Scaling Scaling Laws with Board Games
- Andy L. Jones.
-
Show Your Work: Scratchpads for Intermediate Computation with Language Models
- Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, Augustus Odena
-
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
- David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, Demis Hassabis.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLM-Strawberry
Similar Open Source Tools
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.
AI-PhD-S25
AI-PhD-S25 is a mono-repo for the DOTE 6635 course on AI for Business Research at CUHK Business School. The course aims to provide a fundamental understanding of ML/AI concepts and methods relevant to business research, explore applications of ML/AI in business research, and discover cutting-edge AI/ML technologies. The course resources include Google CoLab for code distribution, Jupyter Notebooks, Google Sheets for group tasks, Overleaf template for lecture notes, replication projects, and access to HPC Server compute resource. The course covers topics like AI/ML in business research, deep learning basics, attention mechanisms, transformer models, LLM pretraining, posttraining, causal inference fundamentals, and more.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.
IvyGPT
IvyGPT is a medical large language model that aims to generate the most realistic doctor consultation effects. It has been fine-tuned on high-quality medical Q&A data and trained using human feedback reinforcement learning. The project features full-process training on medical Q&A LLM, multiple fine-tuning methods support, efficient dataset creation tools, and a dataset of over 300,000 high-quality doctor-patient dialogues for training.
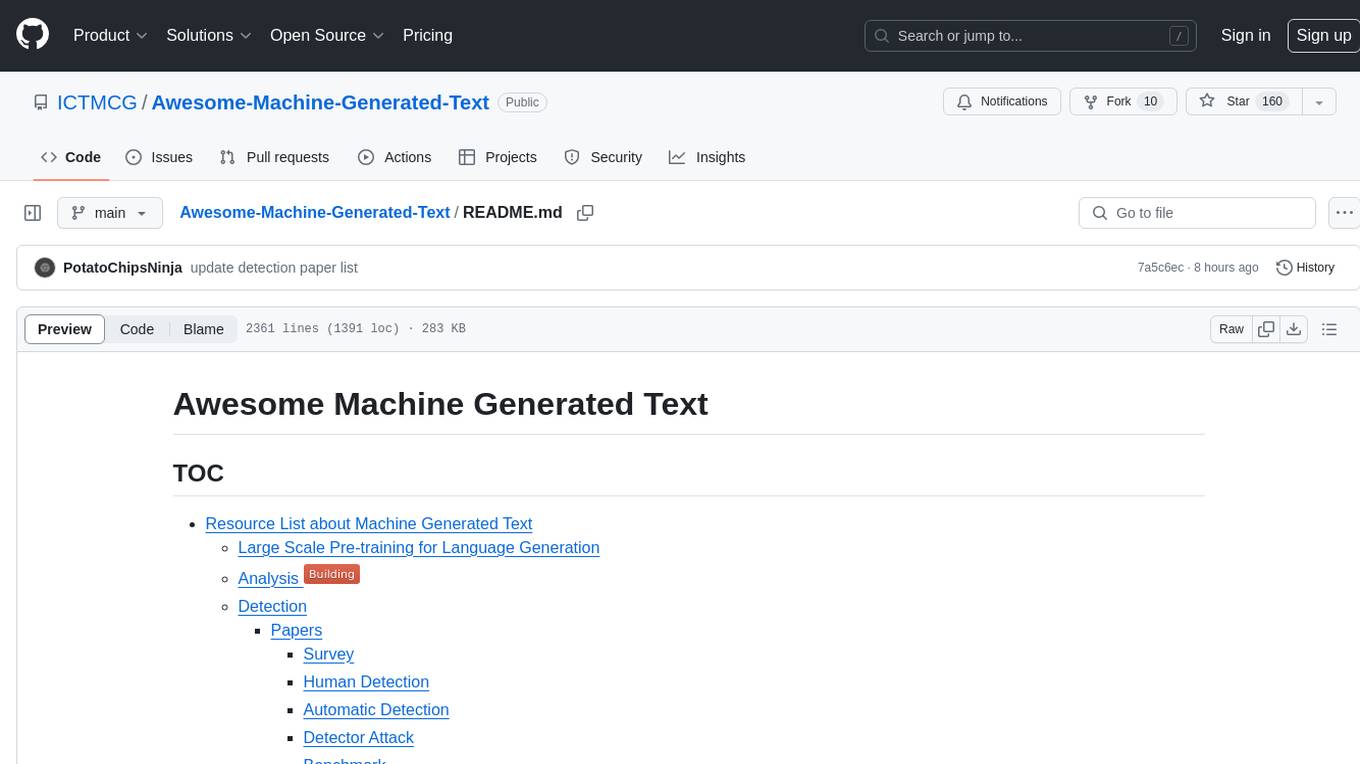
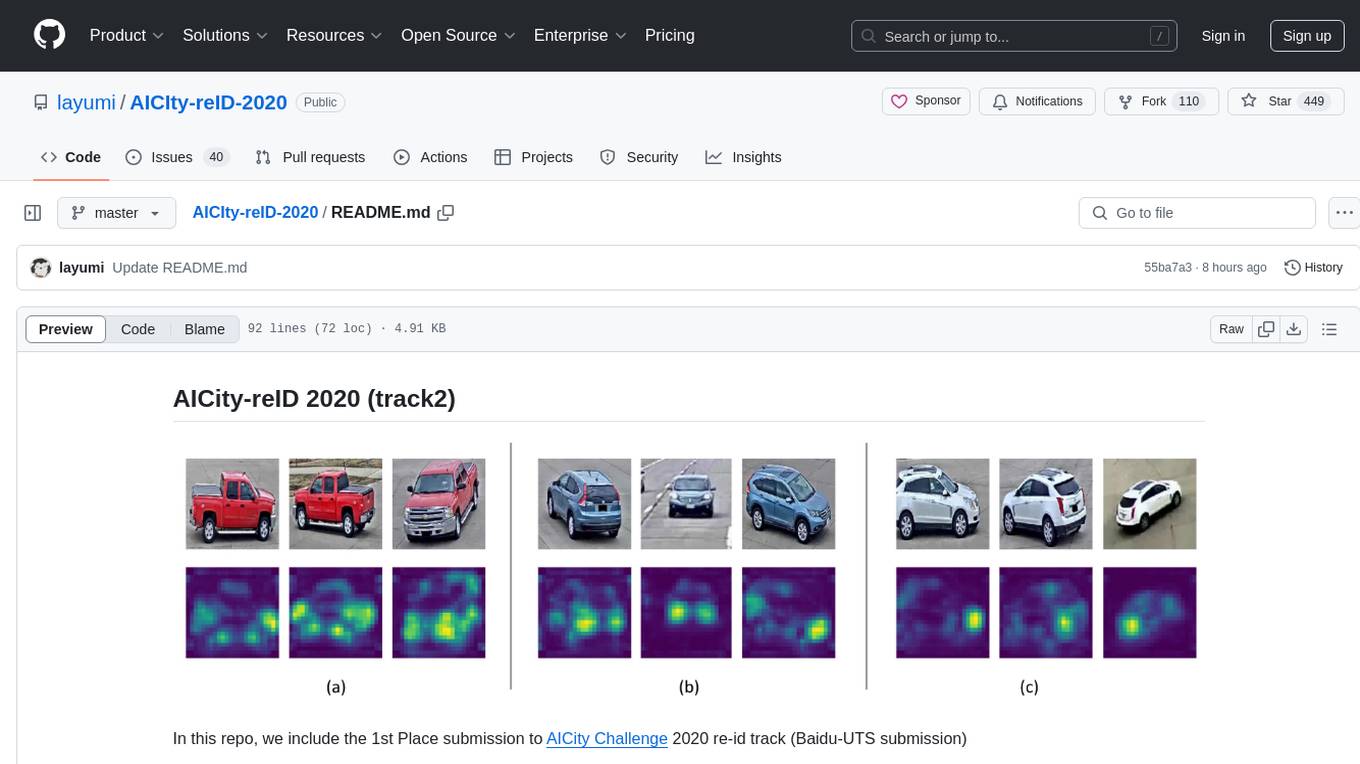
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.

