
RAG-Survey
Collecting awesome papers of RAG for AIGC. We propose a taxonomy of RAG foundations, enhancements, and applications in paper "Retrieval-Augmented Generation for AI-Generated Content: A Survey".
Stars: 1016
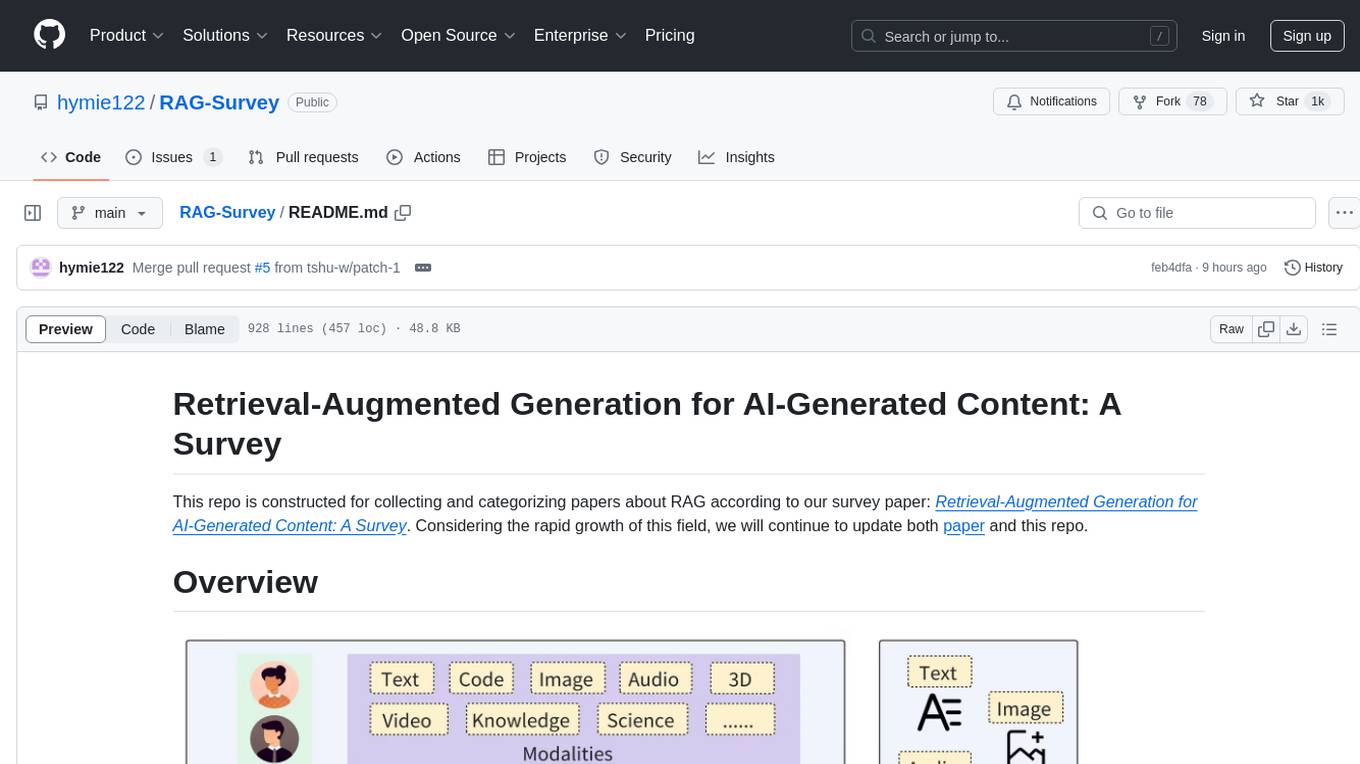
This repository is dedicated to collecting and categorizing papers related to Retrieval-Augmented Generation (RAG) for AI-generated content. It serves as a survey repository based on the paper 'Retrieval-Augmented Generation for AI-Generated Content: A Survey'. The repository is continuously updated to keep up with the rapid growth in the field of RAG.
