
adversarial-robustness-toolbox
Adversarial Robustness Toolbox (ART) - Python Library for Machine Learning Security - Evasion, Poisoning, Extraction, Inference - Red and Blue Teams
Stars: 5003
Adversarial Robustness Toolbox (ART) is a Python library for Machine Learning Security. ART provides tools that enable developers and researchers to defend and evaluate Machine Learning models and applications against the adversarial threats of Evasion, Poisoning, Extraction, and Inference. ART supports all popular machine learning frameworks (TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost, LightGBM, CatBoost, GPy, etc.), all data types (images, tables, audio, video, etc.) and machine learning tasks (classification, object detection, speech recognition, generation, certification, etc.).
README:

![]()

![]()
Adversarial Robustness Toolbox (ART) is a Python library for Machine Learning Security. ART is hosted by the Linux Foundation AI & Data Foundation (LF AI & Data). ART provides tools that enable developers and researchers to defend and evaluate Machine Learning models and applications against the adversarial threats of Evasion, Poisoning, Extraction, and Inference. ART supports all popular machine learning frameworks (TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost, LightGBM, CatBoost, GPy, etc.), all data types (images, tables, audio, video, etc.) and machine learning tasks (classification, object detection, speech recognition, generation, certification, etc.).



| Get Started | Documentation | Contributing |
|---|---|---|
| - Installation - Examples - Notebooks |
- Attacks - Defences - Estimators - Metrics - Technical Documentation |
- Slack, Invitation - Contributing - Roadmap - Citing |
The library is under continuous development. Feedback, bug reports and contributions are very welcome!
This material is partially based upon work supported by the Defense Advanced Research Projects Agency (DARPA) under Contract No. HR001120C0013. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the Defense Advanced Research Projects Agency (DARPA).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for adversarial-robustness-toolbox
Similar Open Source Tools
adversarial-robustness-toolbox
Adversarial Robustness Toolbox (ART) is a Python library for Machine Learning Security. ART provides tools that enable developers and researchers to defend and evaluate Machine Learning models and applications against the adversarial threats of Evasion, Poisoning, Extraction, and Inference. ART supports all popular machine learning frameworks (TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost, LightGBM, CatBoost, GPy, etc.), all data types (images, tables, audio, video, etc.) and machine learning tasks (classification, object detection, speech recognition, generation, certification, etc.).

