
MiniCPM-V-CookBook
Cook up amazing multimodal AI applications effortlessly with MiniCPM-o
Stars: 192

MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.
README:
🏠 Main Repository | 📚 Full Documentation
Cook up amazing multimodal AI applications effortlessly with MiniCPM-o, bringing vision, speech, and live-streaming capabilities right to your fingertips!
Our comprehensive documentation website presents every recipe in a clear, well-organized manner. All features are displayed at a glance, making it easy for you to quickly find exactly what you need.
We support a wide range of users, from individuals to enterprises and researchers.
- Individuals: Enjoy effortless inference using Ollama and Llama.cpp with minimal setup.
- Enterprises: Achieve high-throughput, scalable performance with vLLM and SGLang.
- Researchers: Leverage advanced frameworks including Transformers , LLaMA-Factory, SWIFT, and Align-anything to enable flexible model development and cutting-edge experimentation.
Our ecosystem delivers optimal solution for a variety of hardware environments and deployment demands.
- Web demo: Launch interactive multimodal AI web demo with FastAPI.
- Quantized deployment: Maximize efficiency and minimize resource consumption using GGUF, BNB, and AWQ.
- Edge devices: Bring powerful AI experiences to iPhone and iPad, supporting offline and privacy-sensitive applications.
Explore real-world examples of MiniCPM-V deployed on edge devices using our curated recipes. These demos highlight the model’s high efficiency and robust performance in practical scenarios.
- Run locally on iPhone with iOS demo.


- Run locally on iPad with iOS demo, observing the process of drawing a rabbit.
Ready-to-run examples
| Recipe | Description |
|---|---|
| Vision Capabilities | |
| 🖼️ Single-image QA | Question answering on a single image |
| 🧩 Multi-image QA | Question answering with multiple images |
| 🎬 Video QA | Video-based question answering |
| 📄 Document Parser | Parse and extract content from PDFs and webpages |
| 📝 Text Recognition | Reliable OCR for photos and screenshots |
| Audio Capabilities | |
| 🎤 Speech-to-Text | Multilingual speech recognition |
| 🗣️ Text-to-Speech | Instruction-following speech synthesis |
| 🎭 Voice Cloning | Realistic voice cloning and role-play |
Customize your model with your own ingredients
Data preparation
Follow the guidance to set up your training datasets.
Training
We provide training methods serving different needs as following:
| Framework | Description |
|---|---|
| Transformers | Most flexible for customization |
| LLaMA-Factory | Modular fine-tuning toolkit |
| SWIFT | Lightweight and fast parameter-efficient tuning |
| Align-anything | Visual instruction alignment for multimodal models |
Deploy your model efficiently
| Method | Description |
|---|---|
| vLLM | High-throughput GPU inference |
| SGLang | High-throughput GPU inference |
| Llama.cpp | Fast CPU inference on PC, iPhone and iPad |
| Ollama | User-friendly setup |
| OpenWebUI | Interactive Web demo with Open WebUI |
| Gradio | Interactive Web demo with Gradio |
| FastAPI | Interactive Omni Streaming demo with FastAPI |
| iOS | Interactive iOS demo with llama.cpp |
Compress your model to improve efficiency
| Format | Key Feature |
|---|---|
| GGUF | Simplest and most portable format |
| BNB | Simple and easy-to-use quantization method |
| AWQ | High-performance quantization for efficient inference |
| Category | Framework | Cookbook Link | Upstream PR | Supported since (branch) | Supported since (release) |
|---|---|---|---|---|---|
| Edge (On-device) | Llama.cpp | Llama.cpp Doc | #15575 (2025-08-26) | master (2025-08-26) | b6282 |
| Ollama | Ollama Doc | #12078 (2025-08-26) | Merging | Waiting for official release | |
| Serving (Cloud) | vLLM | vLLM Doc | #23586 (2025-08-26) | main (2025-08-27) | v0.10.2 |
| SGLang | SGLang Doc | #9610 (2025-08-26) | Merging | Waiting for official release | |
| Finetuning | LLaMA-Factory | LLaMA-Factory Doc | #9022 (2025-08-26) | main (2025-08-26) | Waiting for official release |
| Quantization | GGUF | GGUF Doc | — | — | — |
| BNB | BNB Doc | — | — | — | |
| AWQ | AWQ Doc | — | — | — | |
| Demos | Gradio Demo | Gradio Demo Doc | — | — | — |
If you'd like us to prioritize support for another open-source framework, please let us know via this short form.
