
fairseq
Facebook AI Research Sequence-to-Sequence Toolkit written in Python.
Stars: 30241
Fairseq is a sequence modeling toolkit that enables researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. It provides reference implementations of various sequence modeling papers covering CNN, LSTM networks, Transformer networks, LightConv, DynamicConv models, Non-autoregressive Transformers, Finetuning, and more. The toolkit supports multi-GPU training, fast generation on CPU and GPU, mixed precision training, extensibility, flexible configuration based on Hydra, and full parameter and optimizer state sharding. Pre-trained models are available for translation and language modeling with a torch.hub interface. Fairseq also offers pre-trained models and examples for tasks like XLS-R, cross-lingual retrieval, wav2vec 2.0, unsupervised quality estimation, and more.
README:
![]()

![]()

Fairseq(-py) is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling and other text generation tasks.
We provide reference implementations of various sequence modeling papers:
List of implemented papers
-
Convolutional Neural Networks (CNN)
- Language Modeling with Gated Convolutional Networks (Dauphin et al., 2017)
- Convolutional Sequence to Sequence Learning (Gehring et al., 2017)
- Classical Structured Prediction Losses for Sequence to Sequence Learning (Edunov et al., 2018)
- Hierarchical Neural Story Generation (Fan et al., 2018)
- wav2vec: Unsupervised Pre-training for Speech Recognition (Schneider et al., 2019)
- LightConv and DynamicConv models
-
Long Short-Term Memory (LSTM) networks
- Effective Approaches to Attention-based Neural Machine Translation (Luong et al., 2015)
-
Transformer (self-attention) networks
- Attention Is All You Need (Vaswani et al., 2017)
- Scaling Neural Machine Translation (Ott et al., 2018)
- Understanding Back-Translation at Scale (Edunov et al., 2018)
- Adaptive Input Representations for Neural Language Modeling (Baevski and Auli, 2018)
- Lexically constrained decoding with dynamic beam allocation (Post & Vilar, 2018)
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context (Dai et al., 2019)
- Adaptive Attention Span in Transformers (Sukhbaatar et al., 2019)
- Mixture Models for Diverse Machine Translation: Tricks of the Trade (Shen et al., 2019)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach (Liu et al., 2019)
- Facebook FAIR's WMT19 News Translation Task Submission (Ng et al., 2019)
- Jointly Learning to Align and Translate with Transformer Models (Garg et al., 2019)
- Multilingual Denoising Pre-training for Neural Machine Translation (Liu et at., 2020)
- Neural Machine Translation with Byte-Level Subwords (Wang et al., 2020)
- Unsupervised Quality Estimation for Neural Machine Translation (Fomicheva et al., 2020)
- wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations (Baevski et al., 2020)
- Generating Medical Reports from Patient-Doctor Conversations Using Sequence-to-Sequence Models (Enarvi et al., 2020)
- Linformer: Self-Attention with Linear Complexity (Wang et al., 2020)
- Cross-lingual Retrieval for Iterative Self-Supervised Training (Tran et al., 2020)
- Deep Transformers with Latent Depth (Li et al., 2020)
- Unsupervised Cross-lingual Representation Learning for Speech Recognition (Conneau et al., 2020)
- Self-training and Pre-training are Complementary for Speech Recognition (Xu et al., 2020)
- Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training (Hsu, et al., 2021)
- Unsupervised Speech Recognition (Baevski, et al., 2021)
- Simple and Effective Zero-shot Cross-lingual Phoneme Recognition (Xu et al., 2021)
- VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding (Xu et. al., 2021)
- VLM: Task-agnostic Video-Language Model Pre-training for Video Understanding (Xu et. al., 2021)
- NormFormer: Improved Transformer Pretraining with Extra Normalization (Shleifer et. al, 2021)
-
Non-autoregressive Transformers
- Non-Autoregressive Neural Machine Translation (Gu et al., 2017)
- Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement (Lee et al. 2018)
- Insertion Transformer: Flexible Sequence Generation via Insertion Operations (Stern et al. 2019)
- Mask-Predict: Parallel Decoding of Conditional Masked Language Models (Ghazvininejad et al., 2019)
