
Awesome-LLMs-meet-Multimodal-Generation
🔥🔥🔥 A curated list of papers on LLMs-based multimodal generation (image, video, 3D and audio).
Stars: 450
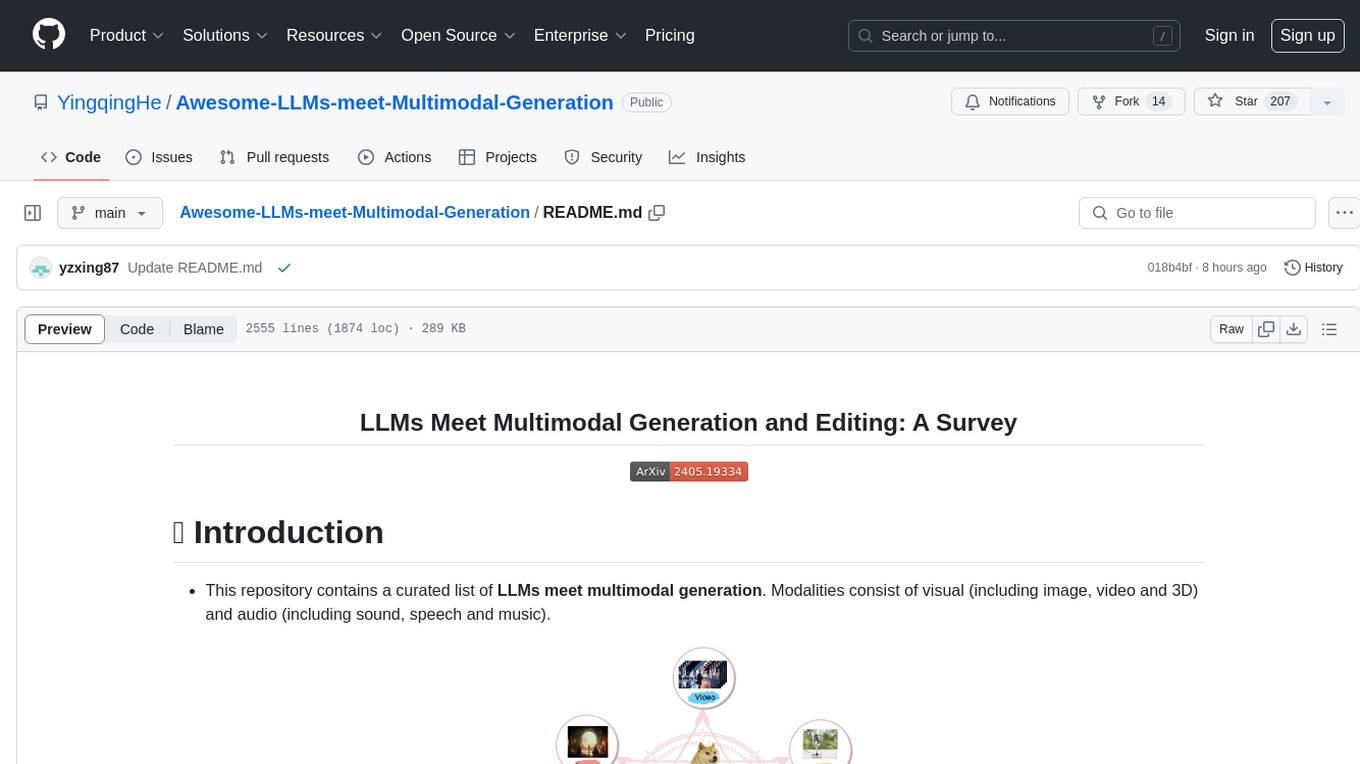
README:
- This repository contains a curated list of LLMs meet multimodal generation. Modalities consist of visual (including image, video and 3D) and audio (including sound, speech and music).

- We welcome any contributions and suggestions to our repository or the addition of your own work. Feel free to make a pull request or leave your comments!!
- 🤗 Introduction
- 📋 Contents
- 💘 Tips
- 📍 Multimodal Generation
- 📍 Multimodal Editing
- 📍 Multimodal Agents
- 📍 Multimodal Understanding with LLMs
- 📍 Multimodal LLM Safety
- 📍 Related Surveys
- 👨💻 Team
- 😉 Citation
- ⭐️ Star History
- ✅ Paper searching via catatogue: directly clicking the content of the catatogue to select the area of your research and browse related papers.
-
✅ Paper searching via author name: Free feel to search papers of a specific author via
ctrl + Fand then type the author name. The dropdown list of authors will automatically expand when searching. -
✅ Paper searching via tag: You can also search the related papers via the following tags:
customization,iteractive,human motion generationtokenizer. (More tags are ongoing)
-
I Think, Therefore I Diffuse: Enabling Multimodal In-Context Reasoning in Diffusion Models (12 Feb 2025)
Zhenxing Mi, Kuan-Chieh Wang, Guocheng Qian, et al.
Zhenxing Mi, Kuan-Chieh Wang, Guocheng Qian, Hanrong Ye, Runtao Liu, Sergey Tulyakov, Kfir Aberman, Dan Xu -
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning (18 Dec 2024)
Shengbang Tong, David Fan, Jiachen Zhu, et al.
Shengbang Tong, David Fan, Jiachen Zhu, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, Zhuang Liu -
X-Prompt: Towards Universal In-Context Image Generation in Auto-Regressive Vision Language Foundation Models (2 Dec 2024)
Zeyi Sun, Ziyang Chu, Pan Zhang, et al.
Zeyi Sun, Ziyang Chu, Pan Zhang, Tong Wu, Xiaoyi Dong, Yuhang Zang, Yuanjun Xiong, Dahua Lin, Jiaqi Wang -
Cosmos Tokenizer: A suite of image and video neural tokenizers (06 Nov 2024)
Fitsum Reda, Jinwei Gu, Xian Liu et al.
Fitsum Reda, Jinwei Gu, Xian Liu, Songwei Ge, Ting-Chun Wang, Haoxiang Wang, Ming-Yu Liutokenizer -
[ICLR 2025 Spotlight] Rare-to-Frequent: Unlocking Compositional Generation Power of Diffusion Models on Rare Concepts with LLM Guidance (29 Oct 2024)
Dongmin Park, Sebin Kim, Taehong Moon et al.
Dongmin Park, Sebin Kim, Taehong Moon, Minkyu Kim, Kangwook Lee, Jaewoong Cho -
ElasticTok: Adaptive Tokenization for Image and Video (10 Oct 2024)
Wilson Yan, Matei Zaharia, Volodymyr Mnih et al.
Wilson Yan, Matei Zaharia, Volodymyr Mnih, Pieter Abbeel, Aleksandra Faust, Hao Liutokenizer -
DART: Denoising Autoregressive Transformer for Scalable Text-to-Image Generation (10 Oct 2024)
Jiatao Gu, Yuyang Wang, Yizhe Zhang et al.
Jiatao Gu, Yuyang Wang, Yizhe Zhang, Qihang Zhang, Dinghuai Zhang, Navdeep Jaitly, Josh Susskind, Shuangfei Zhai -
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation (6 Sep 2024)
Yecheng Wu, Zhuoyang Zhang, Junyu Chen et al.
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, Song Han, Yao Lu -
OmniTokenizer: A Joint Image-Video Tokenizer for Visual Generation (13 Jun 2024)
Junke Wang, Yi Jiang, Zehuan Yuan et al.
Junke Wang, Yi Jiang, Zehuan Yuan, Binyue Peng, Zuxuan Wu, Yu-Gang Jiangtokenizer -
InstantUnify: Integrates Multimodal LLM into Diffusion Models (Aug 2024)
Qixun Wang, Xu Bai, Rui Wang et al.
Qixun Wang, Xu Bai, Rui Wang, Haofan Wang -
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation (22 Aug 2024)
Jinheng Xie, Weijia Mao, Zechen Bai, et al.
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, Mike Zheng Shou -
Image Textualization: An Automatic Framework for Creating Accurate and Detailed Image Descriptions (11 Jun 2024)
Renjie Pi, Jianshu Zhang, Jipeng Zhang et al.
Renjie Pi, Jianshu Zhang, Jipeng Zhang, Rui Pan, Zhekai Chen, Tong Zhang -
T2S-GPT: Dynamic Vector Quantization for Autoregressive Sign Language Production from Text (11 Jun 2024)
[ACL 2024] Aoxiong Yin, Haoyuan Li, Kai Shen et al.
Aoxiong Yin, Haoyuan Li, Kai Shen, Siliang Tang, Yueting Zhuang -
Open-World Human-Object Interaction Detection via Multi-modal Prompts (11 Jun 2024)
Jie Yang, Bingliang Li, Ailing Zeng et al.
Jie Yang, Bingliang Li, Ailing Zeng, Lei Zhang, Ruimao Zhang -
Commonsense-T2I Challenge: Can Text-to-Image Generation Models Understand Commonsense? (11 Jun 2024)
Xingyu Fu, Muyu He, Yujie Lu et al.
Xingyu Fu, Muyu He, Yujie Lu, William Yang Wang, Dan Roth -
An Image is Worth 32 Tokens for Reconstruction and Generation (11 Jun 2024)
Qihang Yu, Mark Weber, Xueqing Deng et al.
Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, Liang-Chieh Chen -
TRINS: Towards Multimodal Language Models that Can Read (10 Jun 2024)
[CVPR 2024] Ruiyi Zhang, Yanzhe Zhang, Jian Chen et al.
Ruiyi Zhang, Yanzhe Zhang, Jian Chen, Yufan Zhou, Jiuxiang Gu, Changyou Chen, Tong Sun -
[LlamaGen] Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation (10 Jun 2024)
Peize Sun, Yi Jiang, Shoufa Chen et al.
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, Zehuan Yuan








-
Chameleon: Mixed-Modal Early-Fusion Foundation Models (16 May 2024)
Chameleon Team
-
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation (22 Apr 2024)
Yuying Ge, Sijie Zhao, Jinguo Zhu, et al.
Yuying Ge, Sijie Zhao, Jinguo Zhu, Yixiao Ge, Kun Yi, Lin Song, Chen Li, Xiaohan Ding, Ying Shan -
Graphic Design with Large Multimodal Model (22 Apr 2024)
Yutao Cheng, Zhao Zhang, Maoke Yang, et al.
Yutao Cheng, Zhao Zhang, Maoke Yang, Hui Nie, Chunyuan Li, Xinglong Wu, and Jie Shao -
PMG : Personalized Multimodal Generation with Large Language Models (7 Apr 2024)
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, et al.
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, Xi Xiao -
MineDreamer: Learning to Follow Instructions via Chain-of-Imagination for Simulated-World Control (19 Mar 2024)
Enshen Zhou, Yiran Qin, Zhenfei Yin, et al.
Enshen Zhou, Yiran Qin, Zhenfei Yin, Yuzhou Huang, Ruimao Zhang, Lu Sheng, Yu Qiao, Jing Shao -
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment (8 Mar 2024)
Xiwei Hu, Rui Wang, Yixiao Fang, et al.
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, Gang Yu -
StrokeNUWA: Tokenizing Strokes for Vector Graphic Synthesis (30 Jan 2024)
Zecheng Tang, Chenfei Wu, Zekai Zhang, et al.
Zecheng Tang, Chenfei Wu, Zekai Zhang, Mingheng Ni, Shengming Yin, Yu Liu, Zhengyuan Yang, Lijuan Wang, Zicheng Liu, Juntao Li, Nan Duantokenizer -
DiffusionGPT: LLM-Driven Text-to-Image Generation System (18 Jan 2024)
Jie Qin, Jie Wu, Weifeng Chen, et al.
Jie Qin, Jie Wu, Weifeng Chen, Yuxi Ren, Huixia Li, Hefeng Wu, Xuefeng Xiao, Rui Wang, Shilei Wen -
StarVector: Generating Scalable Vector Graphics Code from Images (17 Dec 2023)
Juan A. Rodriguez, Shubham Agarwal, Issam H. Laradji, et al.
Juan A. Rodriguez, Shubham Agarwal, Issam H. Laradji, Pau Rodriguez, David Vazquez, Christopher Pal, Marco Pedersoli -
VL-GPT: A Generative Pre-trained Transformer for Vision and Language Understanding and Generation (14 Dec 2023)
Jinguo Zhu, Xiaohan Ding, Yixiao Ge, et al.
Jinguo Zhu, Xiaohan Ding, Yixiao Ge, Yuying Ge, Sijie Zhao, Hengshuang Zhao, Xiaohua Wang, Ying Shan -
StoryGPT-V: Large Language Models as Consistent Story Visualizers (13 Dec 2023)
Xiaoqian Shen, Mohamed Elhoseiny
Xiaoqian Shen, Mohamed Elhoseiny -
GENIXER: Empowering Multimodal Large Language Models as a Powerful Data Generator (11 Dec 2023)
Henry Hengyuan Zhao, Pan Zhou, Mike Zheng Shou
Henry Hengyuan Zhao, Pan Zhou, Mike Zheng Shou -
Customization Assistant for Text-to-image Generation (5 Dec 2023)
Yufan Zhou, Ruiyi Zhang, Jiuxiang Gu, et al.
Yufan Zhou, Ruiyi Zhang, Jiuxiang Gu, Tong Suncustomization -
ChatIllusion: Efficient-Aligning Interleaved Generation ability with Visual Instruction Model (29 Nov 2023)
Xiaowei Chi, Yijiang Liu, Zhengkai Jiang, et al.
Xiaowei Chi, Yijiang Liu, Zhengkai Jiang, Rongyu Zhang, Ziyi Lin, Renrui Zhang, Peng Gao, Chaoyou Fu, Shanghang Zhang, Qifeng Liu, Yike Guo -
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback (29 Nov 2023)
Jiao Sun, Deqing Fu, Yushi Hu, et al.
Jiao Sun, Deqing Fu, Yushi Hu, Su Wang, Royi Rassin, Da-Cheng Juan, Dana Alon, Charles Herrmann, Sjoerd van Steenkiste, Ranjay Krishna, Cyrus Rashtchian -
COLE: A Hierarchical Generation Framework for Graphic Design (28 Nov 2023)
Peidong Jia, Chenxuan Li, Zeyu Liu, et al.
Peidong Jia, Chenxuan Li, Zeyu Liu, Yichao Shen, Xingru Chen, Yuhui Yuan, Yinglin Zheng, Dong Chen, Ji Li, Xiaodong Xie, Shanghang Zhang, Baining Guo -
TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering (28 Nov 2023)
Jingye Chen, Yupan Huang, Tengchao Lv, et al.
Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, Furu Wei -
LLMGA: Multimodal Large Language Model based Generation Assistant (27 Nov 2023)
Bin Xia, Shiyin Wang, Yingfan Tao, et al.
Bin Xia, Shiyin Wang, Yingfan Tao, Yitong Wang, Jiaya Jia -
Self-correcting LLM-controlled Diffusion Models (27 Nov 2023)
Tsung-Han Wu, Long Lian, Joseph E. Gonzalez, et al.
Tsung-Han Wu, Long Lian, Joseph E. Gonzalez, Boyi Li, Trevor Darrell -
[ParaDiffusion] Paragraph-to-Image Generation with Information-Enriched Diffusion Model (29 Nov 2023)
Weijia Wu, Zhuang Li, Yefei He, et al.
Weijia Wu, Zhuang Li, Yefei He, Mike Zheng Shou, Chunhua Shen, Lele Cheng, Yan Li, Tingting Gao, Di Zhang, Zhongyuan Wang -
Tokenize and Embed ALL for Multi-modal Large Language Models (8 Nov 2023)
Zhen Yang, Yingxue Zhang, Fandong Meng, et al.
Zhen Yang, Yingxue Zhang, Fandong Meng, Jie Zhoutokenizer -
WordArt Designer: User-Driven Artistic Typography Synthesis using Large Language Models (20 Oct 2023)
Jun-Yan He, Zhi-Qi Cheng, Chenyang Li, et al.
Jun-Yan He, Zhi-Qi Cheng, Chenyang Li, Jingdong Sun, Wangmeng Xiang, Xianhui Lin, Xiaoyang Kang, Zengke Jin, Yusen Hu, Bin Luo, Yifeng Geng, Xuansong Xie, Jingren Zhou -
LLM Blueprint: Enabling Text-to-Image Generation with Complex and Detailed Prompts (16 Oct 2023)
[ICLR 2024] Hanan Gani, Shariq Farooq Bhat, Muzammal Naseer, et al.
Hanan Gani, Shariq Farooq Bhat, Muzammal Naseer, Salman Khan, Peter Wonka -
Making Multimodal Generation Easier: When Diffusion Models Meet LLMs (13 Oct 2023)
Xiangyu Zhao, Bo Liu, Qijiong Liu, et al.
Xiangyu Zhao, Bo Liu, Qijiong Liu, Guangyuan Shi, Xiao-Ming Wu -
Idea2Img: Iterative Self-Refinement with GPT-4V(ision) for Automatic Image Design and Generation (12 Oct 2023)
Zhengyuan Yang, Jianfeng Wang, Linjie Li, et al.
Zhengyuan Yang, Jianfeng Wang, Linjie Li, Kevin Lin, Chung-Ching Lin, Zicheng Liu, Lijuan Wang -
OpenLEAF: Open-Domain Interleaved Image-Text Generation and Evaluation (11 Oct 2023)
Jie An, Zhengyuan Yang, Linjie Li, et al.
Jie An, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Lijuan Wang, Jiebo Luo -
Mini-DALLE3: Interactive Text to Image by Prompting Large Language Models (11 Oct 2023)
Zeqiang Lai, Xizhou Zhu, Jifeng Dai, et al.
Zeqiang Lai, Xizhou Zhu, Jifeng Dai, Yu Qiao, Wenhai Wang -
[DALL-E 3] Improving Image Generation with Better Captions
James Betker, Gabriel Goh, Li Jing, et al.
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, Wesam Manassra, Prafulla Dhariwal, Casey Chu, Yunxin Jiao, Aditya Ramesh -
MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens (3 Oct 2023)
Kaizhi Zheng, Xuehai He, Xin Eric Wang.
-
Making LLaMA SEE and Draw with SEED Tokenizer (2 Oct 2023)
Yuying Ge, Sijie Zhao, Ziyun Zeng, et al.
Yuying Ge, Sijie Zhao, Ziyun Zeng, Yixiao Ge, Chen Li, Xintao Wang, Ying Shantokenizer -
InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists (30 Sep 2023)
Yulu Gan, Sungwoo Park, Alexander Schubert, et al.
Yulu Gan, Sungwoo Park, Alexander Schubert, Anthony Philippakis, Ahmed M. Alaa -
InternLM-XComposer: A Vision-Language Large Model for Advanced Text-image Comprehension and Composition (26 Sep 2023)
Pan Zhang, Xiaoyi Dong, Bin Wang, et al.
Pan Zhang, Xiaoyi Dong, Bin Wang, Yuhang Cao, Chao Xu, Linke Ouyang, Zhiyuan Zhao, Haodong Duan, Songyang Zhang, Shuangrui Ding, Wenwei Zhang, Hang Yan, Xinyue Zhang, Wei Li, Jingwen Li, Kai Chen, Conghui He, Xingcheng Zhang, Yu Qiao, Dahua Lin, Jiaqi Wang -
Text-to-Image Generation for Abstract Concepts (26 Sep 2023)
Jiayi Liao, Xu Chen, Qiang Fu, et al.
Jiayi Liao, Xu Chen, Qiang Fu, Lun Du, Xiangnan He, Xiang Wang, Shi Han, Dongmei Zhang -
DreamLLM: Synergistic Multimodal Comprehension and Creation (20 Sep 2023)
[ICLR 2024] Runpei Dong, Chunrui Han, Yuang Peng, et al.
Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi -
SwitchGPT: Adapting Large Language Models for Non-Text Outputs (14 Sep 2023)
Wang, Xinyu, Bohan Zhuang, and Qi Wu.
-
NExT-GPT: Any-to-Any Multimodal LLM (11 Sep 2023)
Shengqiong Wu, Hao Fei, Leigang Qu, et al.
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, Tat-Seng Chua -
LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation (9 Aug 2023)
Leigang Qu, Shengqiong Wu, Hao Fei, et al. ACM MM 2023
Leigang Qu, Shengqiong Wu, Hao Fei, Liqiang Nie, Tat-Seng Chua -
Planting a SEED of Vision in Large Language Model (16 Jul 2023)
Yuying Ge, Yixiao Ge, Ziyun Zeng, et al.
Yuying Ge, Yixiao Ge, Ziyun Zeng, Xintao Wang, Ying Shan -
Generative Pretraining in Multimodality (11 Jul 2023)
Quan Sun, Qiying Yu, Yufeng Cui, et al.
Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, Xinlong Wang -
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs (30 Jun 2023)
[NeurIPS 2023 Spotlight] Lijun Yu, Yong Cheng, Zhiruo Wang, et al.
Lijun Yu, Yong Cheng, Zhiruo Wang, Vivek Kumar, Wolfgang Macherey, Yanping Huang, David A. Ross, Irfan Essa, Yonatan Bisk, Ming-Hsuan Yang, Kevin Murphy, Alexander G. Hauptmann, Lu Jiang -
Controllable Text-to-Image Generation with GPT-4 (29 May 2023)
Tianjun Zhang, Yi Zhang, Vibhav Vineet, et al.
Tianjun Zhang, Yi Zhang, Vibhav Vineet, Neel Joshi, Xin Wang -
Generating Images with Multimodal Language Models (26 May 2023)
[NeurIPS 2023] Koh, Jing Yu, Daniel Fried, and Ruslan Salakhutdinov.
-
LayoutGPT: Compositional Visual Planning and Generation with Large Language Models (24 May 2023)
[NeurIPS 2023] Weixi Feng, Wanrong Zhu, Tsu-jui Fu, et al.
Weixi Feng, Wanrong Zhu, Tsu-jui Fu, Varun Jampani, Arjun Akula, Xuehai He, Sugato Basu, Xin Eric Wang, William Yang Wang -
Visual Programming for Text-to-Image Generation and Evaluation (24 May 2023)
[NeurIPS 2023] Jaemin Cho, Abhay Zala, Mohit Bansal.
-
LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models (23 May 2023)
Long Lian, Boyi Li, Adam Yala, et al.
Long Lian, Boyi Li, Adam Yala, Trevor Darrell -
Interactive Data Synthesis for Systematic Vision Adaptation via LLMs-AIGCs Collaboration (22 May 2023)
Qifan Yu, Juncheng Li, Wentao Ye, et al.
Qifan Yu, Juncheng Li, Wentao Ye, Siliang Tang, Yueting Zhuang -
LLMScore: Unveiling the Power of Large Language Models in Text-to-Image Synthesis Evaluation (18 May 2023)
[NeurIPS 2023] Yujie Lu, Xianjun Yang, Xiujun Li, et al.
Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, William Yang Wang -
SUR-adapter: Enhancing Text-to-Image Pre-trained Diffusion Models with Large Language Models (9 May 2023)
[ACM MM 2023] Shanshan Zhong, Zhongzhan Huang, Wushao Wen, et al.
Shanshan Zhong, Zhongzhan Huang, Wushao Wen, Jinghui Qin, Liang Lin -
Grounding Language Models to Images for Multimodal Inputs and Outputs (31 Jan 2023)
[ICML 2023] Koh, Jing Yu, Ruslan Salakhutdinov, and Daniel Fried.
-
[RPG-DiffusionMaster] Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs (22 Jan 2024)
[ICML 2024] Ling Yang, Zhaochen Yu, Chenlin Meng, et al.
Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui -
RealCompo: Balancing Realism and Compositionality Improves Text-to-Image Diffusion Models (20 Feb 2024)
Xinchen Zhang, Ling Yang, Yaqi Cai, et al.
Xinchen Zhang, Ling Yang, Yaqi Cai, Zhaochen Yu, Kai-Ni Wang, Jiake Xie, Ye Tian, Minkai Xu, Yong Tang, Yujiu Yang, Bin Cui



