README:
This repo is constructed for collecting and categorizing papers about RAG according to our survey paper: Retrieval-Augmented Generation for AI-Generated Content: A Survey. Considering the rapid growth of this field, we will continue to update both paper and this repo.


-
Query-based RAG
REALM: Retrieval-Augmented Language Model Pre-Training
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
REPLUG: Retrieval-Augmented Black-Box Language Models
In-Context Retrieval-Augmented Language Models
When Language Model Meets Private Library
DocPrompting: Generating Code by Retrieving the Docs
Retrieval-based prompt selection for code-related few-shot learning
Inferfix: End-to-end program repair with llms
Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models
Reacc: A retrieval-augmented code completion framework
Uni-parser: Unified semantic parser for question answering on knowledge base and database
RNG-KBQA: generation augmented iterative ranking for knowledge base question answering
End-to-end casebased reasoning for commonsense knowledge base completion
Retrievegan:Image synthesis via differentiable patch retrieval
Retrieval-Augmented Score Distillation for Text-to-3D Generation
-
Latent Representation-based RAG
Leveraging passage retrieval with generative models for open domain question answering
Bashexplainer: Retrieval-augmented bash code comment generation based on finetuned codebert
EditSum: A Retrieve-and-Edit Framework for Source Code Summarization
Retrieve and Refine: Exemplar-based Neural Comment Generation
RACE: retrieval-augmented commit message generation
A Retrieve-and-Edit Framework for Predicting Structured Outputs
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
Bridging the kb-text gap: Leveraging structured knowledge-aware pre-training for KBQA
Retrieval-enhanced generative model for large-scale knowledge graph completion
Case-based reasoning for natural language queries over knowledge bases
Improving language models by retrieving from trillions of tokens
Remodiffuse: Retrieval-augmented motion diffusion model
Retrieval augmented convolutional encoder-decoder networks for video captioning
Retrieval-augmented egocentric video captioning
Re-imagen: Retrievalaugmented text-to-image generator
Knn-diffusion: Image generation via large-scale retrieval
Retrieval-augmented diffusion models
Text-guided synthesis of artistic images with retrieval-augmented diffusion models
Memory-driven text-to-image generation
Mention memory: incorporating textual knowledge into transformers through entity mention attention
Unlimiformer:Long-range transformers with unlimited length input
Entities as experts: Sparse memory access with entity supervision
Amd: Anatomical motion diffusion with interpretable motion decomposition and fusion
Retrieval-augmented text-to-audio generation
Concept-aware video captioning: Describing videos with effective prior information
-
Logit-based RAG
Generalization through memorization: Nearest neighbor language models
Syntax-Aware Retrieval Augmented Code Generation
Memory-augmented image captioning
Retrieval-based neural source code summarization
Efficient nearest neighbor language models
Nonparametric masked language modeling
Editsum:A retrieve-and-edit framework for source code summarization
-
Speculative RAG

-
Input Enhancement
-
Query Transformations
Query2doc: Query Expansion with Large Language Models
Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models
Precise Zero-Shot Dense Retrieval without Relevance Labels
RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation
Dynamic Contexts for Generating Suggestion Questions in RAG Based Conversational Systems
-
Data Augmentation
LESS: selecting influential data for targeted instruction tuning
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models
Telco-RAG: Navigating the challenges of retrieval-augmented language models for telecommunications
-
-
Retriever Enhancement
-
Recursive Retrieve
Query Expansion by Prompting Large Language Models
Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation
React: Synergizing reasoning and acting in language models
Chain-of-thought prompting elicits reasoning in large language models
ACTIVERAG: Revealing the Treasures of Knowledge via Active Learning
Retrieval-Augmented Thought Process as Sequential Decision Making
In search of needles in a 10m haystack: Recurrent memory finds what llms miss
-
Chunk Optimization
RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
Question-Based Retrieval using Atomic Units for Enterprise RAG
-
Finetune Retriever
C-Pack: Packaged Resources To Advance General Chinese Embedding
LM-Cocktail: Resilient Tuning of Language Models via Model Merging
Retrieve Anything To Augment Large Language Models
Replug: Retrieval-augmented black-box language models
