
aitviewer
A set of tools to visualize and interact with sequences of 3D data.
Stars: 542
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. It provides a native Python interface for loading and displaying SMPL[-H/-X], MANO, FLAME, STAR, and SUPR sequences in an interactive viewer. Users can render 3D data on top of images, edit SMPL sequences and poses, export screenshots and videos, and utilize a high-performance ModernGL-based rendering pipeline. The tool is designed for easy use and hacking, with features like headless mode, remote mode, animatable camera paths, and a built-in extensible GUI.
README:
![]()
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. See the official page at https://eth-ait.github.io/aitviewer for all the details.
Basic Installation:
pip install aitviewer
Note that this does not install the GPU-version of PyTorch automatically. If your environment already contains it, you should be good to go, otherwise install it manually.
Or install locally (if you need to extend or modify code)
git clone [email protected]:eth-ait/aitviewer.git
cd aitviewer
pip install -e .
On macOS with Apple Silicon it is recommended to use PyQt6. Please check this issue for installation instructions.
For more advanced installation and for installing SMPL body models, please refer to the documentation .
- Native Python interface, easy to use and hack.
- Load SMPL[-H/-X] / MANO / FLAME / STAR / SUPR sequences and display them in an interactive viewer.
- Headless mode for server rendering of videos/images.
- Remote mode for non-blocking integration of visualization code.
- Render 3D data on top of images via weak-perspective or OpenCV camera models.
- Animatable camera paths.
- Edit SMPL sequences and poses manually.
- Prebuilt renderable primitives (cylinders, spheres, point clouds, etc).
- Built-in extensible GUI (based on Dear ImGui).
- Export screenshots, videos and turntable views (as mp4/gif)
- High-Performance ModernGL-based rendering pipeline (running at 100fps+ on most laptops).

Display an SMPL T-pose (Requires SMPL models):
from aitviewer.renderables.smpl import SMPLSequence
from aitviewer.viewer import Viewer
if __name__ == '__main__':
v = Viewer()
v.scene.add(SMPLSequence.t_pose())
v.run()A sampling of projects using the aitviewer. Let us know if you want to be added to this list!
- Fan et al., HOLD: Category-agnostic 3D Reconstruction of Interacting Hands and Objects from Video, CVPR 2024
- Braun et al., Physically Plausible Full-Body Hand-Object Interaction Synthesis, 3DV 2024
- Zhang and Christen et al., ArtiGrasp: Physically Plausible Synthesis of Bi-Manual Dexterous Grasping and Articulation, 3DV 2024
- Kaufmann et al., EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild, ICCV 2023
- Shen and Guo et al., X-Avatar: Expressive Human Avatars, CVPR 2023
- Sun et al., TRACE: 5D Temporal Regression of Avatars with Dynamic Cameras in 3D Environments, CVPR 2023
- Fan et al., ARCTIC: A Dataset for Dexterous Bimanual Hand-Object Manipulation, CVPR 2023
- Dong and Guo et al., PINA: Learning a Personalized Implicit Neural Avatar from a Single RGB-D Video Sequence, CVPR 2022
- Dong et al., Shape-aware Multi-Person Pose Estimation from Multi-view Images, ICCV 2021
- Kaufmann et al., EM-POSE: 3D Human Pose Estimation from Sparse Electromagnetic Trackers, ICCV 2021
- Vechev et al., Computational Design of Kinesthetic Garments, Eurographics 2021
- Guo et al., Human Performance Capture from Monocular Video in the Wild, 3DV 2021
If you use this software, please cite it as below.
@software{Kaufmann_Vechev_aitviewer_2022,
author = {Kaufmann, Manuel and Vechev, Velko and Mylonopoulos, Dario},
doi = {10.5281/zenodo.10013305},
month = {7},
title = {{aitviewer}},
url = {https://github.com/eth-ait/aitviewer},
year = {2022}
}
This software was developed by Manuel Kaufmann, Velko Vechev and Dario Mylonopoulos. For questions please create an issue. We welcome and encourage module and feature contributions from the community.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aitviewer
Similar Open Source Tools
aitviewer
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. It provides a native Python interface for loading and displaying SMPL[-H/-X], MANO, FLAME, STAR, and SUPR sequences in an interactive viewer. Users can render 3D data on top of images, edit SMPL sequences and poses, export screenshots and videos, and utilize a high-performance ModernGL-based rendering pipeline. The tool is designed for easy use and hacking, with features like headless mode, remote mode, animatable camera paths, and a built-in extensible GUI.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.

