
AICIty-reID-2020
:red_car: The 1st Place Submission to AICity Challenge 2020 re-id track (Baidu-UTS submission)
Stars: 449
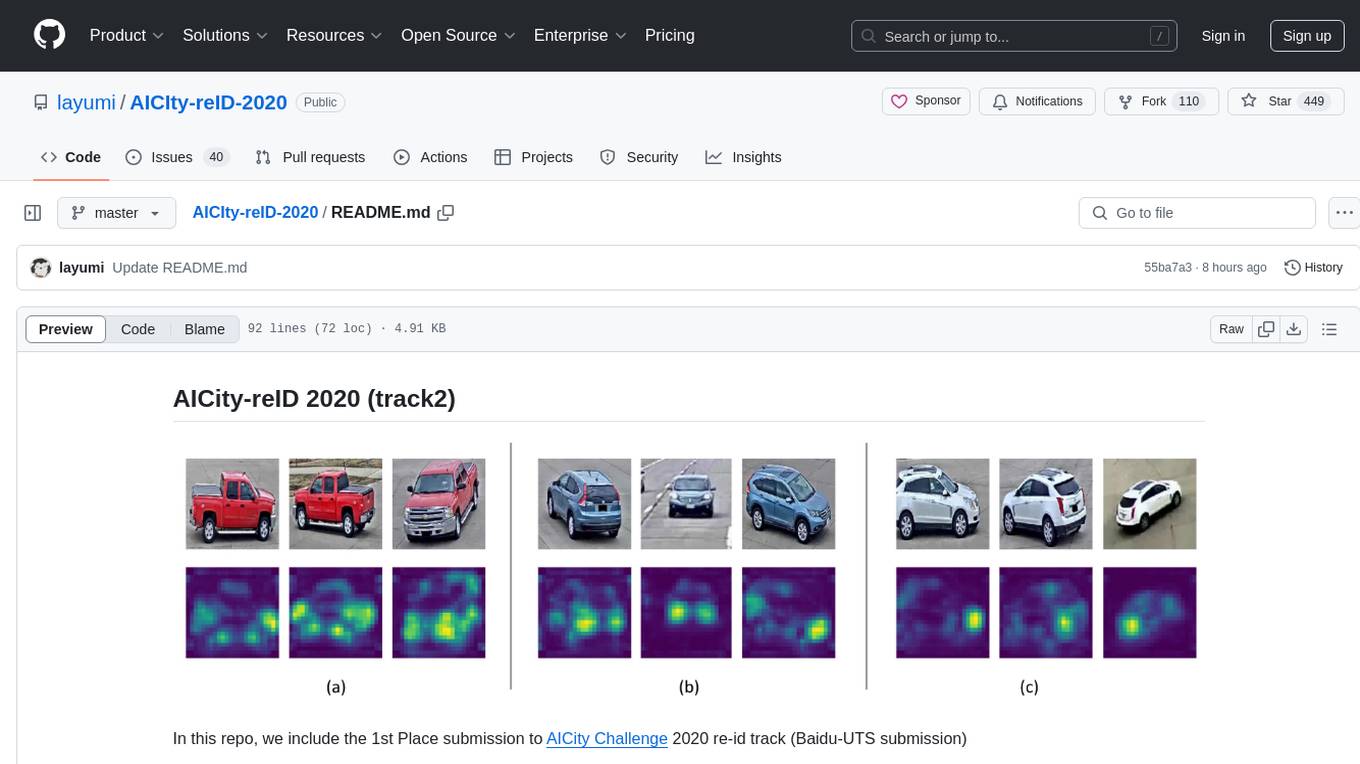
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.
README:

In this repo, we include the 1st Place submission to AICity Challenge 2020 re-id track (Baidu-UTS submission)
We fuse the models trained on Paddlepaddle and Pytorch. To illustrate them, we provide the two training parts seperatively as following.
- We include the Paddlepaddle training code at Here.
- We include the Pytorch training code at Here.
AICITY2020 Challange Track2 Leaderboard
| TeamName | mAP | Link |
|---|---|---|
| Baidu-UTS(Ours) | 84.1% | code |
| RuiYanAI | 78.1% | code |
| DMT | 73.1% | code |
How to extract features? Please refer to [Here] and there is one simplified version at [Here]. Here we provide one model of the final models.
- SE_imbalance_s1_384_p0.5_lr2_mt_d0_b24+v+aug (AICity 2020) can be downloaded at [GoogleDrive].
The state-of-the-art model achieving 83.41% mAP on VeRi-776, which is based on our TMM paper.
- Training on VehicelNet only (80.91): Res50_imbalance_s1_256_p0.5_lr2_mt_d0_b48 (TMM) can be downloaded at [GoogleDrive].
- Finetuning on VeRi (83.41): ft_Res50_imbalance_s1_256_p0.5_lr1_mt_d0.2_b48_w5 (TMM) can be downloaded at [GoogleDrive].
I have updated the feature. You may download from GoogleDrive or OneDrive (expired by July 1 2022)
├── final_features/
│ ├── features/ /* extracted pytorch feature
│ ├── pkl_feas/ /* extracted paddle feature (include direction similarity)
│ ├── real_query_fea_ResNeXt101_32x8d_wsl_416_416_final.pkl
| ...
│ ├── query_fea_Res2Net101_vd_final2.pkl
│ ├── gallery_cam_preds_baidu.txt /* gallery camera prediction
│ ├── query_cam_preds_baidu.txt /* query camera prediction
| ├── submit_cam.mat /* camera feature for camera similarity calculation
-
[Vehicle re-ID Paper Collection] https://github.com/layumi/Vehicle_reID-Collection
-
[Person re-ID Baseline] https://github.com/layumi/Person_reID_baseline_pytorch
-
[Person/Vehicle Generation] https://github.com/NVlabs/DG-Net
Please cite this paper if it helps your research:
@inproceedings{zheng2020going,
title={Going beyond real data: A robust visual representation for vehicle re-identification},
author={Zheng, Zhedong and Jiang, Minyue and Wang, Zhigang and Wang, Jian and Bai, Zechen and Zhang, Xuanmeng and Yu, Xin and Tan, Xiao and Yang, Yi and Wen, Shilei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops},
pages={598--599},
year={2020}
}
@article{zheng2020beyond,
title={VehicleNet: Learning Robust Visual Representation for Vehicle Re-identification},
author={Zheng, Zhedong and Ruan, Tao and Wei, Yunchao and Yang, Yi and Mei, Tao},
journal={IEEE Transactions on Multimedia (TMM)},
doi={10.1109/TMM.2020.3014488},
note={\mbox{doi}:\url{10.1109/TMM.2020.3014488}},
year={2020}
}The heatmap visualization is based on
@article{zheng2017discriminatively,
title={A discriminatively learned cnn embedding for person reidentification},
author={Zheng, Zhedong and Zheng, Liang and Yang, Yi},
journal={ACM transactions on multimedia computing, communications, and applications (TOMM)},
volume={14},
number={1},
pages={1--20},
year={2017},
publisher={ACM New York, NY, USA}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AICIty-reID-2020
Similar Open Source Tools
AICIty-reID-2020
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.
IvyGPT
IvyGPT is a medical large language model that aims to generate the most realistic doctor consultation effects. It has been fine-tuned on high-quality medical Q&A data and trained using human feedback reinforcement learning. The project features full-process training on medical Q&A LLM, multiple fine-tuning methods support, efficient dataset creation tools, and a dataset of over 300,000 high-quality doctor-patient dialogues for training.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

Vision-LLM-Alignment
Vision-LLM-Alignment is a repository focused on implementing alignment training for visual large language models (LLMs), including SFT training, reward model training, and PPO/DPO training. It supports various model architectures and provides datasets for training. The repository also offers benchmark results and installation instructions for users.

MineStudio
MineStudio is a simple and efficient Minecraft development kit for AI research. It contains tools and APIs for developing Minecraft AI agents, including a customizable simulator, trajectory data structure, policy models, offline and online training pipelines, inference framework, and benchmarking automation. The repository is under development and welcomes contributions and suggestions.