LLMEvaluation
The LLMEvaluation repository is a comprehensive compendium of evaluation methods for Large Language Models (LLMs) and LLM-based systems. It aims to assist academics and industry professionals in creating effective evaluation suites tailored to their specific needs by reviewing industry practices for assessing LLMs and their applications. The repository covers a wide range of evaluation techniques, benchmarks, and studies related to LLMs, including areas such as embeddings, question answering, multi-turn dialogues, reasoning, multi-lingual tasks, ethical AI, biases, safe AI, code generation, summarization, software performance, agent LLM architectures, long text generation, graph understanding, and various unclassified tasks. It also includes evaluations for LLM systems in conversational systems, copilots, search and recommendation engines, task utility, and verticals like healthcare, law, science, financial, and others. The repository provides a wealth of resources for evaluating and understanding the capabilities of LLMs in different domains.
interpret
InterpretML is an open-source package that incorporates state-of-the-art machine learning interpretability techniques under one roof. With this package, you can train interpretable glassbox models and explain blackbox systems. InterpretML helps you understand your model's global behavior, or understand the reasons behind individual predictions. Interpretability is essential for: - Model debugging - Why did my model make this mistake? - Feature Engineering - How can I improve my model? - Detecting fairness issues - Does my model discriminate? - Human-AI cooperation - How can I understand and trust the model's decisions? - Regulatory compliance - Does my model satisfy legal requirements? - High-risk applications - Healthcare, finance, judicial, ...
Medical_Image_Analysis
The Medical_Image_Analysis repository focuses on X-ray image-based medical report generation using large language models. It provides pre-trained models and benchmarks for CheXpert Plus dataset, context sample retrieval for X-ray report generation, and pre-training on high-definition X-ray images. The goal is to enhance diagnostic accuracy and reduce patient wait times by improving X-ray report generation through advanced AI techniques.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
Play-with-LLMs
This repository provides a comprehensive guide to training, evaluating, and building applications with Large Language Models (LLMs). It covers various aspects of LLMs, including pretraining, fine-tuning, reinforcement learning from human feedback (RLHF), and more. The repository also includes practical examples and code snippets to help users get started with LLMs quickly and easily.
Recommendation-Systems-without-Explicit-ID-Features-A-Literature-Review
This repository is a collection of papers and resources related to recommendation systems, focusing on foundation models, transferable recommender systems, large language models, and multimodal recommender systems. It explores questions such as the necessity of ID embeddings, the shift from matching to generating paradigms, and the future of multimodal recommender systems. The papers cover various aspects of recommendation systems, including pretraining, user representation, dataset benchmarks, and evaluation methods. The repository aims to provide insights and advancements in the field of recommendation systems through literature reviews, surveys, and empirical studies.
LLM-PLSE-paper
LLM-PLSE-paper is a repository focused on the applications of Large Language Models (LLMs) in Programming Language and Software Engineering (PL/SE) domains. It covers a wide range of topics including bug detection, specification inference and verification, code generation, fuzzing and testing, code model and reasoning, code understanding, IDE technologies, prompting for reasoning tasks, and agent/tool usage and planning. The repository provides a comprehensive collection of research papers, benchmarks, empirical studies, and frameworks related to the capabilities of LLMs in various PL/SE tasks.
OpenNARS-for-Applications
OpenNARS-for-Applications is an implementation of a Non-Axiomatic Reasoning System, a general-purpose reasoner that adapts under the Assumption of Insufficient Knowledge and Resources. The system combines the logic and conceptual ideas of OpenNARS, event handling and procedure learning capabilities of ANSNA and 20NAR1, and the control model from ALANN. It is written in C, offers improved reasoning performance, and has been compared with Reinforcement Learning and means-end reasoning approaches. The system has been used in real-world applications such as assisting first responders, real-time traffic surveillance, and experiments with autonomous robots. It has been developed with a pragmatic mindset focusing on effective implementation of existing theory.