When Language Model Meets Private Library
EditSum: A Retrieve-and-Edit Framework for Source Code Summarization
Synchromesh: Reliable Code Generation from Pre-trained Language Models
Retrieval Augmented Convolutional Encoder-decoder Networks for Video Captioning
Reinforcement learning for optimizing RAG for domain chatbots
-
Hybrid Retrieve
RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair
ReACC: A Retrieval-Augmented Code Completion Framework
Retrieval-based neural source code summarization
BashExplainer: Retrieval-Augmented Bash Code Comment Generation based on Fine-tuned CodeBERT
Retrieval-Augmented Score Distillation for Text-to-3D Generation
Corrective Retrieval Augmented Generation
Retrieval augmented generation with rich answer encoding
Unims-rag: A unified multi-source retrieval-augmented generation for personalized dialogue systems
You'll Never Walk Alone: A Sketch and Text Duet for Fine-Grained Image Retrieval
-
Re-ranking
Re2G: Retrieve, Rerank, Generate
AceCoder: Utilizing Existing Code to Enhance Code Generation
A Fine-tuning Enhanced RAG System with Quantized Influence Measure as AI Judge
UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers
Learning to Retrieve In-Context Examples for Large Language Models
The Chronicles of RAG: The Retriever, the Chunk and the Generator
-
Retrieval Transformation
Learning to filter context for retrieval-augmented generation
Fid-light: Efficient and effective retrieval-augmented text generation
-
Others
Generate rather than retrieve: Large language models are strong context generators
Generator-retriever-generator: A novel approach to open-domain question answering
-
-
Generator Enhancement
-
Prompt Engineering
Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
Active Prompting with Chain-of-Thought for Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
Lost in the Middle: How Language Models Use Long Contexts
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
Automatic Semantic Augmentation of Language Model Prompts (for Code Summarization)
Retrieval-Based Prompt Selection for Code-Related Few-Shot Learning
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models
-
Decoding Tuning
InferFix: End-to-End Program Repair with LLMs
Synchromesh: Reliable Code Generation from Pre-trained Language Models
-
Finetune Generator
Improving Language Models by Retrieving from Trillions of Tokens
When Language Model Meets Private Library
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Concept-Aware Video Captioning: Describing Videos With Effective Prior Information
Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation
Lora: Low-rank adaptation of large language models
Retrieval-Augmented Score Distillation for Text-to-3D Generation
-
-
Result Enhancement
-
RAG Pipeline Enhancement
-
Adaptive Retrieval
-
Rule-Baesd
Active retrieval augmented generation
Efficient Nearest Neighbor Language Models
Generalization through Memorization: Nearest Neighbor Language Models
-
Model-Based
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Investigating the Factual Knowledge Boundary of Large Language Models with Retrieval Augmentation
Self-Knowledge Guided Retrieval Augmentation for Large Language Models
-
-
Iterative RAG
RepoCoder: Repository-Level Through Iterative Retrieval and Generation
Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy
Knowledge graph based synthetic corpus generation for knowledge-enhanced language model pre-training
-


-
Question Answering
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
REALM: Retrieval-Augmented Language Model Pre-Training
Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training
Atlas: Few-shot Learning with Retrieval Augmented Language Models
Improving Language Models by Retrieving from Trillions of Tokens
Self-Knowledge Guided Retrieval Augmentation for Large Language Models
Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering
Think-on-Graph: Deep and Responsible Reasoning of Large Language Model with Knowledge Graph
Nonparametric Masked Language Modeling
CL-ReLKT: Cross-lingual Language Knowledge Transfer for Multilingual Retrieval Question Answering
One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval
Entities as Experts: Sparse Memory Access with Entity Supervision
When to Read Documents or QA History: On Unified and Selective Open-domain QA
DISC-LawLLM: Fine-tuning Large Language Models for Intelligent Legal Service
-
Fact verification
CONCRETE: Improving Cross-lingual Fact-checking with Cross-lingual Retrieval
Stochastic RAG: End-to-End Retrieval-Augmented Generation through Expected Utility Maximization
-
Commonsense Reasoning
KG-BART: Knowledge Graph-Augmented {BART} for Generative Commonsense Reasoning
What Evidence Do Language Models Find Convincing?
