
unitxt
🦄 Unitxt is a Python library for enterprise-grade evaluation of AI performance, offering the world's largest catalog of tools and data for end-to-end AI benchmarking
Stars: 209
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.
README:





🦄 Unitxt is a Python library for enterprise-grade evaluation of AI performance, offering the world's largest catalog of tools and data for end-to-end AI benchmarking
- 🌐 Comprehensive: Evaluate text, tables, vision, speech, and code in one unified framework
- 💼 Enterprise-Ready: Battle-tested components with extensive catalog of benchmarks
- 🧠 Model Agnostic: Works with HuggingFace, OpenAI, WatsonX, and custom models
- 🔒 Reproducible: Shareable, modular components ensure consistent results
pip install unitxt# Simple evaluation
unitxt-evaluate \
--tasks "card=cards.mmlu_pro.engineering" \
--model cross_provider \
--model_args "model_name=llama-3-1-8b-instruct" \
--limit 10
# Multi-task evaluation
unitxt-evaluate \
--tasks "card=cards.text2sql.bird+card=cards.mmlu_pro.engineering" \
--model cross_provider \
--model_args "model_name=llama-3-1-8b-instruct,max_tokens=256" \
--split test \
--limit 10 \
--output_path ./results/evaluate_cli \
--log_samples \
--apply_chat_template
# Benchmark evaluation
unitxt-evaluate \
--tasks "benchmarks.tool_calling" \
--model cross_provider \
--model_args "model_name=llama-3-1-8b-instruct,max_tokens=256" \
--split test \
--limit 10 \
--output_path ./results/evaluate_cli \
--log_samples \
--apply_chat_templateLoad thousands of datasets in chat API format, ready for any model:
from unitxt import load_dataset
dataset = load_dataset(
card="cards.gpqa.diamond",
split="test",
format="formats.chat_api",
)
Launch the graphical user interface to explore datasets and benchmarks:
pip install unitxt[ui]
unitxt-explore
Evaluate your own data with any model:
# Import required components
from unitxt import evaluate, create_dataset
from unitxt.blocks import Task, InputOutputTemplate
from unitxt.inference import HFAutoModelInferenceEngine
# Question-answer dataset
data = [
{"question": "What is the capital of Texas?", "answer": "Austin"},
{"question": "What is the color of the sky?", "answer": "Blue"},
]
# Define the task and evaluation metric
task = Task(
input_fields={"question": str},
reference_fields={"answer": str},
prediction_type=str,
metrics=["metrics.accuracy"],
)
# Create a template to format inputs and outputs
template = InputOutputTemplate(
instruction="Answer the following question.",
input_format="{question}",
output_format="{answer}",
postprocessors=["processors.lower_case"],
)
# Prepare the dataset
dataset = create_dataset(
task=task,
template=template,
format="formats.chat_api",
test_set=data,
split="test",
)
# Set up the model (supports Hugging Face, WatsonX, OpenAI, etc.)
model = HFAutoModelInferenceEngine(
model_name="Qwen/Qwen1.5-0.5B-Chat", max_new_tokens=32
)
# Generate predictions and evaluate
predictions = model(dataset)
results = evaluate(predictions=predictions, data=dataset)
# Print results
print("Global Results:\n", results.global_scores.summary)
print("Instance Results:\n", results.instance_scores.summary)Read the contributing guide for details on how to contribute to Unitxt.
If you use Unitxt in your research, please cite our paper:
@inproceedings{bandel-etal-2024-unitxt,
title = "Unitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative {AI}",
author = "Bandel, Elron and
Perlitz, Yotam and
Venezian, Elad and
Friedman, Roni and
Arviv, Ofir and
Orbach, Matan and
Don-Yehiya, Shachar and
Sheinwald, Dafna and
Gera, Ariel and
Choshen, Leshem and
Shmueli-Scheuer, Michal and
Katz, Yoav",
editor = "Chang, Kai-Wei and
Lee, Annie and
Rajani, Nazneen",
booktitle = "Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: System Demonstrations)",
month = jun,
year = "2024",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.naacl-demo.21",
pages = "207--215",
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for unitxt
Similar Open Source Tools
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.

