
Awesome-AIGC-3D
A curated list of awesome AIGC 3D papers
Stars: 516
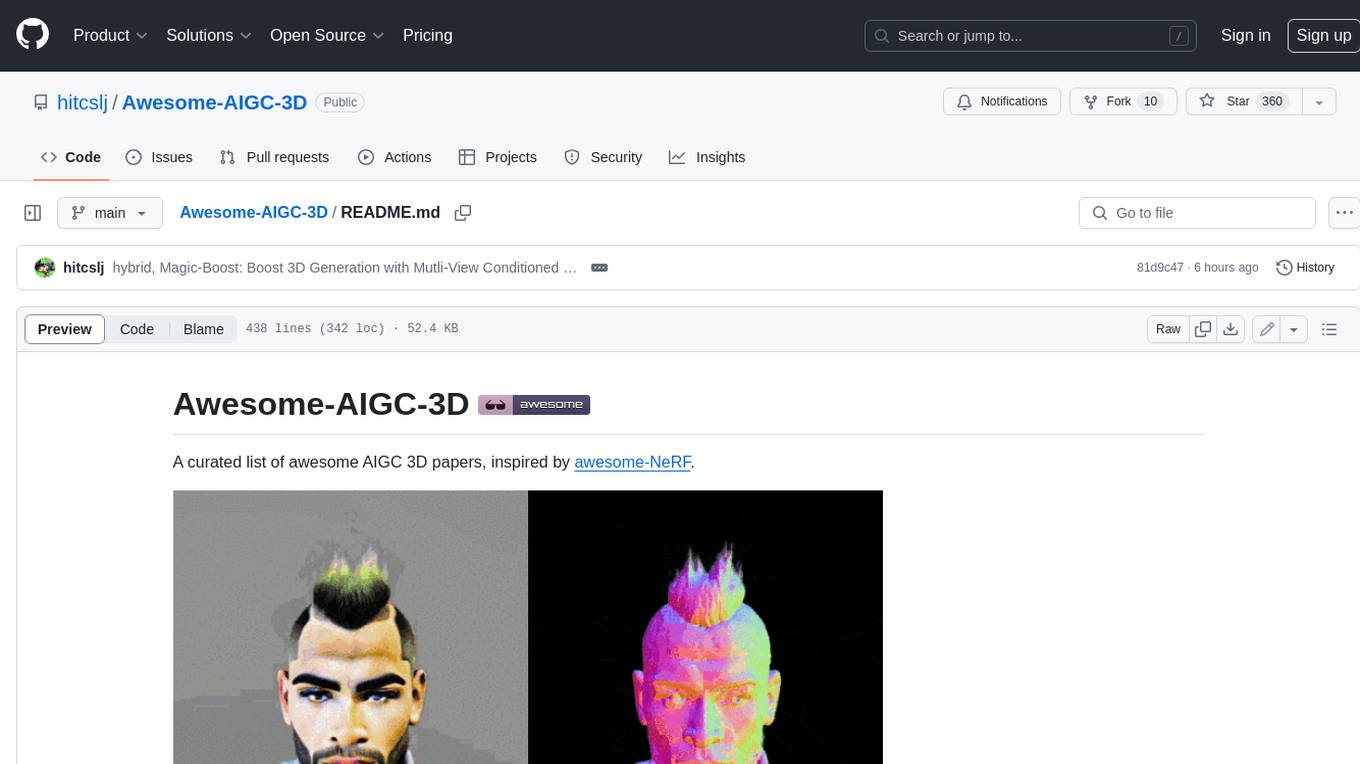
Awesome-AIGC-3D is a curated list of awesome AIGC 3D papers, inspired by awesome-NeRF. It aims to provide a comprehensive overview of the state-of-the-art in AIGC 3D, including papers on text-to-3D generation, 3D scene generation, human avatar generation, and dynamic 3D generation. The repository also includes a list of benchmarks and datasets, talks, companies, and implementations related to AIGC 3D. The description is less than 400 words and provides a concise overview of the repository's content and purpose.
README:
A curated list of awesome AIGC 3D papers, inspired by awesome-NeRF.

- 3D Generative Models: A Survey, Shi et al., arxiv 2022 | bibtex
- Generative AI meets 3D: A Survey on Text-to-3D in AIGC Era, Li et al., arxiv 2023 | bibtex
- AI-Generated Content (AIGC) for Various Data Modalities: A Survey, Foo et al., arxiv 2023 | bibtex
- Advances in 3D Generation: A Survey, Li et al., arxiv 2024 | bibtex
- A Comprehensive Survey on 3D Content Generation, Liu et al., arxiv 2024 | bibtex
- Geometric Constraints in Deep Learning Frameworks: A Survey, Vats et al., arxiv 2024 | bibtex
3D Native Generative Methods
Object
- Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings, Chen et al., ACCV 2018 | github | bibtex
- ShapeCrafter: A Recursive Text-Conditioned 3D Shape Generation Model, Fu et al., NeurIPS 2022 | github | bibtex
- GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images, Gao et al., NeurIPS 2022 | github | bibtex
- LION: Latent Point Diffusion Models for 3D Shape Generation, Zeng et al., NeurIPS 2022 | github | bibtex
- Diffusion-SDF: Conditional Generative Modeling of Signed Distance Functions, Chou et al., ICCV 2023 | github | bibtex
- MagicPony: Learning Articulated 3D Animals in the Wild, Wu et al., CVPR 2023 | github | bibtex
- DiffRF: Rendering-guided 3D Radiance Field Diffusion, Müller et al., CVPR 2023 | bibtex
- SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation, Cheng et al., CVPR 2023 | github | bibtex
- Point-E: A System for Generating 3D Point Clouds from Complex Prompts, Nichol et al., arxiv 2022 | github | bibtex
- 3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models, Zhang et al., TOG 2023 | github | bibtex
- 3DGen: Triplane Latent Diffusion for Textured Mesh Generation, Gupta et al., arxiv 2023 | bibtex
- MeshDiffusion: Score-based Generative 3D Mesh Modeling, Liu et al., ICLR 2023 | github | bibtex
- HoloDiffusion: Training a 3D Diffusion Model using 2D Images, Karnewar et al., CVPR 2023 | github | bibtex
- HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion, Erkoç et al., ICCV 2023 | github | bibtex
- Shap-E: Generating Conditional 3D Implicit Functions, Jun et al., arxiv 2023 | github | bibtex
- LAS-Diffusion: Locally Attentional SDF Diffusion for Controllable 3D Shape Generation, Zheng et al., TOG 2023 | github | bibtex
- Michelangelo: Conditional 3D Shape Generation based on Shape-Image-Text Aligned Latent Representation, Zhao et al., NeurIPS 2023 | github | bibtex
- DiffComplete: Diffusion-based Generative 3D Shape Completion, Chu et al., NeurIPS 2023 | bibtex
- DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation, Mo et al., arxiv 2023 | github | bibtext
- 3D VADER - AutoDecoding Latent 3D Diffusion Models, Ntavelis et al., arxiv 2023 | github | bibtex
- ARGUS: Visualization of AI-Assisted Task Guidance in AR, Castelo et al., TVCG 2023 | bibtex
- Large-Vocabulary 3D Diffusion Model with Transformer, Cao et al., ICLR 2024 | github | bibtext
- TextField3D: Towards Enhancing Open-Vocabulary 3D Generation with Noisy Text Fields, Huang et al., ICLR 2024 | bibtex
- HyperFields:Towards Zero-Shot Generation of NeRFs from Text, Babu et al., arxiv 2023 | github | bibtex
- LRM: Large Reconstruction Model for Single Image to 3D, Hong et al., ICLR 2024 | bibtex
- DMV3D:Denoising Multi-View Diffusion using 3D Large Reconstruction Model, Xu et al., ICLR 2024 | bibtex
- WildFusion:Learning 3D-Aware Latent Diffusion Models in View Space, Schwarz et al., ICLR 2024 | bibtex
- Functional Diffusion, Zhang et al., CVPR 2024 | github | bibtex
- MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers, Siddiqui et al., arxiv 2023 | github | bibtex
- SPiC·E: Structural Priors in 3D Diffusion Models using Cross-Entity Attention, Sella et al., arxiv 2023 | github | bibtex
- ZeroRF: Fast Sparse View 360° Reconstruction with Zero Pretraining, Shi et al., arxiv 2023 | github | bibtex
- Learning the 3D Fauna of the Web, Li et al., arxiv 2024 | bibtex
- Pushing Auto-regressive Models for 3D Shape Generation at Capacity and Scalability, Qian et al., arxiv 2024 | github | bibtext
- LN3Diff: Scalable Latent Neural Fields Diffusion for Speedy 3D Generation, Lan et al., arxiv 2024 | github | bibtext
- GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation, Xu et al., arxiv 2024 | github | bibtext
- Lift3D: Zero-Shot Lifting of Any 2D Vision Model to 3D, Varma T et al., CVPR 2024 | github | bibtext
- MeshLRM: Large Reconstruction Model for High-Quality Meshes, Wei et al., arxiv 2024 | bibtext
- Interactive3D🪄: Create What You Want by Interactive 3D Generation, Dong et al., CVPR 2024 | github | bibtex
- BrepGen: A B-rep Generative Diffusion Model with Structured Latent Geometry, Xu et al., SIGGRAPH 2024 | github | bibtex
- Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer, Wu et al., arxiv 2024 | bibtex
- MeshXL: Neural Coordinate Field for Generative 3D Foundation Models, Chen et al., arXiv 2024 | github | bibtex
- MeshAnything:Artist-Created Mesh Generation with Autoregressive Transformers, Chen et al., arxiv 2024 | github | bibtex
- CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets, Zhang et al., TOG 2024 | github | bibtex