-
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models (11 Nov 2024)
NVIDIA: Yuval Atzmon, Maciej Bala, Yogesh Balaji, et al.
NVIDIA: Yuval Atzmon, Maciej Bala, Yogesh Balaji, Tiffany Cai, Yin Cui, Jiaojiao Fan, Yunhao Ge, Siddharth Gururani, Jacob Huffman, Ronald Isaac, Pooya Jannaty, Tero Karras, Grace Lam, J. P. Lewis, Aaron Licata, Yen-Chen Lin, Ming-Yu Liu, Qianli Ma, Arun Mallya, Ashlee Martino-Tarr, Doug Mendez, Seungjun Nah, Chris Pruett, Fitsum Reda, Jiaming Song, Ting-Chun Wang, Fangyin Wei, Xiaohui Zeng, Yu Zeng, Qinsheng Zhang -
InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation (3 Apr 2024)
Haofan Wang, Matteo Spinelli, Qixun Wang, et al.
Haofan Wang, Matteo Spinelli, Qixun Wang, Xu Bai, Zekui Qin, Anthony Chen -
InstantID: Zero-shot Identity-Preserving Generation in Seconds (15 Jan 2024)
Qixun Wang, Xu Bai, Haofan Wang, et al.
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen, Huaxia Li, Xu Tang, Yao Hu -
PIXART-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis (30 Sep 2023)
[ICLR 2024] Junsong Chen, Jincheng Yu, Chongjian Ge, et al.
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, Zhenguo Li -
TextDiffuser: Diffusion Models as Text Painters (18 May 2023)
[NeurIPS 2023] Jingye Chen, Yupan Huang, Tengchao Lv, et al.
Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, Furu Wei -
TiGAN: Text-Based Interactive Image Generation and Manipulation (Dec 2022)
[AAAI 2022] Yufan Zhou, Ruiyi Zhang, Jiuxiang Gu, et al.
Yufan Zhou, Ruiyi Zhang, Jiuxiang Gu, Chris Tensmeyer, Tong Yu,Changyou Chen, Jinhui Xu, Tong SunTags:
iteractive -
Multi-Concept Customization of Text-to-Image Diffusion (8 Dec 2022)
[CVPR 2023] Nupur Kumari, Bingliang Zhang, Richard Zhang, et al.
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, Jun-Yan Zhu
Tags:customization -
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation (25 Aug 2022)
[CVPR 2023] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, et al.
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman
Tags:customization -
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion (2 Aug 2022)
Rinon Gal, Yuval Alaluf, Yuval Atzmon, et al.
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, Daniel Cohen-Or
Tags:customization -
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (23 May 2022)
[NeurIPS 2022]Saharia, Chitwan Chan, William Saxena, Saurabh Li, Lala Whang, Jay Denton, Emily L Ghasemipour, Kamyar Gontijo Lopes, Raphael Karagol Ayan, Burcu Salimans, Tim others
-
High-Resolution Image Synthesis with Latent Diffusion Models (20 Dec 2021)
[CVPR 2022 (Oral)]Rombach, Robin Blattmann, Andreas Lorenz, et al.
Rombach, Robin Blattmann, Andreas Lorenz, Dominik Esser, Patrick Ommer, Bj{"o}rn






-
MIMIC-IT: Multi-Modal In-Context Instruction Tuning (8 Jun 2023)
[NeurIPS 2023] Bo Li, Yuanhan Zhang, Liangyu Chen, et al.
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, Ziwei Liu -
[LAION-Glyph] GlyphControl: Glyph Conditional Control for Visual Text Generation (29 May 2023)
[NeurIPS 2023] Yukang Yang, Dongnan Gui, Yuhui Yuan, et al.
Yukang Yang, Dongnan Gui, Yuhui Yuan, Weicong Liang, Haisong Ding, Han Hu, Kai Chen -
[MARIO-10M] TextDiffuser: Diffusion Models as Text Painters (18 May 2023)
[NeurIPS 2023] Jingye Chen, Yupan Huang, Tengchao Lv, et al.
Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, Furu Wei -
DataComp: In search of the next generation of multimodal datasets (27 Apr 2023)
[NeurIPS 2023] Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, et al.
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexander Ratner, Shuran Song, Hannaneh Hajishirzi, Ali Farhadi, Romain Beaumont, Sewoong Oh, Alex Dimakis, Jenia Jitsev, Yair Carmon, Vaishaal Shankar, Ludwig Schmidt -
[LLava-instruct] Visual Instruction Tuning (17 Apr 2023)
[NeurIPS 2023] Haotian Liu, Chunyuan Li, Qingyang Wu, et al.
Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee -
Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved with Text (14 Apr 2023)
[NeurIPS 2023] Wanrong Zhu, Jack Hessel, Anas Awadalla, et al.
Wanrong Zhu, Jack Hessel, Anas Awadalla, Samir Yitzhak Gadre, Jesse Dodge, Alex Fang, Youngjae Yu, Ludwig Schmidt, William Yang Wang, Yejin Choi -
Language Is Not All You Need: Aligning Perception with Language Models (27 Feb 2023)
[NeurIPS 2023] Shaohan Huang, Li Dong, Wenhui Wang, et al.
Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Barun Patra, Qiang Liu, Kriti Aggarwal, Zewen Chi, Johan Bjorck, Vishrav Chaudhary, Subhojit Som, Xia Song, Furu Wei -
COYO-700M: Image-Text Pair Dataset (31 Aug 2022)
-
LAION-5B: An open large-scale dataset for training next generation image-text models (16 Oct 2022)
[NeurIPS 2022] Christoph Schuhmann, Romain Beaumont, Richard Vencu, et al.
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, Jenia Jitsev -
LAION COCO: 600M SYNTHETIC CAPTIONS FROM LAION2B-EN (15 Sep 2022)
Christoph Schuhmann, Andreas Köpf , Theo Coombes, et al.
Christoph Schuhmann, Andreas Köpf , Theo Coombes, Richard Vencu, Benjamin Trom , Romain Beaumont -
[M3W] Flamingo: a Visual Language Model for Few-Shot Learning (29 Apr 2022)
[NeurIPS 2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, et al.
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan -
[LAION-FACE]General Facial Representation Learning in a Visual-Linguistic Manner (6 Dec 2021)
[NeurIPS 2021] Yinglin Zheng, Hao Yang, Ting Zhang, et al.
Yinglin Zheng, Hao Yang, Ting Zhang, Jianmin Bao, Dongdong Chen, Yangyu Huang, Lu Yuan, Dong Chen, Ming Zeng, Fang Wen -
[LAION-400M] Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs (3 Nov 2021)
[NeurIPS 2021] Christoph Schuhmann, Richard Vencu, Romain Beaumont, et al.
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, Aran Komatsuzaki -
WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning (2 Mar 2021)
[SIGIR 2021] Krishna Srinivasan, Karthik Raman, Jiecao Chen, et al.
Krishna Srinivasan, Karthik Raman, Jiecao Chen, Michael Bendersky, Marc Najork -
Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts (17 Feb 2021)
[CVPR 2021] Soravit Changpinyo, Piyush Sharma, Nan Ding, et al.
Soravit Changpinyo, Piyush Sharma, Nan Ding, Radu Soricut -
[ALIGN] Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision (11 Feb 2021)
[ICML 2021] Chao Jia, Yinfei Yang, Ye Xia, et al.
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig -
[MS COCO] Microsoft COCO: Common Objects in Context (1 May 2014)
[ECCV 2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, et al.
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollár -
[Im2Text] Describing Images Using 1 Million Captioned Photographs (12 Dec 2011)
[NeurIPS 2011] Vicente Ordonez, Girish Kulkarni, Tamara Berg







-
Loong: Generating Minute-level Long Videos with Autoregressive Language Models (3 Oct 2024)
Yuqing Wang, Tianwei Xiong, Daquan Zhou, et al.
Yuqing Wang, Tianwei Xiong, Daquan Zhou, Zhijie Lin, Yang Zhao, Bingyi Kang, Jiashi Feng, Xihui Liu -
Compositional 3D-aware Video Generation with LLM Director (31 Aug 2024)
Hanxin Zhu, Tianyu He, Anni Tang, et al.
Hanxin Zhu, Tianyu He, Anni Tang, Junliang Guo, Zhibo Chen, Jiang Bian -
Anim-Director: A Large Multimodal Model Powered Agent for Controllable Animation Video Generation (19 Aug 2024)
[SIGGRAPH Asia 2024] Yunxin Li, Haoyuan Shi, Baotian Hu, et al.
Yunxin Li, Haoyuan Shi, Baotian Hu, Longyue Wang, Jiashun Zhu, Jinyi Xu, Zhen Zhao, Min Zhang -
[BSQ-ViT] Image and Video Tokenization with Binary Spherical Quantization (11 Jun 2024)
[Tech Report]Yue Zhao, Yuanjun Xiong, Philipp Krähenbühl
tokenizer -
DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation (11 Mar 2024)
Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, et al.
Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, Xingang Wang -
[Sora] Video generation models as world simulators (15 Feb 2024)
Tim Brooks, Bill Peebles, Connor Holmes, et al.
Tim Brooks and Bill Peebles and Connor Holmes and Will DePue and Yufei Guo and Li Jing and David Schnurr and Joe Taylor and Troy Luhman and Eric Luhman and Clarence Ng and Ricky Wang and Aditya Ramesh -
[LWM] World Model on Million-Length Video And Language With Blockwise RingAttention (13 Feb 2024)
Hao Liu, Wilson Yan, Matei Zaharia, et al.
Hao Liu, Wilson Yan, Matei Zaharia, Pieter Abbeel -
[LGVI] Towards Language-Driven Video Inpainting via Multimodal Large Language Models (18 Jan 2024)
Jianzong Wu, Xiangtai Li, Chenyang Si, et al.
Jianzong Wu, Xiangtai Li, Chenyang Si, Shangchen Zhou, Jingkang Yang, Jiangning Zhang, Yining Li, Kai Chen, Yunhai Tong, Ziwei Liu, Chen Change Loy -
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization: Content-Consistent Multi-Scene Video Generation with LLM (2 Jan 2024)
Yang Jin, Zhicheng Sun, Kun Xu, et al.
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, Yadong Mutokenizer -
VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM (2 Jan 2024)
Fuchen Long, Zhaofan Qiu, Ting Yao, et al.
Fuchen Long, Zhaofan Qiu, Ting Yao, Tao Mei -
[PRO-Motion] Plan, Posture and Go: Towards Open-World Text-to-Motion Generation (22 Dec 2023)
Jinpeng Liu, Wenxun Dai, Chunyu Wang, et al.
Jinpeng Liu, Wenxun Dai, Chunyu Wang, Yiji Cheng, Yansong Tang, Xin Tong -
VideoPoet: A Large Language Model for Zero-Shot Video Generation (21 Dec 2023)
Dan Kondratyuk, Lijun Yu, Xiuye Gu, et al.
Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari, Yair Alon, Vighnesh Birodkar, Yong Cheng, Ming-Chang Chiu, Josh Dillon, Irfan Essa, Agrim Gupta, Meera Hahn, Anja Hauth, David Hendon, Alonso Martinez, David Minnen, David Ross, Grant Schindler, Mikhail Sirotenko, Kihyuk Sohn, Krishna Somandepalli, Huisheng Wang, Jimmy Yan, Ming-Hsuan Yang, Xuan Yang, Bryan Seybold, Lu Jiang -
FlowZero: Zero-Shot Text-to-Video Synthesis with LLM-Driven Dynamic Scene Syntax (27 Nov 2023)
[arXiv 2023] Yu Lu, Linchao Zhu, Hehe Fan, et al.
Yu Lu, Linchao Zhu, Hehe Fan, Yi Yang -
InterControl: Generate Human Motion Interactions by Controlling Every Joint (27 Nov 2023)
Zhenzhi Wang, Jingbo Wang, Dahua Lin, et al.
Zhenzhi Wang, Jingbo Wang, Dahua Lin, Bo Dai
Tags:human motion generation -
MotionLLM: Multimodal Motion-Language Learning with Large Language Models (27 May 2024)
Qi Wu, Yubo Zhao, Yifan Wang, et al.
Qi Wu, Yubo Zhao, Yifan Wang, Yu-Wing Tai, Chi-Keung Tang
Tags:general human motion generation -
GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning (21 Nov 2023)
Jiaxi Lv, Yi Huang, Mingfu Yan, et al.
Jiaxi Lv, Yi Huang, Mingfu Yan, Jiancheng Huang, Jianzhuang Liu, Yifan Liu, Yafei Wen, Xiaoxin Chen, Shifeng Chen -
[LVD] LLM-grounded Video Diffusion Models (29 Sep 2023)
Long Lian, Baifeng Shi, Adam Yala, et al.
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li -
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning (26 Sep 2023)
[arXiv 2023] Han Lin, Abhay Zala, Jaemin Cho, et al.
Han Lin, Abhay Zala, Jaemin Cho, Mohit Bansal -
Free-Bloom: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator (25 Sep 2023)
[NIPS 2023] Hanzhuo Huang, Yufan Feng, Cheng Shi, et al.
Hanzhuo Huang, Yufan Feng, Cheng Shi, Lan Xu, Jingyi Yu, Sibei Yang -
[Dysen-VDM] Empowering Dynamics-aware Text-to-Video Diffusion with Large Language Models (26 Aug 2023)
[CVPR 2024] Hao Fei, Shengqiong Wu, Wei Ji, et al.
Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, Tat-Seng Chua -
[DirecT2V] Large Language Models are Frame-level Directors for Zero-shot Text-to-Video Generation (23 May 2023)
[arXiv 2023] Susung Hong, Junyoung Seo, Sunghwan Hong, et al.
Susung Hong, Junyoung Seo, Sunghwan Hong, Heeseong Shin, Seungryong Kim -
Text2Motion: From Natural Language Instructions to Feasible Plans (21 Mar 2023)
[Autonomous Robots 2023] Kevin Lin, Christopher Agia, Toki Migimatsu, et al.
Kevin Lin, Christopher Agia, Toki Migimatsu, Marco Pavone, Jeannette Bohg