Enhancing Financial Sentiment Analysis via Retrieval Augmented Large Language Models
-
Human-Machine Conversation
Grounded Conversation Generation as Guided Traverses in Commonsense Knowledge Graphs
Skeleton-to-Response: Dialogue Generation Guided by Retrieval Memory
Internet-Augmented Dialogue Generation
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
A Model of Cross-Lingual Knowledge-Grounded Response Generation for Open-Domain Dialogue Systems
From Classification to Generation: Insights into Crosslingual Retrieval Augmented ICL
Cross-Lingual Retrieval Augmented Prompt for Low-Resource Languages
Citation-Enhanced Generation for LLM-based Chatbot
KAUCUS: Knowledge Augmented User Simulators for Training Language Model Assistants
-
Neural Machine Translation
Neural Machine Translation with Monolingual Translation Memory
-
Event Extraction
Retrieval-Augmented Generative Question Answering for Event Argument Extraction
-
Summarization
Retrieval-Augmented Multilingual Keyphrase Generation with Retriever-Generator Iterative Training
Unlimiformer: Long-Range Transformers with Unlimited Length Input
Retrieval-based Full-length Wikipedia Generation for Emergent Events
RIGHT: Retrieval-augmented Generation for Mainstream Hashtag Recommendation
-
Code Generation
Retrieval-Based Neural Code Generation
Retrieval Augmented Code Generation and Summarization
When Language Model Meets Private Library
Language Models of Code are Few-Shot Commonsense Learners
DocPrompting: Generating Code by Retrieving the Docs
CodeT5+: Open Code Large Language Models for Code Understanding and Generation
AceCoder: Utilizing Existing Code to Enhance Code Generation
Syntax-Aware Retrieval Augmented Code Generation
SkCoder: A Sketch-based Approach for Automatic Code Generation
CodeGen4Libs: A Two-Stage Approach for Library-Oriented Code Generation
ToolCoder: Teach Code Generation Models to use API search tools
RRGcode: Deep hierarchical search-based code generation
Code Search Is All You Need? Improving Code Suggestions with Code Search
ARKS: Active Retrieval in Knowledge Soup for Code Generation
-
Code Summary
Retrieval-based neural source code summarization
Retrieve and Refine: Exemplar-based Neural Comment Generation
EditSum: A Retrieve-and-Edit Framework for Source Code Summarization
Retrieval-Augmented Generation for Code Summarization via Hybrid GNN
Context-aware Retrieval-based Deep Commit Message Generation
RACE: Retrieval-augmented Commit Message Generation
BashExplainer: Retrieval-Augmented Bash Code Comment Generation based on Fine-tuned CodeBERT
Retrieval-Based Transformer Pseudocode Generation
A Simple Retrieval-based Method for Code Comment Generation
READSUM: Retrieval-Augmented Adaptive Transformer for Source Code Summarization
Tram: A Token-level Retrieval-augmented Mechanism for Source Code Summarization
Automatic Semantic Augmentation of Language Model Prompts (for Code Summarization)
Automatic Smart Contract Comment Generation via Large Language Models and In-Context Learning
-
Code Completion
A Retrieve-and-Edit Framework for Predicting Structured Outputs
Generating Code with the Help of Retrieved Template Functions and Stack Overflow Answers
ReACC: A Retrieval-Augmented Code Completion Framework
Domain Adaptive Code Completion via Language Models and Decoupled Domain Databases
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
CoCoMIC: Code Completion By Jointly Modeling In-file and Cross-file Context
RepoFusion: Training Code Models to Understand Your Repository
Revisiting and Improving Retrieval-Augmented Deep Assertion Generation
De-Hallucinator: Iterative Grounding for LLM-Based Code Completion
REPOFUSE: Repository-Level Code Completion with Fused Dual Context
-
Automatic Program Repair
Repair Is Nearly Generation: Multilingual Program Repair with LLMs
Retrieval-Based Prompt Selection for Code-Related Few-Shot Learning
InferFix: End-to-End Program Repair with LLMs
RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair
Automated Code Editing with Search-Generate-Modify
RTLFixer: Automatically Fixing RTL Syntax Errors with Large Language Models
-
Text-to-SQL and Code-based Semantic Parsing
Synchromesh: Reliable Code Generation from Pre-trained Language Models