- L4GM: Large 4D Gaussian Reconstruction Model, Ren et al., arxiv 2024 | bibtex
- Efficient Large-Baseline Radiance Fields, a feed-forward 2DGS model, Chen et al., ECCV 2024 | github | bibtex
- MeshAnything V2: Artist-Created Mesh Generation With Adjacent Mesh Tokenization, Chen et al., arXiv 2024 | github | bibtex
- SF3D: Stable Fast 3D Mesh Reconstruction with UV-unwrapping and Illumination Disentanglement, Boss et al., arXiv 2024 | github | bibtex
- G3PT: Unleash the power of Autoregressive Modeling in 3D Generation via Cross-scale Querying Transformer, Zhang et al., arXiv 2024 | bibtex
- 3DTopia-XL: Scaling High-quality 3D Asset Generation via Primitive Diffusion, Chen et al., arXiv 2024 | github | bibtex
- EdgeRunner: Auto-regressive Auto-encoder for Artistic Mesh Generation, Tang et al., arXiv 2024 | bibtex
Scene
- GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis, Schwarz et al., NeurIPS 2020 | github | bibtext
- ATISS: Autoregressive Transformers for Indoor Scene Synthesis, Paschalidou et al., NeurIPS 2021 | github | bibtext
- GAUDI: A Neural Architect for Immersive 3D Scene Generation, Bautista et al., NeurIPS 2022 | github | bibtext
- NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models, Kim et al., CVPR 2023 | bibtext
- Pyramid Diffusion for Fine 3D Large Scene Generation, Liu et al., arxiv 2023 | github | bibtext
- XCube: Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies, Ren et al., arxiv 2023 | bibtex
- DUSt3R: Geometric 3D Vision Made Easy, Wang et al., arxiv 2023 | github | bibtext
Human Avatar
- SMPL: A skinned multi-person linear model, Loper et al., TOG 2015 | bibtex
- SMPLicit: Topology-aware Generative Model for Clothed People, Corona et al., CVPR 2021 | github | bibtext
- HeadNeRF: A Real-time NeRF-based Parametric Head Model, Hong et al., CVPR 2022 | github | bibtext
- gDNA: Towards Generative Detailed Neural Avatars, Chen et al., CVPR 2022 | github | bibtext
- Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion, Wang et al., CVPR 2023 | bibtex
- Single-View 3D Human Digitalization with Large Reconstruction Models, Weng et al., CVPR 2023 | bibtex
2D Prior-based 3D Generative Methods
Object
- DreamFields: Zero-Shot Text-Guided Object Generation with Dream Fields, Jain et al., CVPR 2022 | github | bibtex
- DreamFusion: Text-to-3D using 2D Diffusion, Poole et al., ICLR 2023 | github | bibtex
- Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models, Xu et al., CVPR 2023 | bibtex
- Magic3D: High-Resolution Text-to-3D Content Creation, Lin et al., CVPR 2023 | bibtex
- Score Jacobian Chaining: Lifting Pretrained 2D Diffusion Models for 3D Generation, Wang et al., CVPR 2023 |github| bibtex
- RealFusion: 360° Reconstruction of Any Object from a Single Image, Melas-Kyriazi et al., CVPR 2023 | github | bibtex
- 3DFuse: Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation, Seo et al., ICLR 2024 | github | bibtex
- DreamBooth3D: Subject-Driven Text-to-3D Generation, Raj et al., ICCV 2023 | bibtex
- Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation, Chen et al., ICCV 2023 | github | bibtex
- Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior, Tang et al., ICCV 2023 | github | bibtex
- HiFA: High-fidelity Text-to-3D with Advanced Diffusion Guidance, Zhu et al., ICLR 2024 | github | bibtex
- ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation, Wang et al., NeurIPS 2023 | github | bibtex
- ATT3D: Amortized Text-to-3D Object Synthesis, Lorraine et al., ICCV 2023 | bibtex
- DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation, Tang et al., ICLR 2024 | github | bibtex
- NFSD: Noise Free Score Distillation, Katzir et al., arxiv 2023 | github | bibtex
- Text-to-3D with Classifier Score Distillation, Yu et al., arxiv 2023 | github | bibtex
- IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts, Zeng et al., arxiv 2023 | bibtex
- Progressive3D: Progressively Local Editing for Text-to-3D Content Creation with Complex Semantic Prompts, Cheng et al., arxiv 2023 | github | bibtex
- Instant3D : Instant Text-to-3D Generation, Li et al., ICLR 2024 | bibtex
- LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching, Liang et al., arxiv 2023 | github | bibtex
- Control3D: Towards Controllable Text-to-3D Generation, Chen et al., ACM Multimedia 2023 | bibtex
- CG3D: Compositional Generation for Text-to-3D via Gaussian Splatting, Vilesov et al., arxiv 2023 | bibtex
- StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D, Guo et al., arxiv 2023 | bibtex
- CAD: Photorealistic 3D Generation via Adversarial Distillation, Wan et al., arxiv 2023 | github | bibtex
- DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior, Huang et al., arxiv 2023 | github | bibtex
- AGAP:Learning Naturally Aggregated Appearance for Efficient 3D Editing, Cheng et al., arxiv 2023 | github | bibtex
- SSD: Stable Score Distillation for High-Quality 3D Generation, Tang et al., arxiv 2023 | bibtex
- SteinDreamer: Variance Reduction for Text-to-3D Score Distillation via Stein Identity, Wang et al., arxiv 2023 | github | bibtex
- Taming Mode Collapse in Score Distillation for Text-to-3D Generation, Wang et al., arxiv 2024 | github | bibtex
- Score Distillation Sampling with Learned Manifold Corrective, Alldieck et al., arxiv 2024 | bibtex
- Consistent3D: Towards Consistent High-Fidelity Text-to-3D Generation with Deterministic Sampling Prior, Wu et al., arxiv 2024 | bibtex
- TIP-Editor: An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts, Zhuang et al., arxiv 2024 | bibtex
- ICE-G: Image Conditional Editing of 3D Gaussian Splats, Jaganathan et al., CVPRW 2024 | bibtext
- GaussianDreamerPro: Text to Manipulable 3D Gaussians with Highly Enhanced Quality, Yi et al., arxiv 2024 | github | bibtex
- ScaleDreamer: Scalable Text-to-3D Synthesis with Asynchronous Score Distillation, Ma et al., ECCV 2024 | github | bibtex
