
ChatLaw
ChatLaw:A Powerful LLM Tailored for Chinese Legal. 中文法律大模型
Stars: 7038
ChatLaw is an open-source legal large language model tailored for Chinese legal scenarios. It aims to combine LLM and knowledge bases to provide solutions for legal scenarios. The models include ChatLaw-13B and ChatLaw-33B, trained on various legal texts to construct dialogue data. The project focuses on improving logical reasoning abilities and plans to train models with parameters exceeding 30B for better performance. The dataset consists of forum posts, news, legal texts, judicial interpretations, legal consultations, exam questions, and court judgments, cleaned and enhanced to create dialogue data. The tool is designed to assist in legal tasks requiring complex logical reasoning, with a focus on accuracy and reliability.
README:
Chatlaw: A Large Language Model-based Multi-Agent Legal Assistant Enhanced by Knowledge Graph and Mixture-of-Experts.
-
Latest Version: Based on the InternLM architecture with a 4x7B Mixture of Experts (MoE) design.
-
Specialization: Tailored for Chinese legal language processing、
- Demo Version: Built on the Ziya-LLaMA-13B-v1 model.
- Performance: Excels in general Chinese tasks but requires a larger model for complex legal QA.
- Demo Version: Utilizes the Anima-33B model.
- Enhancements: Improved logical reasoning over the 13B version.
- Challenge: Occasionally defaults to English responses due to limited Chinese training data in Anima.
- Function: A text similarity model trained on 93,000 court case decisions.
- Capability: Matches user queries to pertinent legal statutes, offering contextual relevance.
- Example: Connects questions about loan repayment to the appropriate sections of contract law.
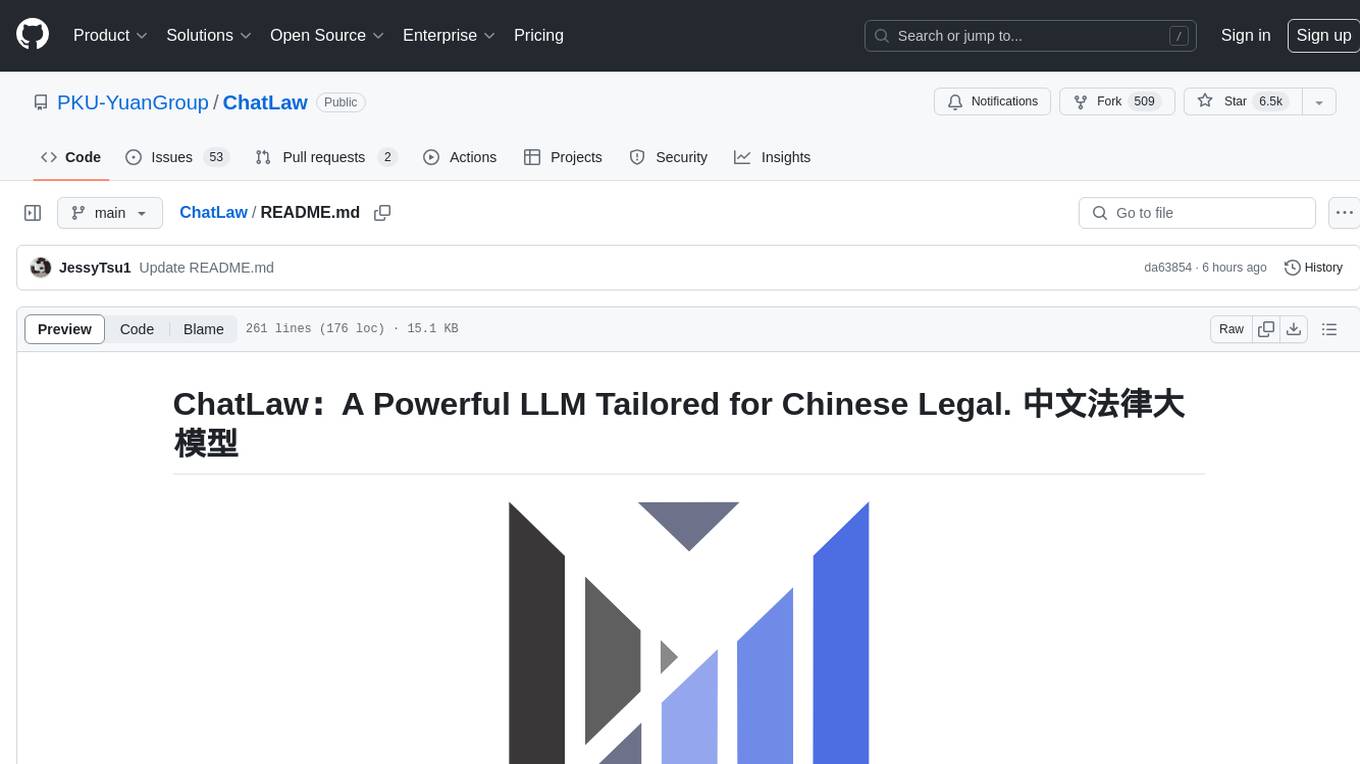