-
OSV: One Step is Enough for High-Quality Image to Video Generation (17 Sep 2024)
Xiaofeng Mao, Zhengkai Jiang, Fu-Yun Wang, et al.
Xiaofeng Mao, Zhengkai Jiang, Fu-Yun Wang, Wenbing Zhu, Jiangning Zhang, Hao Chen, Mingmin Chi, Yabiao Wang -
[PAB] Real-Time Video Generation with Pyramid Attention Broadcast (26 Jun 2024)
Xuanlei Zhao, Xiaolong Jin, Kai Wang, et al.
Xuanlei Zhao, Xiaolong Jin, Kai Wang, Yang You -
Video-Infinity: Distributed Long Video Generation (24 Jun 2024)
Zhenxiong Tan, Xingyi Yang, Songhua Liu, et al.
Zhenxiong Tan, Xingyi Yang, Songhua Liu, Xinchao Wang -
Pandora: Towards General World Model with Natural Language Actions and Video (12 Jun 2024)
Jiannan Xiang, Guangyi Liu, Yi Gu, et al.
Jiannan Xiang, Guangyi Liu, Yi Gu, Qiyue Gao, Yuting Ning, Yuheng Zha, Zeyu Feng, Tianhua Tao, Shibo Hao, Yemin Shi, Zhengzhong Liu, Eric P. Xing, Zhiting Hu -
Text-Animator: Controllable Visual Text Video Generation (25 Jun 2024)
Lin Liu, Quande Liu, Shengju Qian, et al.
Lin Liu, Quande Liu, Shengju Qian, Yuan Zhou, Wengang Zhou, Houqiang Li, Lingxi Xie, Qi Tian -
MotionBooth: Motion-Aware Customized Text-to-Video Generation (25 Jun 2024)
Jianzong Wu, Xiangtai Li, Yanhong Zeng, et al.
Jianzong Wu, Xiangtai Li, Yanhong Zeng, Jiangning Zhang, Qianyu Zhou, Yining Li, Yunhai Tong, Kai Chen -
FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models (24 Jun 2024)
Haonan Qiu, Zhaoxi Chen, Zhouxia Wang, et al.
Haonan Qiu, Zhaoxi Chen, Zhouxia Wang, Yingqing He, Menghan Xia, Ziwei Liu -
Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model (22 Jun 2024)
Min Zhao, Hongzhou Zhu, Chendong Xiang, et al.
Min Zhao, Hongzhou Zhu, Chendong Xiang, Kaiwen Zheng, Chongxuan Li, Jun Zhu -
Image Conductor: Precision Control for Interactive Video Synthesis (21 Jun 2024)
Yaowei Li, Xintao Wang, Zhaoyang Zhang, et al.
Yaowei Li, Xintao Wang, Zhaoyang Zhang, Zhouxia Wang, Ziyang Yuan, Liangbin Xie, Yuexian Zou, Ying Shan -
VIDEOSCORE: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation (21 Jun 2024)
Xuan He, Dongfu Jiang, Ge Zhang, et al.
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, Kai Wang, Quy Duc Do, Yuansheng Ni, Bohan Lyu, Yaswanth Narsupalli, Rongqi Fan, Zhiheng Lyu, Yuchen Lin, Wenhu Chen -
Dreamitate: Real-World Visuomotor Policy Learning via Video Generation (24 Jun 2024)
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, et al.
Junbang Liang, Ruoshi Liu, Ege Ozguroglu, Sruthi Sudhakar, Achal Dave, Pavel Tokmakov, Shuran Song, Carl Vondrick -
[MCM] Motion Consistency Model: Accelerating Video Diffusion with Disentangled Motion-Appearance Distillation (11 Jun 2024)
Yuanhao Zhai, Kevin Lin, Zhengyuan Yang, et al.
Yuanhao Zhai, Kevin Lin, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Chung-Ching Lin, David Doermann, Junsong Yuan, Lijuan Wang -
Searching Priors Makes Text-to-Video Synthesis Better (5 Jun 2024)
Haoran Cheng, Liang Peng, Linxuan Xia, et al.
Haoran Cheng, Liang Peng, Linxuan Xia, Yuepeng Hu, Hengjia Li, Qinglin Lu, Xiaofei He, Boxi Wu -
ZeroSmooth: Training-free Diffuser Adaptation for High Frame Rate Video Generation (3 Jun 2024)
Shaoshu Yang, Yong Zhang, Xiaodong Cun, et al.
Shaoshu Yang, Yong Zhang, Xiaodong Cun, Ying Shan, Ran He -
EasyAnimate: A High-Performance Long Video Generation Method based on Transformer Architecture (30 May 2024)
Sijie Zhao, Yong Zhang, Xiaodong Cun, et al.
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, Ying Shan -
[MOFT] Video Diffusion Models are Training-free Motion Interpreter and Controller (23 Mar 2024)
Zeqi Xiao, Yifan Zhou, Shuai Yang, et al.
Zeqi Xiao, Yifan Zhou, Shuai Yang, Xingang Pan -
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text (21 Mar 2024)
Roberto Henschel, Levon Khachatryan, Daniil Hayrapetyan, et al.
Roberto Henschel, Levon Khachatryan, Daniil Hayrapetyan, Hayk Poghosyan, Vahram Tadevosyan, Zhangyang Wang, Shant Navasardyan, Humphrey Shi -
Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis (22 Feb 2024)
Willi Menapace, Aliaksandr Siarohin, Ivan Skorokhodov, et al.
Willi Menapace, Aliaksandr Siarohin, Ivan Skorokhodov, Ekaterina Deyneka, Tsai-Shien Chen, Anil Kag, Yuwei Fang, Aleksei Stoliar, Elisa Ricci, Jian Ren, Sergey Tulyakov -
VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models (17 Jan 2024)
Haoxin Chen, Yong Zhang, Xiaodong Cun, et al.
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, Ying Shan -
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets (25 Nov 2023)
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, et al.
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, Robin Rombach -
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation (30 Oct 2023)
Haoxin Chen, Menghan Xia, Yingqing He, et al.
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, Ying Shan -
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors (18 Oct 2023)
Jinbo Xing, Menghan Xia, Yong Zhang, et al.
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Xintao Wang, Tien-Tsin Wong, Ying Shan -
FreeNoise: Tuning-Free Longer Video Diffusion via Noise Rescheduling (23 Oct 2023)
Haonan Qiu, Menghan Xia, Yong Zhang, et al.
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xintao Wang, Ying Shan, Ziwei Liu -
Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation (13 Jul 2023)
Yingqing He, Menghan Xia, Haoxin Chen, et al.
Yingqing He, Menghan Xia, Haoxin Chen, Xiaodong Cun, Yuan Gong, Jinbo Xing, Yong Zhang, Xintao Wang, Chao Weng, Ying Shan, Qifeng Chen -
Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance (1 Jun 2023)
Jinbo Xing, Menghan Xia, Yuxin Liu, et al.
Jinbo Xing, Menghan Xia, Yuxin Liu, Yuechen Zhang, Yong Zhang, Yingqing He, Hanyuan Liu, Haoxin Chen, Xiaodong Cun, Xintao Wang, Ying Shan, Tien-Tsin Wong -
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos (3 Apr 2023)
Yue Ma, Yingqing He, Xiaodong Cun, et al.
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Siran Chen, Ying Shan, Xiu Li, Qifeng Chen -
Real-time Controllable Denoising for Image and Video (29 Mar 2023)
[CVPR 2023] Zhaoyang Zhang, Yitong Jiang, Wenqi Shao, et al.
Zhaoyang Zhang, Yitong Jiang, Wenqi Shao, Xiaogang Wang, Ping Luo, Kaimo Lin, Jinwei Gu -
VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation (15 Mar 2023)
Zhengxiong Luo, Dayou Chen, Yingya Zhang, et al.
Zhengxiong Luo, Dayou Chen, Yingya Zhang, Yan Huang, Liang Wang, Yujun Shen, Deli Zhao, Jingren Zhou, Tieniu Tan















-
DLFR-VAE: Dynamic Latent Frame Rate VAE for Video Generation (17 Feb 2025)
Zhihang Yuan, Siyuan Wang, Rui Xie, et al.
Zhihang Yuan, Siyuan Wang, Rui Xie, Hanling Zhang, Tongcheng Fang, Yuzhang Shang, Shengen Yan, Guohao Dai, Yu Wang -
VideoVAE+: Large Motion Video Autoencoding with Cross-modal Video VAE (23 Dec 2024)
Yazhou Xing, Yang Fei, Yingqing He, et al.
Yazhou Xing, Yang Fei, Yingqing He, Jingye Chen, Jiaxin Xie, Xiaowei Chi, Qifeng Chen -
VidTwin: Video VAE with Decoupled Structure and Dynamics (23 Dec 2024)
Yuchi Wang, Junliang Guo, Xinyi Xie, et al.
Yuchi Wang, Junliang Guo, Xinyi Xie, Tianyu He, Xu Sun, Jiang Bian -
VidTok: A Versatile and Open-Source Video Tokenizer (17 Dec 2024)
Anni Tang, Tianyu He, Junliang Guo, et al.
Anni Tang, Tianyu He, Junliang Guo, Xinle Cheng, Li Song, Jiang Bian -
[CVPR 2025] WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model (26 Nov 2024)
Zongjian Li, Bin Lin, Yang Ye, et al.
Zongjian Li, Bin Lin, Yang Ye, Liuhan Chen, Xinhua Cheng, Shenghai Yuan, Li Yuan -
[CVPR 2025] [IV-VAE] Improved Video VAE for Latent Video Diffusion Model (10 Nov 2024)
Pingyu Wu, Kai Zhu, Yu Liu, et al.
Pingyu Wu, Kai Zhu, Yu Liu, Liming Zhao, Wei Zhai, Yang Cao, Zheng-Jun Zha -
[Tech Report] Cosmos Tokenizer: A suite of image and video neural tokenizers (Nov 6, 2024)
Fitsum Reda, Jinwei Gu, Xian Liu, et al.
Fitsum Reda, Jinwei Gu, Xian Liu, Songwei Ge, Ting-Chun Wang, Haoxiang Wang, Ming-Yu Liu -
[NeurIPS 2024] CV-VAE: A Compatible Video VAE for Latent Generative Video Models (30 May 2024)
Sijie Zhao, Yong Zhang, Xiaodong Cun, et al.
Sijie Zhao, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Muyao Niu, Xiaoyu Li, Wenbo Hu, Ying Shan -
[ICLR 2024] [MAGVIT-v2] Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation (9 Oct 2023)
Lijun Yu, José Lezama, Nitesh B. Gundavarapu, et al.
Lijun Yu, José Lezama, Nitesh B. Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G. Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A. Ross, Lu Jiang




-
JavisDiT: Joint Audio-Video Diffusion Transformer with Hierarchical Spatio-Temporal Prior Synchronization (30 Mar 2025)
Kai Liu, Wei Li, Lai Chen, et al.
Kai Liu, Wei Li, Lai Chen, Shengqiong Wu, Yanhao Zheng, Jiayi Ji, Fan Zhou, Rongxin Jiang, Jiebo Luo, Hao Fei, Tat-Seng Chua -
[LVAS-Agent] Long-Video Audio Synthesis with Multi-Agent Collaboration (13 Mar 2025)
Yehang Zhang, Xinli Xu, Xiaojie Xu, et al
Yehang Zhang, Xinli Xu, Xiaojie Xu, Li Liu, Yingcong Chen -
UniForm: A Unified Diffusion Transformer for Audio-Video Generation (6 Feb 2025)
Lei Zhao, Linfeng Feng, Dongxu Ge, et al
Lei Zhao, Linfeng Feng, Dongxu Ge, Fangqiu Yi, Chi Zhang, Xiao-Lei Zhang, Xuelong Li -
TIA2V: Video generation conditioned on triple modalities of text–image–audio (4 Jan 2025)
Minglu Zhao, Wenmin Wang, Rui Zhang, et al.
Minglu Zhao, Wenmin Wang, Rui Zhang, Haomei Jia, Qi Chen -
SAVGBench: Benchmarking Spatially Aligned Audio-Video Generation (18 Dec 2024)
Kazuki Shimada, Christian Simon, Takashi Shibuya, et al.
Kazuki Shimada, Christian Simon, Takashi Shibuya, Shusuke Takahashi, Yuki Mitsufuji -
AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation (19 Dec 2024)
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, et al,
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Ivan Skorokhodov, Alper Canberk, Kwot Sin Lee, Vicente Ordonez, Sergey Tulyakov -
SyncFlow: Temporally Aligned Joint Audio-Video Generation from Text (3 Dec 2024)
Haohe Liu, Gael Le Lan, Xinhao Mei, et al.
Haohe Liu, Gael Le Lan, Xinhao Mei, Zhaoheng Ni, Anurag Kumar, Varun Nagaraja, Wenwu Wang, Mark D. Plumbley, Yangyang Shi, Vikas Chandra -
A Simple but Strong Baseline for Sounding Video Generation: Effective Adaptation of Audio and Video Diffusion Models for Joint Generation (26 Sep 2024)
Masato Ishii, Akio Hayakawa, Takashi Shibuya
Masato Ishii, Akio Hayakawa, Takashi Shibuya, Yuki Mitsufuji -
AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation (11 Jun 2024)
Kai Wang, Shijian Deng, Jing Shi, et al.
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, Yapeng Tian -
Discriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation (28 May 2024)
Akio Hayakawa, Masato Ishii, Takashi Shibuya, et al.
Akio Hayakawa, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji -
AudioScenic: Audio-Driven Video Scene Editing (25 Apr 2024)
Kaixin Shen, Ruijie Quan, Linchao Zhu, et al.
Kaixin Shen, Ruijie Quan, Linchao Zhu, Jun Xiao, Yi Yang -
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation (22 May 2024)
Gwanghyun Kim, Alonso Martinez, Yu-Chuan Su, et al.
Gwanghyun Kim, Alonso Martinez, Yu-Chuan Su, Brendan Jou, José Lezama, Agrim Gupta, Lijun Yu, Lu Jiang, Aren Jansen, Jacob Walker, Krishna Somandepalli -
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model (25 Apr 2024)
Gehui Chen, Guan'an Wang, Xiaowen Huang, et al.
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang -
TAVGBench: Benchmarking Text to Audible-Video Generation (22 Apr 2024)
Yuxin Mao, Xuyang Shen, Jing Zhang, et al.
Yuxin Mao, Xuyang Shen, Jing Zhang, Zhen Qin, Jinxing Zhou, Mochu Xiang, Yiran Zhong, Yuchao Dai -
[ECCV 2024 Oral] ASVA: Audio-Synchronized Visual Animation (8 Mar 2024)
Lin Zhang, Shentong Mo, Yijing Zhang, et al.
Lin Zhang, Shentong Mo, Yijing Zhang, Pedro Morgado -
[CVPR 2024] Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (27 Feb 2024)
Yazhou Xing, Yingqing He, Zeyue Tian, et al.
Yazhou Xing, Yingqing He, Zeyue Tian, Xintao Wang, Qifeng Chen -
TräumerAI: Dreaming Music with StyleGAN (9 Feb 2021)
Dasaem Jeong, Seungheon Doh, Taegyun Kwon (NeurIPS Workshop 2020)
Dasaem Jeong, Seungheon Doh, Taegyun Kwon -
Sound2Sight: Generating Visual Dynamics from Sound and Context (23 Jul 2020)
Anoop Cherian, Moitreya Chatterjee, Narendra Ahuja. (ECCV 2020)
Anoop Cherian, Moitreya Chatterjee, Narendra Ahuja