For similar tasks
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
MiniCPM
MiniCPM is a series of open-source large models on the client side jointly developed by Face Intelligence and Tsinghua University Natural Language Processing Laboratory. The main language model MiniCPM-2B has only 2.4 billion (2.4B) non-word embedding parameters, with a total of 2.7B parameters. - After SFT, MiniCPM-2B performs similarly to Mistral-7B on public comprehensive evaluation sets (better in Chinese, mathematics, and code capabilities), and outperforms models such as Llama2-13B, MPT-30B, and Falcon-40B overall. - After DPO, MiniCPM-2B also surpasses many representative open-source large models such as Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, and Zephyr-7B-alpha on the current evaluation set MTBench, which is closest to the user experience. - Based on MiniCPM-2B, a multi-modal large model MiniCPM-V 2.0 on the client side is constructed, which achieves the best performance of models below 7B in multiple test benchmarks, and surpasses larger parameter scale models such as Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on the OpenCompass leaderboard. MiniCPM-V 2.0 also demonstrates leading OCR capabilities, approaching Gemini Pro in scene text recognition capabilities. - After Int4 quantization, MiniCPM can be deployed and inferred on mobile phones, with a streaming output speed slightly higher than human speech speed. MiniCPM-V also directly runs through the deployment of multi-modal large models on mobile phones. - A single 1080/2080 can efficiently fine-tune parameters, and a single 3090/4090 can fully fine-tune parameters. A single machine can continuously train MiniCPM, and the secondary development cost is relatively low.
SemanticKernel.Assistants
This repository contains an assistant proposal for the Semantic Kernel, allowing the usage of assistants without relying on OpenAI Assistant APIs. It runs locally planners and plugins for the assistants, providing scenarios like Assistant with Semantic Kernel plugins, Multi-Assistant conversation, and AutoGen conversation. The Semantic Kernel is a lightweight SDK enabling integration of AI Large Language Models with conventional programming languages, offering functions like semantic functions, native functions, and embeddings-based memory. Users can bring their own model for the assistants and host them locally. The repository includes installation instructions, usage examples, and information on creating new conversation threads with the assistant.
AMchat
AMchat is a large language model that integrates advanced math concepts, exercises, and solutions. The model is based on the InternLM2-Math-7B model and is specifically designed to answer advanced math problems. It provides a comprehensive dataset that combines Math and advanced math exercises and solutions. Users can download the model from ModelScope or OpenXLab, deploy it locally or using Docker, and even retrain it using XTuner for fine-tuning. The tool also supports LMDeploy for quantization, OpenCompass for evaluation, and various other features for model deployment and evaluation. The project contributors have provided detailed documentation and guides for users to utilize the tool effectively.

MathVerse
MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.
Self-Iterative-Agent-System-for-Complex-Problem-Solving
The Self-Iterative Agent System for Complex Problem Solving is a solution developed for the Alibaba Mathematical Competition (AI Challenge). It involves multiple LLMs engaging in multi-round 'self-questioning' to iteratively refine the problem-solving process and select optimal solutions. The system consists of main and evaluation models, with a process that includes detailed problem-solving steps, feedback loops, and iterative improvements. The approach emphasizes communication and reasoning between sub-agents, knowledge extraction, and the importance of Agent-like architectures in complex tasks. While effective, there is room for improvement in model capabilities and error prevention mechanisms.
LLM4Opt
LLM4Opt is a collection of references and papers focusing on applying Large Language Models (LLMs) for diverse optimization tasks. The repository includes research papers, tutorials, workshops, competitions, and related collections related to LLMs in optimization. It covers a wide range of topics such as algorithm search, code generation, machine learning, science, industry, and more. The goal is to provide a comprehensive resource for researchers and practitioners interested in leveraging LLMs for optimization tasks.
LibreOffice-Content-Generator
LibreOffice AI Content Generator is a simple Python macro script that enables users to generate content from selected words/sentences using OpenAI or Google AI. The script allows users to perform various tasks such as generating content, translating to other languages, summarizing long content, improving content, and custom tasks like solving math questions. It requires APSO, OpenAI API Key, Google AI API Key, zenity for handling progress bars, and specific Python modules. Users need a little knowledge of LibreOffice macros and Python to use this tool effectively.
For similar jobs

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
NewEraAI-Papers
The NewEraAI-Papers repository provides links to collections of influential and interesting research papers from top AI conferences, along with open-source code to promote reproducibility and provide detailed implementation insights beyond the scope of the article. Users can stay up to date with the latest advances in AI research by exploring this repository. Contributions to improve the completeness of the list are welcomed, and users can create pull requests, open issues, or contact the repository owner via email to enhance the repository further.
cltk
The Classical Language Toolkit (CLTK) is a Python library that provides natural language processing (NLP) capabilities for pre-modern languages. It offers a modular processing pipeline with pre-configured defaults and supports almost 20 languages. Users can install the latest version using pip and access detailed documentation on the official website. The toolkit is designed to meet the unique needs of researchers working with historical languages, filling a void in the NLP landscape that often neglects non-spoken languages and different research goals.
