Best AI tools for< Train Video Models >
20 - AI tool Sites
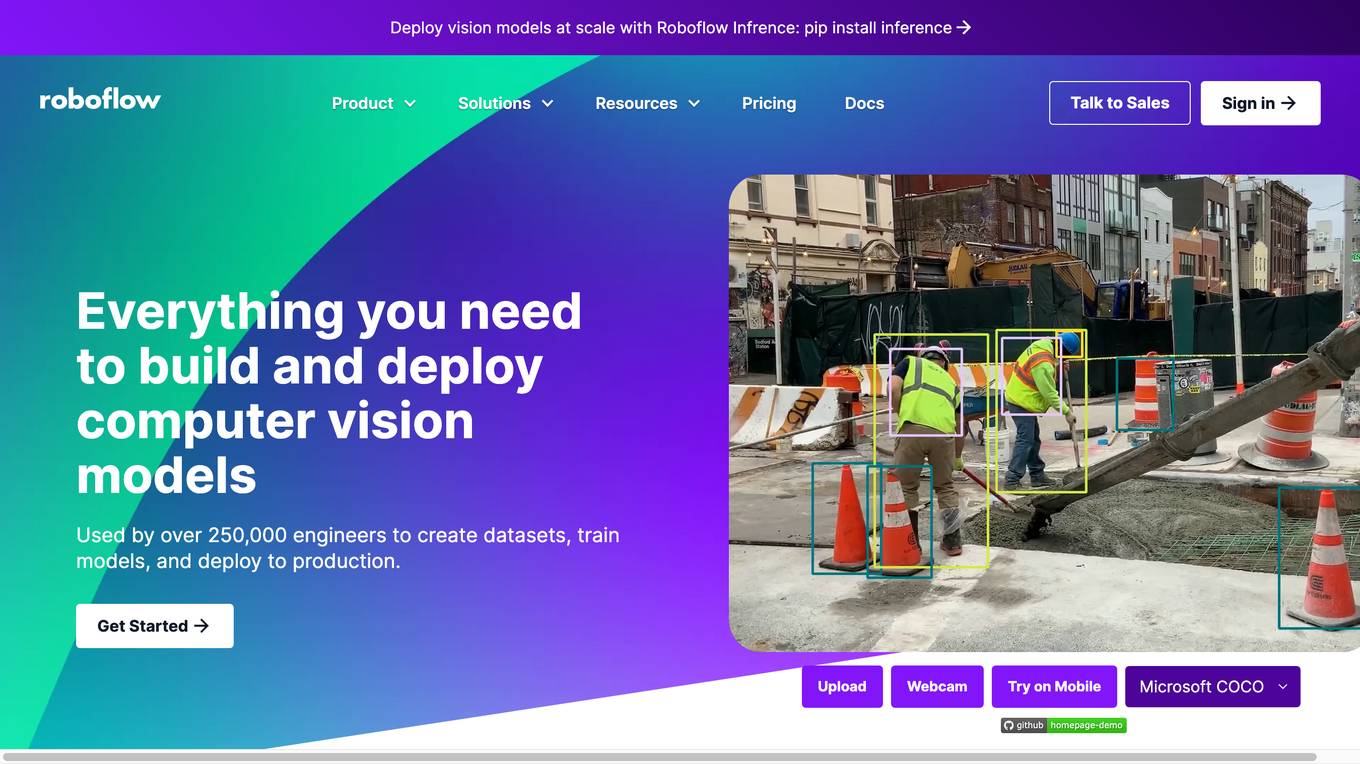
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
LoraAI
LoraAI is a cutting-edge AI platform that empowers creators to generate images, create videos, train custom AI styles, and edit with powerful tools. With a wide range of AI models and features, LoraAI provides everything needed for AI creation, catering to professionals and hobbyists alike. The platform offers fast and efficient processing, high-quality outputs, and user-friendly interfaces, making it a top choice for those looking to enhance their creative projects with AI technology.
Rupert AI
Rupert AI is an all-in-one AI platform that allows users to train custom AI models for text, audio, video, and images. The platform streamlines AI workflows by providing access to the latest open-source AI models and tools in a single studio tailored to business needs. Users can automate their AI workflow, generate high-quality AI product photography, and utilize popular AI workflows like the AI Fashion Model Generator and Facebook Ad Testing Tool. Rupert AI aims to revolutionize the way businesses leverage AI technology to enhance marketing visuals, streamline operations, and make informed decisions.