Scene
- Text2Light: Zero-Shot Text-Driven HDR Panorama Generation, Chen et al., TOG 2022 | github | bibtext
- SceneScape: Text-Driven Consistent Scene Generation, Fridman et al., NeurIPS 2023 | github | bibtext
- DiffuScene: Scene Graph Denoising Diffusion Probabilistic Model for Generative Indoor Scene Synthesis, Tang et al., arxiv 2023 | github | bibtext
- Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models, Höllein et al., ICCV 2023 | github | bibtext
- Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields, Zhang et al., TVCG 2024 | github | bibtext
- CityDreamer: Compositional Generative Model of Unbounded 3D Cities, Xie et al., arxiv 2023 | github | bibtext
- GaussianEditor: Swift and Controllable 3D Editing with Gaussian Splatting, Chen et al., arxiv 2023 | github | bibtex
- LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes, Chuang et al., arxiv 2023 | github | bibtext
- GaussianEditor: Editing 3D Gaussians Delicately with Text Instructions, Fang et al., arxiv 2023 | bibtex
- Gaussian Grouping: Segment and Edit Anything in 3D Scenes, Ye et al., arxiv 2023 | github | bibtex
- Inpaint3D: 3D Scene Content Generation using 2D Inpainting Diffusion, Prabhu et al., arxiv 2023 | bibtext
- SIGNeRF: Scene Integrated Generation for Neural Radiance Fields, Dihlmann et al., arxiv 2024 | github | bibtex
- Disentangled 3D Scene Generation with Layout Learning, Epstein, et al., arxiv 2024 | bibtex
Human Avatar
- AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars, Hong et al., SIGGRAPH 2022 | github | bibtex
- DreamWaltz: Make a Scene with Complex 3D Animatable Avatars, Huang et al., NeurIPS 2023 | github | bibtex
- DreamHuman: Animatable 3D Avatars from Text, Wang et al., arxiv 2023 | bibtex
- TECA: Text-Guided Generation and Editing of Compositional 3D Avatars, Zhang et al., arxiv 2023 | github | bibtex
- HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting, Liu et al., arxiv 2023 | github | bibtex
- HeadArtist: Text-conditioned 3D Head Generation with Self Score Distillation, Liu et al., arxiv 2023 | bibtex
- 3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting, Qian et al., arxiv 2023 | github | bibtex
Hybrid 3D Generative Methods
Object
- Zero-1-to-3: Zero-shot One Image to 3D Object, Liu et al., ICCV 2023 | github | bibtex
- One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization, Liu et al., NeurIPS 2023 | github | bibtex
- Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors, Qian et al., arxiv 2023 | github | bibtex
- MVDream: Multi-view Diffusion for 3D Generation, Shi et al., arxiv 2023 | github | bibtex
- SyncDreamer: Generating Multiview-consistent Images from a Single-view Image, Liu et al., arxiv 2023 | github | bibtex
- Gsgen: Text-to-3D using Gaussian Splatting, Chen et al., arxiv 2023 | github | bibtex
- Consistent123: One Image to Highly Consistent 3D Asset Using Case-Aware Diffusion Priors, Lin et al., arxiv 2024 | bibtex
- GaussianDreamer: Fast Generation from Text to 3D Gaussians by Bridging 2D and 3D Diffusion Models, Yi et al., arxiv 2023 | github | bibtex
- Consistent-1-to-3: Consistent Image to 3D View Synthesis via Geometry-aware Diffusion Models, Ye et al., 3DV 2024 | bibtex
- Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model, Shi et al., arxiv 2023 | github | bibtex
- TOSS: High-quality Text-guided Novel View Synthesis from a Single Image, Shi et al., arxiv 2023 | bibtex
- Wonder3D: Single Image to 3D using Cross-Domain Diffusion, Long et al., arxiv 2023 | github | bibtex
- DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior, Sun et al., ICLR 2024 | github | bibtex
- SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D, Li et al., arxiv 2023 | github | bibtex
- One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion, Liu et al., arxiv 2023 | github | bibtex
- Direct2.5: Diverse Text-to-3D Generation via Multi-view 2.5D Diffusion, Lu et al., arxiv 2023 | bibtex
- ConRad: Image Constrained Radiance Fields for 3D Generation from a Single Image, Purushwalkam et al., NeurIPS 2023 | bibtex
- Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model, Li et al., arxiv 2023 | bibtex
- MVControl: Adding Conditional Control to Multi-view Diffusion for Controllable Text-to-3D Generation, Li et al., arxiv 2023 | github | bibtex
- GeoDream:Disentangling 2D and Geometric Priors for High-Fidelity and Consistent 3D Generation, Ma et al., arxiv 2023 | github | bibtex
- RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D, Qiu et al., arxiv 2023 | github | bibtex
- Slice3D: Multi-Slice, Occlusion-Revealing, Single View 3D Reconstruction, Wang et al., CVPR 2024 | github | bibtex
- DreamComposer: Controllable 3D Object Generation via Multi-View Conditions, Yang et al., arxiv 2023 | github | bibtex
- Cascade-Zero123: One Image to Highly Consistent 3D with Self-Prompted Nearby Views, Chen et al., arxiv 2023 | github | bibtex
- Free3D: Consistent Novel View Synthesis without 3D Representation, Zheng et al., arxiv 2023 | github | bibtex
- Sherpa3D: Boosting High-Fidelity Text-to-3D Generation via Coarse 3D Prior, Liu et al., arxiv 2023 | github | bibtex
- UniDream: Unifying Diffusion Priors for Relightable Text-to-3D Generation, Liu et al., arxiv 2023 | github | bibtex
- Repaint123: Fast and High-quality One Image to 3D Generation with Progressive Controllable 2D Repainting, Zhang et al., arxiv 2023 | github | bibtex
- BiDiff: Text-to-3D Generation with Bidirectional Diffusion using both 2D and 3D priors, Ding et al., arxiv 2023 | github | bibtex
- ControlDreamer: Stylized 3D Generation with Multi-View ControlNet, Oh et al., arxiv 2023 | github | bibtex
- X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation, Ma et al., arxiv 2023 | github | bibtex