AI legal assistants, powered by Large Language Models (LLMs), offer accessible legal consulting. However, the risk of hallucination in AI responses is a concern. This paper introduces ChatLaw, an innovative assistant that employs a Mixture-of-Experts (MoE) model and a multi-agent system to enhance reliability and accuracy in AI legal services. By integrating knowledge graphs and artificial screening, we've created a high-quality legal dataset for training the MoE model. This model leverages various experts to address a range of legal issues, optimizing legal response accuracy. Standardized Operating Procedures (SOPs), inspired by law firm workflows, significantly minimize errors and hallucinations.
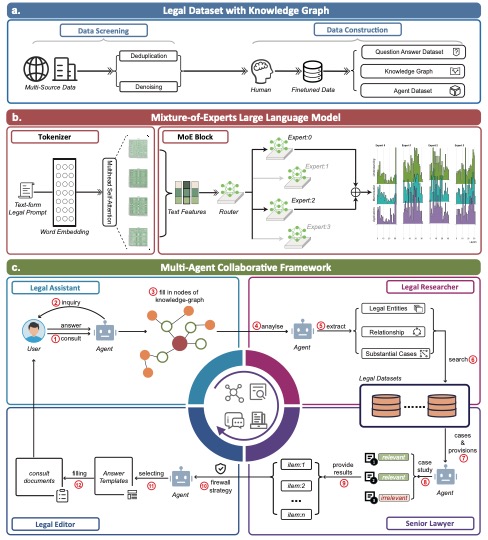
Our MoE model outperforms GPT-4 in the Lawbench and Unified Qualification Exam for Legal Professionals, achieving a 7.73% higher accuracy and an 11-point lead, respectively. It also surpasses other models in real-case consultations across multiple dimensions, showcasing robust legal consultation capabilities.
The diagram below illustrates the collaborative process of multiple agents in providing legal consultation services, exemplified by a divorce consultation. The process involves gathering information, legal research, comprehensive advice, and culminates in a detailed Legal Consultation Report.

(a) Our legal dataset covers a diverse range of tasks, from case classification to public opinion analysis.
(b) ChatLaw demonstrates superior performance across multiple legal categories compared to other models.
(c) ChatLaw consistently outperforms other models in legal cognitive tasks, as shown in the Lawbench comparison.
(d) ChatLaw maintains high performance across five years on the Unified Qualification Exam for Legal Professionals.
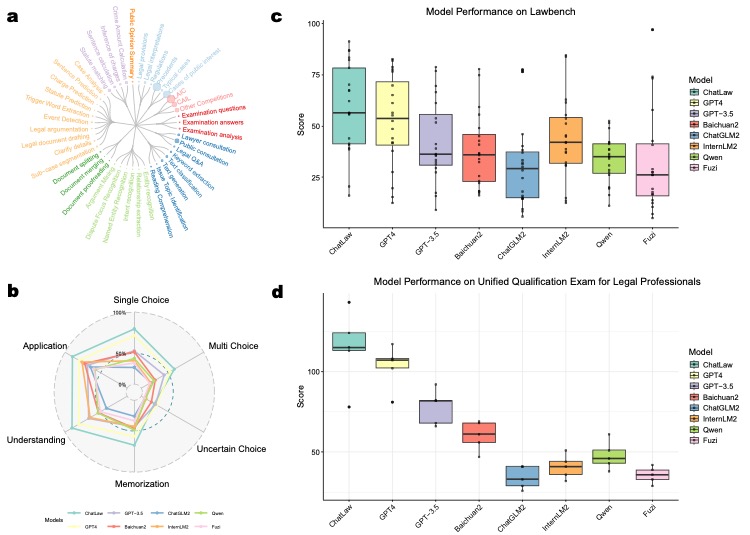
(a) Legal consultation quality is assessed based on Completeness, Logic, Correctness, Language Quality, Guidance, and Authority.