-
text-extract-api: Document extraction API using OCRs and Ollama supported models
-
comfyui_LLM_party: Build LLM workflows and integrate into existing image workflows
-
Ollama-OCR: OCR package uses vlms through Ollama to extract text from images and PDF
-
comfyui-mixlab-nodes: ComfyUI node suite supports Workflow-to-APP、GPT&3D and more
-
OpenAvatarChat: Interactive digital human conversation implementation on single PC
-
pensieve: A privacy-focused passive recording project by recording screen content
-
paperless-gpt: Use LLMs to handle paperless-ngx, AI-powered titles, tags and OCR
-
Neuro: A recreation of Neuro-Sama, but running on local models on consumer hardware







We love new recipes! Please share your creative dishes:
- Fork the repository
- Create your recipe
- Submit a pull request
- Found a bug? Open an issue
- Need help? Join our Discord
This cookbook is developed by OpenBMB and OpenSQZ.
This cookbook is served under the Apache-2.0 License - cook freely, share generously! 🍳
If you find our model/code/paper helpful, please consider citing our papers 📝 and staring us ⭐️!
@misc{yu2025minicpmv45cookingefficient,
title={MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe},
author={Tianyu Yu and Zefan Wang and Chongyi Wang and Fuwei Huang and Wenshuo Ma and Zhihui He and Tianchi Cai and Weize Chen and Yuxiang Huang and Yuanqian Zhao and Bokai Xu and Junbo Cui and Yingjing Xu and Liqing Ruan and Luoyuan Zhang and Hanyu Liu and Jingkun Tang and Hongyuan Liu and Qining Guo and Wenhao Hu and Bingxiang He and Jie Zhou and Jie Cai and Ji Qi and Zonghao Guo and Chi Chen and Guoyang Zeng and Yuxuan Li and Ganqu Cui and Ning Ding and Xu Han and Yuan Yao and Zhiyuan Liu and Maosong Sun},
year={2025},
eprint={2509.18154},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2509.18154},
}
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={Nat Commun 16, 5509 (2025)},
year={2025}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MiniCPM-V-CookBook
Similar Open Source Tools
MiniCPM-V-CookBook
MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.
generative-ai-with-javascript
The 'Generative AI with JavaScript' repository is a comprehensive resource hub for JavaScript developers interested in delving into the world of Generative AI. It provides code samples, tutorials, and resources from a video series, offering best practices and tips to enhance AI skills. The repository covers the basics of generative AI, guides on building AI applications using JavaScript, from local development to deployment on Azure, and scaling AI models. It is a living repository with continuous updates, making it a valuable resource for both beginners and experienced developers looking to explore AI with JavaScript.
Awesome-AITools
This repo collects AI-related utilities. ## All Categories * All Categories * ChatGPT and other closed-source LLMs * AI Search engine * Open Source LLMs * GPT/LLMs Applications * LLM training platform * Applications that integrate multiple LLMs * AI Agent * Writing * Programming Development * Translation * AI Conversation or AI Voice Conversation * Image Creation * Speech Recognition * Text To Speech * Voice Processing * AI generated music or sound effects * Speech translation * Video Creation * Video Content Summary * OCR(Optical Character Recognition)
Vision-Agents
Vision Agents is an open-source project by Stream that provides building blocks for creating intelligent, low-latency video experiences powered by custom models and infrastructure. It offers multi-modal AI agents that watch, listen, and understand video in real-time. The project includes SDKs for various platforms and integrates with popular AI services like Gemini and OpenAI. Vision Agents can be used for tasks such as sports coaching, security camera systems with package theft detection, and building invisible assistants for various applications. The project aims to simplify the development of real-time vision AI applications by providing a range of processors, integrations, and out-of-the-box features.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.
rai
RAI is a framework designed to bring general multi-agent system capabilities to robots, enhancing human interactivity, flexibility in problem-solving, and out-of-the-box AI features. It supports multi-modalities, incorporates an advanced database for agent memory, provides ROS 2-oriented tooling, and offers a comprehensive task/mission orchestrator. The framework includes features such as voice interaction, customizable robot identity, camera sensor access, reasoning through ROS logs, and integration with LangChain for AI tools. RAI aims to support various AI vendors, improve human-robot interaction, provide an SDK for developers, and offer a user interface for configuration.
ai-hands-on
A complete, hands-on guide to becoming an AI Engineer. This repository is designed to help you learn AI from first principles, build real neural networks, and understand modern LLM systems end-to-end. Progress through math, PyTorch, deep learning, transformers, RAG, and OCR with clean, intuitive Jupyter notebooks guiding you at every step. Suitable for beginners and engineers leveling up, providing clarity, structure, and intuition to build real AI systems.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.
AI-For-Beginners
AI-For-Beginners is a comprehensive 12-week, 24-lesson curriculum designed by experts at Microsoft to introduce beginners to the world of Artificial Intelligence (AI). The curriculum covers various topics such as Symbolic AI, Neural Networks, Computer Vision, Natural Language Processing, Genetic Algorithms, and Multi-Agent Systems. It includes hands-on lessons, quizzes, and labs using popular frameworks like TensorFlow and PyTorch. The focus is on providing a foundational understanding of AI concepts and principles, making it an ideal starting point for individuals interested in AI.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).