- Levenshtein Transformer (Gu et al., 2019)
- Finetuning
- May 2023 Released models for Scaling Speech Technology to 1,000+ Languages (Pratap, et al., 2023)
- June 2022 Released code for wav2vec-U 2.0 from Towards End-to-end Unsupervised Speech Recognition (Liu, et al., 2022)
- May 2022 Integration with xFormers
- December 2021 Released Direct speech-to-speech translation code
- October 2021 Released VideoCLIP and VLM models
- October 2021 Released multilingual finetuned XLSR-53 model
- September 2021
masterbranch renamed tomain. - July 2021 Released DrNMT code
- July 2021 Released Robust wav2vec 2.0 model
- June 2021 Released XLMR-XL and XLMR-XXL models
- May 2021 Released Unsupervised Speech Recognition code
- March 2021 Added full parameter and optimizer state sharding + CPU offloading
- February 2021 Added LASER training code
- December 2020: Added Adaptive Attention Span code
- December 2020: GottBERT model and code released
- November 2020: Adopted the Hydra configuration framework
- November 2020: fairseq 0.10.0 released
- October 2020: Added R3F/R4F (Better Fine-Tuning) code
- October 2020: Deep Transformer with Latent Depth code released
- October 2020: Added CRISS models and code
Previous updates
- September 2020: Added Linformer code
- September 2020: Added pointer-generator networks
- August 2020: Added lexically constrained decoding
- August 2020: wav2vec2 models and code released
- July 2020: Unsupervised Quality Estimation code released
- May 2020: Follow fairseq on Twitter
- April 2020: Monotonic Multihead Attention code released
- April 2020: Quant-Noise code released
- April 2020: Initial model parallel support and 11B parameters unidirectional LM released
- March 2020: Byte-level BPE code released
- February 2020: mBART model and code released
- February 2020: Added tutorial for back-translation
- December 2019: fairseq 0.9.0 released
- November 2019: VizSeq released (a visual analysis toolkit for evaluating fairseq models)
- November 2019: CamemBERT model and code released
- November 2019: BART model and code released
- November 2019: XLM-R models and code released
- September 2019: Nonautoregressive translation code released
- August 2019: WMT'19 models released
- July 2019: fairseq relicensed under MIT license
- July 2019: RoBERTa models and code released
- June 2019: wav2vec models and code released
- multi-GPU training on one machine or across multiple machines (data and model parallel)
- fast generation on both CPU and GPU with multiple search algorithms implemented:
- beam search
- Diverse Beam Search (Vijayakumar et al., 2016)
- sampling (unconstrained, top-k and top-p/nucleus)
- lexically constrained decoding (Post & Vilar, 2018)
- gradient accumulation enables training with large mini-batches even on a single GPU
- mixed precision training (trains faster with less GPU memory on NVIDIA tensor cores)
- extensible: easily register new models, criterions, tasks, optimizers and learning rate schedulers
- flexible configuration based on Hydra allowing a combination of code, command-line and file based configuration
- full parameter and optimizer state sharding
- offloading parameters to CPU
We also provide pre-trained models for translation and language modeling
with a convenient torch.hub interface:
en2de = torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-de.single_model')
en2de.translate('Hello world', beam=5)
# 'Hallo Welt'See the PyTorch Hub tutorials for translation and RoBERTa for more examples.
- PyTorch version >= 1.10.0
- Python version >= 3.8
- For training new models, you'll also need an NVIDIA GPU and NCCL
- To install fairseq and develop locally:
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install --editable ./
# on MacOS:
# CFLAGS="-stdlib=libc++" pip install --editable ./
# to install the latest stable release (0.10.x)
# pip install fairseq- For faster training install NVIDIA's apex library:
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" \
--global-option="--deprecated_fused_adam" --global-option="--xentropy" \
--global-option="--fast_multihead_attn" ./-
For large datasets install PyArrow:
pip install pyarrow - If you use Docker make sure to increase the shared memory size either with
--ipc=hostor--shm-sizeas command line options tonvidia-docker run.