- Splatter Image: Ultra-Fast Single-View 3D Reconstruction, Szymanowicz et al., arxiv 2023 | github | bibtex
- Carve3D: Improving Multi-view Reconstruction Consistency for Diffusion Models with RL Finetuning, Xie et al., arxiv 2023 | bibtex
- HarmonyView: Harmonizing Consistency and Diversity in One-Image-to-3D, Woo et al., arxiv 2023 | github | bibtex
- ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation, Wang et al., arxiv 2023 | github | bibtex
- iFusion: Inverting Diffusion for Pose-Free Reconstruction from Sparse Views, Wu et al., arxiv 2023 | github | bibtex
- AGG: Amortized Generative 3D Gaussians for Single Image to 3D, Xu et al., arxiv 2024 | bibtex
- HexaGen3D: StableDiffusion is just one step away from Fast and Diverse Text-to-3D Generation, Mercier et al., arxiv 2024 | bibtex
- HexaGen3D: StableDiffusion is just one step away from Fast and Diverse Text-to-3D Generation, Mercier et al., arxiv 2024 | bibtex
- Sketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation, Chen et al., arxiv 2024 | bibtex
- IM-3D: Iterative Multiview Diffusion and Reconstruction for High-Quality 3D Generation, Melas-Kyriazi et al., arxiv 2024 | bibtex
- LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation, Tang et al., arxiv 2024 | github | bibtex
- Retrieval-Augmented Score Distillation for Text-to-3D Generation, Seo et al., ICML 2024 | github | bibtex
- EscherNet: A Generative Model for Scalable View Synthesis, Kong et al., arxiv 2024 | github | bibtex
- MVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction, Tang et al., arxiv 2024 | bibtex
- MVD2: Efficient Multiview 3D Reconstruction for Multiview Diffusion, Zheng et al., arxiv 2024 | bibtex
- Consolidating Attention Features for Multi-view Image Editing, Patashnik et al., arxiv 2024 | bibtex
- ViewFusion: Towards Multi-View Consistency via Interpolated Denoising, Yang et al., CVPR 2024 | github | bibtex
- CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model, Wang et al., arxiv 2024 | github | bibtext
- Sculpt3D: Multi-View Consistent Text-to-3D Generation with Sparse 3D Prior, Chen et al., CVPR 2024 | github | bibtext
- Make-Your-3D: Fast and Consistent Subject-Driven 3D Content Generation, Liu et al., arxiv 2024 | github | bibtext
- Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting, Li et al., arxiv 2024 | github | bibtex
- VideoMV: Consistent Multi-View Generation Based on Large Video Generative Model, Zuo et al., arxiv 2024 | github | bibtex
- SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion, Voleti et al., arxiv 2024 | bibtex
- DreamReward: Text-to-3D Generation with Human Preference, Ye et al., arxiv 2024 | bibtex
- LATTE3D: Large-scale Amortized Text-To-Enhanced3D Synthesis, Xie et al., arxiv 2024 | bibtex
- DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion, Lin et al., arxiv 2024 | github | bibtex
- GeoWizard: Unleashing the Diffusion Priors for 3D Geometry Estimation from a Single Image, Fu et al., arxiv 2024 | github | bibtex
- ThemeStation: Generating Theme-Aware 3D Assets from Few Exemplars, Wang et al., arxiv 2024 | github | bibtex
- FlexiDreamer: Single Image-to-3D Generation with FlexiCubes, Zhao et al., arxiv 2024 | github | bibtex
- Sketch3D: Style-Consistent Guidance for Sketch-to-3D Generation, Zheng et al., arxiv 2024 | bibtex
- DreamView: Injecting View-specific Text Guidance into Text-to-3D Generation, Yan et al., arxiv 2024 | github | bibtex
- InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models, Xu et al., arxiv 2024 | github | bibtex
- DGE: Direct Gaussian 3D Editing by Consistent Multi-view Editing, Chen et al., arxiv 2024 | github | bibtex
- MicroDreamer: Zero-shot 3D Generation in ∼20 Seconds by Score-based Iterative Reconstruction, Chen et al., arxiv 2024 | github | bibtex
- SketchDream: Sketch-based Text-to-3D Generation and Editing, Liu et al., SIGGRAPH 2024 | bibtex
- Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image, Wu et al., arxiv 2024 | github | bibtex
- Fourier123: One Image to High-Quality 3D Object Generation with Hybrid Fourier Score Distillation, Yang et al., arxiv 2024 | github | bibtex
- CAT3D: Create Anything in 3D with Multi-View Diffusion Models, Gao et al., arxiv 2024 | bibtext
- CraftsMan: High-fidelity Mesh Generation with 3D Native Generation and Interactive Geometry Refiner, Li et al., arxiv 2024 | github | bibtext
- Meta 3D AssetGen: Text-to-Mesh Generation with High-Quality Geometry, Texture, and PBR Materials, Siddiqui et al., arxiv 2024 | bibtext
- VQA-Diff: Exploiting VQA and Diffusion for Zero-Shot Image-to-3D Vehicle Asset Generation in Autonomous Driving, Liu et al., ECCV 2024 | bibtext
- Cycle3D: High-quality and Consistent Image-to-3D Generation via Generation-Reconstruction Cycle, Tang et al., arxiv 2024 | github | bibtext
- Phidias: A Generative Model for Creating 3D Content from Text, Image, and 3D Conditions with Reference-Augmented Diffusion, Wang et al., arxiv 2024 | github | bibtext
Scene
- Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints, Fang et al., arxiv 2023 | github | bibtext
- RoomDesigner: Encoding Anchor-latents for Style-consistent and Shape-compatible Indoor Scene Generation, Zhao et al., 3DV 2024 | github | bibtext
- ZeroNVS: Zero-Shot 360-Degree View Synthesis from a Single Real Image, Sargent et al., arxiv 2023 | github | bibtext
- GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs, Gao et al., arxiv 2023 | github | bibtext
- ControlRoom3D:Room Generation using Semantic Proxy Rooms, Schult et al., arxiv 2023 | bibtext
- AnyHome: Open-Vocabulary Generation of Structured and Textured 3D Homes, Wen et al., arxiv 2023 | bibtext
- SceneWiz3D: Towards Text-guided 3D Scene Composition, Zhang et al., arxiv 2023 | github | bibtext
- Text2Immersion: Generative Immersive Scene with 3D Gaussians, Ouyang et al., arxiv 2023 | bibtext