Globose Technology Solutions
Globose Technology Solutions Pvt Ltd (GTS) is an AI data collection company that provides various datasets such as image datasets, video datasets, text datasets, speech datasets, etc., to train machine learning models. They offer premium data collection services with a human touch, aiming to refine AI vision and propel AI forward. With over 25+ years of experience, they specialize in data management, annotation, and effective data collection techniques for AI/ML. The company focuses on unlocking high-quality data, understanding AI's transformative impact, and ensuring data accuracy as the backbone of reliable AI.

Tavus
Tavus is an AI tool that offers digital twin APIs for video generation and conversational video interfaces. It provides developers with cutting-edge AI technology to create immersive video experiences using AI-generated digital twins. Tavus' Phoenix model enables the generation of realistic digital replicas with natural face movements and expressions. The platform also supports rapid training, instant inference, and multi-language capabilities. With a developer-first approach, Tavus focuses on security, trust, and user experience, offering features like dubbing APIs and automated content moderation. The tool is praised for its speed of development cycles, high-quality AI video, and exceptional customer service.
DeepfakeVFX.com
DeepfakeVFX.com is an AI tool designed for the deepfake community, providing forums, guides, tutorials, and downloads for users interested in creating deepfake videos. The platform offers comprehensive resources for learning how to deepfake, including step-by-step tutorials and pretrained models. Users can engage in discussions, share knowledge, and access a variety of tools and settings to enhance their deepfake creations.
Cartesia Sonic Team Blog Research Playground
Cartesia Sonic Team Blog Research Playground is an AI application that offers real-time multimodal intelligence for every device. The application aims to build the next generation of AI by providing ubiquitous, interactive intelligence that can run on any device. It features the fastest, ultra-realistic generative voice API and is backed by research on simple linear attention language models and state-space models. The founding team, who met at the Stanford AI Lab, has invented State Space Models (SSMs) and scaled it up to achieve state-of-the-art results in various modalities such as text, audio, video, images, and time-series data.
Stablematic
Stablematic is a web-based platform that allows users to run Stable Diffusion and other machine learning models without the need for local setup or hardware limitations. It provides a user-friendly interface, pre-installed plugins, and dedicated GPU resources for a seamless and efficient workflow. Users can generate images and videos from text prompts, merge multiple models, train custom models, and access a range of pre-trained models, including Dreambooth and CivitAi models. Stablematic also offers API access for developers and dedicated support for users to explore and utilize the capabilities of Stable Diffusion and other machine learning models.

Genice
Genice is an online face swap tool that allows users to effortlessly swap faces in videos or images. With its advanced technology, Genice can generate realistic results by incorporating multiple face images, delivering superior quality compared to the method of using just a single face image. Users can train their custom model with just about 10 images and endlessly generate their dream photos or videos. Genice also offers a variety of features such as changing faces in any video or image effortlessly, generating images through style selection, and providing free credits to new sign-up users.

Runway
Runway is a platform that provides tools and resources for artists and researchers to create and explore artificial intelligence-powered creative applications. The platform includes a library of pre-trained models, a set of tools for building and training custom models, and a community of users who share their work and collaborate on projects. Runway's mission is to make AI more accessible and understandable, and to empower artists and researchers to create new and innovative forms of creative expression.