The full documentation contains instructions for getting started, training new models and extending fairseq with new model types and tasks.
We provide pre-trained models and pre-processed, binarized test sets for several tasks listed below, as well as example training and evaluation commands.
- Translation: convolutional and transformer models are available
- Language Modeling: convolutional and transformer models are available
We also have more detailed READMEs to reproduce results from specific papers:
- XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale (Babu et al., 2021)
- Cross-lingual Retrieval for Iterative Self-Supervised Training (Tran et al., 2020)
- wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations (Baevski et al., 2020)
- Unsupervised Quality Estimation for Neural Machine Translation (Fomicheva et al., 2020)
- Training with Quantization Noise for Extreme Model Compression ({Fan*, Stock*} et al., 2020)
- Neural Machine Translation with Byte-Level Subwords (Wang et al., 2020)
- Multilingual Denoising Pre-training for Neural Machine Translation (Liu et at., 2020)
- Reducing Transformer Depth on Demand with Structured Dropout (Fan et al., 2019)
- Jointly Learning to Align and Translate with Transformer Models (Garg et al., 2019)
- Levenshtein Transformer (Gu et al., 2019)
- Facebook FAIR's WMT19 News Translation Task Submission (Ng et al., 2019)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach (Liu et al., 2019)
- wav2vec: Unsupervised Pre-training for Speech Recognition (Schneider et al., 2019)
- Mixture Models for Diverse Machine Translation: Tricks of the Trade (Shen et al., 2019)
- Pay Less Attention with Lightweight and Dynamic Convolutions (Wu et al., 2019)
- Understanding Back-Translation at Scale (Edunov et al., 2018)
- Classical Structured Prediction Losses for Sequence to Sequence Learning (Edunov et al., 2018)
- Hierarchical Neural Story Generation (Fan et al., 2018)
- Scaling Neural Machine Translation (Ott et al., 2018)
- Convolutional Sequence to Sequence Learning (Gehring et al., 2017)
- Language Modeling with Gated Convolutional Networks (Dauphin et al., 2017)
- Twitter: https://twitter.com/fairseq
- Facebook page: https://www.facebook.com/groups/fairseq.users
- Google group: https://groups.google.com/forum/#!forum/fairseq-users
fairseq(-py) is MIT-licensed. The license applies to the pre-trained models as well.
Please cite as:
@inproceedings{ott2019fairseq,
title = {fairseq: A Fast, Extensible Toolkit for Sequence Modeling},
author = {Myle Ott and Sergey Edunov and Alexei Baevski and Angela Fan and Sam Gross and Nathan Ng and David Grangier and Michael Auli},
booktitle = {Proceedings of NAACL-HLT 2019: Demonstrations},
year = {2019},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for fairseq
Similar Open Source Tools
fairseq
Fairseq is a sequence modeling toolkit that enables researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. It provides reference implementations of various sequence modeling papers covering CNN, LSTM networks, Transformer networks, LightConv, DynamicConv models, Non-autoregressive Transformers, Finetuning, and more. The toolkit supports multi-GPU training, fast generation on CPU and GPU, mixed precision training, extensibility, flexible configuration based on Hydra, and full parameter and optimizer state sharding. Pre-trained models are available for translation and language modeling with a torch.hub interface. Fairseq also offers pre-trained models and examples for tasks like XLS-R, cross-lingual retrieval, wav2vec 2.0, unsupervised quality estimation, and more.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.