Macaw-LLM
Macaw-LLM is a pioneering multi-modal language modeling tool that seamlessly integrates image, audio, video, and text data. It builds upon CLIP, Whisper, and LLaMA models to process and analyze multi-modal information effectively. The tool boasts features like simple and fast alignment, one-stage instruction fine-tuning, and a new multi-modal instruction dataset. It enables users to align multi-modal features efficiently, encode instructions, and generate responses across different data types.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.
Sarvadnya
Sarvadnya is a repository focused on interfacing custom data using Large Language Models (LLMs) through Proof-of-Concepts (PoCs) like Retrieval Augmented Generation (RAG) and Fine-Tuning. It aims to enable domain adaptation for LLMs to answer on user-specific corpora. The repository also covers topics such as Indic-languages models, 3D World Simulations, Knowledge Graphs Generation, Signal Processing, Drones, UAV Image Processing, and Floor Plan Segmentation. It provides insights into building chatbots of various modalities, preparing videos, and creating content for different platforms like Medium, LinkedIn, and YouTube. The tech stacks involved range from enterprise solutions like Google Doc AI and Microsoft Azure Language AI Services to open-source tools like Langchain and HuggingFace.

HolmesVAD
Holmes-VAD is a framework for unbiased and explainable Video Anomaly Detection using multimodal instructions. It addresses biased detection in challenging events by leveraging precise temporal supervision and rich multimodal instructions. The framework includes a largescale VAD instruction-tuning benchmark, VAD-Instruct50k, created with single-frame annotations and a robust video captioner. It offers accurate anomaly localization and comprehensive explanations through a customized solution for interpretable video anomaly detection.

merlin
Merlin is a groundbreaking model capable of generating natural language responses intricately linked with object trajectories of multiple images. It excels in predicting and reasoning about future events based on initial observations, showcasing unprecedented capability in future prediction and reasoning. Merlin achieves state-of-the-art performance on the Future Reasoning Benchmark and multiple existing multimodal language models benchmarks, demonstrating powerful multi-modal general ability and foresight minds.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.

AgentCPM
AgentCPM is a series of open-source LLM agents jointly developed by THUNLP, Renmin University of China, ModelBest, and the OpenBMB community. It addresses challenges faced by agents in real-world applications such as limited long-horizon capability, autonomy, and generalization. The team focuses on building deep research capabilities for agents, releasing AgentCPM-Explore, a deep-search LLM agent, and AgentCPM-Report, a deep-research LLM agent. AgentCPM-Explore is the first open-source agent model with 4B parameters to appear on widely used long-horizon agent benchmarks. AgentCPM-Report is built on the 8B-parameter base model MiniCPM4.1, autonomously generating long-form reports with extreme performance and minimal footprint, designed for high-privacy scenarios with offline and agile local deployment.

agno
Agno is a lightweight library for building multi-modal Agents. It is designed with core principles of simplicity, uncompromising performance, and agnosticism, allowing users to create blazing fast agents with minimal memory footprint. Agno supports any model, any provider, and any modality, making it a versatile container for AGI. Users can build agents with lightning-fast agent creation, model agnostic capabilities, native support for text, image, audio, and video inputs and outputs, memory management, knowledge stores, structured outputs, and real-time monitoring. The library enables users to create autonomous programs that use language models to solve problems, improve responses, and achieve tasks with varying levels of agency and autonomy.
uccl
UCCL is a command-line utility tool designed to simplify the process of converting Unix-style file paths to Windows-style file paths and vice versa. It provides a convenient way for developers and system administrators to handle file path conversions without the need for manual adjustments. With UCCL, users can easily convert file paths between different operating systems, making it a valuable tool for cross-platform development and file management tasks.