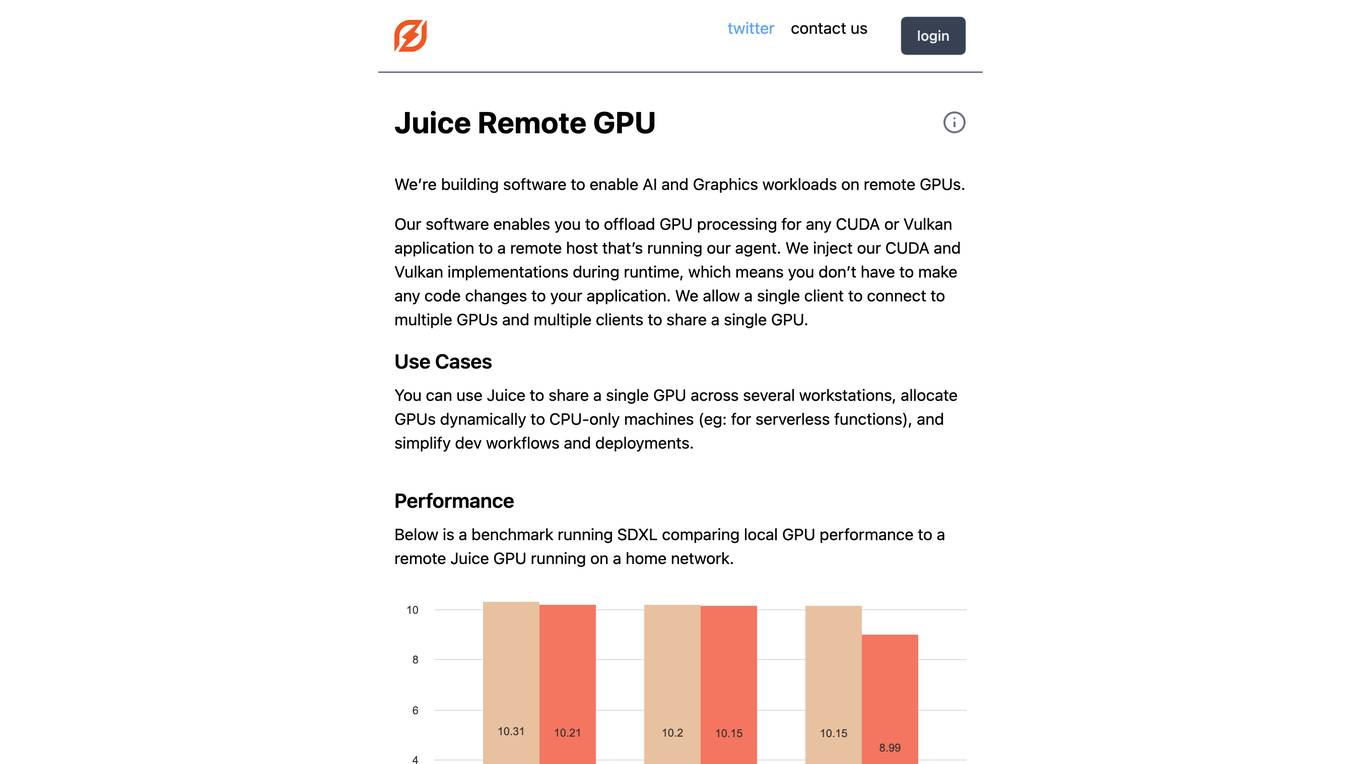
Juice Remote GPU
Juice Remote GPU is a software that enables AI and Graphics workloads on remote GPUs. It allows users to offload GPU processing for any CUDA or Vulkan application to a remote host running the Juice agent. The software injects CUDA and Vulkan implementations during runtime, eliminating the need for code changes in the application. Juice supports multiple clients connecting to multiple GPUs and multiple clients sharing a single GPU. It is useful for sharing a single GPU across multiple workstations, allocating GPUs dynamically to CPU-only machines, and simplifying development workflows and deployments. Juice Remote GPU performs within 5% of a local GPU when running in the same datacenter. It supports various APIs, including CUDA, Vulkan, DirectX, and OpenGL, and is compatible with PyTorch and TensorFlow. The team behind Juice Remote GPU consists of engineers from Meta, Intel, and the gaming industry.

Neural Frames
Neural Frames is an AI-powered video animation generator that allows users to create videos from text prompts. It is designed to be easy to use, even for those with no prior experience in video editing. Neural Frames offers a variety of features, including the ability to create videos in any style, control the camera, and add music. It is also possible to train custom AI models to achieve specific styles or character consistency.
V7
V7 is an AI data engine for computer vision and generative AI. It provides a multimodal automation tool that helps users label data 10x faster, power AI products via API, build AI + human workflows, and reach 99% AI accuracy. V7's platform includes features such as automated annotation, DICOM annotation, dataset management, model management, image annotation, video annotation, document processing, and labeling services.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.
Liner.ai
Liner is a free and easy-to-use tool that allows users to train machine learning models without writing any code. It provides a user-friendly interface that guides users through the process of importing data, selecting a model, and training the model. Liner also offers a variety of pre-trained models that can be used for common tasks such as image classification, text classification, and object detection. With Liner, users can quickly and easily create and deploy machine learning applications without the need for specialized knowledge or expertise.