RustySEO
RustySEO is a free, modern SEO/GEO toolkit designed to help users crawl and analyze websites and server logs without crawl limits. It is an all-in-one, cross-platform marketing toolkit for comprehensive SEO & GEO analysis, providing actionable insights into marketing and SEO strategies. The tool offers features such as shallow & deep crawl, technical diagnostics, on-page SEO analysis, dashboards, reporting, topic and keyword generators, AI chatbot, crawl history, image conversion and optimization, and more. RustySEO aims to be a robust, free alternative to costly commercial SEO tools, with integrations like Google PageSpeed Insights, Google Gemini, and more.

together-cookbook
The Together Cookbook is a collection of code and guides designed to help developers build with open source models using Together AI. The recipes provide examples on how to chain multiple LLM calls, create agents that route tasks to specialized models, run multiple LLMs in parallel, break down tasks into parallel subtasks, build agents that iteratively improve responses, perform LoRA fine-tuning and inference, fine-tune LLMs for repetition, improve summarization capabilities, fine-tune LLMs on multi-step conversations, implement retrieval-augmented generation, conduct multimodal search and conditional image generation, visualize vector embeddings, improve search results with rerankers, implement vector search with embedding models, extract structured text from images, summarize and evaluate outputs with LLMs, generate podcasts from PDF content, and get LLMs to generate knowledge graphs.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
generative-ai-for-beginners
This course has 18 lessons. Each lesson covers its own topic so start wherever you like! Lessons are labeled either "Learn" lessons explaining a Generative AI concept or "Build" lessons that explain a concept and code examples in both **Python** and **TypeScript** when possible. Each lesson also includes a "Keep Learning" section with additional learning tools. **What You Need** * Access to the Azure OpenAI Service **OR** OpenAI API - _Only required to complete coding lessons_ * Basic knowledge of Python or Typescript is helpful - *For absolute beginners check out these Python and TypeScript courses. * A Github account to fork this entire repo to your own GitHub account We have created a **Course Setup** lesson to help you with setting up your development environment. Don't forget to star (🌟) this repo to find it easier later. ## 🧠 Ready to Deploy? If you are looking for more advanced code samples, check out our collection of Generative AI Code Samples in both **Python** and **TypeScript**. ## 🗣️ Meet Other Learners, Get Support Join our official AI Discord server to meet and network with other learners taking this course and get support. ## 🚀 Building a Startup? Sign up for Microsoft for Startups Founders Hub to receive **free OpenAI credits** and up to **$150k towards Azure credits to access OpenAI models through Azure OpenAI Services**. ## 🙏 Want to help? Do you have suggestions or found spelling or code errors? Raise an issue or Create a pull request ## 📂 Each lesson includes: * A short video introduction to the topic * A written lesson located in the README * Python and TypeScript code samples supporting Azure OpenAI and OpenAI API * Links to extra resources to continue your learning ## 🗃️ Lessons | | Lesson Link | Description | Additional Learning | | :-: | :------------------------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------: | ------------------------------------------------------------------------------ | | 00 | Course Setup | **Learn:** How to Setup Your Development Environment | Learn More | | 01 | Introduction to Generative AI and LLMs | **Learn:** Understanding what Generative AI is and how Large Language Models (LLMs) work. | Learn More | | 02 | Exploring and comparing different LLMs | **Learn:** How to select the right model for your use case | Learn More | | 03 | Using Generative AI Responsibly | **Learn:** How to build Generative AI Applications responsibly | Learn More | | 04 | Understanding Prompt Engineering Fundamentals | **Learn:** Hands-on Prompt Engineering Best Practices | Learn More | | 05 | Creating Advanced Prompts | **Learn:** How to apply prompt engineering techniques that improve the outcome of your prompts. | Learn More | | 06 | Building Text Generation Applications | **Build:** A text generation app using Azure OpenAI | Learn More | | 07 | Building Chat Applications | **Build:** Techniques for efficiently building and integrating chat applications. | Learn More | | 08 | Building Search Apps Vector Databases | **Build:** A search application that uses Embeddings to search for data. | Learn More | | 09 | Building Image Generation Applications | **Build:** A image generation application | Learn More | | 10 | Building Low Code AI Applications | **Build:** A Generative AI application using Low Code tools | Learn More | | 11 | Integrating External Applications with Function Calling | **Build:** What is function calling and its use cases for applications | Learn More | | 12 | Designing UX for AI Applications | **Learn:** How to apply UX design principles when developing Generative AI Applications | Learn More | | 13 | Securing Your Generative AI Applications | **Learn:** The threats and risks to AI systems and methods to secure these systems. | Learn More | | 14 | The Generative AI Application Lifecycle | **Learn:** The tools and metrics to manage the LLM Lifecycle and LLMOps | Learn More | | 15 | Retrieval Augmented Generation (RAG) and Vector Databases | **Build:** An application using a RAG Framework to retrieve embeddings from a Vector Databases | Learn More | | 16 | Open Source Models and Hugging Face | **Build:** An application using open source models available on Hugging Face | Learn More | | 17 | AI Agents | **Build:** An application using an AI Agent Framework | Learn More | | 18 | Fine-Tuning LLMs | **Learn:** The what, why and how of fine-tuning LLMs | Learn More |

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.
