
Awesome-Neuro-Symbolic-Learning-with-LLM
✨✨Latest Advances on Neuro-Symbolic Learning in the era of Large Language Models
Stars: 53
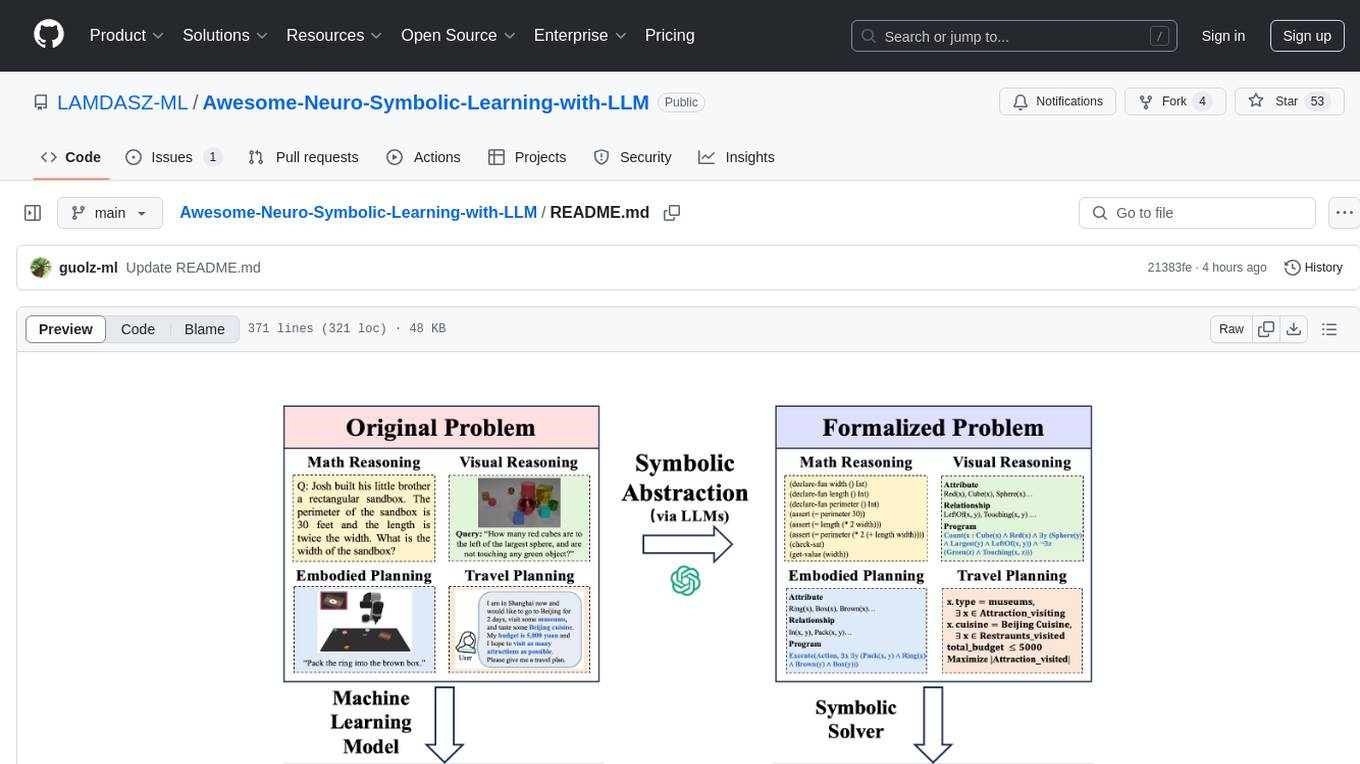
The Awesome-Neuro-Symbolic-Learning-with-LLM repository is a curated collection of papers and resources focusing on improving reasoning and planning capabilities of Large Language Models (LLMs) and Multi-Modal Large Language Models (MLLMs) through neuro-symbolic learning. It covers a wide range of topics such as neuro-symbolic visual reasoning, program synthesis, logical reasoning, mathematical reasoning, code generation, visual reasoning, geometric reasoning, classical planning, game AI planning, robotic planning, AI agent planning, and more. The repository provides a comprehensive overview of tutorials, workshops, talks, surveys, papers, datasets, and benchmarks related to neuro-symbolic learning with LLMs and MLLMs.