Synthesis AI
Synthesis AI is a synthetic data platform that enables more capable and ethical computer vision AI. It provides on-demand labeled images and videos, photorealistic images, and 3D generative AI to help developers build better models faster. Synthesis AI's products include Synthesis Humans, which allows users to create detailed images and videos of digital humans with rich annotations; Synthesis Scenarios, which enables users to craft complex multi-human simulations across a variety of environments; and a range of applications for industries such as ID verification, automotive, avatar creation, virtual fashion, AI fitness, teleconferencing, visual effects, and security.
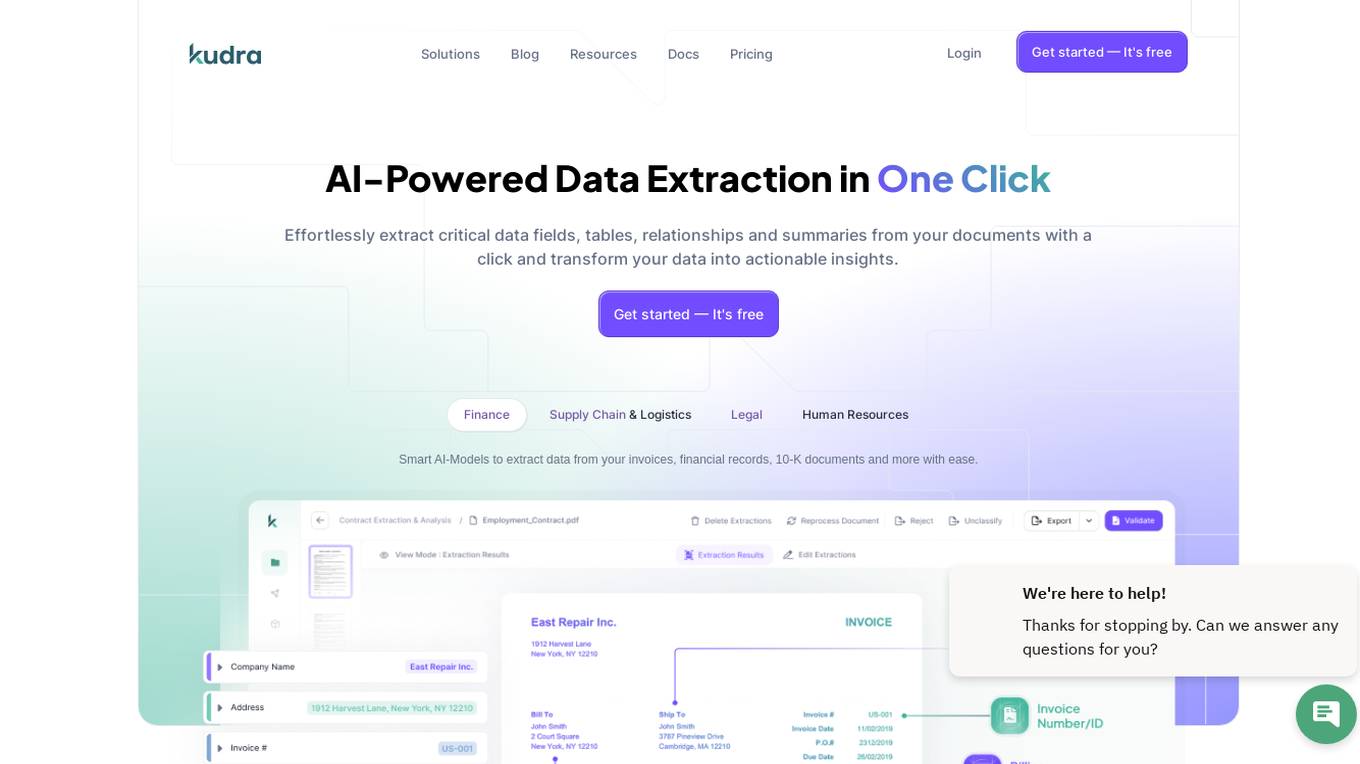
Kudra
Kudra is an AI-powered data extraction tool that offers dedicated solutions for finance, human resources, logistics, legal, and more. It effortlessly extracts critical data fields, tables, relationships, and summaries from various documents, transforming unstructured data into actionable insights. Kudra provides customizable AI models, seamless integrations, and secure document processing while supporting over 20 languages. With features like custom workflows, model training, API integration, and workflow builder, Kudra aims to streamline document processing for businesses of all sizes.