For similar tasks
MiniCPM-V-CookBook
MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.
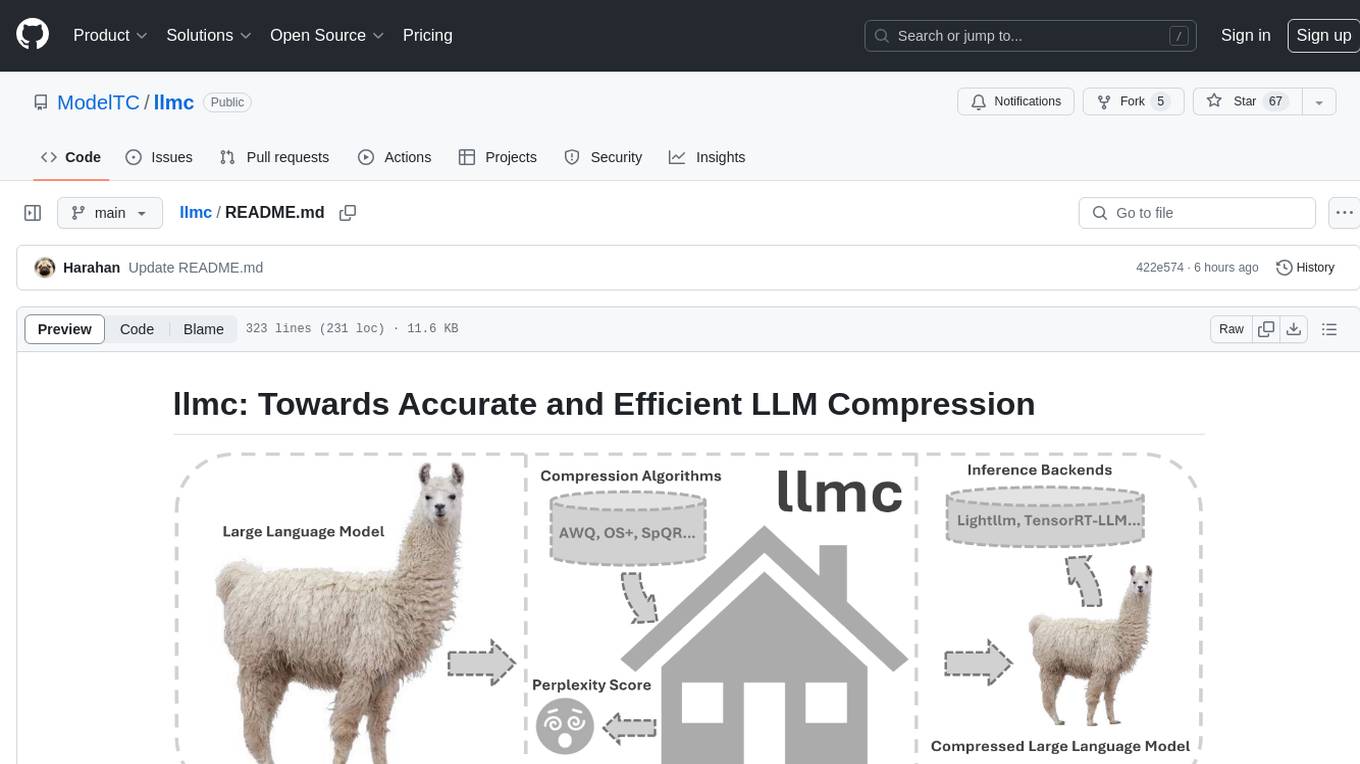
llmc
llmc is an off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance. It provides users with the ability to quantize LLMs, choose from various compression algorithms, export transformed models for further optimization, and directly infer compressed models with a shallow memory footprint. The tool supports a range of model types and quantization algorithms, with ongoing development to include pruning techniques. Users can design their configurations for quantization and evaluation, with documentation and examples planned for future updates. llmc is a valuable resource for researchers working on post-training quantization of large language models.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.