-
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models (20 Nov 2024)
Ziqi Huang, Fan Zhang, Xiaojie Xu, et al.
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu -
[VideoGen-Eval] The Dawn of Video Generation: Preliminary Explorations with SORA-like Models (7 Oct 2024)
Ailing Zeng, Yuhang Yang, Weidong Chen, et al.
Ailing Zeng, Yuhang Yang, Weidong Chen, Wei Liu -
ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation (26 Jun 2024)
Shenghai Yuan, Jinfa Huang, Yongqi Xu, et al.
Shenghai Yuan, Jinfa Huang, Yongqi Xu, Yaoyang Liu, Shaofeng Zhang, Yujun Shi, Ruijie Zhu, Xinhua Cheng, Jiebo Luo, Li Yuan -
TAVGBench: Benchmarking Text to Audible-Video Generation (22 Apr 2024)
Yuxin Mao, Xuyang Shen, Jing Zhang, et al.
Yuxin Mao, Xuyang Shen, Jing Zhang, Zhen Qin, Jinxing Zhou, Mochu Xiang, Yiran Zhong, Yuchao Dai -
Sora Generates Videos with Stunning Geometrical Consistency (27 Feb 2024)
Xuanyi Li, Daquan Zhou, Chenxu Zhang, et al.
Xuanyi Li, Daquan Zhou, Chenxu Zhang, Shaodong Wei, Qibin Hou, Ming-Ming Cheng -
[CVPR 2024 Highlight] VBench: Comprehensive Benchmark Suite for Video Generative Models (29 Nov 2023)
Ziqi Huang, Yinan He, Jiashuo Yu, et al.
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu -
[CVPR 2024] EvalCrafter: Benchmarking and Evaluating Large Video Generation Models (23 Mar 2024)
Yaofang Liu, Xiaodong Cun, Xuebo Liu, et al.
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, Ying Shan





-
VidGen-1M: A Large-Scale Dataset for Text-to-video Generation (5 Aug 2024)
Zhiyu Tan, Xiaomeng Yang, Luozheng Qin, et al.
Zhiyu Tan, Xiaomeng Yang, Luozheng Qin, Hao Li -
Vript: A Video Is Worth Thousands of Words (10 Jun 2024)
[NIPS 2024 Dataset & Benchmark track] Dongjie Yang, Suyuan Huang, Chengqiang Lu, et al.
Dongjie Yang, Suyuan Huang, Chengqiang Lu, Xiaodong Han, Haoxin Zhang, Yan Gao, Yao Hu, Hai Zhao -
MMTrail: A Multimodal Trailer Video Dataset with Language and Music Descriptions (30 Jul 2024)
Xiaowei Chi, Yatian Wang, Aosong Cheng, et al.
Xiaowei Chi, Yatian Wang, Aosong Cheng, Pengjun Fang, Zeyue Tian, Yingqing He, Zhaoyang Liu, Xingqun Qi, Jiahao Pan, Rongyu Zhang, Mengfei Li, Ruibin Yuan, Yanbing Jiang, Wei Xue, Wenhan Luo, Qifeng Chen, Shanghang Zhang, Qifeng Liu, Yike Guo -
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation (13 Jul 2023)
[ICLR 2024 Spotlight] Yi Wang, Yinan He, Yizhuo Li, et al.
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, Yu Qiao -
[HD-VG-130M] VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation (18 May 2023)
Wenjing Wang, Huan Yang, Zixi Tuo, et al.
Wenjing Wang, Huan Yang, Zixi Tuo, Huiguo He, Junchen Zhu, Jianlong Fu, Jiaying Liu -
[VideoCC3M] Learning Audio-Video Modalities from Image Captions (18 May 2023)
[ECCV 2022] Arsha Nagrani, Paul Hongsuck Seo, Bryan Seybold, et al.
Arsha Nagrani, Paul Hongsuck Seo, Bryan Seybold, Anja Hauth, Santiago Manen, Chen Sun, Cordelia Schmid -
CelebV-Text: A Large-Scale Facial Text-Video Dataset (26 Mar 2023)
[CVPR 2023] Jianhui Yu, Hao Zhu, Liming Jiang, et al.
Jianhui Yu, Hao Zhu, Liming Jiang, Chen Change Loy, Weidong Cai, Wayne Wu -
[HD-VILA-100M] Advancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions (19 Nov 2021)
[CVPR 2022] Hongwei Xue, Tiankai Hang, Yanhong Zeng, et al.
Hongwei Xue, Tiankai Hang, Yanhong Zeng, Yuchong Sun, Bei Liu, Huan Yang, Jianlong Fu, Baining Guo -
[YT-Temporal-180M] MERLOT: Multimodal Neural Script Knowledge Models (4 Jun 2021)
[NeurIPS 2021] Rowan Zellers, Ximing Lu, Jack Hessel, et al.
Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, Yejin Choi -
[WebVid-10M] Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval (1 Apr 2021)
[ICCV 2021] Max Bain, Arsha Nagrani, Gül Varol, et al.
Max Bain, Arsha Nagrani, Gül Varol, Andrew Zisserman -
[WTS70M] Learning Video Representations from Textual Web Supervision (29 Jul 2020)
Jonathan C. Stroud, Zhichao Lu, Chen Sun, et al.
Jonathan C. Stroud, Zhichao Lu, Chen Sun, Jia Deng, Rahul Sukthankar, Cordelia Schmid, David A. Ross -
HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips (7 Jun 2019)
[ICCV 2019] Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, et al.
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, Josef Sivic -
VATEX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research (6 Apr 2019)
[ICCV 2019 Oral] Xin Wang, Jiawei Wu, Junkun Chen, et al.
Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, William Yang Wang -
How2: A Large-scale Dataset for Multimodal Language Understanding (7 Jun 2019)
[NeurIPS 2018] Ramon Sanabria, Ozan Caglayan, Shruti Palaskar, et al.
Ramon Sanabria, Ozan Caglayan, Shruti Palaskar, Desmond Elliott, Loïc Barrault, Lucia Specia, Florian Metze -
[ActivityNet Captions] Dense-Captioning Events in Videos (2 May 2017)
[ICCV 2017] Ranjay Krishna, Kenji Hata, Frederic Ren, et al.
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, Juan Carlos Niebles -
[LSMDC] Movie Description (12 May 2016)
[IJCV 2017] Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, et al.
Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, Niket Tandon, Christopher Pal, Hugo Larochelle, Aaron Courville, Bernt Schiele -
MSR-VTT: A Large Video Description Dataset for Bridging Video and Language (1 Apr 2021)
[CVPR 2016] Jun Xu , Tao Mei , Ting Yao, et al.
Jun Xu , Tao Mei , Ting Yao and Yong Rui









-
SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code (2 Mar 2024)
Ziniu Hu, Ahmet Iscen, Aashi Jain, et al.
Ziniu Hu, Ahmet Iscen, Aashi Jain, Thomas Kipf, Yisong Yue, David A. Ross, Cordelia Schmid, Alireza Fathi -
MotionScript: Natural Language Descriptions for Expressive 3D Human Motions (19 Dec 2023)
Payam Jome Yazdian, Eric Liu, Li Cheng, et al.
Payam Jome Yazdian, Eric Liu, Li Cheng, Angelica Lim -
HOLODECK: Language Guided Generation of 3D Embodied AI Environments (19 Dec 2023)
[CVPR 2024]Yue Yang, Fan-Yun Sun, Luca Weihs, et al.
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, Chris Callison-Burch, Mark Yatskar, Aniruddha Kembhavi, Christopher Clark -
PoseGPT: Chatting about 3D Human Pose (30 Nov 2023)
Yao Feng, Jing Lin, Sai Kumar Dwivedi, et al.
[CVPR 2024] Yao Feng, Jing Lin, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Michael J. Black -
3D-GPT: Procedural 3D MODELING WITH LARGE LANGUAGE MODELS (19 Oct 2023)
Chunyi Sun*, Junlin Han*, Weijian Deng, et al.
Chunyi Sun, Junlin Han, Weijian Deng, Xinlong Wang, Zishan Qin, Stephen Gould



-
DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion (12 Mar 2024)
Yuanze Lin, Ronald Clark, Philip Torr.
Yuanze Lin, Ronald Clark, Philip Torr -
Consistent3D: Towards Consistent High-Fidelity Text-to-3D Generation with Deterministic Sampling Prior (12 Mar 2024)
Zike Wu, Pan Zhou, Xuanyu Yi, et al.
[CVPR 2024]Zike Wu, Pan Zhou, Xuanyu Yi, Xiaoding Yuan, Hanwang Zhang -
AToM: Amortized Text-to-Mesh using 2D Diffusion (1 Feb 2024)
Guocheng Qian, Junli Cao, Aliaksandr Siarohin, et al.
Guocheng Qian, Junli Cao, Aliaksandr Siarohin, Yash Kant, Chaoyang Wang, Michael Vasilkovsky, Hsin-Ying Lee, Yuwei Fang, Ivan Skorokhodov, Peiye Zhuang, Igor Gilitschenski, Jian Ren, Bernard Ghanem, Kfir Aberman, Sergey Tulyakov -
DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior ( 12 Mar 2024)
Tianyu Huang, Yihan Zeng, Zhilu Zhang, et al.
[CVPR 2024]Tianyu Huang, Yihan Zeng, Zhilu Zhang, Wan Xu, Hang Xu, Songcen Xu, Rynson W. H. Lau, Wangmeng Zuo -
UniDream: Unifying Diffusion Priors for Relightable Text-to-3D Generation (14 Dec 2023)
Zexiang Liu, Yangguang Li, Youtian Lin, et al.
Zexiang Liu, Yangguang Li, Youtian Lin, Xin Yu, Sida Peng, Yan-Pei Cao, Xiaojuan Qi, Xiaoshui Huang, Ding Liang, Wanli Ouyang -
Sherpa3D: Boosting High-Fidelity Text-to-3D Generation via Coarse 3D Prior (11 Dec 2023)
[CVPR 2024] Fangfu Liu, Diankun Wu, Yi Wei, et al.
Fangfu Liu, Diankun Wu, Yi Wei, Yongming Rao, Yueqi Duan -
Learn to Optimize Denoising Scores for 3D Generation: A Unified and Improved Diffusion Prior on NeRF and 3D Gaussian Splatting (8 Dec 2023)
Xiaofeng Yang, Yiwen Chen, Cheng Chen, et al.
Xiaofeng Yang, Yiwen Chen, Cheng Chen, Chi Zhang, Yi Xu, Xulei Yang, Fayao Liu, Guosheng Lin -
DreamPropeller: Supercharge Text-to-3D Generation with Parallel Sampling (28 Nov 2023)
Linqi Zhou, Andy Shih, Chenlin Meng, et al.
Linqi Zhou, Andy Shih, Chenlin Meng, Stefano Ermon -
RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D (28 Nov 2023)
[CVPR 2024] Lingteng Qiu, Guanying Chen, Xiaodong Gu, et al.
Lingteng Qiu, Guanying Chen, Xiaodong Gu, Qi Zuo, Mutian Xu, Yushuang Wu, Weihao Yuan, Zilong Dong, Liefeng Bo, Xiaoguang Han -
DreamAvatar: Text-and-Shape Guided 3D Human Avatar Generation via Diffusion Models (30 Nov 2023)
[CVPR 2024] Yukang Cao, Yan-Pei Cao, Kai Han, et al.
Yukang Cao, Yan-Pei Cao, Kai Han, Ying Shan, Kwan-Yee K. Wong -
LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching (2 Dec 2023)
[CVPR 2024] Yixun Liang, Xin Yang, Jiantao Lin, et al.
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiaogang Xu, Yingcong Chen -
GaussianDreamer: Fast Generation from Text to 3D Gaussians by Bridging 2D and 3D Diffusion Models (12 Oct 2023)
[CVPR 2024] Taoran Yi, Jiemin Fang, Junjie Wang, et al.
Taoran Yi, Jiemin Fang, Junjie Wang, Guanjun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Qi Tian, Xinggang Wang -
Text-to-3D using Gaussian Splatting (28 Sep 2023)
[CVPR 2024] Zilong Chen, Feng Wang, Huaping Liu
Zilong Chen, Feng Wang, Huaping Liu -
EfficientDreamer: High-Fidelity and Robust 3D Creation via Orthogonal-view Diffusion Prior (10 Sep 2023)
[CVPR 2024] Zhipeng Hu, Minda Zhao, Chaoyi Zhao, Xinyue Liang, Lincheng Li, Zeng Zhao, Changjie Fan, Xiaowei Zhou, Xin Yu
-
TADA! Text to Animatable Digital Avatars (21 Aug 2023)
[3DV 2024] Tingting Liao, Hongwei Yi, Yuliang Xiu, et al.
Tingting Liao, Hongwei Yi, Yuliang Xiu, Jiaxaing Tang, Yangyi Huang, Justus Thies, Michael J. Black -
SweetDreamer: Aligning Geometric Priors in 2D Diffusion for Consistent Text-to-3D (20 Oct 2023 )
[ICLR 2024] Weiyu Li, Rui Chen, Xuelin Chen, et al.
Weiyu Li, Rui Chen, Xuelin Chen, Ping Tan -
Noise-Free Score Distillation (26 Oct 2023)
[ICLR 2024] Oren Katzir, Or Patashnik, Daniel Cohen-Or, et al.
Oren Katzir, Or Patashnik, Daniel Cohen-Or, Dani Lischinski -
Text-to-3D with Classifier Score Distillation (26 Oct 2023 )
[ICLR 2024] Xin Yu, Yuan-Chen Guo, Yangguang Li, et al.
Xin Yu, Yuan-Chen Guo, Yangguang Li, Ding Liang, Song-Hai Zhang, Xiaojuan Qi -
HiFA: High-fidelity Text-to-3D Generation with Advanced Diffusion Guidance (28 Nov 2023)
[ICLR 2024] Junzhe Zhu, Peiye Zhuang.
Junzhe Zhu, Peiye Zhuang -
MVDream: Multi-view Diffusion for 3D Generation (31 Aug 2023)
[ICLR 2024] Yichun Shi, Peng Wang, Jianglong Ye, et al.
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, Xiao Yang -
DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation (28 Sep 2023)
[ICLR 2024] Jiaxiang Tang, Jiawei Ren, Hang Zhou, et al.
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, Gang Zeng -
Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation (11 Apr 2023)
[ICLR 2024] Junyoung Seo, Wooseok Jang, Min-Seop Kwak, et al.
Junyoung Seo, Wooseok Jang, Min-Seop Kwak, Hyeonsu Kim, Jaehoon Ko, Junho Kim, Jin-Hwa Kim, Jiyoung Lee, Seungryong Kim -
IT3D: Improved Text-to-3D Generation with Explicit View Synthesis (22 Aug 2023)
[AAAI 2024] Yiwen Chen, Chi Zhang, Xiaofeng Yang, et al.
Yiwen Chen, Chi Zhang, Xiaofeng Yang, Zhongang Cai, Gang Yu, Lei Yang, Guosheng Lin -
HD-Fusion: Detailed Text-to-3D Generation Leveraging Multiple Noise Estimation (30 Jul 2023)
[WACV 2024] Jinbo Wu, Xiaobo Gao, Xing Liu, et al.
Jinbo Wu, Xiaobo Gao, Xing Liu, Zhengyang Shen, Chen Zhao, Haocheng Feng, Jingtuo Liu, Errui Ding -
Re-imagine the Negative Prompt Algorithm: Transform 2D Diffusion into 3D, alleviate Janus problem and Beyond (11 Apr 2023)
Mohammadreza Armandpour, Ali Sadeghian, Huangjie Zheng, et al.
Mohammadreza Armandpour, Ali Sadeghian, Huangjie Zheng, Amir Sadeghian, Mingyuan Zhou -
Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures (14 Nov 2022)
[CVPR 2023] Gal Metzer, Elad Richardson, Or Patashnik, et al.
Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, Daniel Cohen-Or -
Magic3D: High-Resolution Text-to-3D Content Creation (18 Nov 2022)
[CVPR 2023 Highlight] Chen-Hsuan Lin, Jun Gao, Luming Tang, et al.
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, Tsung-Yi Lin -
Score Jacobian Chaining: Lifting Pretrained 2D Diffusion Models for 3D Generation (1 Dec 2022)
[CVPR 2023] Haochen Wang, Xiaodan Du, Jiahao Li, et al.
Haochen Wang, Xiaodan Du, Jiahao Li, Raymond A. Yeh, Greg Shakhnarovich -
High-fidelity 3D Face Generation from Natural Language Descriptions (5 May 2023)
[CVPR 2023] Menghua Wu, Hao Zhu, Linjia Huang, et al.
Menghua Wu, Hao Zhu, Linjia Huang, Yiyu Zhuang, Yuanxun Lu, Xun Cao -
RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion (12 Dec 2022)
[CVPR 2023 Highlight] Tengfei Wang, Bo Zhang, Ting Zhang, et al.
Tengfei Wang, Bo Zhang, Ting Zhang, Shuyang Gu, Jianmin Bao, Tadas Baltrusaitis, Jingjing Shen, Dong Chen, Fang Wen, Qifeng Chen, Baining Guo -
ClipFace: Text-guided Editing of Textured 3D Morphable Models (24 Apr 2023)
[SIGGRAPH 2023] Tengfei Wang, Bo Zhang, Ting Zhang, et al.
Tengfei Wang, Bo Zhang, Ting Zhang, Shuyang Gu, Jianmin Bao, Tadas Baltrusaitis, Jingjing Shen, Dong Chen, Fang Wen, Qifeng Chen, Baining Guo -
DreamFusion: Text-to-3D using 2D Diffusion (29 Sep 2022)
[ICLR 2023 Oral] Ben Poole, Ajay Jain, Jonathan T. Barron, et al.
Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall -
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation (25 May 2023)
[NeurIPS 2023 Spotlight] Zhengyi Wang, Cheng Lu, Yikai Wang, et al.
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, Jun Zhu -
HeadSculpt: Crafting 3D Head Avatars with Text (25 May 2023)
[NeurIPS 2023] Xiao Han, Yukang Cao, Kai Han, et al.
Xiao Han, Yukang Cao, Kai Han, Xiatian Zhu, Jiankang Deng, Yi-Zhe Song, Tao Xiang, Kwan-Yee K. Wong -
ATT3D: Amortized Text-to-3D Object Synthesis (6 Jun 2023)
[ICCV 2023] Jonathan Lorraine, Kevin Xie, Xiaohui Zeng, et al.
Jonathan Lorraine, Kevin Xie, Xiaohui Zeng, Chen-Hsuan Lin, Towaki Takikawa, Nicholas Sharp, Tsung-Yi Lin, Ming-Yu Liu, Sanja Fidler, James Lucas -
Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation (24 Mar 2023)
[ICCV 2023] Rui Chen, Yongwei Chen, Ningxin Jiao, et al.
Rui Chen, Yongwei Chen, Ningxin Jiao, Kui Jia -
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models (10 Sep 2023)
[ICCV 2023] Lukas Höllein, Ang Cao, Andrew Owens, et al.
Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, Matthias Nießner -
X-Mesh: Towards Fast and Accurate Text-driven 3D Stylization via Dynamic Textual Guidance (28 Mar 2023)
[ICCV 2023] Yiwei Ma, Xiaioqing Zhang, Xiaoshuai Sun, et al.
Yiwei Ma, Xiaioqing Zhang, Xiaoshuai Sun, Jiayi Ji, Haowei Wang, Guannan Jiang, Weilin Zhuang, Rongrong Ji -
StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation (31 May 2023)
Chi Zhang, Yiwen Chen, Yijun Fu, et al.
Chi Zhang, Yiwen Chen, Yijun Fu, Zhenglin Zhou, Gang YU, Billzb Wang, Bin Fu, Tao Chen, Guosheng Lin, Chunhua Shen -
TextMesh: Generation of Realistic 3D Meshes From Text Prompts (24 Apr 2023)
[3DV 2023] Christina Tsalicoglou, Fabian Manhardt, Alessio Tonioni, et al.
Christina Tsalicoglou, Fabian Manhardt, Alessio Tonioni, Michael Niemeyer, Federico Tombari -
Clip-forge: Towards zero-shot text-to-shape generation (28 Apr 2022)
[CVPR 2022] Aditya Sanghi, Hang Chu, Joseph G. Lambourne, et al.
Aditya Sanghi, Hang Chu, Joseph G. Lambourne, Ye Wang, Chin-Yi Cheng, Marco Fumero, Kamal Rahimi Malekshan -
Zero-Shot Text-Guided Object Generation with Dream Fields (2 Dec 2021)
[CVPR 2022] Ajay Jain, Ben Mildenhall, Jonathan T. Barron, et al.
Ajay Jain, Ben Mildenhall, Jonathan T. Barron, Pieter Abbeel, Ben Poole -
Text2Mesh: Text-Driven Neural Stylization for Meshes (6 Dec 2021)
[CVPR 2022] Oscar Michel, Roi Bar-On, Richard Liu, et al.
Oscar Michel, Roi Bar-On, Richard Liu, Sagie Benaim, Rana Hanocka -
TANGO: Text-driven Photorealistic and Robust 3D Stylization via Lighting Decomposition (20 Oct 2022)
[NeurIPS 2022 Spotlight] Yongwei Chen, Rui Chen, Jiabao Lei, et al.
Yongwei Chen, Rui Chen, Jiabao Lei, Yabin Zhang, Kui Jia -
CLIP-Mesh: Generating textured meshes from text using pretrained image-text models (24 Mar 2022)
[SIGGRAPH ASIA 2022] Nasir Mohammad Khalid, Tianhao Xie, Eugene Belilovsky, et al.
Nasir Mohammad Khalid, Tianhao Xie, Eugene Belilovsky, Tiberiu Popa -
MotionCLIP: Exposing Human Motion Generation to CLIP Space (15 Mar 2022)
[ECCV 2022] Guy Tevet, Brian Gordon, Amir Hertz, et al.
Guy Tevet, Brian Gordon, Amir Hertz, Amit H. Bermano, Daniel Cohen-Or





