NeMo
NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and PyTorch developers working on Large Language Models (LLMs), Multimodal Models (MMs), Automatic Speech Recognition (ASR), Text to Speech (TTS), and Computer Vision (CV) domains. It is designed to help you efficiently create, customize, and deploy new generative AI models by leveraging existing code and pre-trained model checkpoints.
FedLLM-Bench
FedLLM-Bench is a realistic benchmark for the Federated Learning of Large Language Models community. It includes datasets for federated instruction tuning and preference alignment tasks, exhibiting diversities in language, quality, quantity, instruction, sequence length, embedding, and preference. The repository provides training scripts and code for open-ended evaluation, aiming to facilitate research and development in federated learning of large language models.
For similar tasks
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.
deforum-comfy-nodes
Deforum for ComfyUI is an integration tool designed to enhance the user experience of using ComfyUI. It provides custom nodes that can be added to ComfyUI to improve functionality and workflow. Users can easily install Deforum for ComfyUI by cloning the repository and following the provided instructions. The tool is compatible with Python v3.10 and is recommended to be used within a virtual environment. Contributions to the tool are welcome, and users can join the Discord community for support and discussions.
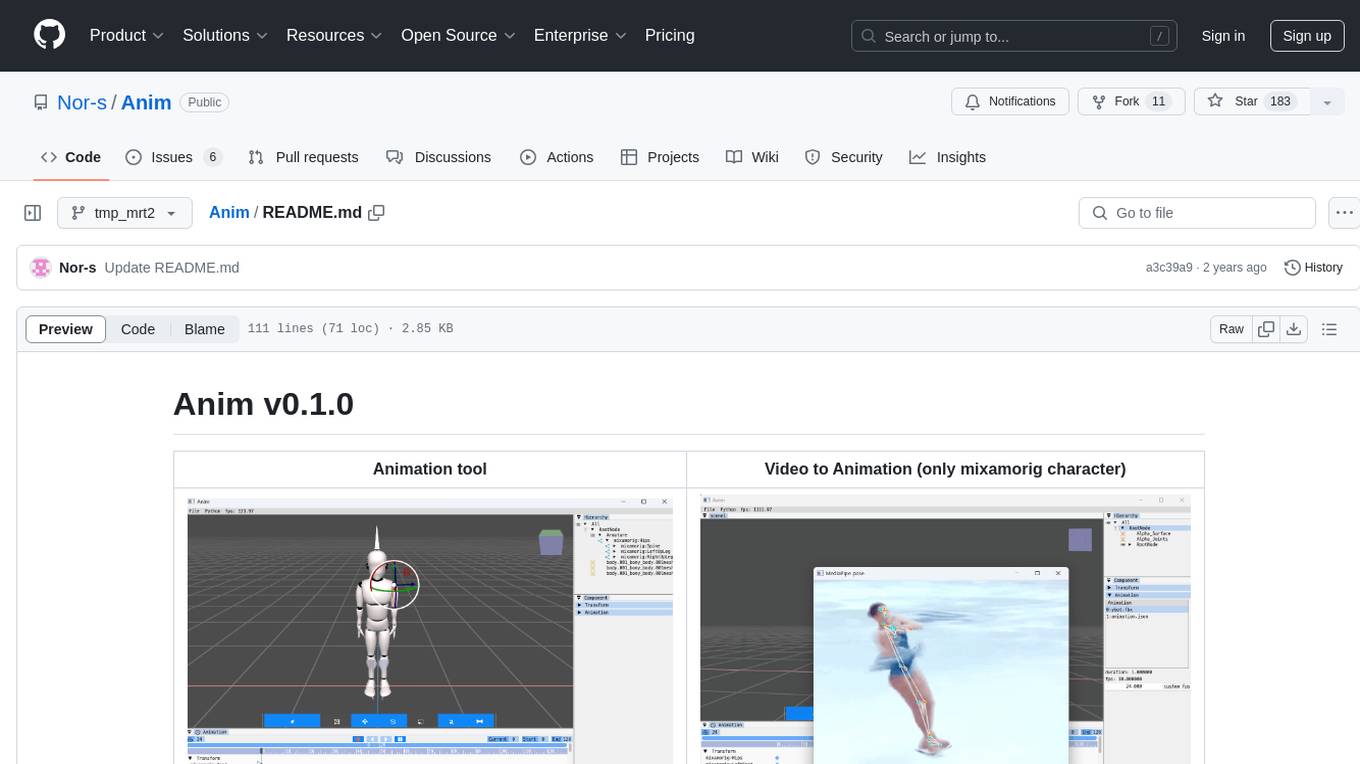
Anim
Anim v0.1.0 is an animation tool that allows users to convert videos to animations using mixamorig characters. It features FK animation editing, object selection, embedded Python support (only on Windows), and the ability to export to glTF and FBX formats. Users can also utilize Mediapipe to create animations. The tool is designed to assist users in creating animations with ease and flexibility.
next-money
Next Money Stripe Starter is a SaaS Starter project that empowers your next project with a stack of Next.js, Prisma, Supabase, Clerk Auth, Resend, React Email, Shadcn/ui, and Stripe. It seamlessly integrates these technologies to accelerate your development and SaaS journey. The project includes frameworks, platforms, UI components, hooks and utilities, code quality tools, and miscellaneous features to enhance the development experience. Created by @koyaguo in 2023 and released under the MIT license.
aitviewer