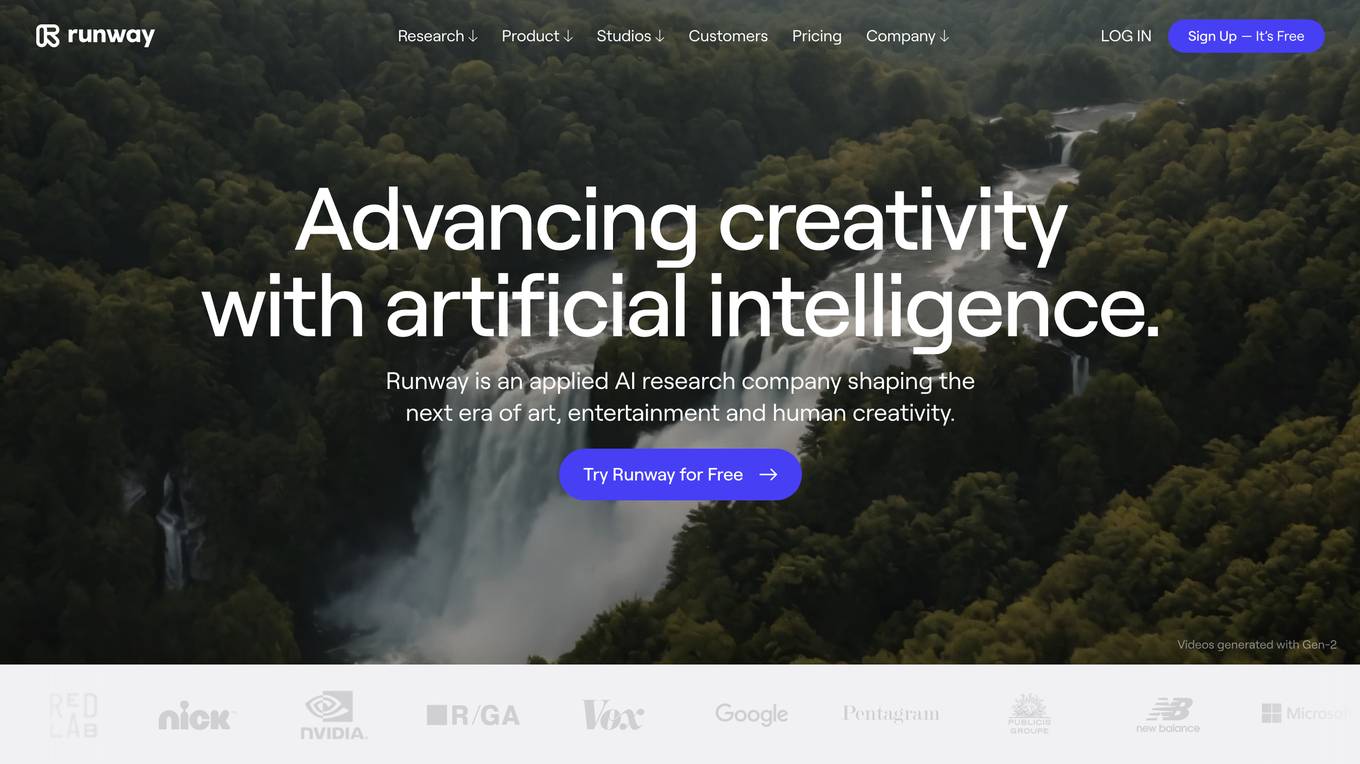
Runway
Runway is an applied AI research company shaping the next era of art, entertainment, and human creativity. With a suite of creative tools designed to turn ideas into reality, Runway empowers users to explore the possibilities of AI-generated worlds. Founded in 2018, Runway has been pushing creativity forward with cutting-edge research in artificial intelligence and machine learning, collaborating with leading institutes worldwide.