README:

✨✨ Curated collection of papers and resources on latest advances on improving reasoning and planning abilities of LLM/MLLMs with neuro-symbolic learning
🗂️ Table of Contents
- Neuro-Symbolic Visual Reasoning and Program Synthesis Tutorials in CVPR 2020
- Neuro-Symbolic Methods for Language and Vision Tutorials in AAAI 2022
- AAAI 2022 Tutorial on AI Planning: Theory and Practice Tutorials in AAAI 2022
- Advances in Neuro Symbolic Reasoning and Learning Tutorials in AAAI 2023
- Neuro-Symbolic Approaches: Large Language Models + Tool Use Tutorials in ACL 2023
- Neuro-Symbolic Generative Models Workshop in ICLR 2023
- Neuro-Symbolic Learning and Reasoning in the Era of Large Language Models Workshop in AAAI 2024
- Neuro-Symbolic Concepts for Robotic Manipulation Talk given by Jiayuan Mao [Video]
- Building General-Purpose Robots with Compositional Action Abstractions Talk given by Jiayuan Mao
- Summer School on Neurosymbolic Programming
- MIT 6.S191: Neuro-Symbolic AI Talk given by David Cox [Video]
- NeuroSymbolic Programming [Slides]
- LLM Reasoning: Key Ideas and Limitations Talk give by Denny Zhou
- Inference-Time Techniques for LLM Reasoning Talk given by Xinyun Chen
- Neurosymbolic Reasoning for Large Language Models Neuro-Symbolic AI Summer School in UCLA, 2024
- Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
- LLM Post-Training: A Deep Dive into Reasoning Large Language Models
- A Survey on Post-training of Large Language Models
- Reasoning Language Models: A Blueprint
- Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
- Logical Reasoning in Large Language Models: A Survey
- From System 1 to System 2: A Survey of Reasoning Large Language Models
- A Survey on LLM Inference-Time Self-Improvement
- Empowering LLMs with Logical Reasoning: A Comprehensive Survey
- Advancing Reasoning in Large Language Models: Promising Methods and Approaches
- A Survey on Deep Learning for Theorem Proving
- A Survey of Mathematical Reasoning in the Era of Multi-Modal Large Language Model: Benchmark, Method & Challenges
- Multi-Modal Chain-of-Thought Reasoning:A Comprehensive Survey
- Exploring the Reasoning Abilities of Multi-Modal Large Language Models (MLLMs): A Comprehensive Survey on Emerging Trends in Multimodal Reasoning
- A Survey on Large Language Models for Automated Planning
- A Survey of Optimization-based Task and Motion Planning: From Classical To Learning Approaches
- A Survey on Large Language Model based Autonomous Agents
- Understanding the planning of LLM agents: A survey
- Introduction to AI Planning
- A Survey on Neural-symbolic Learning Systems
- Towards Cognitive AI Systems: a Survey and Prospective on Neuro-Symbolic AI
- Bridging the Gap: Representation Spaces in Neuro-Symbolic AI
- Neuro-Symbolic AI: The 3rd Wave
- Neuro-Symbolic AI and its Taxonomy: A Survey
- The third AI summer: AAAI Robert S. Engelmore Memorial Lecture
- NeuroSymbolic AI - Why, What, and How
- From Statistical Relational to Neuro-Symbolic Artificial Intelligence: a Survey
- Neuro-Symbolic Artificial Intelligence: Current Trends
- Neuro-Symbolic Reinforcement Learning and Planning: A Survey
- A Review on Neuro-symbolic AI Improvements to Natural Language Processing
- Survey on Applications of NeuroSymbolic Artificial Intelligence
- Overview of Neuro-Symbolic Integration Frameworks
| Title | Venue | Date | Domain | Code |
|---|---|---|---|---|
|
AMR-DA: Data Augmentation by Abstract Meaning Representation |
ACL | 2022 | Logic Reasoning | Github |
|
Abstract Meaning Representation-Based Logic-Driven Data Augmentation for Logical Reasoning |
ACL | 2024 | Logic Reasoning | Github |
|
Neuro-Symbolic Data Generation for Math Reasoning |
NeurIPS | 2024 | Math Reasoning | - |
|
LawGPT: Knowledge-Guided Data Generation and Its Application to Legal LLM |
SCI-FM Workshop @ ICLR | 2025 | Legal Reasoning | Github |
|
AlphaIntegrator: Transformer Action Search for Symbolic Integration Proofs |
Arxiv | 2024 | Theorem Proving | - |
|
Large Language Models Meet Symbolic Provers for Logical Reasoning Evaluation |
ICLR | 2025 | Logic Reasoning | Github |
| Title | Venue | Date | Domain | Code |
|---|---|---|---|---|
|
PAL: Program-aided Language Models |
ICML | 2023 | Reasoning | Github |
|
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks |
TMLR | 2023 | Math Reasoning | Github |
|
Binding Language Models in Symbolic Languages |