- ShowRoom3D: Text to High-Quality 3D Room Generation Using 3D Priors, Mao et al., arxiv 2023 | github | bibtext
- GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guided Generative Gaussian Splatting, Zhou et al., arxiv 2024 | github | bibtext
- 3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation, Zhang et al., arxiv 2024 | bibtext
- Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image, Szymanowicz et al., arxiv 2024 | bibtext
- ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis, Mao et al., arxiv 2024 | github | bibtext
Human Avatar
- SofGAN: A Portrait Image Generator with Dynamic Styling, Chen et al., TOG 2022 | github | bibtext
- Get3DHuman: Lifting StyleGAN-Human into a 3D Generative Model using Pixel-aligned Reconstruction Priors, Xiong et al., ICCV 2023 | github | bibtext
- DreamFace: Progressive Generation of Animatable 3D Faces under Text Guidance, Zhang et al., arxiv 2023 | bibtext
- TADA! Text to Animatable Digital Avatars, Liao et al., 3DV 2024 | github | bibtext
- SCULPT: Shape-Conditioned Unpaired Learning of Pose-dependent Clothed and Textured Human Meshes, Sanyal et al., arxiv 2023 | bibtext
- HumanNorm: Learning Normal Diffusion Model for High-quality and Realistic 3D Human Generation, Huang et al., arxiv 2023 | github | bibtex
Dynamic
- MAV3d: Text-To-4D Dynamic Scene Generation, Singer et al., arxiv 2023 | bibtext
- Control4D: Dynamic Portrait Editing by Learning 4D GAN from 2D Diffusion-based Editor, Shao et al., arxiv 2023 | bibtex
- MAS: Multi-view Ancestral Sampling for 3D motion generation using 2D diffusion, Kapon et al., arxiv 2023 | github | bibtext
- Consistent4D: Consistent 360° Dynamic Object Generation from Monocular Video, Jiang et al., arxiv 2023 | github | bibtext
- Animate124: Animating One Image to 4D Dynamic Scene, Zhao et al., arxiv 2023 | github | bibtext
- A Unified Approach for Text- and Image-guided 4D Scene Generation, Zheng et al., arxiv 2023 | bibtext
- 4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling, Bahmani et al., arxiv 2023 | github | bibtext
- AnimatableDreamer: Text-Guided Non-rigid 3D Model Generation and Reconstruction with Canonical Score Distillation, Wang et al., arxiv 2023 | bibtext
- Virtual Pets: Animatable Animal Generation in 3D Scenes, Cheng et al., arxiv 2023 | github | bibtext
- Align Your Gaussians:Text-to-4D with Dynamic 3D Gaussians and Composed Diffusion Models, Ling et al., arxiv 2023 bibtext
- Ponymation: Learning 3D Animal Motions from Unlabeled Online Videos, Sun et al., arxiv 2023 | bibtext
- 4DGen: Grounded 4D Content Generation with Spatial-temporal Consistency, Yin et al., arxiv 2023 | github | bibtext
- DreamGaussian4D: Generative 4D Gaussian Splatting, Ren et al., arxiv 2023 | github | bibtext
- Fast Dynamic 3D Object Generation from a Single-view Video, Pan et al., arxiv 2024 | github | bibtext
- ComboVerse: Compositional 3D Assets Creation Using Spatially-Aware Diffusion Guidance, Chen et al., arxiv 2024 | bibtext
- STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians, Zeng et al., arxiv 2024 | bibtext
- TC4D: Trajectory-Conditioned Text-to-4D Generation, Bahmani et al., arxiv 2024 | bibtext
- Diffusion^2: Dynamic 3D Content Generation via Score Composition of Orthogonal Diffusion Models, Yang et al., arxiv 2024 | bibtext
- Hash3D: Training-free Acceleration for 3D Generation, Yang et al., arxiv 2024 | github | bibtext
- Magic-Boost: Boost 3D Generation with Mutli-View Conditioned Diffusion, Yang et al., arxiv 2024 | github | bibtext
- Enhancing 3D Fidelity of Text-to-3D using Cross-View Correspondences, Kim et al., CVPR 2024 | bibtext
- DreamScene4D: Dynamic Multi-Object Scene Generation from Monocular Videos, Chu et al., arxiv 2024 | github | bibtext
- Diffusion4D: Fast Spatial-temporal Consistent 4D Generation via Video Diffusion Models, Liang et al., arxiv 2024 | github | bibtext
- Vidu4D: Single Generated Video to High-Fidelity 4D Reconstruction with Dynamic Gaussian Surfels, Wang et al., arxiv 2024 | github | bibtext
- Physics3D: Learning Physical Properties of 3D Gaussians via Video Diffusion, Liu et al., arxiv 2024 | github | bibtext
- 4Real: Towards Photorealistic 4D Scene Generation via Video Diffusion Models, Liu et al., arxiv 2024 | bibtext
- SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency, Xie et al., arxiv 2024 | github | bibtext
Others
Physical
- Physical Property Understanding from Language-Embedded Feature Fields, Zhai et al., CVPR 2024 | github | bibtext
- Physically Compatible 3D Object Modeling from a Single Image, Guo et al., arxiv 2024 | bibtext
Texture
- StyleMesh: Style Transfer for Indoor 3D Scene Reconstructions, Höllein et al., CVPR 2022 | github | bibtex
- CLIP-Mesh: Generating textured meshes from text using pretrained image-text models, Khalid et al., SIGGRAPH Asia 2022 | github | bibtex
- TANGO: Text-driven PhotoreAlistic aNd Robust 3D Stylization via LiGhting DecompOsition, Chen et al., NeurIPS 2022 | github | bibtex
- Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures, Metzer et al., CVPR 2023 | github | bibtex
- TEXTure: Text-Guided Texturing of 3D Shapes, Richardson et al., SIGGRAPH 2023 | github | bibtex
- Text2Tex: Text-driven Texture Synthesis via Diffusion Models, Chen et al., ICCV 2023 | github | bibtex
- RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture, Song et al., ACM Multimedia 2023 | bibtex
- Generating Parametric BRDFs from Natural Language Descriptions, Memery et al., arxiv 2023 bibtex
- MVDiffusion: Enabling Holistic Multi-view Image Generation with Correspondence-Aware Diffusion, Tang et al., NeurIPS 2023 | github | bibtext
- MATLABER: Material-Aware Text-to-3D via LAtent BRDF auto-EncodeR, Xu et al., arxiv 2023 | github | bibtex