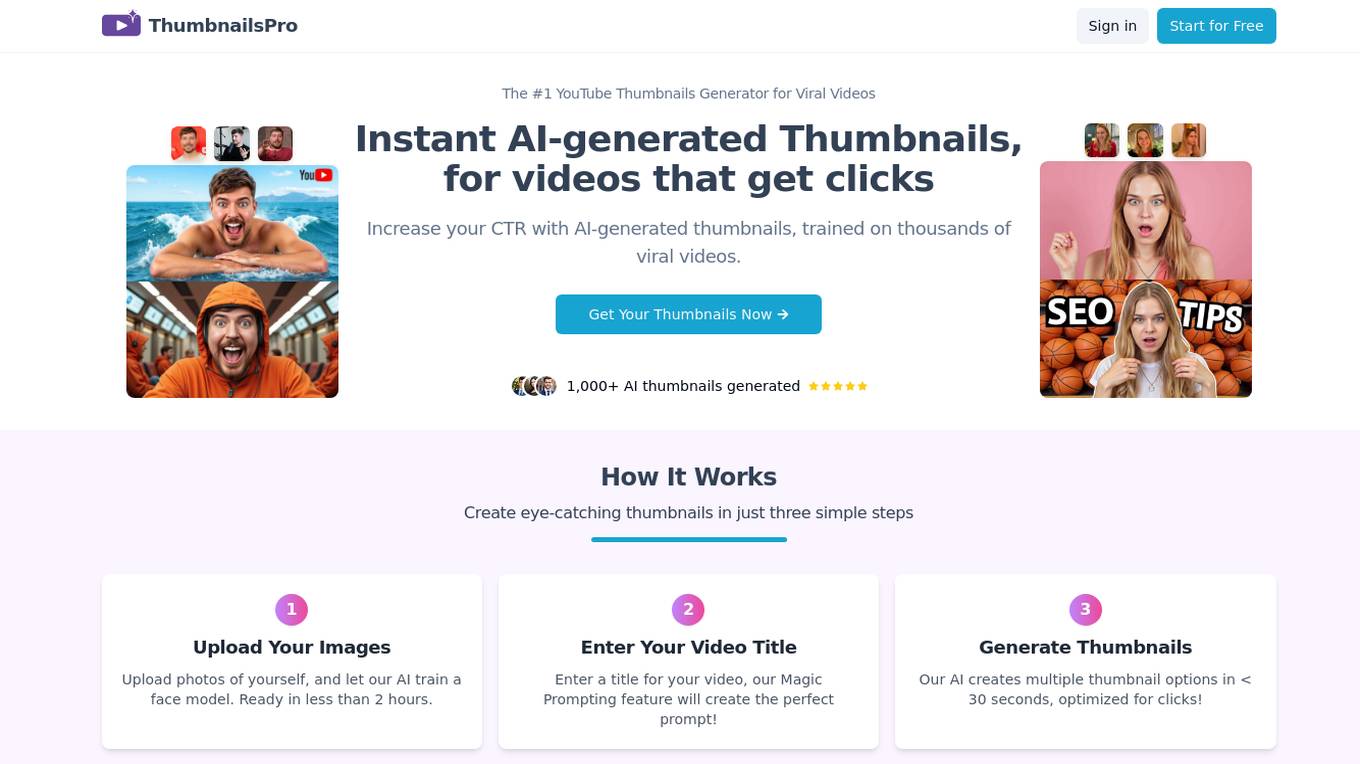
ThumbnailsPro
ThumbnailsPro is the #1 YouTube Thumbnails Generator for Viral Videos, offering instant AI-generated thumbnails to increase click-through rates. The AI is trained on thousands of viral videos to ensure optimized thumbnail creation. Users can upload images, enter video titles, and generate multiple thumbnail options in under 30 seconds. With affordable subscription plans, full ownership rights, and a user-friendly interface, ThumbnailsPro is designed for YouTube success.

Stanford Artificial Intelligence Laboratory
The Stanford Artificial Intelligence Laboratory (SAIL) is a center of excellence for Artificial Intelligence research, teaching, theory, and practice since its founding in 1963. SAIL faculty and students are committed to developing the theoretical foundations of AI, advancing the state-of-the-art in AI technologies, and applying AI to address real-world problems. SAIL is a vibrant and collaborative community of researchers, students, and staff who are passionate about AI and its potential to make the world a better place.