AutoPatent
AutoPatent is a multi-agent framework designed for automatic patent generation. It challenges large language models to generate full-length patents based on initial drafts. The framework leverages planner, writer, and examiner agents along with PGTree and RRAG to craft lengthy, intricate, and high-quality patent documents. It introduces a new metric, IRR (Inverse Repetition Rate), to measure sentence repetition within patents. The tool aims to streamline the patent generation process by automating the creation of detailed and specialized patent documents.
ProLLM
ProLLM is a framework that leverages Large Language Models to interpret and analyze protein sequences and interactions through natural language processing. It introduces the Protein Chain of Thought (ProCoT) method to transform complex protein interaction data into intuitive prompts, enhancing predictive accuracy by incorporating protein-specific embeddings and fine-tuning on domain-specific datasets.
rllm
rLLM is an open-source framework for post-training language agents via reinforcement learning. With rLLM, you can easily build your custom agents and environments, train them with reinforcement learning, and deploy them for real-world workloads. The framework provides tools for training coding models, software engineering agents, and language agents using reinforcement learning techniques. It supports various models of different sizes and capabilities, enabling users to achieve state-of-the-art performance in coding and language-related tasks. rLLM is designed to be user-friendly, scalable, and efficient for training and deploying language agents in diverse applications.
TornadoVM
TornadoVM is a plug-in to OpenJDK and GraalVM that allows programmers to automatically run Java programs on heterogeneous hardware. TornadoVM targets OpenCL, PTX and SPIR-V compatible devices which include multi-core CPUs, dedicated GPUs (Intel, NVIDIA, AMD), integrated GPUs (Intel HD Graphics and ARM Mali), and FPGAs (Intel and Xilinx).
aitviewer
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. It provides a native Python interface for loading and displaying SMPL[-H/-X], MANO, FLAME, STAR, and SUPR sequences in an interactive viewer. Users can render 3D data on top of images, edit SMPL sequences and poses, export screenshots and videos, and utilize a high-performance ModernGL-based rendering pipeline. The tool is designed for easy use and hacking, with features like headless mode, remote mode, animatable camera paths, and a built-in extensible GUI.
LLMRec
LLMRec is a PyTorch implementation for the WSDM 2024 paper 'Large Language Models with Graph Augmentation for Recommendation'. It is a novel framework that enhances recommenders by applying LLM-based graph augmentation strategies to recommendation systems. The tool aims to make the most of content within online platforms to augment interaction graphs by reinforcing u-i interactive edges, enhancing item node attributes, and conducting user node profiling from a natural language perspective.
OpenNARS-for-Applications
OpenNARS-for-Applications is an implementation of a Non-Axiomatic Reasoning System, a general-purpose reasoner that adapts under the Assumption of Insufficient Knowledge and Resources. The system combines the logic and conceptual ideas of OpenNARS, event handling and procedure learning capabilities of ANSNA and 20NAR1, and the control model from ALANN. It is written in C, offers improved reasoning performance, and has been compared with Reinforcement Learning and means-end reasoning approaches. The system has been used in real-world applications such as assisting first responders, real-time traffic surveillance, and experiments with autonomous robots. It has been developed with a pragmatic mindset focusing on effective implementation of existing theory.

slideflow
Slideflow is a deep learning library for digital pathology, offering a user-friendly interface for model development. It is designed for medical researchers and AI enthusiasts, providing an accessible platform for developing state-of-the-art pathology models. Slideflow offers customizable training pipelines, robust slide processing and stain normalization toolkit, support for weakly-supervised or strongly-supervised labels, built-in foundation models, multiple-instance learning, self-supervised learning, generative adversarial networks, explainability tools, layer activation analysis tools, uncertainty quantification, interactive user interface for model deployment, and more. It supports both PyTorch and Tensorflow, with optional support for Libvips for slide reading. Slideflow can be installed via pip, Docker container, or from source, and includes non-commercial add-ons for additional tools and pretrained models. It allows users to create projects, extract tiles from slides, train models, and provides evaluation tools like heatmaps and mosaic maps.
For similar tasks

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.