- ITEM3D: Illumination-Aware Directional Texture Editing for 3D Models, Liu et al., arxiv 2023 | github | bibtex
- TexFusion: Synthesizing 3D Textures with Text-Guided Image Diffusion Models, Cao et al., ICCV 2023 | bibtex
- DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation, Yang et al., arxiv 2023 | github | bibtext
- 3DStyle-Diffusion: Pursuing Fine-grained Text-driven 3D Stylization with 2D Diffusion Models, Yang et al., ACM Multimedia 2023 | github | bibtex
- Text-Guided Texturing by Synchronized Multi-View Diffusion, Liu et al., arxiv 2023 | bibtex
- SceneTex: High-Quality Texture Synthesis for Indoor Scenes via Diffusion Priors, Chen et al., arxiv 2023 | github | bibtext
- TeMO: Towards Text-Driven 3D Stylization for Multi-Object Meshes, Zhang et al., arxiv 2023 | bibtex
- Single Mesh Diffusion Models with Field Latents for Texture Generation, Mitchel et al., arxiv 2023 | bibtex
- Paint-it: Text-to-Texture Synthesis via Deep Convolutional Texture Map Optimization and Physically-Based Rendering, Youwang et al., arxiv 2023 | github | bibtext
- Paint3D: Paint Anything 3D with Lighting-Less Texture Diffusion Models, Zeng et al., arxiv 2023 | github | bibtext
- TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion, Yeh et al., arxiv 2024 | bibtext
- FlashTex: Fast Relightable Mesh Texturing with LightControlNet, Deng et al., arxiv 2024 | bibtext
- Make-it-Real: Unleashing Large Multimodal Model's Ability for Painting 3D Objects with Realistic Materials, Fang et al., arxiv 2024 | github | bibtext
- MaPa: Text-driven Photorealistic Material Painting for 3D Shapes, Zhang et al., SIGGRAPH 2024 | bibtext
- Meta 3D TextureGen: Fast and Consistent Texture Generation for 3D Objects, Bensadoun et al., arxiv 2024 | bibtext
Procedural 3D Modeling
- ProcTHOR: Large-Scale Embodied AI Using Procedural Generation, Deitke et al., NeurIPS 2022 | github | bibtex
- 3D-GPT: Procedural 3D Modeling with Large Language Models, Sun et al., arxiv 2023 | github | bibtex
3D Representation
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, Mildenhall et al., ECCV 2020 | github | bibtex
- Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis, Shen et al., arxiv 2021 | bibtex
- 3D Gaussian Splatting for Real-Time Radiance Field Rendering, Kerbl et al., TOG 2023 | github | bibtex
- Uni3D: Exploring Unified 3D Representation at Scale, Zhou et al., ICLR 2024 | github | bibtex
- SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene, Duckworth et al., arxiv 2023 | bibtex
- Triplane Meets Gaussian Splatting:Fast and Generalizable Single-View 3D Reconstruction with Transformers, Zou et al., arxiv 2023 | bibtex
- SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes, Huang et al., arxiv 2023 | github | bibtex
- DMesh: A Differentiable Representation for General Meshes, Son et al., arxiv 2024 | github | bibtex
- Objaverse-XL, Deitke et al., NeurIPS 2023 | github | bibtext
- G-buffer Objaverse: High-Quality Rendering Dataset of Objaverse, Xu et al.
- GPT-4V(ision) is a Human-Aligned Evaluator for Text-to-3D Generation, Wu et al., arXiv 2024 | github | bibtext
- SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding, Jia et al., arXiv 2024 | bibtext
- Make-A-Shape: a Ten-Million-scale 3D Shape Model, Wu et al., arXiv 2024 | bibtext
- Zeroverse, Xie et al., arXiv 2024 | github | bibtext
- AI 3D Generation, explained, Jia-Bin Huang
- 3D Generation, bilibili, Leo
- 3D AIGC Algorithm Trends and Industry Implementation, Ding Liang
- 3D Generation: Past, Present and Future,GAMES Webinar 311
- Threestudio, Yuan-Chen Guo, 2023 | bibtex
- stable-dreamfusion, Jiaxiang Tang, 2023 | bibtex
- Dream Textures, Carson Katri, 2023
- ComfyTextures, Alexander Dzhoganov, 2023
- ComfyUI-3D-Pack, MrForExample, 2024
- GauStudio, Ye et al., arxiv 2024 | github | bibtex
Awesome AIGC 3D is released under the MIT license.
If you find this project useful in your research, please consider citing:
@article{liu2024comprehensive,
title={A Comprehensive Survey on 3D Content Generation},
author={Liu, Jian and Huang, Xiaoshui and Huang, Tianyu and Chen, Lu and Hou, Yuenan and Tang, Shixiang and Liu, Ziwei and Ouyang, Wanli and Zuo, Wangmeng and Jiang, Junjun and others},
journal={arXiv preprint arXiv:2402.01166},
year={2024}
}contact: [email protected].
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-AIGC-3D
Similar Open Source Tools
Awesome-AIGC-3D
Awesome-AIGC-3D is a curated list of awesome AIGC 3D papers, inspired by awesome-NeRF. It aims to provide a comprehensive overview of the state-of-the-art in AIGC 3D, including papers on text-to-3D generation, 3D scene generation, human avatar generation, and dynamic 3D generation. The repository also includes a list of benchmarks and datasets, talks, companies, and implementations related to AIGC 3D. The description is less than 400 words and provides a concise overview of the repository's content and purpose.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.
dive-into-llms
The 'Dive into Large Language Models' series programming practice tutorial is an extension of the 'Artificial Intelligence Security Technology' course lecture notes from Shanghai Jiao Tong University (Instructor: Zhang Zhuosheng). It aims to provide introductory programming references related to large models. Through simple practice, it helps students quickly grasp large models, better engage in course design, or academic research. The tutorial covers topics such as fine-tuning and deployment, prompt learning and thought chains, knowledge editing, model watermarking, jailbreak attacks, multimodal models, large model intelligent agents, and security. Disclaimer: The content is based on contributors' personal experiences, internet data, and accumulated research work, provided for reference only.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.

