
finetrainers
Memory-optimized training library for diffusion models
Stars: 964
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.
README:
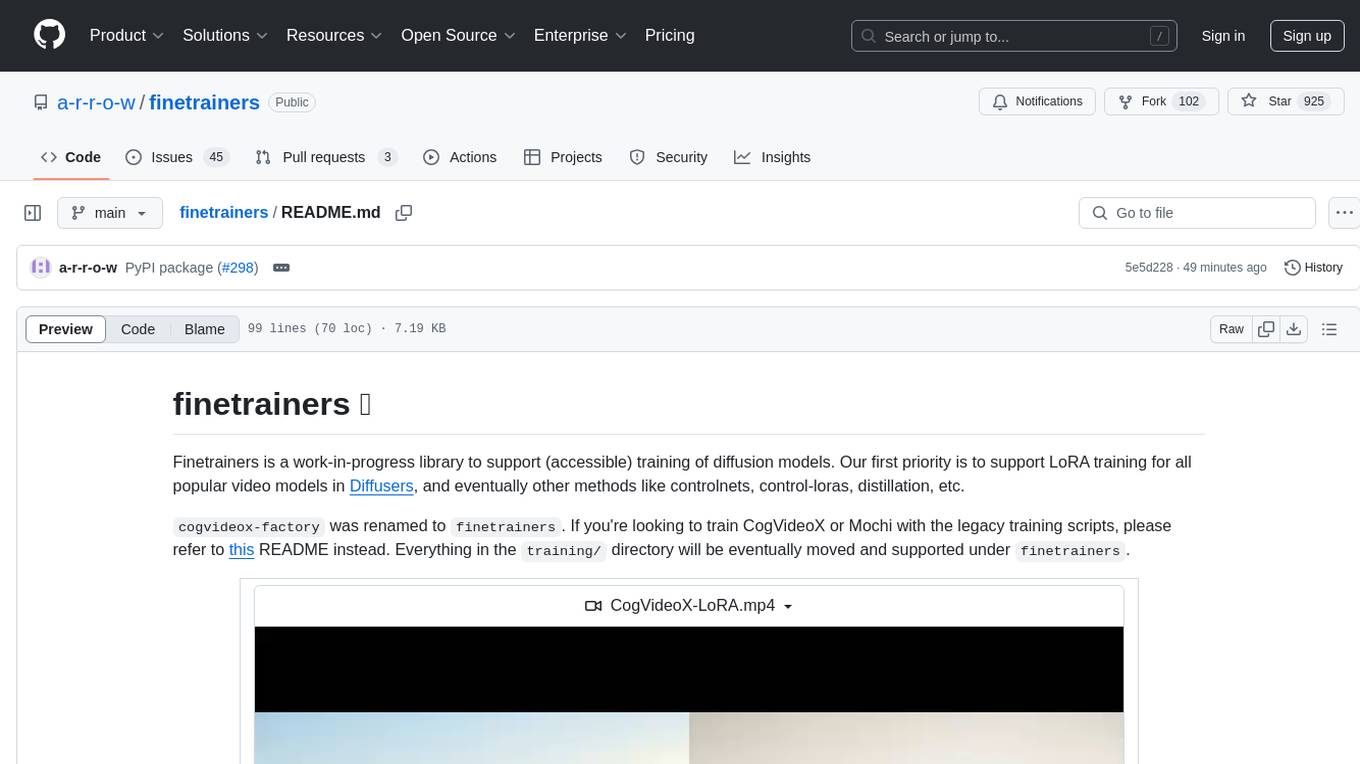
Finetrainers is a work-in-progress library to support (accessible) training of diffusion models. Our first priority is to support LoRA training for all popular video models in Diffusers, and eventually other methods like controlnets, control-loras, distillation, etc.
| Your browser does not support the video tag. | Your browser does not support the video tag. |
| CogVideoX LoRA training as the first iteration of this project | Replication of PikaEffects |
|---|
Clone the repository and make sure the requirements are installed: pip install -r requirements.txt and install diffusers from source by pip install git+https://github.com/huggingface/diffusers. The requirements specify diffusers>=0.32.1, but it is always recommended to use the main branch of Diffusers for the latest features and bugfixes. Note that the main branch for finetrainers is also the development branch, and stable support should be expected from the release tags.
Checkout to the latest release tag:
git fetch --all --tags
git checkout tags/v0.0.1Follow the instructions mentioned in the README for the latest stable release.
To get started quickly with example training scripts on the main development branch, refer to the following:
The following are some simple datasets/HF orgs with good datasets to test training with quickly:
- Disney Video Generation Dataset
- bigdatapw Video Dataset Collection
- Finetrainers HF Dataset Collection
Please checkout docs/models and examples/training to learn more about supported models for training & example reproducible training launch scripts.
[!IMPORTANT] It is recommended to use Pytorch 2.5.1 or above for training. Previous versions can lead to completely black videos, OOM errors, or other issues and are not tested. For fully reproducible training, please use the same environment as mentioned in environment.md.
- 🔥 2025-03-07: CogView4 support added!
- 🔥 2025-03-03: Wan T2V support added!
- 🔥 2025-03-03: We have shipped a complete refactor to support multi-backend distributed training, better precomputation handling for big datasets, model specification format (externally usable for training custom models), FSDP & more.
- 🔥 2025-02-12: We have shipped a set of tooling to curate small and high-quality video datasets for fine-tuning. See video-dataset-scripts documentation page for details!
- 🔥 2025-02-12: Check out eisneim/ltx_lora_training_i2v_t2v! It builds off of
finetrainersto support image to video training for LTX-Video and STG guidance for inference. - 🔥 2025-01-15: Support for naive FP8 weight-casting training added! This allows training HunyuanVideo in under 24 GB upto specific resolutions.