2 - Open Source AI Tools
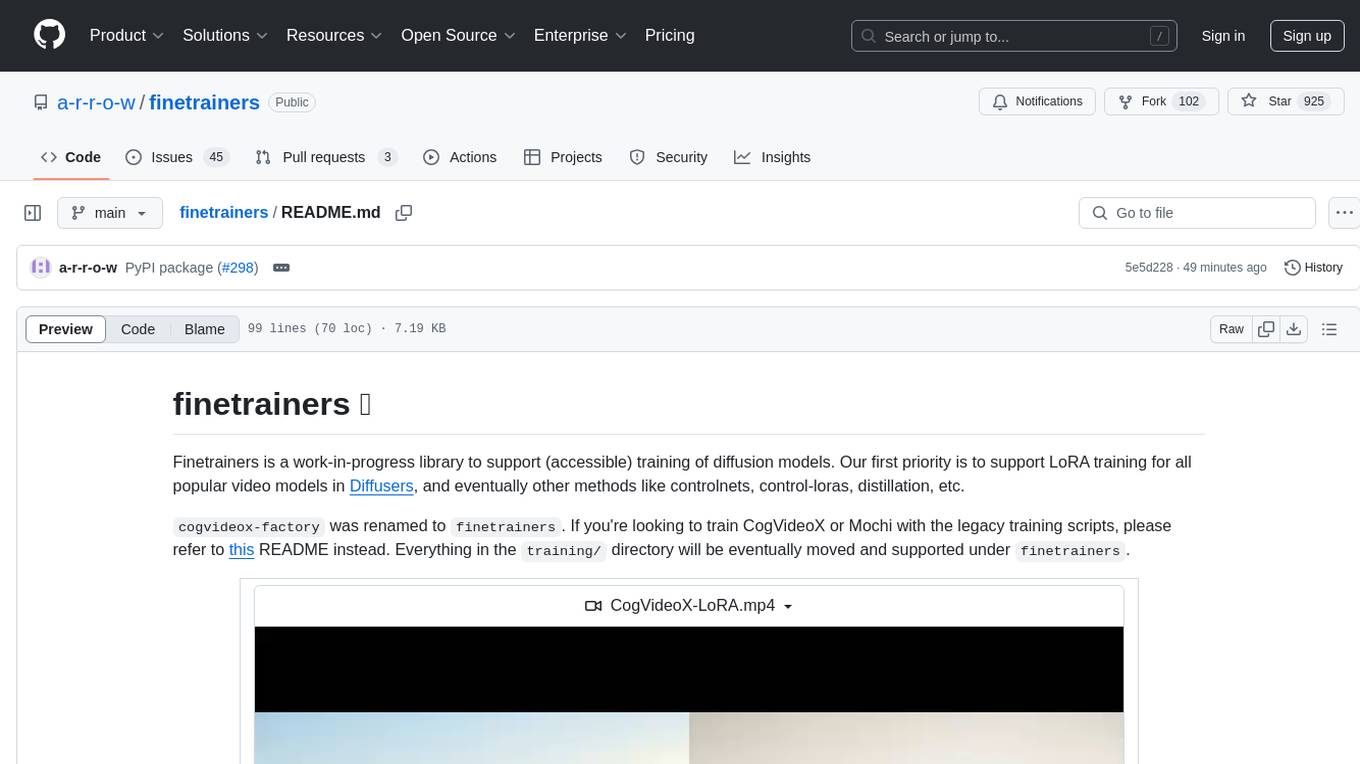
finetrainers
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.