Hands-On-Large-Language-Models-CN
Hands-On Large Language Models CN(ZH) is a Chinese version of the book 'Hands-On Large Language Models' by Jay Alammar and Maarten Grootendorst. It provides detailed code annotations and additional insights, offers Notebook versions suitable for Chinese network environments, utilizes openbayes for free GPU access, allows convenient environment setup with vscode, and includes accompanying Chinese language videos on platforms like Bilibili and YouTube. The book covers various chapters on topics like Tokens and Embeddings, Transformer LLMs, Text Classification, Text Clustering, Prompt Engineering, Text Generation, Semantic Search, Multimodal LLMs, Text Embedding Models, Fine-tuning Models, and more.
LLMs-from-scratch-CN
This repository is a Chinese translation of the GitHub project 'LLMs-from-scratch', including detailed markdown notes and related Jupyter code. The translation process aims to maintain the accuracy of the original content while optimizing the language and expression to better suit Chinese learners' reading habits. The repository features detailed Chinese annotations for all Jupyter code, aiding users in practical implementation. It also provides various supplementary materials to expand knowledge. The project focuses on building Large Language Models (LLMs) from scratch, covering fundamental constructions like Transformer architecture, sequence modeling, and delving into deep learning models such as GPT and BERT. Each part of the project includes detailed code implementations and learning resources to help users construct LLMs from scratch and master their core technologies.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
imodelsX
imodelsX is a Scikit-learn friendly library that provides tools for explaining, predicting, and steering text models/data. It also includes a collection of utilities for getting started with text data. **Explainable modeling/steering** | Model | Reference | Output | Description | |---|---|---|---| | Tree-Prompt | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/tree_prompt) | Explanation + Steering | Generates a tree of prompts to steer an LLM (_Official_) | | iPrompt | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/iprompt) | Explanation + Steering | Generates a prompt that explains patterns in data (_Official_) | | AutoPrompt | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/autoprompt) | Explanation + Steering | Find a natural-language prompt using input-gradients (⌛ In progress)| | D3 | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/d3) | Explanation | Explain the difference between two distributions | | SASC | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/sasc) | Explanation | Explain a black-box text module using an LLM (_Official_) | | Aug-Linear | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/aug_linear) | Linear model | Fit better linear model using an LLM to extract embeddings (_Official_) | | Aug-Tree | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/aug_tree) | Decision tree | Fit better decision tree using an LLM to expand features (_Official_) | **General utilities** | Model | Reference | |---|---| | LLM wrapper| [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/llm) | Easily call different LLMs | | | Dataset wrapper| [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/data) | Download minimially processed huggingface datasets | | | Bag of Ngrams | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/bag_of_ngrams) | Learn a linear model of ngrams | | | Linear Finetune | [Reference](https://github.com/microsoft/AugML/tree/main/imodelsX/linear_finetune) | Finetune a single linear layer on top of LLM embeddings | | **Related work** * [imodels package](https://github.com/microsoft/interpretml/tree/main/imodels) (JOSS 2021) - interpretable ML package for concise, transparent, and accurate predictive modeling (sklearn-compatible). * [Adaptive wavelet distillation](https://arxiv.org/abs/2111.06185) (NeurIPS 2021) - distilling a neural network into a concise wavelet model * [Transformation importance](https://arxiv.org/abs/1912.04938) (ICLR 2020 workshop) - using simple reparameterizations, allows for calculating disentangled importances to transformations of the input (e.g. assigning importances to different frequencies) * [Hierarchical interpretations](https://arxiv.org/abs/1807.03343) (ICLR 2019) - extends CD to CNNs / arbitrary DNNs, and aggregates explanations into a hierarchy * [Interpretation regularization](https://arxiv.org/abs/2006.14340) (ICML 2020) - penalizes CD / ACD scores during training to make models generalize better * [PDR interpretability framework](https://www.pnas.org/doi/10.1073/pnas.1814225116) (PNAS 2019) - an overarching framewwork for guiding and framing interpretable machine learning
chat-master
ChatMASTER is a self-built backend conversation service based on AI large model APIs, supporting synchronous and streaming responses with perfect printer effects. It supports switching between mainstream models such as DeepSeek, Kimi, Doubao, OpenAI, Claude3, Yiyan, Tongyi, Xinghuo, ChatGLM, Shusheng, and more. It also supports loading local models and knowledge bases using Ollama and Langchain, as well as online API interfaces like Coze and Gitee AI. The project includes Java server-side, web-side, mobile-side, and management background configuration. It provides various assistant types for prompt output and allows creating custom assistant templates in the management background. The project uses technologies like Spring Boot, Spring Security + JWT, Mybatis-Plus, Lombok, Mysql & Redis, with easy-to-understand code and comprehensive permission control using JWT authentication system for multi-terminal support.
ChatGPT-On-CS
ChatGPT-On-CS is an intelligent chatbot tool based on large models, supporting various platforms like WeChat, Taobao, Bilibili, Douyin, Weibo, and more. It can handle text, voice, and image inputs, access external resources through plugins, and customize enterprise AI applications based on proprietary knowledge bases. Users can set custom replies, utilize ChatGPT interface for intelligent responses, send images and binary files, and create personalized chatbots using knowledge base files. The tool also features platform-specific plugin systems for accessing external resources and supports enterprise AI applications customization.

bravegpt
BraveGPT is a userscript that brings the power of ChatGPT to Brave Search. It allows users to engage with a conversational AI assistant directly within their search results, providing instant and personalized responses to their queries. BraveGPT is powered by GPT-4, the latest and most advanced language model from OpenAI, ensuring accurate and comprehensive answers. With BraveGPT, users can ask questions, get summaries, generate creative content, and more, all without leaving the Brave Search interface. The tool is easy to install and use, making it accessible to users of all levels. BraveGPT is a valuable addition to the Brave Search experience, enhancing its capabilities and providing users with a more efficient and informative search experience.
AIAS
AIAS is a comprehensive AI training platform that offers courses and practical examples in various AI fields such as traditional image processing, deep learning algorithms, JavaAI applications, NLP, web development, image generation, and desktop application development. The platform also provides SDKs for tasks like image recognition, OCR, natural language processing, audio processing, video analysis, and big data analysis. Users can access training materials, source code, and tools for developing AI applications across different domains.
For similar tasks
Awesome-AIGC-3D
Awesome-AIGC-3D is a curated list of awesome AIGC 3D papers, inspired by awesome-NeRF. It aims to provide a comprehensive overview of the state-of-the-art in AIGC 3D, including papers on text-to-3D generation, 3D scene generation, human avatar generation, and dynamic 3D generation. The repository also includes a list of benchmarks and datasets, talks, companies, and implementations related to AIGC 3D. The description is less than 400 words and provides a concise overview of the repository's content and purpose.
