
ComfyUI-OllamaGemini
AI-api text generation
Stars: 160
ComfyUI GeminiOllama Extension integrates Google's Gemini API, OpenAI (ChatGPT), Anthropic's Claude, Ollama, Qwen, and image processing tools into ComfyUI for leveraging powerful models and features directly within workflows. Features include multiple AI API integrations, advanced prompt engineering, Gemini image generation, background removal, SVG conversion, FLUX resolutions, ComfyUI Styler, smart prompt generator, and more. The extension offers comprehensive API integration, advanced prompt engineering with researched templates, high-quality tools like Smart Prompt Generator and BRIA RMBG, and supports video & audio processing. It provides a single interface to access powerful AI models, transform prompts into detailed instructions, and use various tools for image processing, styling, and content generation.
README:


|
|
Happy Creators |
Hours Saved Daily |
AI Providers |
Prompt Templates |
https://github.com/user-attachments/assets/6ffba8bc-47e9-42c5-be98-5849ffb03547

|

|

|
🎞️ View More Examples
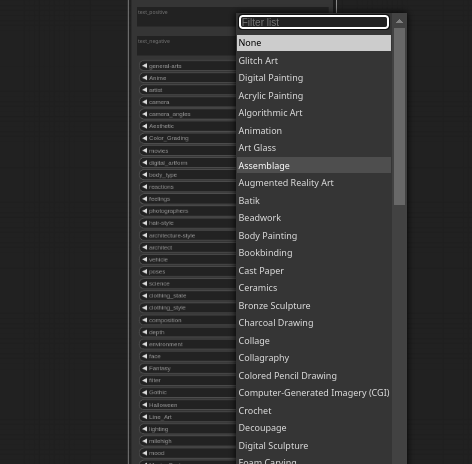
500+ Styles |
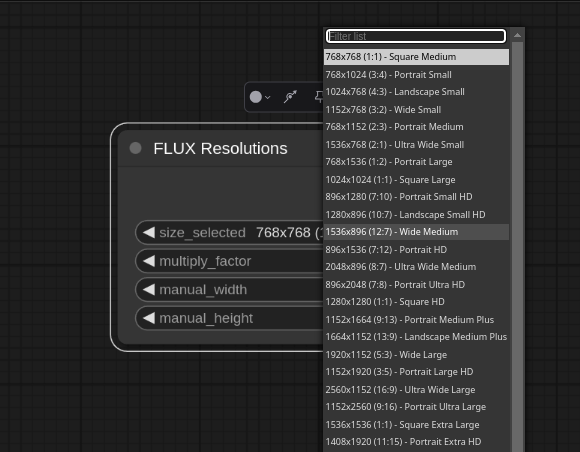
FLUX Resolutions |
SVG Conversion |
- 5 different extensions to manage
- 5 different config files
- Inconsistent prompt formats
- Hours wasted switching tools
- Frequent compatibility issues |
+ ONE unified extension
+ ONE config for all APIs
+ Smart prompt optimization
+ Instant provider switching
+ Always up-to-date |
|
Gemini 2.0 Pro • Flash • 1.5 |
ChatGPT GPT-4o • 4-Turbo • 3.5 |
Claude 3.7 • 3.5 Sonnet • Opus |
Ollama Any Local Model |
Qwen Max • Plus • Turbo |