-
Objaverse-XL: A Universe of 10M+ 3D Objects (11 Jul 2023)
Matt Deitke, Dustin Schwenk, Jordi Salvador, et al.
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram Voleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl Vondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, Ali Farhadi -
Objaverse: A Universe of Annotated 3D Objects (15 Dec 2022)
[CVPR 2023] Matt Deitke, Dustin Schwenk, Jordi Salvador, et al.
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, Ali Farhadi

-
SongComposer: A Large Language Model for Lyric and Melody Composition in Song Generation (27 Feb 2024)
Shuangrui Ding, Zihan Liu, Xiaoyi Dong, et al.
Shuangrui Ding, Zihan Liu, Xiaoyi Dong, Pan Zhang, Rui Qian, Conghui He, Dahua Lin, Jiaqi Wang -
ChatMusician: Understanding and Generating Music Intrinsically with LLM (25 Feb 2024)
Ruibin Yuan, Hanfeng Lin, Yi Wang, et al.
Ruibin Yuan, Hanfeng Lin, Yi Wang, Zeyue Tian, Shangda Wu, Tianhao Shen, Ge Zhang, Yuhang Wu, Cong Liu, Ziya Zhou, Ziyang Ma, Liumeng Xue, Ziyu Wang, Qin Liu, Tianyu Zheng, Yizhi Li, Yinghao Ma, Yiming Liang, Xiaowei Chi, Ruibo Liu, Zili Wang, Pengfei Li, Jingcheng Wu, Chenghua Lin, Qifeng Liu, Tao Jiang, Wenhao Huang, Wenhu Chen, Emmanouil Benetos, Jie Fu, Gus Xia, Roger Dannenberg, Wei Xue, Shiyin Kang, Yike Guo -
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling (19 Feb 2024)
Jun Zhan, Junqi Dai, Jiasheng Ye, et al.
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, Hang Yan, Jie Fu, Tao Gui, Tianxiang Sun, Yugang Jiang, Xipeng Qiu -
Boosting Large Language Model for Speech Synthesis: An Empirical Study (30 Dec 2023)
Hongkun Hao, Long Zhou, Shujie Liu, et al.
Hongkun Hao, Long Zhou, Shujie Liu, Jinyu Li, Shujie Hu, Rui Wang, Furu Wei -
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action (28 Dec 2023)
Jiasen Lu, Christopher Clark, Sangho Lee, et al.
Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, Aniruddha Kembhavi -
M2UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models (19 Nov 2023)
Atin Sakkeer Hussain, Shansong Liu, Chenshuo Sun, et al.
Atin Sakkeer Hussain, Shansong Liu, Chenshuo Sun, Ying Shan -
LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT (7 Oct 2023)
Jiaming Wang, Zhihao Du, Qian Chen, et al.
Jiaming Wang, Zhihao Du, Qian Chen, Yunfei Chu, Zhifu Gao, Zerui Li, Kai Hu, Xiaohuan Zhou, Jin Xu, Ziyang Ma, Wen Wang, Siqi Zheng, Chang Zhou, Zhijie Yan, Shiliang Zhang -
LLaSM: Large Language and Speech Model (30 Aug 2023)
Yu Shu, Siwei Dong, Guangyao Chen, et al.
Yu Shu, Siwei Dong, Guangyao Chen, Wenhao Huang, Ruihua Zhang, Daochen Shi, Qiqi Xiang, Yemin Shi -
AudioPaLM: A Large Language Model That Can Speak and Listen (22 Jun 2023)
Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, et al.
Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, Hannah Muckenhirn, Dirk Padfield, James Qin, Danny Rozenberg, Tara Sainath, Johan Schalkwyk, Matt Sharifi, Michelle Tadmor Ramanovich, Marco Tagliasacchi, Alexandru Tudor, Mihajlo Velimirović, Damien Vincent, Jiahui Yu, Yongqiang Wang, Vicky Zayats, Neil Zeghidour, Yu Zhang, Zhishuai Zhang, Lukas Zilka, Christian Frank -
Pengi: An Audio Language Model for Audio Tasks (19 May 2023)
Soham Deshmukh, Benjamin Elizalde, Rita Singh, et al.
Soham Deshmukh, Benjamin Elizalde, Rita Singh, Huaming Wang -
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities (18 May 2023)
Dong Zhang, Shimin Li, Xin Zhang, et al.
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, Xipeng Qiu -
Sparks of Artificial General Intelligence: Early experiments with GPT-4 (22 Mar 2023)
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al.
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang








-
Audiobox: Unified Audio Generation with Natural Language Prompts (25 Dec 2023)
Apoorv Vyas, Bowen Shi, Matthew Le
-
Music ControlNet: Multiple Time-varying Controls for Music Generation (13 Nov 2023)
Shih-Lun Wu, Chris Donahue, Shinji Watanabe, et al.
Shih-Lun Wu, Chris Donahue, Shinji Watanabe, Nicholas J. Bryan -
Loop Copilot: Conducting AI Ensembles for Music Generation and Iterative Editing (19 Oct 2023)
Yixiao Zhang, Akira Maezawa, Gus Xia, et al.
Yixiao Zhang, Akira Maezawa, Gus Xia, Kazuhiko Yamamoto, Simon Dixon -
MusicAgent: An AI Agent for Music Understanding and Generation with Large Language Models (18 Oct 2023)
Dingyao Yu, Kaitao Song, Peiling Lu, et al.
Dingyao Yu, Kaitao Song, Peiling Lu, Tianyu He, Xu Tan, Wei Ye, Shikun Zhang, Jiang Bian -
UniAudio: An Audio Foundation Model Toward Universal Audio Generation (1 Oct 2023)
Dongchao Yang, Jinchuan Tian, Xu Tan
-
AudioLM: a Language Modeling Approach to Audio Generation (7 Sep 2022)
Zalán Borsos, Raphaël Marinier, Damien Vincent, et al. (IEEE/ACM Transactions on Audio, Speech, and Language Processing)
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, Neil Zeghidour -
Wavjourney: Compositional audio creation with large language models (26 Jul 2023)
Xubo Liu, Zhongkai Zhu, Haohe Liu, et al.
Xubo Liu, Zhongkai Zhu, Haohe Liu, Yi Yuan, Meng Cui, Qiushi Huang, Jinhua Liang, Yin Cao, Qiuqiang Kong, Mark D. Plumbley, Wenwu Wang -
Investigating the Utility of Surprisal from Large Language Models for Speech Synthesis Prosody (16 Jun 2023)
Sofoklis Kakouros, Juraj Šimko, Martti Vainio, et al. (2023 SSW)
Sofoklis Kakouros, Juraj Šimko, Martti Vainio, Antti Suni -
Simple and Controllable Music Generation (8 Jun 2023)
Jade Copet, Felix Kreuk, Itai Gat, et al.
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, Alexandre Défossez -
Make-An-Audio 2: Temporal-Enhanced Text-to-Audio Generation (29 May 2023)
Jiawei Huang, Yi Ren, Rongjie Huang, et al.
Jiawei Huang, Yi Ren, Rongjie Huang, Dongchao Yang, Zhenhui Ye, Chen Zhang, Jinglin Liu, Xiang Yin, Zejun Ma, Zhou Zhao -
Jukebox: A Generative Model for Music (30 Apr 2020)
Prafulla Dhariwal, Heewoo Jun, Christine Payne, et al.
Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever -
Audiogpt: Understanding and generating speech, music, sound, and talking head (25 Apr 2023)
Rongjie Huang, Mingze Li, Dongchao Yang, et al.
Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, Shinji Watanabe -
TANGO: Text-to-Audio Generation using Instruction Tuned LLM and Latent Diffusion Model (24 Apr 2023)
Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, et al.
Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Soujanya Poria -
Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface (30 Mar 2023)
Yongliang Shen, Kaitao Song, Xu Tan, et al.
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang -
Neural codec language models are zero-shot text to speech synthesizers (5 Jan 2023)
Chengyi Wang, Sanyuan Chen, Yu Wu, et al.
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, Furu Wei -
MusicLM: Generating Music From Text (26 Jan 2023)
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, et al.
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, Christian Frank









-
Libriheavy: a 50,000 hours ASR corpus with punctuation casing and context (15 Sep 2023)
Wei Kang, Xiaoyu Yang, Zengwei Yao, et al.
Wei Kang, Xiaoyu Yang, Zengwei Yao, Fangjun Kuang, Yifan Yang, Liyong Guo, Long Lin, Daniel Povey -
WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition (7 Oct 2021)
BinBin Zhang, Hang Lv, Pengcheng Guo, et al.
BinBin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, Di wu, Zhendong Peng -
Vggsound: A large-scale audio-visual dataset (29 Apr 2020)
Honglie Chen, Weidi Xie, Andrea Vedaldi, et al. (ICASSP)
Honglie Chen, Weidi Xie, Andrea Vedaldi, Andrew Zisserman -
Libri-Light: A Benchmark for ASR with Limited or No Supervision (17 Dec 2019 )
Jacob Kahn, Morgane Rivière, Weiyi Zheng, et al. (ICASSP)
Jacob Kahn, Morgane Rivière, Weiyi Zheng, Evgeny Kharitonov, Qiantong Xu, Pierre-Emmanuel Mazaré, Julien Karadayi, Vitaliy Liptchinsky, Ronan Collobert, Christian Fuegen, Tatiana Likhomanenko, Gabriel Synnaeve, Armand Joulin, Abdel-rahman Mohamed, Emmanuel Dupoux -
The mtg-jamendo dataset for automatic music tagging (15 Jun 2019)
Dmitry Bogdanov, Minz Won, Philip Tovstogan, et al. (ICML)
Dmitry Bogdanov, Minz Won, Philip Tovstogan, Alastair Porter, Xavier Serra -
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech (5 Apr 2019)
Heiga Zen, Viet Dang, Rob Clark, et al.
Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J. Weiss, Ye Jia, Zhifeng Chen, Yonghui Wu -
Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset (29 Oct 2018)
Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, et al.
Curtis Hawthorne, Andriy Stasyuk, Adam Roberts, Ian Simon, Cheng-Zhi Anna Huang, Sander Dieleman, Erich Elsen, Jesse Engel, Douglas Eck -
Audio Set: An ontology and human-labeled dataset for audio events (05 Mar 2017)
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, et al. (TASLP)
Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, Marvin Ritter -
Librispeech: An ASR corpus based on public domain audio books (19 Apr2015)
Vassil Panayotov, Guoguo Chen, Daniel Povey, et al. (ICASSP)
Vassil Panayotov, Guoguo Chen, Daniel Povey, Sanjeev Khudanpur -
Evaluation of Algorithms Using Games: The Case of Music Tagging (26 Oct 2009)
Edith Law, Kris West, Michael Mandel, et al. (ISMIR)
Edith Law, Kris West, Michael Mandel, Mert Bay J. Stephen Downie

-
C3LLM: Conditional Multimodal Content Generation Using Large Language Models (25 May 2024)
Zixuan Wang, Qinkai Duan, Yu-Wing Tai, et al.
Zixuan Wang, Qinkai Duan, Yu-Wing Tai, Chi-Keung Tang -
CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation (30 Nov 2023)
Zineng Tang, Ziyi Yang, Mahmoud Khademi, et al.
Zineng Tang, Ziyi Yang, Mahmoud Khademi, Yang Liu, Chenguang Zhu, Mohit Bansal -
TEAL: Tokenize and Embed ALL for Multi-modal Large Language Models (8 Nov 2023)
Zhen Yang, Yingxue Zhang, Fandong Meng, et al.
Zhen Yang, Yingxue Zhang, Fandong Meng, Jie Zhoutokenizer -
NExT-GPT: Any-to-Any Multimodal LLM (11 Sep 2023)
Shengqiong Wu, Hao Fei, Leigang Qu, et al.
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, Tat-Seng Chua -
CoDi: Any-to-Any Generation via Composable Diffusion (19 May 2023)
[NeurIPS 2023] Zineng Tang, Ziyi Yang, Chenguang Zhu, et al.
Zineng Tang, Ziyi Yang, Chenguang Zhu, Michael Zeng, Mohit Bansal

-
DiffSHEG: A Diffusion-Based Approach for Real-Time Speech-driven Holistic 3D Expression and Gesture Generation (9 Jan 2024)
[CVPR 2024] Junming Chen, et al.
Junming Chen, Yunfei Liu, Jianan Wang, Ailing Zeng, Yu Li, Qifeng Chen -
Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (27 Feb 2024)
[CVPR 2024] Yazhou Xing, Yingqing He, Zeyue Tian, et al.
Yazhou Xing, Yingqing He, Zeyue Tian, Xintao Wang, Qifeng Chen

-
UltraEdit: Instruction-based Fine-Grained Image Editing at Scale (7 Jul 2024)
Haozhe Zhao, Xiaojian Ma, Liang Chen, et al.
Haozhe Zhao, Xiaojian Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, Baobao Chang -
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing (27 May 2024)
Xinyu Zhang, Mengxue Kang, Fei Wei, et al.
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma -
SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models (11 Dec 2023)
[CVPR 2024] Yuzhou Huang, Liangbin Xie, Xintao Wang, et al.
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, Ying Shan -
Self-correcting LLM-controlled Diffusion Models (27 Nov 2023)
[CVPR 2024] Tsung-Han Wu, Long Lian, Joseph E. Gonzalez, et al.
Tsung-Han Wu, Long Lian, Joseph E. Gonzalez, Boyi Li, Trevor Darrell -
Emu Edit: Precise Image Editing via Recognition and Generation Tasks (16 Nov 2023)
[ArXiv 2023] Shelly Sheynin, Adam Polyak, Uriel Singer, et al.
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, Yaniv Taigman -
Guiding Instruction-based Image Editing via Multimodal Large Language Models
[ICLR 2024 (Spotlight)] Tsu-Jui Fu, Wenze Hu, Xianzhi Du, et al.
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, Zhe Gan -
CHATEDIT: Towards Multi-turn Interactive Facial Image Editing via Dialogue (20 Mar 2023)
[EMNLP 2023] Xing Cui, Zekun Li, Peipei Li, et al.
Xing Cui, Zekun Li, Peipei Li, Yibo Hu, Hailin Shi, Zhaofeng He -
HIVE: Harnessing Human Feedback for Instructional Visual Editing (16 Mar 2023)
Shu Zhang, Xinyi Yang, Yihao Feng, et al.
Shu Zhang, Xinyi Yang, Yihao Feng, Can Qin, Chia-Chih Chen, Ning Yu, Zeyuan Chen, Huan Wang, Silvio Savarese, Stefano Ermon, Caiming Xiong, Ran Xu. -
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models (8 Mar 2023)
Chenfei Wu, Shengming Yin, Weizhen Qi, et al.
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan -
InstructPix2Pix: Learning to Follow Image Editing Instructions (17 Nov 2022)
[CVPR 2023 (Highlight)] Brooks, Tim, Aleksander Holynski, and Alexei A. Efros.