(b) ChatLaw achieves the highest scores across all criteria, particularly excelling in Completeness, Guidance, and Authority.
(c) ChatLaw shows a higher win rate compared to other models, indicating superior capability in providing high-quality legal consultations.

Find the model at: ChatLaw2-MoE
@misc{cui2024chatlaw,
title={Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model},
author={Jiaxi Cui and Munan Ning and Zongjian Li and Bohua Chen and Yang Yan and Hao Li and Bin Ling and Yonghong Tian and Li Yuan},
year={2024},
eprint={2306.16092},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{ChatLaw,
author={Jiaxi Cui and Zongjian Li and Yang Yan and Bohua Chen and Li Yuan},
title={ChatLaw},
year={2023},
publisher={GitHub},
journal={GitHub repository},
howpublished={\url{https://github.com/PKU-YuanGroup/ChatLaw}},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ChatLaw
Similar Open Source Tools
ChatLaw
ChatLaw is an open-source legal large language model tailored for Chinese legal scenarios. It aims to combine LLM and knowledge bases to provide solutions for legal scenarios. The models include ChatLaw-13B and ChatLaw-33B, trained on various legal texts to construct dialogue data. The project focuses on improving logical reasoning abilities and plans to train models with parameters exceeding 30B for better performance. The dataset consists of forum posts, news, legal texts, judicial interpretations, legal consultations, exam questions, and court judgments, cleaned and enhanced to create dialogue data. The tool is designed to assist in legal tasks requiring complex logical reasoning, with a focus on accuracy and reliability.

dash-infer
DashInfer is a C++ runtime tool designed to deliver production-level implementations highly optimized for various hardware architectures, including x86 and ARMv9. It supports Continuous Batching and NUMA-Aware capabilities for CPU, and can fully utilize modern server-grade CPUs to host large language models (LLMs) up to 14B in size. With lightweight architecture, high precision, support for mainstream open-source LLMs, post-training quantization, optimized computation kernels, NUMA-aware design, and multi-language API interfaces, DashInfer provides a versatile solution for efficient inference tasks. It supports x86 CPUs with AVX2 instruction set and ARMv9 CPUs with SVE instruction set, along with various data types like FP32, BF16, and InstantQuant. DashInfer also offers single-NUMA and multi-NUMA architectures for model inference, with detailed performance tests and inference accuracy evaluations available. The tool is supported on mainstream Linux server operating systems and provides documentation and examples for easy integration and usage.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

k2
K2 (GeoLLaMA) is a large language model for geoscience, trained on geoscience literature and fine-tuned with knowledge-intensive instruction data. It outperforms baseline models on objective and subjective tasks. The repository provides K2 weights, core data of GeoSignal, GeoBench benchmark, and code for further pretraining and instruction tuning. The model is available on Hugging Face for use. The project aims to create larger and more powerful geoscience language models in the future.
Mooncake
Mooncake is a serving platform for Kimi, a leading LLM service provided by Moonshot AI. It features a KVCache-centric disaggregated architecture that separates prefill and decoding clusters, leveraging underutilized CPU, DRAM, and SSD resources of the GPU cluster. Mooncake's scheduler balances throughput and latency-related SLOs, with a prediction-based early rejection policy for highly overloaded scenarios. It excels in long-context scenarios, achieving up to a 525% increase in throughput while handling 75% more requests under real workloads.
learn-agentic-ai
Learn Agentic AI is a repository that is part of the Panaversity Certified Agentic and Robotic AI Engineer program. It covers AI-201 and AI-202 courses, providing fundamentals and advanced knowledge in Agentic AI. The repository includes video playlists, projects, and project submission guidelines for students to enhance their understanding and skills in the field of AI engineering.