PPTAgent
PPTAgent is an innovative system that automatically generates presentations from documents. It employs a two-step process for quality assurance and introduces PPTEval for comprehensive evaluation. With dynamic content generation, smart reference learning, and quality assessment, PPTAgent aims to streamline presentation creation. The tool follows an analysis phase to learn from reference presentations and a generation phase to develop structured outlines and cohesive slides. PPTEval evaluates presentations based on content accuracy, visual appeal, and logical coherence.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.
LMCache
LMCache is a serving engine extension designed to reduce time to first token (TTFT) and increase throughput, particularly in long-context scenarios. It stores key-value caches of reusable texts across different locations like GPU, CPU DRAM, and Local Disk, allowing the reuse of any text in any serving engine instance. By combining LMCache with vLLM, significant delay savings and GPU cycle reduction are achieved in various large language model (LLM) use cases, such as multi-round question answering and retrieval-augmented generation (RAG). LMCache provides integration with the latest vLLM version, offering both online serving and offline inference capabilities. It supports sharing key-value caches across multiple vLLM instances and aims to provide stable support for non-prefix key-value caches along with user and developer documentation.
awesome-green-ai
Awesome Green AI is a curated list of resources and tools aimed at reducing the environmental impacts of using and deploying AI. It addresses the carbon footprint of the ICT sector, emphasizing the importance of AI in reducing environmental impacts beyond GHG emissions and electricity consumption. The tools listed cover code-based tools for measuring environmental impacts, monitoring tools for power consumption, optimization tools for energy efficiency, and calculation tools for estimating environmental impacts of algorithms and models. The repository also includes leaderboards, papers, survey papers, and reports related to green AI and environmental sustainability in the AI sector.
AI-Infra-Guard
A.I.G (AI-Infra-Guard) is an AI red teaming platform by Tencent Zhuque Lab that integrates capabilities such as AI infra vulnerability scan, MCP Server risk scan, and Jailbreak Evaluation. It aims to provide users with a comprehensive, intelligent, and user-friendly solution for AI security risk self-examination. The platform offers features like AI Infra Scan, AI Tool Protocol Scan, and Jailbreak Evaluation, along with a modern web interface, complete API, multi-language support, cross-platform deployment, and being free and open-source under the MIT license.
Building-a-Small-LLM-from-Scratch
This tutorial provides a comprehensive guide on building a small Large Language Model (LLM) from scratch using PyTorch. The author shares insights and experiences gained from working on LLM projects in the industry, aiming to help beginners understand the fundamental components of LLMs and training fine-tuning codes. The tutorial covers topics such as model structure overview, attention modules, optimization techniques, normalization layers, tokenizers, pretraining, and fine-tuning with dialogue data. It also addresses specific industry-related challenges and explores cutting-edge model concepts like DeepSeek network structure, causal attention, dynamic-to-static tensor conversion for ONNX inference, and performance optimizations for NPU chips. The series emphasizes hands-on practice with small models to enable local execution and plans to expand into multimodal language models and tensor parallel multi-card deployment.
qgate-model
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.
video-SALMONN-2
video-SALMONN 2 is a powerful audio-visual large language model that generates high-quality audio-visual video captions. Developed by the Department of Electronic Engineering at Tsinghua University and ByteDance, it offers various models achieving state-of-the-art results on audio-visual QA benchmarks and visual-only benchmarks. Users can train the model, evaluate checkpoints, and access different versions of video-SALMONN 2 for enhanced audio-visual understanding.