Evaluating the Impact of Model Scale for Compositional Generalization in Semantic Parsing
RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL
Leveraging Code to Improve In-context Learning for Semantic Parsing
ReFSQL: A Retrieval-Augmentation Framework for Text-to-SQL Generation
Enhancing Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
Selective Demonstrations for Cross-domain Text-to-SQL
DBCopilot: Scaling Natural Language Querying to Massive Databases via Schema Routing
Multi-Hop Table Retrieval for Open-Domain Text-to-SQL
CodeS: Towards Building Open-source Language Models for Text-to-SQL
-
Others
De-fine: Decomposing and Refining Visual Programs with Auto-Feedback
Leveraging training data in few-shot prompting for numerical reasoning
Retrieval-Augmented Code Generation for Universal Information Extraction
Lessons from Building StackSpot AI: A Contextualized AI Coding Assistant
-
Audio Generation
Retrieval-Augmented Text-to-Audio Generation
Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models
-
Audio Captioning
RECAP: Retrieval-Augmented Audio Captioning
CNN architectures for large-scale audio classification
Natural language supervision for general-purpose audio representations
Weakly-supervised Automated Audio Captioning via text only training
-
Image Generation
Retrievegan: Image synthesis via differentiable patch retrieval
Memory-driven text-to-image generation
Re-imagen: Retrieval-augmented text-to-image generator
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Retrieval-Augmented Diffusion Models
Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
X&Fuse: Fusing Visual Information in Text-to-Image Generation
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
-
Image Captioning
Memory-augmented image captioning
Retrieval-Augmented Transformer for Image Captioning
Retrieval-augmented image captioning
SmallCap: Lightweight Image Captioning Prompted With Retrieval Augmentation
Cross-Modal Retrieval and Semantic Refinement for Remote Sensing Image Captioning
-
Others
An empirical study of gpt-3 for few-shot knowledge-based vqa
Retrieval augmented visual question answering with outside knowledge
Augmenting transformers with KNN-based composite memory for dialog
Maria: A visual experience powered conversational agent
Neural machine translation with phrase-level universal visual representations
-
Video Captioning
Incorporating Background Knowledge into Video Description Generation
Retrieval Augmented Convolutional Encoder-decoder Networks for Video Captioning
Concept-Aware Video Captioning: Describing Videos With Effective Prior Information
-
Video QA&Dialogue
Memory augmented deep recurrent neural network for video question answering
Retrieving-to-answer: Zero-shot video question answering with frozen large language models
Tvqa+: Spatio-temporal grounding for video question answering
Vgnmn: Video-grounded neural module networks for video-grounded dialogue systems
-
Others
Language models with image descriptors are strong few-shot video-language learners
Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation
Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval
-
Text-to-3D
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
AMD: Anatomical Motion Diffusion with Interpretable Motion Decomposition and Fusion
Retrieval-Augmented Score Distillation for Text-to-3D Generation
-
Knowledge Base Question Answering
ReTraCk: A Flexible and Efficient Framework for Knowledge Base Question Answering
Unseen Entity Handling in Complex Question Answering over Knowledge Base via Language Generation
Case-based Reasoning for Natural Language Queries over Knowledge Bases
Logical Form Generation via Multi-task Learning for Complex Question Answering over Knowledge Bases
Uni-Parser: Unified Semantic Parser for Question Answering on Knowledge Base and Database
RNG-KBQA: Generation Augmented Iterative Ranking for Knowledge Base Question Answering
TIARA: Multi-grained Retrieval for Robust Question Answering over Large Knowledge Base
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
End-to-end Case-Based Reasoning for Commonsense Knowledge Base Completion
Bridging the KB-Text Gap: Leveraging Structured Knowledge-aware Pre-training for KBQA
FC-KBQA: A Fine-to-Coarse Composition Framework for Knowledge Base Question Answering
Knowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering
Knowledge Graph-augmented Language Models for Complex Question Answering
Retrieve-Rewrite-Answer: A KG-to-Text Enhanced LLMs Framework for Knowledge Graph Question Answering
Probing Structured Semantics Understanding and Generation of Language Models via Question Answering
Keqing: Knowledge-based Question Answering is A Nature Chain-of-Thought mentor of LLMs
-
Knowledge-augmented Open-domain Question Answering
KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering
Empowering Language Models with Knowledge Graph Reasoning for Open-Domain Question Answering
Grape: Knowledge Graph Enhanced Passage Reader for Open-domain Question Answering
KnowledGPT: Enhancing Large Language Models with Retrieval and Storage Access on Knowledge Bases
Evidence-Focused Fact Summarization for Knowledge-Augmented Zero-Shot Question Answering
Two-stage Generative Question Answering on Temporal Knowledge Graph Using Large Language Models
KnowledgeNavigator: Leveraging Large Language Models for Enhanced Reasoning over Knowledge Graph
GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning
-
Table Question Answering
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Dual Reader-Parser on Hybrid Textual and Tabular Evidence for Open Domain Question Answering
End-to-End Table Question Answering via Retrieval-Augmented Generation
OmniTab: Pretraining with Natural and Synthetic Data for Few-shot Table-based Question Answering
Reasoning over Hybrid Chain for Table-and-Text Open Domain Question Answering
Conversational Question Answering on Heterogeneous Sources
Open-domain Question Answering via Chain of Reasoning over Heterogeneous Knowledge
StructGPT: A General Framework for Large Language Model to Reason over Structured Data
cTBLS: Augmenting Large Language Models with Conversational Tables
RINK: Reader-Inherited Evidence Reranker for Table-and-Text Open Domain Question Answering
Localize, Retrieve and Fuse: A Generalized Framework for Free-Form Question Answering over Tables
ERATTA: Extreme RAG for Table To Answers with Large Language Models
-
Others
Improving Knowledge-Aware Dialogue Response Generation by Using Human-Written Prototype Dialogues
Knowledge Graph-Augmented Language Models for Knowledge-Grounded Dialogue Generation
RHO: Reducing Hallucination in Open-domain Dialogues with Knowledge Grounding
Retrieval-Enhanced Generative Model for Large-Scale Knowledge Graph Completion
Knowledge-Augmented Large Language Models for Personalized Contextual Query Suggestion
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
-
Drug Discovery
Retrieval-based controllable molecule generation
Prompt-based 3d molecular diffusion models for structure-based drug design
-
Biomedical Informatics Enhancement
PoET: A generative model of protein families as sequences-of-sequences
BioReader: a Retrieval-Enhanced Text-to-Text Transformer for Biomedical Literature
Writing by Memorizing: Hierarchical Retrieval-based Medical Report Generation
From RAG to QA-RAG: Integrating Generative AI for Pharmaceutical Regulatory Compliance Process
-
Math Applications
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
Benchmarking Large Language Models in Retrieval-Augmented Generation
ARES: An Automated Evaluation Framework for Retrieval-AugmentedGeneration Systems
RAGAS: Automated Evaluation of Retrieval Augmented Generation
KILT: a Benchmark for Knowledge Intensive Language Tasks
if you find this work useful, please cite our paper:
@article{zhao2024retrieval,
title={Retrieval-Augmented Generation for AI-Generated Content: A Survey},
author={Zhao, Penghao and Zhang, Hailin and Yu, Qinhan and Wang, Zhengren and Geng, Yunteng and Fu, Fangcheng and Yang, Ling and Zhang, Wentao and Cui, Bin},
journal={arXiv preprint arXiv:2402.19473},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RAG-Survey
Similar Open Source Tools
RAG-Survey
This repository is dedicated to collecting and categorizing papers related to Retrieval-Augmented Generation (RAG) for AI-generated content. It serves as a survey repository based on the paper 'Retrieval-Augmented Generation for AI-Generated Content: A Survey'. The repository is continuously updated to keep up with the rapid growth in the field of RAG.