Veo 3.1 Video Text/Image to Video + Extend |

Background Removal BRIA RMBG hair-level detail |

Imagen 4 Google's latest image model |

Gemini Banana Pro Advanced image editing |

FLUX Resolutions Perfect sizing for every model |

500+ Art Styles 🎨 Curated artistic presets |

Smart Prompts AI-enhanced engineering |

Multi Prompt Batch processing workflows |
|
Latest AI for Object Detection & Segmentation |
|||
|
SAM3 Text Prompts Detect "sun", "lake", "shadow" |
YOLOE-26 + SAM2.1 Auto-download detection |
BiRefNet Matting Hair-level edge quality |
Smart Model Paths Auto-finds in models/ |
|
Cinema 80+ styles |
Fine Art 120+ styles |
Gaming 60+ styles |
Photo 90+ styles |
Fantasy 100+ styles |
🔥 View Popular Style Categories
| Category | Styles | Examples |
|---|---|---|
| 🎬 Cinematic | 80+ | Film Noir, Blade Runner, Spielberg, Nolan, Wes Anderson |
| 🖼️ Fine Art | 120+ | Van Gogh, Monet, Picasso, Rembrandt, Caravaggio |
| 🎮 Digital Art | 60+ | Cyberpunk, Synthwave, Vaporwave, Pixel Art, 3D Render |
| 📸 Photography | 90+ | Portrait, Landscape, Street, Fashion, Product |
| ✨ Fantasy | 100+ | Epic Fantasy, Dark Fantasy, Fairy Tale, Mythological |
| 🎌 Anime | 50+ | Studio Ghibli, Makoto Shinkai, Trigger, Mappa |
|
ComfyUI Manager (One-Click) |
Git Clone cd ComfyUI/custom_nodes
git clone https://github.com/al-swaiti/ComfyUI-OllamaGemini.git
pip install -r requirements.txt |
🔑 API Configuration
{
"GEMINI_API_KEY": "your_key", // 🆓 aistudio.google.com
"OPENAI_API_KEY": "your_key", // 💰 platform.openai.com
"ANTHROPIC_API_KEY": "your_key", // ⚠️ console.anthropic.com
"OLLAMA_URL": "http://localhost:11434", // 🆓 Local
"QWEN_API_KEY": "your_key" // ⚠️ dashscope.console.aliyun.com
}Extensively researched • Model-optimized • Professional results
🎬 Video Generation
| Template | Description |
|---|---|
Veo3-TextToVideo |
Google Veo 3.1 with composition, camera, subject, action & native audio |
Veo3-ReferenceImages |
Reference image video preserving subject appearance |
Veo3-Interpolation |
First-to-last frame interpolation with motion paths |
VideoGen |
Professional cinematography: subject, action, lighting, style |
⚡ FLUX Models
| Template | Description |
|---|---|
FLUX.1-dev |
Hyper-detailed cinematographic with lighting & camera specs |
FLUX.2-dev |
Natural language following official BFL guide |
FLUX.2-dev-Edit |
Multi-reference editing for up to 10 images |
FLUX.2-dev-JSON |
Structured JSON for complex scenes |
FLUXKontext |
Context-aware editing with character consistency |
🎨 Image Generation
| Template | Description |
|---|---|
SDXL |
Premium comma-separated tags with artistic medium |
Imagen4 |
Structured, layered prompts for Google Imagen 4 |
Z-Image-Turbo |
6B diffusion transformer for concept fusion |
Qwen-Image-2512 |
Photorealistic eliminating "AI look" |
Upscale |
Sharpness-maximizing enhancement |
🍌 Gemini Nano Banana Pro
| Template | Description |
|---|---|
GeminiNanaBananaEdit |
Mask-free contextual editing |
NanaBananaPro |
Gemini 3 Pro Image with narrative style |
NanaBananaPro-Edit |
Advanced editing with multi-image composition |
NanaBananaPro-Pro |
Professional 4K asset production |

Abdallah Al-Swaiti 🇯🇴 Amman, Jordan
|
Made with ❤️ in Jordan 🇯🇴
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ComfyUI-OllamaGemini
Similar Open Source Tools
ComfyUI-OllamaGemini
ComfyUI GeminiOllama Extension integrates Google's Gemini API, OpenAI (ChatGPT), Anthropic's Claude, Ollama, Qwen, and image processing tools into ComfyUI for leveraging powerful models and features directly within workflows. Features include multiple AI API integrations, advanced prompt engineering, Gemini image generation, background removal, SVG conversion, FLUX resolutions, ComfyUI Styler, smart prompt generator, and more. The extension offers comprehensive API integration, advanced prompt engineering with researched templates, high-quality tools like Smart Prompt Generator and BRIA RMBG, and supports video & audio processing. It provides a single interface to access powerful AI models, transform prompts into detailed instructions, and use various tools for image processing, styling, and content generation.