lionagi
LionAGI is a powerful intelligent workflow automation framework that introduces advanced ML models into any existing workflows and data infrastructure. It can interact with almost any model, run interactions in parallel for most models, produce structured pydantic outputs with flexible usage, automate workflow via graph based agents, use advanced prompting techniques, and more. LionAGI aims to provide a centralized agent-managed framework for "ML-powered tools coordination" and to dramatically lower the barrier of entries for creating use-case/domain specific tools. It is designed to be asynchronous only and requires Python 3.10 or higher.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.
funcchain
Funcchain is a Python library that allows you to easily write cognitive systems by leveraging Pydantic models as output schemas and LangChain in the backend. It provides a seamless integration of LLMs into your apps, utilizing OpenAI Functions or LlamaCpp grammars (json-schema-mode) for efficient structured output. Funcchain compiles the Funcchain syntax into LangChain runnables, enabling you to invoke, stream, or batch process your pipelines effortlessly.
notte
Notte is a web browser designed specifically for LLM agents, providing a language-first web navigation experience without the need for DOM/HTML parsing. It transforms websites into structured, navigable maps described in natural language, enabling users to interact with the web using natural language commands. By simplifying browser complexity, Notte allows LLM policies to focus on conversational reasoning and planning, reducing token usage, costs, and latency. The tool supports various language model providers and offers a reinforcement learning style action space and controls for full navigation control.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.

CopilotKit
CopilotKit is an open-source framework for building, deploying, and operating fully custom AI Copilots, including in-app AI chatbots, AI agents, and AI Textareas. It provides a set of components and entry points that allow developers to easily integrate AI capabilities into their applications. CopilotKit is designed to be flexible and extensible, so developers can tailor it to their specific needs. It supports a variety of use cases, including providing app-aware AI chatbots that can interact with the application state and take action, drop-in replacements for textareas with AI-assisted text generation, and in-app agents that can access real-time application context and take action within the application.
VinAI_Translate
VinAI_Translate is a Vietnamese-English Neural Machine Translation System offering state-of-the-art text-to-text translation models for Vietnamese-to-English and English-to-Vietnamese. The system includes pre-trained models with different configurations and parameters, allowing for further fine-tuning. Users can interact with the models through the VinAI Translate system website or the HuggingFace space 'VinAI Translate'. Evaluation scripts are available for assessing the translation quality. The tool can be used in the 'transformers' library for Vietnamese-to-English and English-to-Vietnamese translations, supporting both GPU-based batch translation and CPU-based sequence translation examples.
vecs
vecs is a Python client for managing and querying vector stores in PostgreSQL with the pgvector extension. It allows users to create collections of vectors with associated metadata, index the collections for fast search performance, and query the collections based on specified filters. The tool simplifies the process of working with vector data in a PostgreSQL database, making it easier to store, retrieve, and analyze vector information.
mcp-agent
mcp-agent is a simple, composable framework designed to build agents using the Model Context Protocol. It handles the lifecycle of MCP server connections and implements patterns for building production-ready AI agents in a composable way. The framework also includes OpenAI's Swarm pattern for multi-agent orchestration in a model-agnostic manner, making it the simplest way to build robust agent applications. It is purpose-built for the shared protocol MCP, lightweight, and closer to an agent pattern library than a framework. mcp-agent allows developers to focus on the core business logic of their AI applications by handling mechanics such as server connections, working with LLMs, and supporting external signals like human input.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline

wandb
Weights & Biases (W&B) is a platform that helps users build better machine learning models faster by tracking and visualizing all components of the machine learning pipeline, from datasets to production models. It offers tools for tracking, debugging, evaluating, and monitoring machine learning applications. W&B provides integrations with popular frameworks like PyTorch, TensorFlow/Keras, Hugging Face Transformers, PyTorch Lightning, XGBoost, and Sci-Kit Learn. Users can easily log metrics, visualize performance, and compare experiments using W&B. The platform also supports hosting options in the cloud or on private infrastructure, making it versatile for various deployment needs.
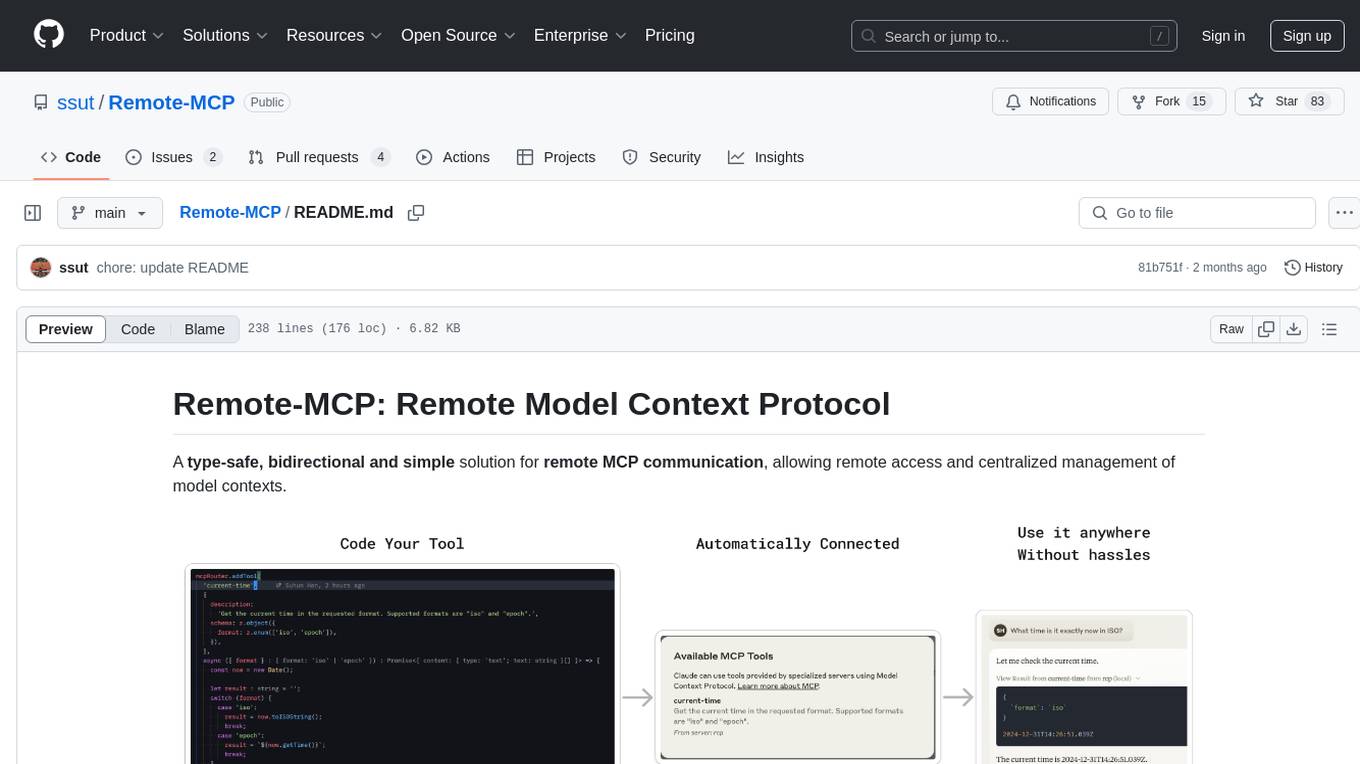
Remote-MCP
Remote-MCP is a type-safe, bidirectional, and simple solution for remote MCP communication, enabling remote access and centralized management of model contexts. It provides a bridge for immediate remote access to a remote MCP server from a local MCP client, without waiting for future official implementations. The repository contains client and server libraries for creating and connecting to remotely accessible MCP services. The core features include basic type-safe client/server communication, MCP command/tool/prompt support, custom headers, and ongoing work on crash-safe handling and event subscription system.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.
For similar tasks
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.
files-to-prompt
files-to-prompt is a tool that concatenates a directory full of files into a single prompt for use with Language Models (LLMs). It allows users to provide the path to one or more files or directories for processing, outputting the contents of each file with relative paths and separators. The tool offers options to include hidden files, ignore specific patterns, and exclude files specified in .gitignore. It is designed to streamline the process of preparing text data for LLMs by simplifying file concatenation and customization.
For similar jobs

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

dolma
Dolma is a dataset and toolkit for curating large datasets for (pre)-training ML models. The dataset consists of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. The toolkit provides high-performance, portable, and extensible tools for processing, tagging, and deduplicating documents. Key features of the toolkit include built-in taggers, fast deduplication, and cloud support.
unitxt
Unitxt is a customizable library for textual data preparation and evaluation tailored to generative language models. It natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).
multimodal_cognitive_ai
The multimodal cognitive AI repository focuses on research work related to multimodal cognitive artificial intelligence. It explores the integration of multiple modes of data such as text, images, and audio to enhance AI systems' cognitive capabilities. The repository likely contains code, datasets, and research papers related to multimodal AI applications, including natural language processing, computer vision, and audio processing. Researchers and developers interested in advancing AI systems' understanding of multimodal data can find valuable resources and insights in this repository.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.