-
SeedEdit: Align Image Re-Generation to Image Editing (11 Nov 2024)
Yichun Shi, Peng Wang, Weilin Huang
-
DiffEditor: Boosting Accuracy and Flexibility on Diffusion-based Image Editing (4 Feb 2024)
[CVPR 2024] Chong Mou, Xintao Wang, Jiechong Song, et al.
Chong Mou, Xintao Wang, Jiechong Song, Ying Shan, Jian Zhang. -
ZONE: Zero-Shot Instruction-Guided Local Editing (28 Dec 2023)
Shanglin Li, Bohan Zeng, Yutang Feng, et al.
Shanglin Li, Bohan Zeng, Yutang Feng, Sicheng Gao, Xuhui Liu, Jiaming Liu, Li Lin, Xu Tang, Yao Hu, Jianzhuang Liu, Baochang Zhang. -
Watch Your Steps: Local Image and Scene Editing by Text Instructions (17 Aug 2023 )
Ashkan Mirzaei, Tristan Aumentado-Armstrong, Marcus A. Brubaker, et al.
Ashkan Mirzaei, Tristan Aumentado-Armstrong, Marcus A. Brubaker, Jonathan Kelly, Alex Levinshtein, Konstantinos G. Derpanis, Igor Gilitschenski. -
Dragondiffusion: Enabling drag-style manipulation on diffusion models (5 Jul 2023)
[ICLR 2024] Chong Mou, Xintao Wang, Jiechong Song, et al.
Chong Mou, Xintao Wang, Jiechong Song, Ying Shan, Jian Zhang. -
Differential Diffusion: Giving Each Pixel Its Strength (1 Jun 2023)
[Arxiv 2023] Thao Nguyen, Yuheng Li, Utkarsh Ojha, et al.
Thao Nguyen, Yuheng Li, Utkarsh Ojha, Yong Jae Lee -
Visual Instruction Inversion: Image Editing via Visual Prompting (26 Jul 2023)
[ArXiv 2023] Thao Nguyen, Yuheng Li, Utkarsh Ojha, et al.
Thao Nguyen, Yuheng Li, Utkarsh Ojha, Yong Jae Lee. -
MasaCtrl: Tuning-Free Mutual Self-Attention Control for Consistent Image Synthesis and Editing (17 Apr 2023)
[ICCV 2023] Mingdeng Cao, Xintao Wang, Zhongang Qi, et al.
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, Yinqiang Zheng. -
PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image Editor (30 Mar 2023)
[ArXiv 2023] Vidit Goel, Elia Peruzzo, Yifan Jiang, et al.
Vidit Goel, Elia Peruzzo, Yifan Jiang, Dejia Xu, Xingqian Xu, Nicu Sebe, Trevor Darrell, Zhangyang Wang, Humphrey Shi. -
Zero-shot Image-to-Image Translation (6 Feb 2023)
[SIGGRAPH 2023] Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, et al.
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, Jun-Yan Zhu. -
SINE: SINgle Image Editing with Text-to-Image Diffusion Models (8 Dec 2022)
[CVPR 2023] Zhixing Zhang, Ligong Han, Arnab Ghosh, et al.
Zhixing Zhang, Ligong Han, Arnab Ghosh, Dimitris Metaxas, Jian Ren. -
Interactive Image Manipulation with Complex Text Instructions (25 Nov 2022)
[WACV 2023] Ryugo Morita, Zhiqiang Zhang, Man M. Ho, et al.
Ryugo Morita, Zhiqiang Zhang, Man M. Ho, Jinjia Zhou. -
Plug-and-Play Diffusion Features for Text-Driven Image-to-Image Translation (22 Nov 2022)
[CVPR 2023] Narek Tumanyan, Michal Geyer, Shai Bagon, et al.
Narek Tumanyan, Michal Geyer, Shai Bagon, Tali Dekel. -
Imagic: Text-Based Real Image Editing with Diffusion Models (17 Oct 2022)
[CVPR 2023] Bahjat Kawar, Shiran Zada, Oran Lang, et al.
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, Michal Irani.







-
Null-text Inversion for Editing Real Images using Guided Diffusion Models
[ICLR 2023] Ron Mokady, Amir Hertz, Kfir Aberman, et al.
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, Daniel Cohen-Or. -
Prompt-to-Prompt Image Editing with Cross Attention Control
[ICLR 2023] Amir Hertz, Ron Mokady, Jay Tenenbaum, et al.
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, Daniel Cohen-Or. -
DiffEdit: Diffusion-based semantic image editing with mask guidance (20 Oct 2022)
[ICLR 2023] Guillaume Couairon, Jakob Verbeek, Holger Schwenk, et al.
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, Matthieu Cord.

-
DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation (6 Oct 2021)
[CVPR 2022] Gwanghyun Kim, Taesung Kwon, Jong Chul Ye.
-
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations (2 Aug 2021)
[ICLR 2022] Chenlin Meng, Yutong He, Yang Song, et al.
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, Stefano Ermon.


-
CONSISTENT VIDEO-TO-VIDEO TRANSFER USING SYNTHETIC DATASET (1 Nov 2023)
Jiaxin Cheng, Tianjun Xiao, Tong He.
-
InstructVid2Vid: Controllable Video Editing with Natural Language Instructions (21 May 2023)
Bosheng Qin, Juncheng Li, Siliang Tang, et al.
Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, Yueting Zhuang.

-
AudioScenic: Audio-Driven Video Scene Editing (25 Apr 2024)
Kaixin Shen, Ruijie Quan, Linchao Zhu, et al.
Kaixin Shen, Ruijie Quan, Linchao Zhu, Jun Xiao, Yi Yang -
LATENTWARP: CONSISTENT DIFFUSION LATENTS FOR ZERO-SHOT VIDEO-TO-VIDEO TRANSLATION (1 Nov 2023)
Yuxiang Bao, Di Qiu, Guoliang Kang, et al.
Yuxiang Bao, Di Qiu, Guoliang Kang, Baochang Zhang, Bo Jin, Kaiye Wang, Pengfei Yan.
-
MagicStick: Controllable Video Editing via Control Handle Transformations (1 Nov 2023)
Yue Ma, Xiaodong Cun, Yingqing He, et al.
Yue Ma, Xiaodong Cun, Yingqing He, Chenyang Qi, Xintao Wang, Ying Shan, Xiu Li, Qifeng Chen) )
-
MagicEdit: High-Fidelity Temporally Coherent Video Editing (28 Aug 2023)
Jun Hao Liew, Hanshu Yan, Jianfeng Zhang, et al.
Jun Hao Liew, Hanshu Yan, Jianfeng Zhang, Zhongcong Xu, Jiashi Feng. -
StableVideo: Text-driven Consistency-aware Diffusion Video Editing (18 Aug 2023)
[ICCV 2023] Wenhao Chai, Xun Guo, Gaoang Wang, et al.
Wenhao Chai, Xun Guo, Gaoang Wang, Yan Lu. -
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing (15 Aug 2023)
Hao Ouyang, Qiuyu Wang, Yuxi Xiao, et al.
Hao Ouyang, Qiuyu Wang, Yuxi Xiao, Qingyan Bai, Juntao Zhang, Kecheng Zheng, Xiaowei Zhou, Qifeng Chen. -
TokenFlow: Consistent Diffusion Features for Consistent Video Editing (19 Jul 2023)
Michal Geyer, Omer Bar-Tal, Shai Bagon, et al.
Michal Geyer, Omer Bar-Tal, Shai Bagon, Tali Dekel. -
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation (13 Jun 2023)
Shuai Yang, Yifan Zhou, Ziwei Liu, et al.
Shuai Yang, Yifan Zhou, Ziwei Liu, Chen Change Loy. -
ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing (26 May 2023)
Min Zhao, Rongzhen Wang, Fan Bao, et al.
Min Zhao, Rongzhen Wang, Fan Bao, Chongxuan Li, Jun Zhu. -
Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts (15 May 2023) Michal Geyer, Omer Bar-Tal, Shai Bagon, Tali Dekel.
-
Pix2Video: Video Editing using Image Diffusion (22 Mar 2023)
[ICCV 2023] Ceylan, Duygu, Chun-Hao P. Huang, and Niloy J. Mitra.
-
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing (16 Mar 2023)
[ICCV 2023] Chenyang Qi, Xiaodong Cun, Yong Zhang, et al.
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, Qifeng Chen. -
Video-P2P: Video Editing with Cross-attention Control (8 Mar 2023)
Shaoteng Liu, Yuechen Zhang, Wenbo Li, et al.
Shaoteng Liu, Yuechen Zhang, Wenbo Li, Zhe Lin, Jiaya Jia. -
Dreamix: Video Diffusion Models are General Video Editors (2 Feb 2023)
Eyal Molad, Eliahu Horwitz, Dani Valevski, et al.
Eyal Molad, Eliahu Horwitz, Dani Valevski, Alex Rav Acha, Yossi Matias, Yael Pritch, Yaniv Leviathan, Yedid Hoshen. -
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (22 Dec 2022)
[ICCV 2023] Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, et al.
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, Mike Zheng Shou. -
M3L: Language-based Video Editing via Multi-Modal Multi-Level Transformers (2 Apr 2021)
[CVPR 2022] Tsu-Jui Fu, Xin Eric Wang, Scott T. Grafton, et al.
Tsu-Jui Fu, Xin Eric Wang, Scott T. Grafton, Miguel P. Eckstein, William Yang Wang.












-
SceneCraft: An LLM Agent for Synthesizing 3D Scene as Blender Code (2 Mar 2024)
Ziniu Hu, Ahmet Iscen, Aashi Jain, et al.
Ziniu Hu, Ahmet Iscen, Aashi Jain, Thomas Kipf, Yisong Yue, David A. Ross, Cordelia Schmid, Alireza Fathi -
3D-GPT: Procedural 3D MODELING WITH LARGE LANGUAGE MODELS (19 Oct 2023)
Chunyi Sun*, Junlin Han*, Weijian Deng, et al.
Chunyi Sun, Junlin Han, Weijian Deng, Xinlong Wang, Zishan Qin, Stephen Gould
-
Paint3D: Paint Anything 3D with Lighting-Less Texture Diffusion Models (16 Nov 2023)
Xianfang Zeng, Xin Chen, Zhongqi Qi, et al.
Xianfang Zeng, Xin Chen, Zhongqi Qi, Wen Liu, Zibo Zhao, Zhibin Wang, Bin Fu, Yong Liu, Gang Yu -
3D Paintbrush: Local Stylization of 3D Shapes with Cascaded Score Distillation (16 Nov 2023)
Dale Decatur, Itai Lang, Kfir Aberman, et al.
Dale Decatur, Itai Lang, Kfir Aberman, Rana Hanocka -
Blending-NeRF: Text-Driven Localized Editing in Neural Radiance Fields (23 Aug 2023)
Hyeonseop Song, Seokhun Choi, Hoseok Do, et al.
Hyeonseop Song, Seokhun Choi, Hoseok Do, Chul Lee, Taehyeong Kim -
SINE: Semantic-driven Image-based NeRF Editing with Prior-guided Editing Field (23 Mar 2023)
[CVPR 2023] Chong Bao, Yinda Zhang, Bangbang Yang, et al.
Chong Bao, Yinda Zhang, Bangbang Yang, Tianxing Fan, Zesong Yang, Hujun Bao, Guofeng Zhang, Zhaopeng Cui -
TextDeformer: Geometry Manipulation using Text Guidance (26 Apr 2023)
[TVCG 2022] William Gao, Noam Aigerman, Thibault Groueix, et al.
William Gao, Noam Aigerman, Thibault Groueix, Vladimir G. Kim, Rana Hanocka -
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions (22 Mar 2023)
[SIGGRAPH Asia 2023] Ayaan Haque, Matthew Tancik, Alexei A. Efros, et al.
Ayaan Haque, Matthew Tancik, Alexei A. Efros, Aleksander Holynski, Angjoo Kanazawa -
DreamEditor: Text-Driven 3D Scene Editing with Neural Fields (23 Jun 2023)
[SIGGRAPH Asia 2023] Jingyu Zhuang, Chen Wang, Lingjie Liu, et al.
Jingyu Zhuang, Chen Wang, Lingjie Liu, Liang Lin, Guanbin Li -
SKED: Sketch-guided Text-based 3D Editing (19 Mar 2023)
[ICCV 2023] Aryan Mikaeili, Or Perel, Mehdi Safaee, et al.
Aryan Mikaeili, Or Perel, Mehdi Safaee, Daniel Cohen-Or, Ali Mahdavi-Amiri -
Blended-NeRF: Zero-Shot Object Generation and Blending in Existing Neural Radiance Fields (22 Jun 2023)
[ICCVW 2023] Ori Gordon, Omri Avrahami, Dani Lischinski.
Ori Gordon, Omri Avrahami, Dani Lischinski -
ClipFace: Text-guided Editing of Textured 3D Morphable Modelssting Neural Radiance Fields (2 Dec 2022)
[SIGGRAPH 2023] Shivangi Aneja, Justus Thies, Angela Dai, et al.
Shivangi Aneja, Justus Thies, Angela Dai, Matthias Nießner -
CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fieldsadiance Fields (9 Dec 2021)
[CVPR 2022] Can Wang, Menglei Chai, Mingming He, et al.
Can Wang, Menglei Chai, Mingming He, Dongdong Chen, Jing Liao








-
Loop Copilot: Conducting AI Ensembles for Music Generation and Iterative Editing (19 Oct 2023)
Yixiao Zhang, Akira Maezawa, Gus Xia, et al.
Yixiao Zhang, Akira Maezawa, Gus Xia, Kazuhiko Yamamoto, Simon Dixon -
UniAudio: An Audio Foundation Model Toward Universal Audio Generation (1 Oct 2023)
Dongchao Yang, Jinchuan Tian, Xu Tan

-
LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing (1 Nov 2023)
Wei-Ge Chen, Irina Spiridonova, Jianwei Yang, et al.
Wei-Ge Chen, Irina Spiridonova, Jianwei Yang, Jianfeng Gao, Chunyuan Li
Tags:Image ChatImage Segmentation,Image GenerationImage Editing -
ControlLLM: Augment Language Models with Tools by Searching on Graphs (26 Oct 2023)
Zhaoyang Liu, Zeqiang Lai, Zhangwei Gao, et al.
Zhaoyang Liu, Zeqiang Lai, Zhangwei Gao, Erfei Cui, Ziheng Li, Xizhou Zhu, Lewei Lu, Qifeng Chen, Yu Qiao, Jifeng Dai, Wenhai Wang
Tags:Image UnderstandingImage GenerationImage EditingVideo UnderstandingVideo GenerationVideo EditingAudio UnderstandingAudio Generation -
ImageBind-LLM: Multi-modality Instruction Tuning (7 Sep 2023)
Jiaming Han, Renrui Zhang, Wenqi Shao, et al.
Jiaming Han, Renrui Zhang, Wenqi Shao, Peng Gao, Peng Xu, Han Xiao, Kaipeng Zhang, Chris Liu, Song Wen, Ziyu Guo, Xudong Lu, Shuai Ren, Yafei Wen, Xiaoxin Chen, Xiangyu Yue, Hongsheng Li, Yu Qiao
Modalities:textimagevideoaudiopoint cloud -
ModelScope-Agent: Building Your Customizable Agent System with Open-source Large Language Models (2 Sep 2023)
Chenliang Li, Hehong Chen, Ming Yan, et al.
Chenliang Li, Hehong Chen, Ming Yan, Weizhou Shen, Haiyang Xu, Zhikai Wu, Zhicheng Zhang, Wenmeng Zhou, Yingda Chen, Chen Cheng, Hongzhu Shi, Ji Zhang, Fei Huang, Jingren Zhou -
InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language (9 May 2023)
Zhaoyang Liu, Yinan He, Wenhai Wang, et al.
Zhaoyang Liu, Yinan He, Wenhai Wang, Weiyun Wang, Yi Wang, Shoufa Chen, Qinglong Zhang, Zeqiang Lai, Yang Yang, Qingyun Li, Jiashuo Yu, Kunchang Li, Zhe Chen, Xue Yang, Xizhou Zhu, Yali Wang, Limin Wang, Ping Luo, Jifeng Dai, Yu Qiao
Condition Modality:textimagevideoaudio -
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face (30 Mar 2023)
Yongliang Shen, Kaitao Song, Xu Tan, et al.
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang -
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models (8 Mar 2023)
Chenfei Wu, Shengming Yin, Weizhen Qi, et al.
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan -
AutoGPT: build & use AI agents