ICLR | 2023 | Reasoning | Github |
| Chain of Code: Reasoning with a Language Model-Augmented Code Emulator | ICML | 2024 | Reasoning | Github |
| CODE4STRUCT: Code Generation for Few-Shot Event Structure Prediction | ACL | 2023 | Reasoning | Github |
| MathPrompter: Mathematical Reasoning using Large Language Models | ACL | 2023 | Math Reasoning | Github |
|
Natural Language Embedded Programs for Hybrid Language Symbolic Reasoning |
ACL | 2024 | Reasoning | Github |
| Towards Better Understanding of Program-of-Thought Reasoning in Cross-Lingual and Multilingual Environments | Arxiv | 2025 | Reasoning | - |
|
Code as Policies: Language Model Programs for Embodied Control |
Arxiv | 2023 | Robotics | Github |
| Title | Venue | Date | Domain | Code |
|---|---|---|---|---|
|
Neuro-Symbolic Visual Reasoning: Disentangling “Visual” from “Reasoning” |
ICML | 2020 | Visual Reasoning | Github |
|
JARVIS: A Neuro-Symbolic Commonsense Reasoning Framework for Conversational Embodied Agents |
Arxiv | 2022 | Robotics | - |
|
What's Left? Concept Grounding with Logic-Enhanced Foundation Models |
NeurIPS | 2023 | Visual Reasoning | Github |
|
Take A Step Back: Rethinking the Two Stages in Visual Reasoning |
ECCV | 2024 | Visual Reasoning | Github |
|
DiLA: Enhancing LLM Tool Learning with Differential Logic Layer |
Arxiv | 2024 | Reasoning | - |
|
Mastering Symbolic Operations: Augmenting Language Models with Compiled Neural Networks |
ICLR | 2024 | Reasoning | Github |
|
Empowering Language Models with Knowledge Graph Reasoning for Question Answering |
EMNLP | 2022 | Reasoning | - |
|
Neuro-symbolic Training for Spatial Reasoning over Natural Language |
Arxiv | 2025 | Spatial Reasoning | Github |
|
NeSyCoCo: A Neuro-Symbolic Concept Composer for Compositional Generalization |
Arxiv | 2024 | Visual Reasoning | Github |
| Title | Venue | Date | Domain | Code |
|---|---|---|---|---|
|
CoTran: An LLM-based Code Translator using Reinforcement Learning with Feedback from Compiler and Symbolic Execution |
ECAI | 2024 | Code Generation | - |
|
Position: LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks |
ICML | 2024 | Planning | - |
|
RLSF: Reinforcement Learning via Symbolic Feedback |
Arxiv | 2025 | Reasoning | Github |
|
Rule Based Rewards for Language Model Safety |
NeurIPS | 2024 | - |
- GSM8K, MATH, AIME, OlympiadBench, MiniF2F, GSM Symbolic, MWPBench, AMC, AddSub, MathQA, FIMO, TRIGO, U-MATH, Mario, MultiArith, CHAMP, ARB, LeanDojo, LISA, PISA, TheoremQA, FrontierMath, Functional, TABMWP, SCIBENCH, MultiHiertt, ChartQA
- LogicGame, LogiQA, LogiQA-v2.0, PrOntoQA, ProofWriter, BigBench, FOLIO, AbductionRules, ARC Challenge, WANLI, CLUTRR, Adversarial NLI, Adversarial ARCT
- Visual Sudoku, CLEVR Dataset, GQA Dataset, VQA & VQA v2.0, Flickr30k entities, DAQUAR, Visual Genome, Visual7W, COCO-QA, TDIUC, SHAPES, VQA-Rephrasings, VQA P2, VQA-HAT, VQA-X, VQA-E, TallyQA, ST-VQA, Text-VQA, FVQA, OK-VQA
- Atari 100k, Procgen, Gym Retro, Malmö, Obstacle Tower, Torcs, DeepMind Lab, Hard Eight, DeepMind Control, VizDoom, Pommerman, Multiagent emergence, Google Research Football, Neural MMOs, StarCraft II, PySC2, Fever Basketball
- Mini-Behavior, CLIPort Dataset, ALFworld, VirtualHome, RocoBench, Behavior, SMART-LLM, PPNL, Robotouille
- WebArena, OSWorld, API-Bank, TravelPlanner, ChinaTravel, TaskBench, WebShop, AgentBench, AgentGym, AgentBoard, GAIA, MINT
- RSbench: A Neuro-Symbolic Benchmark Suite for Concept Quality and Reasoning Shortcuts
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-Neuro-Symbolic-Learning-with-LLM
Similar Open Source Tools
Awesome-Neuro-Symbolic-Learning-with-LLM
The Awesome-Neuro-Symbolic-Learning-with-LLM repository is a curated collection of papers and resources focusing on improving reasoning and planning capabilities of Large Language Models (LLMs) and Multi-Modal Large Language Models (MLLMs) through neuro-symbolic learning. It covers a wide range of topics such as neuro-symbolic visual reasoning, program synthesis, logical reasoning, mathematical reasoning, code generation, visual reasoning, geometric reasoning, classical planning, game AI planning, robotic planning, AI agent planning, and more. The repository provides a comprehensive overview of tutorials, workshops, talks, surveys, papers, datasets, and benchmarks related to neuro-symbolic learning with LLMs and MLLMs.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.