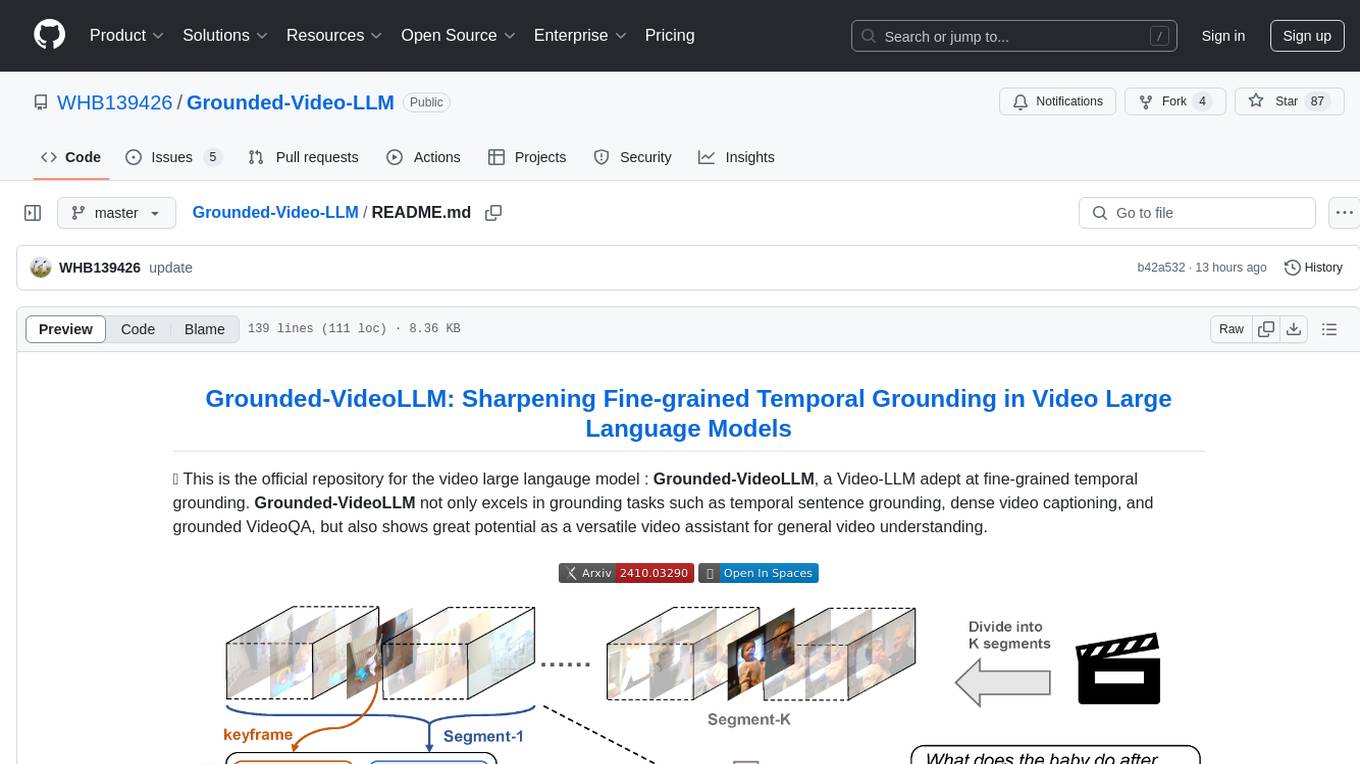
Grounded-Video-LLM
Grounded-VideoLLM is a Video Large Language Model specialized in fine-grained temporal grounding. It excels in tasks such as temporal sentence grounding, dense video captioning, and grounded VideoQA. The model incorporates an additional temporal stream, discrete temporal tokens with specific time knowledge, and a multi-stage training scheme. It shows potential as a versatile video assistant for general video understanding. The repository provides pretrained weights, inference scripts, and datasets for training. Users can run inference queries to get temporal information from videos and train the model from scratch.
20 - OpenAI Gpts
How to Train a Chessie
Comprehensive training and wellness guide for Chesapeake Bay Retrievers.
The Train Traveler
Friendly train travel guide focusing on the best routes, essential travel information, and personalized travel insights, for both experienced and novice travelers.
How to Train Your Dog (or Cat, or Dragon, or...)
Expert in pet training advice, friendly and engaging.
TrainTalk
Your personal advisor for eco-friendly train travel. Let's plan your next journey together!
Monster Battle - RPG Game
Train monsters, travel the world, earn Arena Tokens and become the ultimate monster battling champion of earth!
Hero Master AI: Superhero Training
Train to become a superhero or a supervillain. Master your powers, make pivotal choices. Each decision you make in this action-packed game not only shapes your abilities but also your moral alignment in the battle between good and evil. Another GPT Simulator by Dave Lalande

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch

Design Recruiter
Job interview coach for product designers. Train interviews and say stop when you need a feedback. You got this!!
Pocket Training Activity Expert
Expert in engaging, interactive training methods and activities.

RailwayGPT
Technical expert on locomotives, trains, signalling, and railway technology. Can answer questions and draw designs specific to transportation domain.