Awesome-LLM4Graph-Papers
A collection of papers and resources about Large Language Models (LLM) for Graph Learning (Graph). Integrating LLMs with graph learning techniques to enhance performance in graph learning tasks. Categorizes approaches based on four primary paradigms and nine secondary-level categories. Valuable for research or practice in self-supervised learning for recommendation systems.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.
efficient-transformers
Efficient Transformers Library provides reimplemented blocks of Large Language Models (LLMs) to make models functional and highly performant on Qualcomm Cloud AI 100. It includes graph transformations, handling for under-flows and overflows, patcher modules, exporter module, sample applications, and unit test templates. The library supports seamless inference on pre-trained LLMs with documentation for model optimization and deployment. Contributions and suggestions are welcome, with a focus on testing changes for model support and common utilities.
Awesome-Attention-Heads
Awesome-Attention-Heads is a platform providing the latest research on Attention Heads, focusing on enhancing understanding of Transformer structure for model interpretability. It explores attention mechanisms for behavior, inference, and analysis, alongside feed-forward networks for knowledge storage. The repository aims to support researchers studying LLM interpretability and hallucination by offering cutting-edge information on Attention Head Mining.
llm-continual-learning-survey
This repository is an updating survey for Continual Learning of Large Language Models (CL-LLMs), providing a comprehensive overview of various aspects related to the continual learning of large language models. It covers topics such as continual pre-training, domain-adaptive pre-training, continual fine-tuning, model refinement, model alignment, multimodal LLMs, and miscellaneous aspects. The survey includes a collection of relevant papers, each focusing on different areas within the field of continual learning of large language models.
Awesome-RL-based-LLM-Reasoning
This repository is dedicated to enhancing Language Model (LLM) reasoning with reinforcement learning (RL). It includes a collection of the latest papers, slides, and materials related to RL-based LLM reasoning, aiming to facilitate quick learning and understanding in this field. Starring this repository allows users to stay updated and engaged with the forefront of RL-based LLM reasoning.
Awesome-LLM-Post-training
The Awesome-LLM-Post-training repository is a curated collection of influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies. It covers various aspects of LLMs, including reasoning, decision-making, reinforcement learning, reward learning, policy optimization, explainability, multimodal agents, benchmarks, tutorials, libraries, and implementations. The repository aims to provide a comprehensive overview and resources for researchers and practitioners interested in advancing LLM technologies.
MaxKB
MaxKB is a knowledge base Q&A system based on the LLM large language model. MaxKB = Max Knowledge Base, which aims to become the most powerful brain of the enterprise.
Awesome-local-LLM
Awesome-local-LLM is a curated list of platforms, tools, practices, and resources that help run Large Language Models (LLMs) locally. It includes sections on inference platforms, engines, user interfaces, specific models for general purpose, coding, vision, audio, and miscellaneous tasks. The repository also covers tools for coding agents, agent frameworks, retrieval-augmented generation, computer use, browser automation, memory management, testing, evaluation, research, training, and fine-tuning. Additionally, there are tutorials on models, prompt engineering, context engineering, inference, agents, retrieval-augmented generation, and miscellaneous topics, along with a section on communities for LLM enthusiasts.

qgate-model
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.