-
Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities (9 Nov 2023)
[CVPR 2024] AJ Piergiovanni, Isaac Noble, Dahun Kim, et al.
AJ Piergiovanni, Isaac Noble, Dahun Kim, Michael S. Ryoo, Victor Gomes, Anelia Angelovatext, video, audio
-
Image Textualization: An Automatic Framework for Creating Accurate and Detailed Image Descriptions (11 Jun 2024)
Renjie Pi, Jianshu Zhang, Jipeng Zhang et al.
Renjie Pi, Jianshu Zhang, Jipeng Zhang, Rui Pan, Zhekai Chen, Tong Zhang -
T2S-GPT: Dynamic Vector Quantization for Autoregressive Sign Language Production from Text (11 Jun 2024)
[ACL 2024] Aoxiong Yin, Haoyuan Li, Kai Shen et al.
Aoxiong Yin, Haoyuan Li, Kai Shen, Siliang Tang, Yueting Zhuang -
Open-World Human-Object Interaction Detection via Multi-modal Prompts (11 Jun 2024)
Jie Yang, Bingliang Li, Ailing Zeng et al.
Jie Yang, Bingliang Li, Ailing Zeng, Lei Zhang, Ruimao Zhang -
Commonsense-T2I Challenge: Can Text-to-Image Generation Models Understand Commonsense? (11 Jun 2024)
Xingyu Fu, Muyu He, Yujie Lu et al.
Xingyu Fu, Muyu He, Yujie Lu, William Yang Wang, Dan Roth -
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks (21 Dec 2023)
Zhe Chen, Jiannan Wu, Wenhai Wang, et al.
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, Jifeng Dai -
LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models (28 Nov 2023)
Yanwei Li, Chengyao Wang, Jiaya Jia
-
CogVLM: Visual Expert for Pretrained Language Models (6 Nov 2023)
Weihan Wang, Qingsong Lv, Wenmeng Yu, et al.
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, Jie Tang -
MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning (14 Oct 2023)
Jun Chen, Deyao Zhu, Xiaoqian Shen, et al.
Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, Mohamed Elhoseiny -
OphGLM: Training an Ophthalmology Large Language-and-Vision Assistant based on Instructions and Dialogue (21 Jun 2023)
Weihao Gao, Zhuo Deng, Zhiyuan Niu, et al.
Weihao Gao, Zhuo Deng, Zhiyuan Niu, Fuju Rong, Chucheng Chen, Zheng Gong, Wenze Zhang, Daimin Xiao, Fang Li, Zhenjie Cao, Zhaoyi Ma, Wenbin Wei, Lan Ma -
InternLM-XComposer: A Vision-Language Large Model for Advanced Text-image Comprehension and Composition (26 Sep 2023)
Pan Zhang, Xiaoyi Dong, Bin Wang, et al.
Pan Zhang, Xiaoyi Dong, Bin Wang, Yuhang Cao, Chao Xu, Linke Ouyang, Zhiyuan Zhao, Haodong Duan, Songyang Zhang, Shuangrui Ding, Wenwei Zhang, Hang Yan, Xinyue Zhang, Wei Li, Jingwen Li, Kai Chen, Conghui He, Xingcheng Zhang, Yu Qiao, Dahua Lin, Jiaqi Wang -
[LaVIT] Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization (9 Sep 2023)
Yang Jin, Kun Xu, Kun Xu, et al.
Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Chao Liao, Jianchao Tan, Quzhe Huang, Bin Chen, Chenyi Lei, An Liu, Chengru Song, Xiaoqiang Lei, Di Zhang, Wenwu Ou, Kun Gai, Yadong Mutokenizer -
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond (24 Aug 2023)
Jinze Bai, Shuai Bai, Shusheng Yang, et al.
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, Jingren Zhou -
VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks (18 May 2023)
[NeurIPS 2023] Wenhai Wang, Zhe Chen, Xiaokang Chen, et al.
Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, Jifeng Dai -
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning (11 May 2023)
Wenliang Dai, Junnan Li, Dongxu Li, et al.
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi -
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models (20 Apr 2023)
Deyao Zhu, Jun Chen, Xiaoqian Shen, et al.
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny -
Visual Instruction Tuning (17 Apr 2023)
[NeurIPS 2023 (Oral)] Liu, Haotian, et al.
Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee








-
StoryTeller: Improving Long Video Description through Global Audio-Visual Character Identification (11 Nov 2024)
Yichen He, Yuan Lin, Jianchao Wu, et al.
Yichen He, Yuan Lin, Jianchao Wu, Hanchong Zhang, Yuchen Zhang, Ruicheng Le -
Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding (22 Sep 2024)
Yan Shu, Peitian Zhang, Zheng Liu, et al.
Yan Shu, Peitian Zhang, Zheng Liu, Minghao Qin, Junjie Zhou, Tiejun Huang, Bo Zhao -
Oryx MLLM: On-Demand Spatial-Temporal Understanding at Arbitrary Resolution (19 Sep 2024)
Zuyan Liu, Yuhao Dong, Ziwei Liu, et al.
Zuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Jiwen Lu, Yongming Rao -
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs (25 Apr 2024)
Zesen Cheng, Sicong Leng, Hang Zhang, et al.
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, Lidong Bing -
PLLaVA: Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning (25 Apr 2024)
Lin Xu, Yilin Zhao, Daquan Zhou, et al.
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, Jiashi Feng -
MovieChat: From Dense Token to Sparse Memory for Long Video Understanding (3 Dec 2023)
Enxin, Song, et al.
-
LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models (28 Nov 2023)
Yanwei, Li, et al.
-
Video-Bench: A Comprehensive Benchmark and Toolkit for Evaluating Video-based Large Language Models (27 Nov 2023)
Ning, Munan, et al.
-
PG-Video-LLaVA: Pixel Grounding Large Video-Language Models (22 Nov 2023)
Munasinghe, Shehan, et al.
-
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection (16 Nov 2023)
Lin, Bin, et al.
-
Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding (14 Nov 2023)
Jin, Peng, et al.
-
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding (5 Jun 2023)
Zhang, Hang, Xin Li, and Lidong Bing. EMNLP 2023's demo track.
-
AntGPT: Can Large Language Models Help Long-term Action Anticipation from Videos? (31 Jul 2023)
Zhao, Qi, et al.
-
Valley: Video Assistant with Large Language model Enhanced ability (12 Jun 2023)
Luo, Ruipu, et al.
-
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models (8 Jun 2023)
Muhammad Maaz, Hanoona Rasheed, Salman Khan, et al.
-
VideoChat: Chat-Centric Video Understanding (10 May 2023)
Li, KunChang, et al.
-
VideoLLM: Modeling Video Sequence with Large Language Models (22 May 2023)
Chen, Guo, et al.
-
Learning video embedding space with Natural Language Supervision (25 Mar 2023)
Uppala, Phani Krishna, Shriti Priya, and Vaidehi Joshi.















-
Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding (12 Oct 2024)
[NeurIPS 2024] Yunze Man, Shuhong Zheng, Zhipeng Bao, et al.
Yunze Man, Shuhong Zheng, Zhipeng Bao, Martial Hebert, Liang-Yan Gui, Yu-Xiong Wang -
Situation3D: Situational Awareness Matters in 3D Vision Language Reasoning (12 Oct 2024)
[CVPR 2024] Yunze Man, Liang-Yan Gui, Yu-Xiong Wang
-
LL3DA: Visual Interactive Instruction Tuning for Omni-3D Understanding, Reasoning, and Planning (30 Nov 2023)
[CVPR2024]Sijin Chen, Xin Chen, Chi Zhang, et al.
[CVPR 2024] Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, Tao Chen -
LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding (21 Dec 2023)
Senqiao Yang*, Jiaming Liu*, Ray Zhang, et al.
-
3D-LLM: Injecting the 3D World into Large Language Models (24 Jul 2023)
[NeurIPS 2023 Spotlight] Yining Hong, Haoyu Zhen, Peihao Chen, et al.
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, Chuang Gan -
PointLLM: Empowering Large Language Models to Understand Point Clouds (31 Aug 2023)
[NeurIPS 2023 Spotlight] Runsen Xu, Xiaolong Wang, Tai Wang, et al.
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiangmiao Pang, Dahua Lin -
PointCLIP: Point Cloud Understanding by CLIP (31 Aug 2023)
[CVPR 2022] Renrui Zhang, Ziyu Guo, Wei Zhang,, et al.
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, Hongsheng Li






-
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action (28 Dec 2023)
Jiasen Lu, Christopher Clark, Sangho Lee, et al.
Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, Aniruddha Kembhavi -
M2UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models (19 Nov 2023)
Atin Sakkeer Hussain, Shansong Liu, Chenshuo Sun, et al.
Atin Sakkeer Hussain, Shansong Liu, Chenshuo Sun, Ying Shan -
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models (14 Nov 2023)
Yunfei Chu, Jin Xu, Xiaohuan Zhou, et al.
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, Jingren Zhou -
SALMONN: Towards Generic Hearing Abilities for Large Language Models (20 Oct 2023)
Changli Tang, Wenyi Yu, Guangzhi Sun, et al.
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang -
MusicAgent: An AI Agent for Music Understanding and Generation with Large Language Models (18 Oct 2023)
Dingyao Yu, Kaitao Song, Peiling Lu, et al.
Dingyao Yu, Kaitao Song, Peiling Lu, Tianyu He, Xu Tan, Wei Ye, Shikun Zhang, Jiang Bian -
Llark: A multimodal foundation model for music (11 Oct 2023)
Josh Gardner, Simon Durand, Daniel Stoller, et al.
Josh Gardner, Simon Durand, Daniel Stoller, Rachel M. Bittner -
LauraGPT: Listen, Attend, Understand, and Regenerate Audio with GPT (7 Oct 2023)
Jiaming Wang, Zhihao Du, Qian Chen, et al.
Jiaming Wang, Zhihao Du, Qian Chen, Yunfei Chu, Zhifu Gao, Zerui Li, Kai Hu, Xiaohuan Zhou, Jin Xu, Ziyang Ma, Wen Wang, Siqi Zheng, Chang Zhou, Zhijie Yan, Shiliang Zhang -
Improving Audio Captioning Models with Fine-grained Audio Features, Text Embedding Supervision, and LLM Mix-up Augmentation (29 Sep 2023)
Shih-Lun Wu, Xuankai Chang, Gordon Wichern, et al.
Shih-Lun Wu, Xuankai Chang, Gordon Wichern, Jee-weon Jung, François Germain, Jonathan Le Roux, Shinji Watanabe -
Connecting Speech Encoder and Large Language Model for ASR (25 Sep 2023)
Wenyi Yu, Changli Tang, Guangzhi Sun, et al.
Wenyi Yu, Changli Tang, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang -
Can Whisper perform speech-based in-context learning (13 Sep 2023)
Siyin Wang, Chao-Han Huck Yang, Ji Wu, et al.
Siyin Wang, Chao-Han Huck Yang, Ji Wu, Chao Zhang -
Music understanding LLaMA: Advancing text-to-music generation with question answering and captioning (22 Aug 2023)
Shansong Liu, Atin Sakkeer Hussain, Chenshuo Sun, et al.
Shansong Liu, Atin Sakkeer Hussain, Chenshuo Sun, Ying Shan -
On decoder-only architecture for speech-to-text and large language model integration (8 Jul 2023)
Jian Wu, Yashesh Gaur, Zhuo Chen, et al.
Jian Wu, Yashesh Gaur, Zhuo Chen, Long Zhou, Yimeng Zhu, Tianrui Wang, Jinyu Li, Shujie Liu, Bo Ren, Linquan Liu, Yu Wu -
AudioPaLM: A Large Language Model That Can Speak and Listen (22 Jun 2023)
Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, et al.
Paul K. Rubenstein, Chulayuth Asawaroengchai, Duc Dung Nguyen, Ankur Bapna, Zalán Borsos, Félix de Chaumont Quitry, Peter Chen, Dalia El Badawy, Wei Han, Eugene Kharitonov, Hannah Muckenhirn, Dirk Padfield, James Qin, Danny Rozenberg, Tara Sainath, Johan Schalkwyk, Matt Sharifi, Michelle Tadmor Ramanovich, Marco Tagliasacchi, Alexandru Tudor, Mihajlo Velimirović, Damien Vincent, Jiahui Yu, Yongqiang Wang, Vicky Zayats, Neil Zeghidour, Yu Zhang, Zhishuai Zhang, Lukas Zilka, Christian Frank -
Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface (30 Mar 2023)
Yongliang Shen, Kaitao Song, Xu Tan, et al.
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang -
Sparks of Artificial General Intelligence: Early experiments with GPT-4 (22 Mar 2023)
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al.
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang -
Listen, Think, and Understand (18 May 2023)
Yuan Gong, Hongyin Luo, Alexander H. Liu, et al.
Yuan Gong, Hongyin Luo, Alexander H. Liu, Leonid Karlinsky, James Glass -
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities (18 May 2023)
Dong Zhang, Shimin Li, Xin Zhang, et al.
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, Xipeng Qiu -
Audiogpt: Understanding and generating speech, music, sound, and talking head (25 Apr 2023)
Rongjie Huang, Mingze Li, Dongchao Yang, et al.
Rongjie Huang, Mingze Li, Dongchao Yang, Jiatong Shi, Xuankai Chang, Zhenhui Ye, Yuning Wu, Zhiqing Hong, Jiawei Huang, Jinglin Liu, Yi Ren, Zhou Zhao, Shinji Watanabe



-
Jailbreaking gpt-4v via self-adversarial attacks with system prompts. (20 Jan 2024)
Yuanwei Wu, Xiang Li, Yixin Liu, et al.
Yuanwei Wu, Xiang Li, Yixin Liu, Pan Zhou, Lichao Sun -
Defending chatgpt against jailbreak attack via self-reminders. (1 Dec 2023)
Yueqi Xie, Jingwei Yi, Jiawei Shao, et al.
Yueqi Xie, Jingwei Yi, Jiawei Shao, Justin Curl, Lingjuan Lyu, Qifeng Chen, Xing Xie, Fangzhao Wu -
Misusing Tools in Large Language Models With Visual Adversarial Examples (4 Oct 2023)
Xiaohan Fu, Zihan Wang, Shuheng Li, et al.
Xiaohan Fu, Zihan Wang, Shuheng Li, Rajesh K. Gupta, Niloofar Mireshghallah, Taylor Berg-Kirkpatrick, Earlence Fernandes -
Image Hijacks: Adversarial Images can Control Generative Models at Runtime. (18 Sep 2023)
Luke Bailey, Euan Ong, Stuart Russell, et al.
Luke Bailey, Euan Ong, Stuart Russell, Scott Emmons -
Universal and Transferable Adversarial Attacks on Aligned Language Models (27 Jul 2023)
Andy Zou, Zifan Wang, Nicholas Carlini, et al.
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, Matt Fredrikson -
Prompt injection attack against llm-integrated applications (8 Jun 2023)
Yi Liu, Gelei Deng, Yuekang Li, et al.
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, Yang Liu -
Automatically Auditing Large Language Models via Discrete Optimization (8 Mar 2023)
Erik Jones, Anca Dragan, Aditi Raghunathan, et al.
Erik Jones, Anca Dragan, Aditi Raghunathan, Jacob Steinhardt -
Poisoning Web-Scale Training Datasets is Practical (20 Feb 2023)
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, et al.
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, Florian Tram r -
Exploiting programmatic behavior of llms: Dual-use through standard security attacks. (11 Feb 2023)
Daniel Kang, Xuechen Li, Ion Stoica, et al.
Daniel Kang, Xuechen Li, Ion Stoica, Carlos Guestrin, Matei Zaharia, Tatsunori Hashimoto -
Ignore previous prompt: Attack techniques for language models (17 Nov 2022)
F bio Perez, Ian Ribeiro (NeurIPS 2022 Workshop)
-
Universal Adversarial Triggers for Attacking and Analyzing NLP (20 Aug 2019)
Eric Wallace, Shi Feng, Nikhil Kandpal, et al. (EMNLP 2019)
Eric Wallace, Shi Feng, Nikhil Kandpal, Matt Gardner, Sameer Singh -
Adversarial Examples for Evaluating Reading Comprehension Systems (23 Jul 2017)
Robin Jia, Percy Liang (EMNLP 2017)