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.
intro_pharma_ai
This repository serves as an educational resource for pharmaceutical and chemistry students to learn the basics of Deep Learning through a collection of Jupyter Notebooks. The content covers various topics such as Introduction to Jupyter, Python, Cheminformatics & RDKit, Linear Regression, Data Science, Linear Algebra, Neural Networks, PyTorch, Convolutional Neural Networks, Transfer Learning, Recurrent Neural Networks, Autoencoders, Graph Neural Networks, and Summary. The notebooks aim to provide theoretical concepts to understand neural networks through code completion, but instructors are encouraged to supplement with their own lectures. The work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
agents-towards-production
Agents Towards Production is an open-source playbook for building production-ready GenAI agents that scale from prototype to enterprise. Tutorials cover stateful workflows, vector memory, real-time web search APIs, Docker deployment, FastAPI endpoints, security guardrails, GPU scaling, browser automation, fine-tuning, multi-agent coordination, observability, evaluation, and UI development.
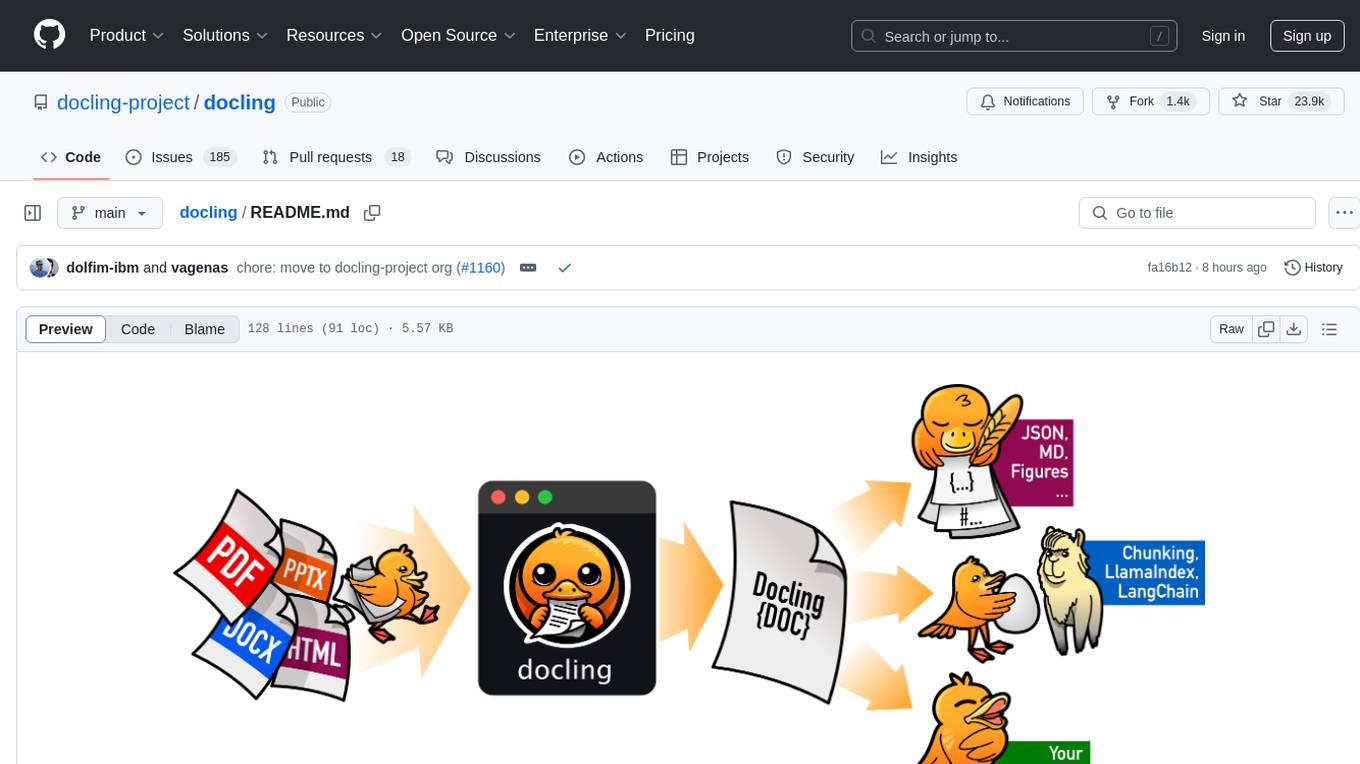
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.
LMCache
LMCache is a serving engine extension designed to reduce time to first token (TTFT) and increase throughput, particularly in long-context scenarios. It stores key-value caches of reusable texts across different locations like GPU, CPU DRAM, and Local Disk, allowing the reuse of any text in any serving engine instance. By combining LMCache with vLLM, significant delay savings and GPU cycle reduction are achieved in various large language model (LLM) use cases, such as multi-round question answering and retrieval-augmented generation (RAG). LMCache provides integration with the latest vLLM version, offering both online serving and offline inference capabilities. It supports sharing key-value caches across multiple vLLM instances and aims to provide stable support for non-prefix key-value caches along with user and developer documentation.
qgate-model
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.
SWE-agent
SWE-agent is a tool that turns language models (e.g. GPT-4) into software engineering agents capable of fixing bugs and issues in real GitHub repositories. It achieves state-of-the-art performance on the full test set by resolving 12.29% of issues. The tool is built and maintained by researchers from Princeton University. SWE-agent provides a command line tool and a graphical web interface for developers to interact with. It introduces an Agent-Computer Interface (ACI) to facilitate browsing, viewing, editing, and executing code files within repositories. The tool includes features such as a linter for syntax checking, a specialized file viewer, and a full-directory string searching command to enhance the agent's capabilities. SWE-agent aims to improve prompt engineering and ACI design to enhance the performance of language models in software engineering tasks.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.
novelai-bot
This repository contains a drawing plugin based on NovelAI. It allows users to draw images, change models, samplers, and image sizes, use advanced request syntax, customize prohibited word lists, automatically translate Chinese keywords, automatically retract messages after a certain time, and connect to private servers. Thanks to Koishi's plugin mechanism, users can achieve more functionalities by combining it with other plugins, such as multi-platform support, rate limiting, context management, and multi-language support.
Workshops
Workshops is a repository containing workshop subjects and materials for developers. It covers a wide range of topics including AI, AR/VR, hardware, security, software, and peer-to-peer technologies. The repository is designed to provide developers with resources and materials to enhance their skills and knowledge in various technology domains.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.
webots
Webots is an open-source robot simulator that provides a complete development environment to model, program, and simulate robots, vehicles, and mechanical systems. It was originally designed at EPFL in 1996 and further developed and commercialized by Cyberbotics since 1998. Webots was open-sourced in December 2018 and continues to be developed by Cyberbotics with paid customer support, training, and consulting services for industry and academic research projects.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.
For similar tasks
adversarial-robustness-toolbox
Adversarial Robustness Toolbox (ART) is a Python library for Machine Learning Security. ART provides tools that enable developers and researchers to defend and evaluate Machine Learning models and applications against the adversarial threats of Evasion, Poisoning, Extraction, and Inference. ART supports all popular machine learning frameworks (TensorFlow, Keras, PyTorch, MXNet, scikit-learn, XGBoost, LightGBM, CatBoost, GPy, etc.), all data types (images, tables, audio, video, etc.) and machine learning tasks (classification, object detection, speech recognition, generation, certification, etc.).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.