matrixone
MatrixOne is the industry's first database to bring Git-style version control to data, combined with MySQL compatibility, AI-native capabilities, and cloud-native architecture. It is a HTAP (Hybrid Transactional/Analytical Processing) database with a hyper-converged HSTAP engine that seamlessly handles transactional, analytical, full-text search, and vector search workloads in a single unified system—no data movement, no ETL, no compromises. Manage your database like code with features like instant snapshots, time travel, branch & merge, instant rollback, and complete audit trail. Built for the AI era, MatrixOne is MySQL-compatible, AI-native, and cloud-native, offering storage-compute separation, elastic scaling, and Kubernetes-native deployment. It serves as one database for everything, replacing multiple databases and ETL jobs with native OLTP, OLAP, full-text search, and vector search capabilities.
kirara-ai
Kirara AI is a chatbot that supports mainstream large language models and chat platforms. It provides features such as image sending, keyword-triggered replies, multi-account support, personality settings, and support for various chat platforms like QQ, Telegram, Discord, and WeChat. The tool also supports HTTP server for Web API, popular large models like OpenAI and DeepSeek, plugin mechanism, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, custom workflows, web management interface, and built-in Frpc intranet penetration.
LLMs-from-scratch-CN
This repository is a Chinese translation of the GitHub project 'LLMs-from-scratch', including detailed markdown notes and related Jupyter code. The translation process aims to maintain the accuracy of the original content while optimizing the language and expression to better suit Chinese learners' reading habits. The repository features detailed Chinese annotations for all Jupyter code, aiding users in practical implementation. It also provides various supplementary materials to expand knowledge. The project focuses on building Large Language Models (LLMs) from scratch, covering fundamental constructions like Transformer architecture, sequence modeling, and delving into deep learning models such as GPT and BERT. Each part of the project includes detailed code implementations and learning resources to help users construct LLMs from scratch and master their core technologies.
chatgpt-mirai-qq-bot
Kirara AI is a chatbot that supports mainstream language models and chat platforms. It features various functionalities such as image sending, keyword-triggered replies, multi-account support, content moderation, personality settings, and support for platforms like QQ, Telegram, Discord, and WeChat. It also offers HTTP server capabilities, plugin support, conditional triggers, admin commands, drawing models, voice replies, multi-turn conversations, cross-platform message sending, and custom workflows. The tool can be accessed via HTTP API for integration with other platforms.
CTFCrackTools
CTFCrackTools X is the next generation of CTFCrackTools, featuring extreme performance and experience, extensible node-based architecture, and future-oriented technology stack. It offers a visual node-based workflow for encoding and decoding processes, with 43+ built-in algorithms covering common CTF needs like encoding, classical ciphers, modern encryption, hashing, and text processing. The tool is lightweight (< 15MB), high-performance, and cross-platform, supporting Windows, macOS, and Linux without the need for a runtime environment. It aims to provide a beginner-friendly tool for CTF enthusiasts to easily work on challenges and improve their skills.
simpletransformers
Simple Transformers is a library based on the Transformers library by HuggingFace, allowing users to quickly train and evaluate Transformer models with only 3 lines of code. It supports various tasks such as Information Retrieval, Language Models, Encoder Model Training, Sequence Classification, Token Classification, Question Answering, Language Generation, T5 Model, Seq2Seq Tasks, Multi-Modal Classification, and Conversational AI.
Awesome-ChatTTS
Awesome-ChatTTS is an official recommended guide for ChatTTS beginners, compiling common questions and related resources. It provides a comprehensive overview of the project, including official introduction, quick experience options, popular branches, parameter explanations, voice seed details, installation guides, FAQs, and error troubleshooting. The repository also includes video tutorials, discussion community links, and project trends analysis. Users can explore various branches for different functionalities and enhancements related to ChatTTS.
anylabeling
AnyLabeling is a tool for effortless data labeling with AI support from YOLO and Segment Anything. It combines features from LabelImg and Labelme with an improved UI and auto-labeling capabilities. Users can annotate images with polygons, rectangles, circles, lines, and points, as well as perform auto-labeling using YOLOv5 and Segment Anything. The tool also supports text detection, recognition, and Key Information Extraction (KIE) labeling, with multiple language options available such as English, Vietnamese, and Chinese.