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. It provides a native Python interface for loading and displaying SMPL[-H/-X], MANO, FLAME, STAR, and SUPR sequences in an interactive viewer. Users can render 3D data on top of images, edit SMPL sequences and poses, export screenshots and videos, and utilize a high-performance ModernGL-based rendering pipeline. The tool is designed for easy use and hacking, with features like headless mode, remote mode, animatable camera paths, and a built-in extensible GUI.
twick
Twick is a comprehensive video editing toolkit built with modern web technologies. It is a monorepo containing multiple packages for video and image manipulation. The repository includes core utilities for media handling, a React-based canvas library for video and image editing, a video visualization and animation toolkit, a React component for video playback and control, timeline management and editing capabilities, a React-based video editor, and example implementations and usage demonstrations. Twick provides detailed API documentation and module information for developers. It offers easy integration with existing projects and allows users to build videos using the Twick Studio. The project follows a comprehensive style guide for naming conventions and code style across all packages.
NanoBanana-AI-Pose-Transfer
NanoBanana-AI-Pose-Transfer is a lightweight tool for transferring poses between images using artificial intelligence. It leverages advanced AI algorithms to accurately map and transfer poses from a source image to a target image. This tool is designed to be user-friendly and efficient, allowing users to easily manipulate and transfer poses for various applications such as image editing, animation, and virtual reality. With NanoBanana-AI-Pose-Transfer, users can seamlessly transfer poses between images with high precision and quality.
For similar jobs
aitviewer
A set of tools to visualize and interact with sequences of 3D data with cross-platform support on Windows, Linux, and macOS. It provides a native Python interface for loading and displaying SMPL[-H/-X], MANO, FLAME, STAR, and SUPR sequences in an interactive viewer. Users can render 3D data on top of images, edit SMPL sequences and poses, export screenshots and videos, and utilize a high-performance ModernGL-based rendering pipeline. The tool is designed for easy use and hacking, with features like headless mode, remote mode, animatable camera paths, and a built-in extensible GUI.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.