For similar jobs
Awesome-AIGC-3D
Awesome-AIGC-3D is a curated list of awesome AIGC 3D papers, inspired by awesome-NeRF. It aims to provide a comprehensive overview of the state-of-the-art in AIGC 3D, including papers on text-to-3D generation, 3D scene generation, human avatar generation, and dynamic 3D generation. The repository also includes a list of benchmarks and datasets, talks, companies, and implementations related to AIGC 3D. The description is less than 400 words and provides a concise overview of the repository's content and purpose.
LayaAir
LayaAir engine, under the Layabox brand, is a 3D engine that supports full-platform publishing. It can be applied in various fields such as games, education, advertising, marketing, digital twins, metaverse, AR guides, VR scenes, architectural design, industrial design, etc.
ComfyUI-BlenderAI-node
ComfyUI-BlenderAI-node is an addon for Blender that allows users to convert ComfyUI nodes into Blender nodes seamlessly. It offers features such as converting nodes, editing launch arguments, drawing masks with Grease pencil, and more. Users can queue batch processing, use node tree presets, and model preview images. The addon enables users to input or replace 3D models in Blender and output controlnet images using composite. It provides a workflow showcase with presets for camera input, AI-generated mesh import, composite depth channel, character bone editing, and more.
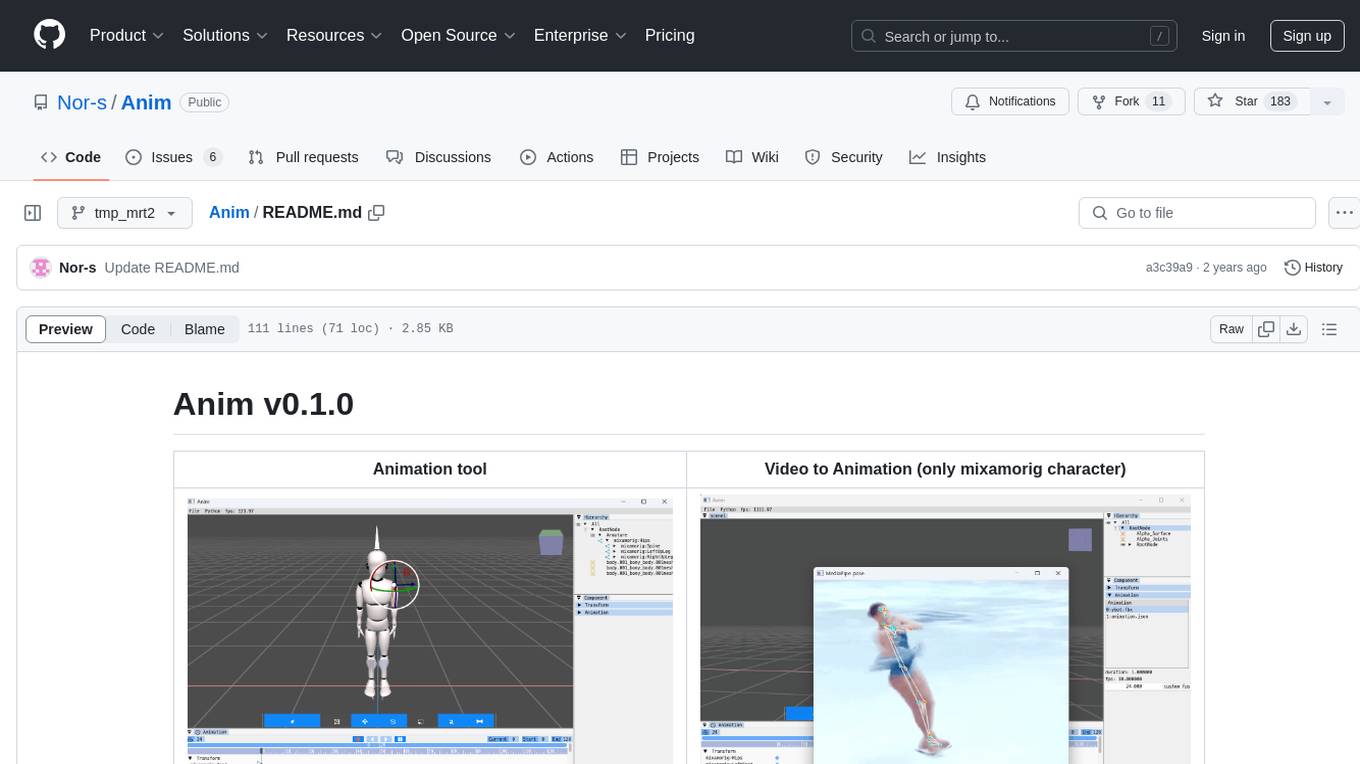
Anim
Anim v0.1.0 is an animation tool that allows users to convert videos to animations using mixamorig characters. It features FK animation editing, object selection, embedded Python support (only on Windows), and the ability to export to glTF and FBX formats. Users can also utilize Mediapipe to create animations. The tool is designed to assist users in creating animations with ease and flexibility.
anthrax-ai
AnthraxAI is a Vulkan-based game engine that allows users to create and develop 3D games. The engine provides features such as scene selection, camera movement, object manipulation, debugging tools, audio playback, and real-time shader code updates. Users can build and configure the project using CMake and compile shaders using the glslc compiler. The engine supports building on both Linux and Windows platforms, with specific dependencies for each. Visual Studio Code integration is available for building and debugging the project, with instructions provided in the readme for setting up the workspace and required extensions.
Facial-Data-Extractor
Facial Data Extractor is a software designed to extract facial data from images using AI, specifically to assist in character customization for Illusion series games. Currently, it only supports AI Shoujo and Honey Select2. Users can open images, select character card templates, extract facial data, and apply it to character cards in the game. The tool provides measurements for various facial features and allows for some customization, although perfect replication of faces may require manual adjustments.
VisionDepth3D
VisionDepth3D is an all-in-one 3D suite for creators, combining AI depth and custom stereo logic for cinema in VR. The suite includes features like real-time 3D stereo composer with CUDA + PyTorch acceleration, AI-powered depth estimation supporting 25+ models, AI upscaling & interpolation, depth blender for blending depth maps, audio to video sync, smart GUI workflow, and various output formats & aspect ratios. The tool is production-ready, offering advanced parallax controls, streamlined export for cinema, VR, or streaming, and real-time preview overlays.
local-agents
Local Agents is a Godot project focusing on a deterministic 3D simulation with ecology, mammals, and chemical smell fields. It includes features like edible plants, rabbits, smell behavior, wind simulation, and camera controls. The project uses shared voxel infrastructure for simulation and chemistry-driven smell modeling. It also features world generation, runtime simulation, rendering with GPU shaders, and integrated demo controls. The project is designed for scene-first and resource-driven runtime, preferring voxel-native simulation over RigidBody3D.