AICIty-reID-2020
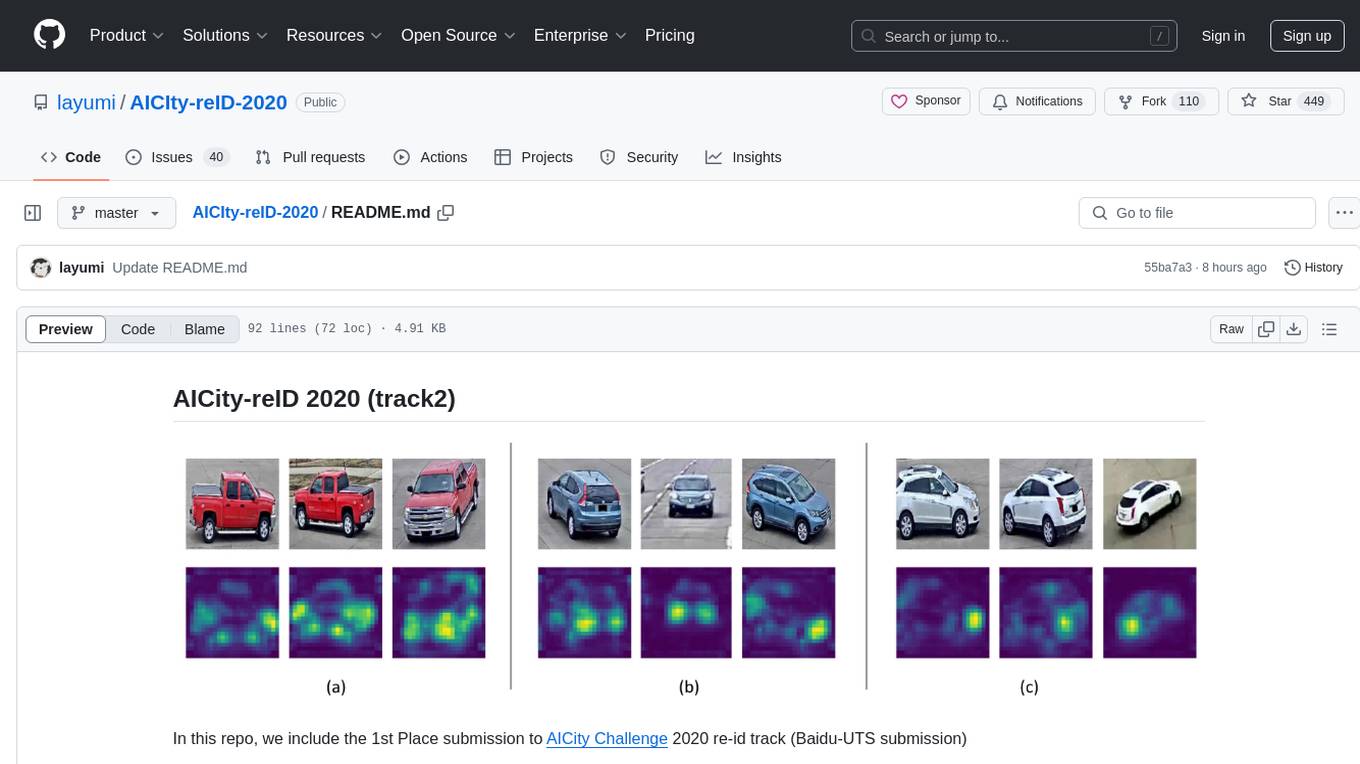
AICIty-reID 2020 is a repository containing the 1st Place submission to AICity Challenge 2020 re-id track by Baidu-UTS. It includes models trained on Paddlepaddle and Pytorch, with performance metrics and trained models provided. Users can extract features, perform camera and direction prediction, and access related repositories for drone-based building re-id, vehicle re-ID, person re-ID baseline, and person/vehicle generation. Citations are also provided for research purposes.
adversarial-robustness-toolbox
Adversarial Robustness Toolbox (ART) is a Python library for Machine Learning Security. ART provides tools that enable developers and researchers to defend and evaluate Machine Learning models and applications against the adversarial threats of Evasion, Poisoning, Extraction, and Inference. ART supports all popular machine learning frameworks (TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost, LightGBM, CatBoost, GPy, etc.), all data types (images, tables, audio, video, etc.) and machine learning tasks (classification, object detection, speech recognition, generation, certification, etc.).

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.