- 🔥 2025-01-13: Support for T2V full-finetuning added! Thanks to @ArEnSc for taking up the initiative!
- 🔥 2025-01-03: Support for T2V LoRA finetuning of CogVideoX added!
- 🔥 2024-12-20: Support for T2V LoRA finetuning of Hunyuan Video added! We would like to thank @SHYuanBest for his work on a training script here.
- 🔥 2024-12-18: Support for T2V LoRA finetuning of LTX Video added!
[!NOTE] The following numbers were obtained from the release branch. The
mainbranch is unstable at the moment and may use higher memory.
| Model Name | Tasks | Min. LoRA VRAM* | Min. Full Finetuning VRAM^ |
|---|---|---|---|
| LTX-Video | Text-to-Video | 5 GB | 21 GB |
| HunyuanVideo | Text-to-Video | 32 GB | OOM |
| CogVideoX-5b | Text-to-Video | 18 GB | 53 GB |
| Wan | Text-to-Video | TODO | TODO |
| CogView4 | Text-to-Image | TODO | TODO |
*Noted for training-only, no validation, at resolution 49x512x768, rank 128, with pre-computation, using FP8 weights & gradient checkpointing. Pre-computation of conditions and latents may require higher limits (but typically under 16 GB).
^Noted for training-only, no validation, at resolution 49x512x768, with pre-computation, using BF16 weights & gradient checkpointing.
If you would like to use a custom dataset, refer to the dataset preparation guide here.
Checkout some amazing projects citing finetrainers:
- Diffusion as Shader
- SkyworkAI's SkyReels-A1
- eisneim's LTX Image-to-Video
- wileewang's TransPixar
- Feizc's Video-In-Context
Checkout the following UIs built for finetrainers:
-
finetrainersbuilds on top of & takes inspiration from great open-source libraries -transformers,accelerate,torchtune,torchtitan,peft,diffusers,bitsandbytes,torchaoanddeepspeed- to name a few. - Some of the design choices of
finetrainerswere inspired bySimpleTuner.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for finetrainers
Similar Open Source Tools
finetrainers
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.
keras-llm-robot
The Keras-llm-robot Web UI project is an open-source tool designed for offline deployment and testing of various open-source models from the Hugging Face website. It allows users to combine multiple models through configuration to achieve functionalities like multimodal, RAG, Agent, and more. The project consists of three main interfaces: chat interface for language models, configuration interface for loading models, and tools & agent interface for auxiliary models. Users can interact with the language model through text, voice, and image inputs, and the tool supports features like model loading, quantization, fine-tuning, role-playing, code interpretation, speech recognition, image recognition, network search engine, and function calling.
rag-chatbot
The RAG ChatBot project combines Lama.cpp, Chroma, and Streamlit to build a Conversation-aware Chatbot and a Retrieval-augmented generation (RAG) ChatBot. The RAG Chatbot works by taking a collection of Markdown files as input and provides answers based on the context provided by those files. It utilizes a Memory Builder component to load Markdown pages, divide them into sections, calculate embeddings, and save them in an embedding database. The chatbot retrieves relevant sections from the database, rewrites questions for optimal retrieval, and generates answers using a local language model. It also remembers previous interactions for more accurate responses. Various strategies are implemented to deal with context overflows, including creating and refining context, hierarchical summarization, and async hierarchical summarization.
EasyInstruct
EasyInstruct is a Python package proposed as an easy-to-use instruction processing framework for Large Language Models (LLMs) like GPT-4, LLaMA, ChatGLM in your research experiments. EasyInstruct modularizes instruction generation, selection, and prompting, while also considering their combination and interaction.
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.
open-unlearning
OpenUnlearning is an easily extensible framework that unifies LLM unlearning evaluation benchmarks. It provides efficient implementations of TOFU and MUSE unlearning benchmarks, supporting 5 unlearning methods, 3+ datasets, 6+ evaluation metrics, and 7+ LLMs. Users can easily extend the framework to incorporate more variants, collaborate by adding new benchmarks, unlearning methods, datasets, and evaluation metrics, and drive progress in the field.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
BIRD-CRITIC-1
BIRD-CRITIC 1.0 is a SQL benchmark designed to evaluate the capability of large language models (LLMs) in diagnosing and solving user issues within real-world database environments. It comprises 600 tasks for development and 200 held-out out-of-distribution tests across 4 prominent open-source SQL dialects. The benchmark expands beyond simple SELECT queries to cover a wider range of SQL operations, reflecting actual application scenarios. An optimized execution-based evaluation environment is included for rigorous and efficient validation.
all-rag-techniques
This repository provides a hands-on approach to Retrieval-Augmented Generation (RAG) techniques, simplifying advanced concepts into understandable implementations using Python libraries like openai, numpy, and matplotlib. It offers a collection of Jupyter Notebooks with concise explanations, step-by-step implementations, code examples, evaluations, and visualizations for various RAG techniques. The goal is to make RAG more accessible and demystify its workings for educational purposes.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.

OmAgent
OmAgent is an open-source agent framework designed to streamline the development of on-device multimodal agents. It enables agents to empower various hardware devices, integrates speed-optimized SOTA multimodal models, provides SOTA multimodal agent algorithms, and focuses on optimizing the end-to-end computing pipeline for real-time user interaction experience. Key features include easy connection to diverse devices, scalability, flexibility, and workflow orchestration. The architecture emphasizes graph-based workflow orchestration, native multimodality, and device-centricity, allowing developers to create bespoke intelligent agent programs.

AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.
For similar tasks
finetrainers
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.