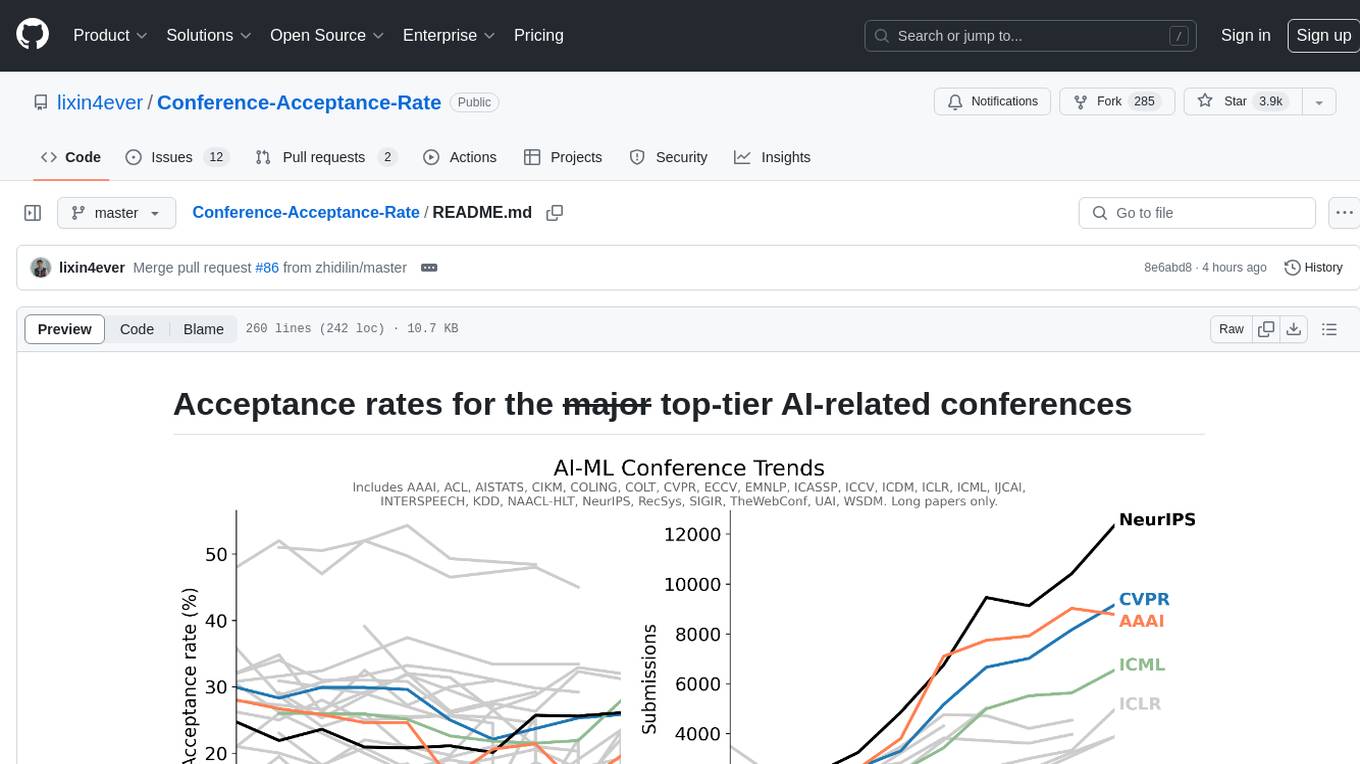
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

tods-arxiv-daily-paper
This repository provides a tool for fetching and summarizing daily papers from the arXiv repository. It allows users to stay updated with the latest research in various fields by automatically retrieving and summarizing papers on a daily basis. The tool simplifies the process of accessing and digesting academic papers, making it easier for researchers and enthusiasts to keep track of new developments in their areas of interest.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
Call-for-Reviewers
The `Call-for-Reviewers` repository aims to collect the latest 'call for reviewers' links from various top CS/ML/AI conferences/journals. It provides an opportunity for individuals in the computer/ machine learning/ artificial intelligence fields to gain review experience for applying for NIW/H1B/EB1 or enhancing their CV. The repository helps users stay updated with the latest research trends and engage with the academic community.