Reflection_Tuning
Reflection-Tuning is a project focused on improving the quality of instruction-tuning data through a reflection-based method. It introduces Selective Reflection-Tuning, where the student model can decide whether to accept the improvements made by the teacher model. The project aims to generate high-quality instruction-response pairs by defining specific criteria for the oracle model to follow and respond to. It also evaluates the efficacy and relevance of instruction-response pairs using the r-IFD metric. The project provides code for reflection and selection processes, along with data and model weights for both V1 and V2 methods.

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.
FinRobot
FinRobot is an open-source AI agent platform designed for financial applications using large language models. It transcends the scope of FinGPT, offering a comprehensive solution that integrates a diverse array of AI technologies. The platform's versatility and adaptability cater to the multifaceted needs of the financial industry. FinRobot's ecosystem is organized into four layers, including Financial AI Agents Layer, Financial LLMs Algorithms Layer, LLMOps and DataOps Layers, and Multi-source LLM Foundation Models Layer. The platform's agent workflow involves Perception, Brain, and Action modules to capture, process, and execute financial data and insights. The Smart Scheduler optimizes model diversity and selection for tasks, managed by components like Director Agent, Agent Registration, Agent Adaptor, and Task Manager. The tool provides a structured file organization with subfolders for agents, data sources, and functional modules, along with installation instructions and hands-on tutorials.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
ProLLM
ProLLM is a framework that leverages Large Language Models to interpret and analyze protein sequences and interactions through natural language processing. It introduces the Protein Chain of Thought (ProCoT) method to transform complex protein interaction data into intuitive prompts, enhancing predictive accuracy by incorporating protein-specific embeddings and fine-tuning on domain-specific datasets.
oat
Oat is a simple and efficient framework for running online LLM alignment algorithms. It implements a distributed Actor-Learner-Oracle architecture, with components optimized using state-of-the-art tools. Oat simplifies the experimental pipeline of LLM alignment by serving an Oracle online for preference data labeling and model evaluation. It provides a variety of oracles for simulating feedback and supports verifiable rewards. Oat's modular structure allows for easy inheritance and modification of classes, enabling rapid prototyping and experimentation with new algorithms. The framework implements cutting-edge online algorithms like PPO for math reasoning and various online exploration algorithms.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.

Macaw-LLM
Macaw-LLM is a pioneering multi-modal language modeling tool that seamlessly integrates image, audio, video, and text data. It builds upon CLIP, Whisper, and LLaMA models to process and analyze multi-modal information effectively. The tool boasts features like simple and fast alignment, one-stage instruction fine-tuning, and a new multi-modal instruction dataset. It enables users to align multi-modal features efficiently, encode instructions, and generate responses across different data types.
For similar tasks
ChatLaw
ChatLaw is an open-source legal large language model tailored for Chinese legal scenarios. It aims to combine LLM and knowledge bases to provide solutions for legal scenarios. The models include ChatLaw-13B and ChatLaw-33B, trained on various legal texts to construct dialogue data. The project focuses on improving logical reasoning abilities and plans to train models with parameters exceeding 30B for better performance. The dataset consists of forum posts, news, legal texts, judicial interpretations, legal consultations, exam questions, and court judgments, cleaned and enhanced to create dialogue data. The tool is designed to assist in legal tasks requiring complex logical reasoning, with a focus on accuracy and reliability.
lawyer-llama
Lawyer LLaMA is a large language model that has been specifically trained on legal data, including Chinese laws, regulations, and case documents. It has been fine-tuned on a large dataset of legal questions and answers, enabling it to understand and respond to legal inquiries in a comprehensive and informative manner. Lawyer LLaMA is designed to assist legal professionals and individuals with a variety of law-related tasks, including: * **Legal research:** Quickly and efficiently search through vast amounts of legal information to find relevant laws, regulations, and case precedents. * **Legal analysis:** Analyze legal issues, identify potential legal risks, and provide insights on how to proceed. * **Document drafting:** Draft legal documents, such as contracts, pleadings, and legal opinions, with accuracy and precision. * **Legal advice:** Provide general legal advice and guidance on a wide range of legal matters, helping users understand their rights and options. Lawyer LLaMA is a powerful tool that can significantly enhance the efficiency and effectiveness of legal research, analysis, and decision-making. It is an invaluable resource for lawyers, paralegals, law students, and anyone else who needs to navigate the complexities of the legal system.