AI-For-Beginners
AI-For-Beginners is a comprehensive 12-week, 24-lesson curriculum designed by experts at Microsoft to introduce beginners to the world of Artificial Intelligence (AI). The curriculum covers various topics such as Symbolic AI, Neural Networks, Computer Vision, Natural Language Processing, Genetic Algorithms, and Multi-Agent Systems. It includes hands-on lessons, quizzes, and labs using popular frameworks like TensorFlow and PyTorch. The focus is on providing a foundational understanding of AI concepts and principles, making it an ideal starting point for individuals interested in AI.
unoplat-code-confluence
Unoplat-CodeConfluence is a universal code context engine that aims to extract, understand, and provide precise code context across repositories tied through domains. It combines deterministic code grammar with state-of-the-art LLM pipelines to achieve human-like understanding of codebases in minutes. The tool offers smart summarization, graph-based embedding, enhanced onboarding, graph-based intelligence, deep dependency insights, and seamless integration with existing development tools and workflows. It provides a precise context API for knowledge engine and AI coding assistants, enabling reliable code understanding through bottom-up code summarization, graph-based querying, and deep package and dependency analysis.
LLMs-Planning
This repository contains code for three papers related to evaluating large language models on planning and reasoning about change. It includes benchmarking tools and analysis for assessing the planning abilities of large language models. The latest addition evaluates and enhances the planning and scheduling capabilities of a specific language reasoning model. The repository provides a static test set leaderboard showcasing model performance on various tasks with natural language and planning domain prompts.
CS7320-AI
CS7320-AI is a repository containing lecture materials, simple Python code examples, and assignments for the course CS 5/7320 Artificial Intelligence. The code examples cover various chapters of the textbook 'Artificial Intelligence: A Modern Approach' by Russell and Norvig. The repository focuses on basic AI concepts rather than advanced implementation techniques. It includes HOWTO guides for installing Python, working on assignments, and using AI with Python.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
awesome-generative-ai-data-scientist
A curated list of 50+ resources to help you become a Generative AI Data Scientist. This repository includes resources on building GenAI applications with Large Language Models (LLMs), and deploying LLMs and GenAI with Cloud-based solutions.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.
rubra
Rubra is a collection of open-weight large language models enhanced with tool-calling capability. It allows users to call user-defined external tools in a deterministic manner while reasoning and chatting, making it ideal for agentic use cases. The models are further post-trained to teach instruct-tuned models new skills and mitigate catastrophic forgetting. Rubra extends popular inferencing projects for easy use, enabling users to run the models easily.

LLaVA-MORE
LLaVA-MORE is a new family of Multimodal Language Models (MLLMs) that integrates recent language models with diverse visual backbones. The repository provides a unified training protocol for fair comparisons across all architectures and releases training code and scripts for distributed training. It aims to enhance Multimodal LLM performance and offers various models for different tasks. Users can explore different visual backbones like SigLIP and methods for managing image resolutions (S2) to improve the connection between images and language. The repository is a starting point for expanding the study of Multimodal LLMs and enhancing new features in the field.

HuatuoGPT-II
HuatuoGPT2 is an innovative domain-adapted medical large language model that excels in medical knowledge and dialogue proficiency. It showcases state-of-the-art performance in various medical benchmarks, surpassing GPT-4 in expert evaluations and fresh medical licensing exams. The open-source release includes HuatuoGPT2 models in 7B, 13B, and 34B versions, training code for one-stage adaptation, partial pre-training and fine-tuning instructions, and evaluation methods for medical response capabilities and professional pharmacist exams. The tool aims to enhance LLM capabilities in the Chinese medical field through open-source principles.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
For similar tasks

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.