-
Detecting and correcting hate speech in multimodal memes with large visual language model. (12 Nov 2023)
Minh-Hao Van, Xintao Wu
-
Detecting Pretraining Data from Large Language Models (3 Nov 2023)
Weijia Shi, Anirudh Ajith, Mengzhou Xia, et al.
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, Luke Zettlemoyer -
Jailbreak and guard aligned language models with only few in-context demonstrations (10 Oct 2023)
Zeming Wei, Yifei Wang, Yisen Wang
-
Smoothllm: Defending large language models against jailbreaking attacks. (5 Oct 2023)
Alexander Robey, Eric Wong, Hamed Hassani, et al.
Alexander Robey, Eric Wong, Hamed Hassani, George J. Pappas -
A Watermark for Large Language Models (6 Jun 2023)
John Kirchenbauer, Jonas Geiping, Yuxin Wen, et al. (ICML 2023)
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein -
Unsafe Diffusion: On the Generation of Unsafe Images and Hateful Memes From Text-To-Image Models (23 May 2023)
Yiting Qu, Xinyue Shen, Xinlei He, et al. (ACM CCS 2023)
Yiting Qu, Xinyue Shen, Xinlei He, Michael Backes, Savvas Zannettou, Yang Zhang -
TRAK: Attributing Model Behavior at Scale (3 Apr 2023)
Sung Min Park, Kristian Georgiev, Andrew Ilyas, et al.
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, Aleksander Madry -
Poisoning Web-Scale Training Datasets is Practical (20 Feb 2023)
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, et al.
Nicholas Carlini, Matthew Jagielski, Christopher A. Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, Florian Tram r -
Mitigating Inappropriate Degeneration in Diffusion Models (9 Nov 2022)
Patrick Schramowski, Manuel Brack, Bj?rn Deiseroth, et al. (CVPR 2023)
Patrick Schramowski, Manuel Brack, Bj?rn Deiseroth, Kristian Kersting -
Extracting Training Data from Large Language Models (15 Jun 2021)
Nicholas Carlini, Florian Tramer, Eric Wallace, et al.
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, Colin Raffel







-
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (13 Dec 2023)
Rafael Rafailov, Archit Sharma, Eric Mitchell, et al.
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn -
Raft: Reward ranked fine tuning for generative foundation model alignment (1 Dec 2023)
Hanze Dong, Wei Xiong, Deepanshu Goyal, et al. (Transactions on Machine Learning Research (TMLR))
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang -
Better aligning text-to-image models with human preference (22 Aug 2023)
Xiaoshi Wu, Keqiang Sun, Feng Zhu, et al. (ICCV 2023)
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li -
Scalable agent alignment via reward modeling: a research direction (19 Nov 2018)
Jan Leike, David Krueger, Tom Everitt, et al.
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg -
Proximal policy optimization algorithms (20 Jul 2017)
John Schulman, Filip Wolski, Prafulla Dhariwal, et al.
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov


-
Goat-bench: Safety insights to large multimodal models through meme-based social abuse. (7 Jan 2024)
Hongzhan Lin, Ziyang Luo, Bo Wang, et al.
Hongzhan Lin, Ziyang Luo, Bo Wang, Ruichao Yang, Jing Ma -
Tovilag: Your visual-language generative model is also an evildoer. (13 Dec 2023)
Xinpeng Wang, Xiaoyuan Yi, Han Jiang, et al. (EMNLP 2023 Oral)
Xinpeng Wang, Xiaoyuan Yi, Han Jiang, Shanlin Zhou, Zhihua Wei, Xing Xie -
Figstep: Jailbreaking large vision-language models via typographic visual prompts. (13 Dec 2023)
Yichen Gong, Delong Ran, Jinyuan Liu, et al.
Yichen Gong, Delong Ran, Jinyuan Liu, Conglei Wang, Tianshuo Cong, Anyu Wang, Sisi Duan, Xiaoyun Wang -
Query-relevant images jailbreak large multi-modal models. (29 Nov 2023)
Xin Liu, Yichen Zhu, Yunshi Lan, et al.
Xin Liu, Yichen Zhu, Yunshi Lan, Chao Yang, Yu Qiao -
Dress: Instructing large vision-language models to align and interact with humans via natural language feedback. (16 Nov 2023)
Yangyi Chen, Karan Sikka, Michael Cogswell, et al.
Yangyi Chen, Karan Sikka, Michael Cogswell, Heng Ji, Ajay Divakaran -
Beavertails: Towards improved safety alignment of llm via a human-preference dataset (7 Nov 2023)
Jiaming Ji, Mickel Liu, Juntao Dai, et al. (NeurIPS 2023)
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, Yaodong Yang -
Can pre-trained vision and language models answer visual information-seeking questions? (17 Oct 2023)
Yang Chen, Hexiang Hu, Yi Luan, et al. (EMNLP 2023)
Yang Chen, Hexiang Hu, Yi Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter, Ming-Wei Chang -
Can language models be instructed to protect personal information? (3 Oct 2023)
Yang Chen, Ethan Mendes, Sauvik Das, et al.
Yang Chen, Ethan Mendes, Sauvik Das, Wei Xu, Alan Ritter -
Safetybench: Evaluating the safety of large language models with multiple choice questions (13 Sep 2023)
Zhexin Zhang, Leqi Lei, Lindong Wu, et al.
Zhexin Zhang, Leqi Lei, Lindong Wu, Rui Sun, Yongkang Huang, Chong Long, Xiao Liu, Xuanyu Lei, Jie Tang, Minlie Huang -
Safety assessment of chinese large language models (20 Apr 2023)
Hao Sun, Zhexin Zhang, Jiawen Deng, et al.
Hao Sun, Zhexin Zhang, Jiawen Deng, Jiale Cheng, Minlie Huang









-
Not My Voice! A Taxonomy of Ethical and Safety Harms of Speech Generators (25 Jan 2024)
Wiebke Hutiri, Oresiti Papakyriakopoulos, Alice Xiang
) )
-
Adv3D: Generating 3D Adversarial Examples in Driving Scenarios with NeRF (4 Sep 2023)
Leheng Li, Qing Lian, Ying-Cong Chen
-
Deepfake Video Detection Using Generative Convolutional Vision Transformer (13 Jul 2023)
Deressa Wodajo, Solomon Atnafu, Zahid Akhtar
-
M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection (19 Apr 2022)
Junke Wang, Zuxuan Wu, Wenhao Ouyang, Xintong Han, Jingjing Chen, Ser-Nam Lim, Yu-Gang Jiang
-
Deepfake Video Detection Using Convolutional Vision Transformer (11 Mar 2021)
Deressa Wodajo, Solomon Atnafu
-
"Deepfakes Generation and Detection: State-of-the-art, open challenges, countermeasures, and way forward" (25 Feb 2021)
Momina Masood, Marriam Nawaz, Khalid Mahmood Malik, Ali Javed, Aun Irtaza


-
MM-LLMs: Recent Advances in MultiModal Large Language Models (24 Jan 2024)
Duzhen Zhang, Yahan Yu, Chenxing Li
Duzhen Zhang, Yahan Yu, Chenxing Li, Jiahua Dong, Dan Su, Chenhui Chu, Dong Yu -
A Survey on Multimodal Large Language Models (23 Jun 2023)
Shukang Yin, Chaoyou Fu, Sirui Zhao, et al.
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, Enhong Chen -
Multimodal Large Language Models: A Survey (22 Nov 2023)
[IEEE BigData 2023] Jiayang Wu, Wensheng Gan, Zefeng Chen, et al.
Jiayang Wu, Wensheng Gan, Zefeng Chen, Shicheng Wan, Philip S. Yu -
A Survey of Large Language Models (31 Mar 2023)
Wayne Xin Zhao, Kun Zhou, Junyi Li, et al.
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, Ji-Rong Wen


-
Autoregressive Models in Vision: A Survey (8 Nov 2024)
Jing Xiong, Gongye Liu, Lun Huang, et al.
Jing Xiong, Gongye Liu, Lun Huang, Chengyue Wu, Taiqiang Wu, Yao Mu, Yuan Yao, Hui Shen, Zhongwei Wan, Jinfa Huang, Chaofan Tao, Shen Yan, Huaxiu Yao, Lingpeng Kong, Hongxia Yang, Mi Zhang, Guillermo Sapiro, Jiebo Luo, Ping Luo, Ngai Wong -
State of the Art on Diffusion Models for Visual Computing (11 Oct 2023)
Ryan Po, Wang Yifan, Vladislav Golyanik, et al.
Ryan Po, Wang Yifan, Vladislav Golyanik, Kfir Aberman, Jonathan T. Barron, Amit H. Bermano, Eric Ryan Chan, Tali Dekel, Aleksander Holynski, Angjoo Kanazawa, C. Karen Liu, Lingjie Liu, Ben Mildenhall, Matthias Nießner, Björn Ommer, Christian Theobalt, Peter Wonka, Gordon Wetzstein -
Diffusion Models in Vision: A Survey (10 Sep 2022)
[TPAMI 2023] Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, et al.
Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, Mubarak Shah


Here is the list of our contributors in each modality of this repository.
| Modality/Task | Contributors |
|---|---|
| Image Generation | Jingye Chen, Xiaowei Chi, Yingqing He |
| Video Generation | Yingqing He, Xiaowei Chi, Jingye Chen |
| Image and Video Editing | Yazhou Xing |
| 3D Generation and Editing | Hongyu Liu |
| Audio Generation and Editing | Zeyue Tian, Ruibin Yuan |
| LLM Agent | Zhaoyang Liu |
| Safety | Runtao Liu |
| Leaders | Yingqing He, Zhaoyang Liu |
If you find this work useful in your research, Please cite the paper as below:
@article{he2024llms,
title={LLMs Meet Multimodal Generation and Editing: A Survey},
author={He, Yingqing and Liu, Zhaoyang and Chen, Jingye and Tian, Zeyue and Liu, Hongyu and Chi, Xiaowei and Liu, Runtao and Yuan, Ruibin and Xing, Yazhou and Wang, Wenhai and Dai, Jifeng and Zhang, Yong and Xue, Wei and Liu, Qifeng and Guo, Yike and Chen, Qifeng},
journal={arXiv preprint arXiv:2405.19334},
year={2024},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLMs-meet-Multimodal-Generation
Similar Open Source Tools
ai_igu
AI-IGU is a GitHub repository focused on Artificial Intelligence (AI) concepts, technology, software development, and algorithm improvement for all ages and professions. It emphasizes the importance of future software for future scientists and the increasing need for software developers in the industry. The repository covers various topics related to AI, including machine learning, deep learning, data mining, data science, big data, and more. It provides educational materials, practical examples, and hands-on projects to enhance software development skills and create awareness in the field of AI.

Ai-Hoshino
Ai Hoshino - MD is a WhatsApp bot tool with features like voice and text interaction, group configuration, anti-delete, anti-link, personalized welcome messages, chatbot functionality, sticker creation, sub-bot integration, RPG game, YouTube music and video downloads, and more. The tool is actively maintained by Starlights Team and offers a range of functionalities for WhatsApp users.
langchat
LangChat is an enterprise AIGC project solution in the Java ecosystem. It integrates AIGC large model functionality on top of the RBAC permission system to help enterprises quickly customize AI knowledge bases and enterprise AI robots. It supports integration with various large models such as OpenAI, Gemini, Ollama, Azure, Zhifu, Alibaba Tongyi, Baidu Qianfan, etc. The project is developed solely by TyCoding and is continuously evolving. It features multi-modality, dynamic configuration, knowledge base support, advanced RAG capabilities, function call customization, multi-channel deployment, workflows visualization, AIGC client application, and more.
MING
MING is an open-sourced Chinese medical consultation model fine-tuned based on medical instructions. The main functions of the model are as follows: Medical Q&A: answering medical questions and analyzing cases. Intelligent consultation: giving diagnosis results and suggestions after multiple rounds of consultation.
xiaozhi-esp32
The xiaozhi-esp32 repository is the first hardware project by Xia Ge, focusing on creating an AI chatbot using ESP32, SenseVoice, and Qwen72B. The project aims to help beginners in AI hardware development understand how to apply language models to hardware devices. It supports various functionalities such as Wi-Fi configuration, offline voice wake-up, multilingual speech recognition, voiceprint recognition, TTS using large models, and more. The project encourages participation for learning and improvement, providing resources for hardware and firmware development.

md_design
Nakidka is a tool for 1C:Enterprise 8 that allows for quick creation of forms based on text descriptions. It uses a simple and understandable syntax similar to Markdown, and also supports visual design of interface elements.
openclaw
OpenClaw is a personal AI assistant that runs on your own devices, answering you on various channels like WhatsApp, Telegram, Slack, Discord, and more. It can speak and listen on different platforms and render a live Canvas you control. The Gateway serves as the control plane, while the assistant is the main product. It provides a local, fast, and always-on single-user assistant experience. The preferred setup involves running the onboarding wizard in your terminal to guide you through setting up the gateway, workspace, channels, and skills. The tool supports various models and authentication methods, with a focus on security and privacy.
ophel
Ophel Atlas is a tool that transforms AI conversations into readable, navigable, and reusable documents. It organizes conversations into a structured workflow, allowing users to easily navigate and reuse valuable insights. It offers features such as intelligent outlining, conversation management, prompt libraries, theme customization, interface optimization, reading experience enhancements, efficiency tools, and privacy-focused data storage. Ophel Atlas is designed for various use cases including learning and research, daily work tasks, development and technical writing, content creation, and frequent AI users seeking structured and reusable capabilities.
KouriChat
KouriChat is a project that seamlessly integrates virtual and real interactions, providing eternal gentle bonds. It offers features like WeChat integration, immersive role-playing, intelligent conversation segmentation, emotion-based emojis, image generation, image recognition, voice messages, and more. The project is focused on technical research and learning exchanges, with a strong emphasis on ethical and legal guidelines. Users are required to take full responsibility for their actions, especially minors who should use the tool under supervision. The project architecture includes avatar configurations, data storage, handlers, AI service interfaces, a web UI, and utility libraries.
XianTu
XianTu is an AI-driven immersive cultivation text adventure game that features dynamic storytelling with multiple large models, a complete cultivation system including realm breakthroughs, cultivation of techniques, equipment refining, and NPC interactions, intelligent decision-making system based on multiple dimensions, multiple save file management with cloud sync support, open world exploration with character relationship networks, cross-platform compatibility with dual themes, and compatibility with SillyTavern embedded environment and standalone web version.
MirrorFlow
MirrorFlow is an end-to-end toolchain for dialogue data processing, cleaning/extraction, trainable samples generation, fine-tuning/distillation, and usage with evaluation. It supports two main routes: 'Digital Self' for fine-tuning chat records to mimic user expression habits and 'GPT-4o Style Alignment' for aligning output structures, clarification methods, refusal habits, and tool invocation behavior.
ComfyUI-OllamaGemini
ComfyUI GeminiOllama Extension integrates Google's Gemini API, OpenAI (ChatGPT), Anthropic's Claude, Ollama, Qwen, and image processing tools into ComfyUI for leveraging powerful models and features directly within workflows. Features include multiple AI API integrations, advanced prompt engineering, Gemini image generation, background removal, SVG conversion, FLUX resolutions, ComfyUI Styler, smart prompt generator, and more. The extension offers comprehensive API integration, advanced prompt engineering with researched templates, high-quality tools like Smart Prompt Generator and BRIA RMBG, and supports video & audio processing. It provides a single interface to access powerful AI models, transform prompts into detailed instructions, and use various tools for image processing, styling, and content generation.
chatgpt-plus
ChatGPT-PLUS is an open-source AI assistant solution based on AI large language model API, with a built-in operational management backend for easy deployment. It integrates multiple large language models from platforms like OpenAI, Azure, ChatGLM, Xunfei Xinghuo, and Wenxin Yanyan. Additionally, it includes MidJourney and Stable Diffusion AI drawing features. The system offers a complete open-source solution with ready-to-use frontend and backend applications, providing a seamless typing experience via Websocket. It comes with various pre-trained role applications such as Xiaohongshu writer, English translation master, Socrates, Confucius, Steve Jobs, and weekly report assistant to meet various chat and application needs. Users can enjoy features like Suno Wensheng music, integration with MidJourney/Stable Diffusion AI drawing, personal WeChat QR code for payment, built-in Alipay and WeChat payment functions, support for various membership packages and point card purchases, and plugin API integration for developing powerful plugins using large language model functions.

magic-resume
Magic Resume is a modern online resume editor that makes creating professional resumes simple and fun. Built on Next.js and Framer Motion, it supports real-time preview and custom themes. Features include Next.js 14+ based construction, smooth animation effects (Framer Motion), custom theme support, responsive design, dark mode, export to PDF, real-time preview, auto-save, and local storage. The technology stack includes Next.js 14+, TypeScript, Framer Motion, Tailwind CSS, Shadcn/ui, and Lucide Icons.
geekai
GeekAI is an open-source AI assistant solution based on AI large language model API, featuring a complete system with ready-to-use front-end and back-end management, providing a seamless typing experience via Websocket. It integrates various pre-trained character applications like Xiaohongshu writing assistant, English translation master, Socrates, Confucius, Steve Jobs, and weekly report assistant. The tool supports multiple large language models from platforms like OpenAI, Azure, Wenxin Yanyan, Xunfei Xinghuo, and Tsinghua ChatGLM. Additionally, it includes MidJourney and Stable Diffusion AI drawing functionalities for creating various artworks such as text-based images, face swapping, and blending images. Users can utilize personal WeChat QR codes for payment without the need for enterprise payment channels, and the tool offers integrated payment options like Alipay and WeChat Pay with support for multiple membership packages and point card purchases. It also features a plugin API for developing powerful plugins using large language model functions, including built-in plugins for Weibo hot search, today's headlines, morning news, and AI drawing functions.