Open-dLLM
Open-dLLM is the most open release of a diffusion-based large language model, providing pretraining, evaluation, inference, and checkpoints. It introduces Open-dCoder, the code-generation variant of Open-dLLM. The repo offers a complete stack for diffusion LLMs, enabling users to go from raw data to training, checkpoints, evaluation, and inference in one place. It includes pretraining pipeline with open datasets, inference scripts for easy sampling and generation, evaluation suite with various metrics, weights and checkpoints on Hugging Face, and transparent configs for full reproducibility.
Code-Review-GPT-Gitlab
A project that utilizes large models to help with Code Review on Gitlab, aimed at improving development efficiency. The project is customized for Gitlab and is developing a Multi-Agent plugin for collaborative review. It integrates various large models for code security issues and stays updated with the latest Code Review trends. The project architecture is designed to be powerful, flexible, and efficient, with easy integration of different models and high customization for developers.
ChuanhuChatGPT
Chuanhu Chat is a user-friendly web graphical interface that provides various additional features for ChatGPT and other language models. It supports GPT-4, file-based question answering, local deployment of language models, online search, agent assistant, and fine-tuning. The tool offers a range of functionalities including auto-solving questions, online searching with network support, knowledge base for quick reading, local deployment of language models, GPT 3.5 fine-tuning, and custom model integration. It also features system prompts for effective role-playing, basic conversation capabilities with options to regenerate or delete dialogues, conversation history management with auto-saving and search functionalities, and a visually appealing user experience with themes, dark mode, LaTeX rendering, and PWA application support.
HivisionIDPhotos
HivisionIDPhoto is a practical algorithm for intelligent ID photo creation. It utilizes a comprehensive model workflow to recognize, cut out, and generate ID photos for various user photo scenarios. The tool offers lightweight cutting, standard ID photo generation based on different size specifications, six-inch layout photo generation, beauty enhancement (waiting), and intelligent outfit swapping (waiting). It aims to solve emergency ID photo creation issues.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.
HaE
HaE is a framework project in the field of network security (data security) that combines artificial intelligence (AI) large models to achieve highlighting and information extraction of HTTP messages (including WebSocket). It aims to reduce testing time, focus on valuable and meaningful messages, and improve vulnerability discovery efficiency. The project provides a clear and visual interface design, simple interface interaction, and centralized data panel for querying and extracting information. It also features built-in color upgrade algorithm, one-click export/import of data, and integration of AI large models API for optimized data processing.
For similar tasks
ComfyUI-OllamaGemini
ComfyUI GeminiOllama Extension integrates Google's Gemini API, OpenAI (ChatGPT), Anthropic's Claude, Ollama, Qwen, and image processing tools into ComfyUI for leveraging powerful models and features directly within workflows. Features include multiple AI API integrations, advanced prompt engineering, Gemini image generation, background removal, SVG conversion, FLUX resolutions, ComfyUI Styler, smart prompt generator, and more. The extension offers comprehensive API integration, advanced prompt engineering with researched templates, high-quality tools like Smart Prompt Generator and BRIA RMBG, and supports video & audio processing. It provides a single interface to access powerful AI models, transform prompts into detailed instructions, and use various tools for image processing, styling, and content generation.
ai-commits-intellij-plugin
AI Commits is a plugin for IntelliJ-based IDEs and Android Studio that generates commit messages using git diff and OpenAI. It offers features such as generating commit messages from diff using OpenAI API, computing diff only from selected files and lines in the commit dialog, creating custom prompts for commit message generation, using predefined variables and hints to customize prompts, choosing any of the models available in OpenAI API, setting OpenAI network proxy, and setting custom OpenAI compatible API endpoint.
extensionOS
Extension | OS is an open-source browser extension that brings AI directly to users' web browsers, allowing them to access powerful models like LLMs seamlessly. Users can create prompts, fix grammar, and access intelligent assistance without switching tabs. The extension aims to revolutionize online information interaction by integrating AI into everyday browsing experiences. It offers features like Prompt Factory for tailored prompts, seamless LLM model access, secure API key storage, and a Mixture of Agents feature. The extension was developed to empower users to unleash their creativity with custom prompts and enhance their browsing experience with intelligent assistance.
img-prompt
IMGPrompt is an AI prompt editor tailored for image and video generation tools like Stable Diffusion, Midjourney, DALL·E, FLUX, and Sora. It offers a clean interface for viewing and combining prompts with translations in multiple languages. The tool includes features like smart recommendations, translation, random color generation, prompt tagging, interactive editing, categorized tag display, character count, and localization. Users can enhance their creative workflow by simplifying prompt creation and boosting efficiency.
5ire
5ire is a cross-platform desktop client that integrates a local knowledge base for multilingual vectorization, supports parsing and vectorization of various document formats, offers usage analytics to track API spending, provides a prompts library for creating and organizing prompts with variable support, allows bookmarking of conversations, and enables quick keyword searches across conversations. It is licensed under the GNU General Public License version 3.

sidecar
Sidecar is the AI brains of Aide the editor, responsible for creating prompts, interacting with LLM, and ensuring seamless integration of all functionalities. It includes 'tool_box.rs' for handling language-specific smartness, 'symbol/' for smart and independent symbols, 'llm_prompts/' for creating prompts, and 'repomap' for creating a repository map using page rank on code symbols. Users can contribute by submitting bugs, feature requests, reviewing source code changes, and participating in the development workflow.
labs-ai-tools-for-devs
This repository provides AI tools for developers through Docker containers, enabling agentic workflows. It allows users to create complex workflows using Dockerized tools and Markdown, leveraging various LLM models. The core features include Dockerized tools, conversation loops, multi-model agents, project-first design, and trackable prompts stored in a git repo.
Prompt_Engineering
Prompt Engineering Techniques is a comprehensive repository for learning, building, and sharing prompt engineering techniques, from basic concepts to advanced strategies for leveraging large language models. It provides step-by-step tutorials, practical implementations, and a platform for showcasing innovative prompt engineering techniques. The repository covers fundamental concepts, core techniques, advanced strategies, optimization and refinement, specialized applications, and advanced applications in prompt engineering.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.