For similar jobs
LLM-and-Law
This repository is dedicated to summarizing papers related to large language models with the field of law. It includes applications of large language models in legal tasks, legal agents, legal problems of large language models, data resources for large language models in law, law LLMs, and evaluation of large language models in the legal domain.
ChatLaw
ChatLaw is an open-source legal large language model tailored for Chinese legal scenarios. It aims to combine LLM and knowledge bases to provide solutions for legal scenarios. The models include ChatLaw-13B and ChatLaw-33B, trained on various legal texts to construct dialogue data. The project focuses on improving logical reasoning abilities and plans to train models with parameters exceeding 30B for better performance. The dataset consists of forum posts, news, legal texts, judicial interpretations, legal consultations, exam questions, and court judgments, cleaned and enhanced to create dialogue data. The tool is designed to assist in legal tasks requiring complex logical reasoning, with a focus on accuracy and reliability.
Free-LLM-Collection
Free-LLM-Collection is a curated list of free resources for mastering the Legal Language Model (LLM) technology. It includes datasets, research papers, tutorials, and tools to help individuals learn and work with LLM models. The repository aims to provide a comprehensive collection of materials to support researchers, developers, and enthusiasts interested in exploring and leveraging LLM technology for various applications in the legal domain.
vocotype-cli
VocoType is a free desktop voice input method designed for professionals who value privacy and efficiency. All recognition is done locally, ensuring offline operation and no data upload. The CLI open-source version of the VocoType core engine on GitHub is mainly targeted at developers.
lawyer-llama
Lawyer LLaMA is a large language model that has been specifically trained on legal data, including Chinese laws, regulations, and case documents. It has been fine-tuned on a large dataset of legal questions and answers, enabling it to understand and respond to legal inquiries in a comprehensive and informative manner. Lawyer LLaMA is designed to assist legal professionals and individuals with a variety of law-related tasks, including: * **Legal research:** Quickly and efficiently search through vast amounts of legal information to find relevant laws, regulations, and case precedents. * **Legal analysis:** Analyze legal issues, identify potential legal risks, and provide insights on how to proceed. * **Document drafting:** Draft legal documents, such as contracts, pleadings, and legal opinions, with accuracy and precision. * **Legal advice:** Provide general legal advice and guidance on a wide range of legal matters, helping users understand their rights and options. Lawyer LLaMA is a powerful tool that can significantly enhance the efficiency and effectiveness of legal research, analysis, and decision-making. It is an invaluable resource for lawyers, paralegals, law students, and anyone else who needs to navigate the complexities of the legal system.
lawglance
LawGlance is an AI-powered legal assistant that aims to bridge the gap between people and legal access. It is a free, open-source initiative designed to provide quick and accurate legal support tailored to individual needs. The project covers various laws, with plans for international expansion in the future. LawGlance utilizes AI-powered Retriever-Augmented Generation (RAG) to deliver legal guidance accessible to both laypersons and professionals. The tool is developed with support from mentors and experts at Data Science Academy and Curvelogics.
DISC-LawLLM
DISC-LawLLM is a legal domain large model that aims to provide professional, intelligent, and comprehensive **legal services** to users. It is developed and open-sourced by the Data Intelligence and Social Computing Lab (Fudan-DISC) at Fudan University.
llm-course
The llm-course repository is a collection of resources and materials for a course on Legal and Legislative Drafting. It includes lecture notes, assignments, readings, and other educational materials to help students understand the principles and practices of drafting legal documents. The course covers topics such as statutory interpretation, legal drafting techniques, and the role of legislation in the legal system. Whether you are a law student, legal professional, or someone interested in understanding the intricacies of legal language, this repository provides valuable insights and resources to enhance your knowledge and skills in legal drafting.