
AgentLab
AgentLab: An open-source framework for developing, testing, and benchmarking web agents on diverse tasks, designed for scalability and reproducibility.
Stars: 239

AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.
README:



![]()
![]()
🛠️ Setup |
🤖 Assistant |
🚀 Launch Experiments |
🔍 Analyse Results |
🏆 Leaderboard |
🤖 Build Your Agent |
↻ Reproducibility |
💪 BrowserGym
[!WARNING] AgentLab is meant to provide an open, easy-to-use and extensible framework to accelerate the field of web agent research. It is not meant to be a consumer product. Use with caution!
AgentLab is a framework for developing and evaluating agents on a variety of benchmarks supported by BrowserGym. It is presented in more details in our BrowserGym ecosystem paper
AgentLab Features:
- Easy large scale parallel agent experiments using ray
- Building blocks for making agents over BrowserGym
- Unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI.
- Preferred way for running benchmarks like WebArena
- Various reproducibility features
- Unified LeaderBoard
| Benchmark | Setup Link |
# Task Template |
Seed Diversity |
Max Step |
Multi-tab | Hosted Method | BrowserGym Leaderboard |
|---|---|---|---|---|---|---|---|
| WebArena | setup | 812 | None | 30 | yes | self hosted (docker) | soon |
| WorkArena L1 | setup | 33 | High | 30 | no | demo instance | soon |
| WorkArena L2 | setup | 341 | High | 50 | no | demo instance | soon |
| WorkArena L3 | setup | 341 | High | 50 | no | demo instance | soon |
| WebLinx | - | 31586 | None | 1 | no | self hosted (dataset) | soon |
| VisualWebArena | setup | 910 | None | 30 | yes | self hosted (docker) | soon |
| AssistantBench | setup | 214 | None | 30 | yes | live web | soon |
| GAIA (soon) | - | - | None | - | - | live web | soon |
| Mind2Web-live (soon) | - | - | None | - | - | live web | soon |
| MiniWoB | setup | 125 | Medium | 10 | no | self hosted (static files) | soon |
AgentLab requires python 3.11 or 3.12.
pip install agentlabIf not done already, install Playwright:
playwright installMake sure to prepare the required benchmark according to the instructions provided in the setup column.
export AGENTLAB_EXP_ROOT=<root directory of experiment results> # defaults to $HOME/agentlab_results
export OPENAI_API_KEY=<your openai api key> # if openai models are usedSetup OpenRouter API
export OPENROUTER_API_KEY=<your openrouter api key> # if openrouter models are usedSetup Azure API
export AZURE_OPENAI_API_KEY=<your azure api key> # if using azure models
export AZURE_OPENAI_ENDPOINT=<your endpoint> # if using azure modelsUse an assistant to work for you (at your own cost and risk).
agentlab-assistant --start_url https://www.google.comTry your own agent:
agentlab-assistant --agent_config="module.path.to.your.AgentArgs"# Import your agent configuration extending bgym.AgentArgs class
# Make sure this object is imported from a module accessible in PYTHONPATH to properly unpickle
from agentlab.agents.generic_agent import AGENT_4o_MINI
from agentlab.experiments.study import make_study
study = make_study(
benchmark="miniwob", # or "webarena", "workarena_l1" ...
agent_args=[AGENT_4o_MINI],
comment="My first study",
)
study.run(n_jobs=5)Relaunching incomplete or errored tasks
from agentlab.experiments.study import Study
study = Study.load("/path/to/your/study/dir")
study.find_incomplete(include_errors=True)
study.run()See main.py to launch experiments with a variety of options. This is like a lazy CLI that is actually more convenient. Just comment and uncomment the lines you need or modify at will (but don't push to the repo).
The complexity of the wild web, Playwright, and asyncio can sometimes cause jobs to hang. This disables workers until the study is terminated and relaunched. If you are running jobs sequentially or with a small number of workers, this could halt your entire study until you manually kill and relaunch it. In the Ray parallel backend, we've implemented a system to automatically terminate jobs exceeding a specified timeout. This feature is particularly useful when task hanging limits your experiments.
For debugging, run experiments with n_jobs=1 and use VSCode's debug mode. This allows you to pause
execution at breakpoints.
Running one agent on one task corresponds to a single job. Conducting ablation studies or random searches across hundreds of tasks with multiple seeds can generate more than 10,000 jobs. Efficient parallel execution is therefore critical. Agents typically wait for responses from the LLM server or updates from the web server. As a result, you can run 10–50 jobs in parallel on a single computer, depending on available RAM.
make_study function returns a SequentialStudies object to ensure proper sequential evaluation of
each agent. AgentLab currently does not support evaluations across multiple instances, but you could
either create a quick script to handle this or submit a PR to AgentLab. For a smoother parallel
experience, consider using benchmarks like WorkArena instead.
The class ExpResult provides a lazy loader for all the information of a specific experiment. You can use yield_all_exp_results to recursively find all results in a directory. Finally load_result_df gathers all the summary information in a single dataframe. See inspect_results.ipynb for example usage.
from agentlab.analyze import inspect_results
# load the summary of all experiments of the study in a dataframe
result_df = inspect_results.load_result_df("path/to/your/study")
# load the detailed results of the 1st experiment
exp_result = bgym.ExpResult(result_df["exp_dir"][0])
step_0_screenshot = exp_result.screenshots[0]
step_0_action = exp_result.steps_info[0].actionhttps://github.com/user-attachments/assets/06c4dac0-b78f-45b7-9405-003da4af6b37
In a terminal, execute:
agentlab-xrayYou can load previous or ongoing experiments in the directory AGENTLAB_EXP_ROOT and visualize
the results in a gradio interface.
In the following order, select:
- The experiment you want to visualize
- The agent if there is more than one
- The task
- And the seed
Once this is selected, you can see the trace of your agent on the given task. Click on the profiling image to select a step and observe the action taken by the agent.
Official unified leaderboard across all benchmarks.
Experiments are on their way for more reference points using GenericAgent. We are also working on code to automatically push a study to the leaderboard.
Get inspiration from the MostBasicAgent in
agentlab/agents/most_basic_agent/most_basic_agent.py.
For a better integration with the tools, make sure to implement most functions in the
AgentArgs API and the extended bgym.AbstractAgentArgs.
If you think your agent should be included directly in AgenLab, let us know and it can be added in agentlab/agents/ with the name of your agent.
Several factors can influence reproducibility of results in the context of evaluating agents on dynamic benchmarks.
- Software version: Different versions of Playwright or any package in the software stack could influence the behavior of the benchmark or the agent.
- API-based LLMs silently changing: Even for a fixed version, an LLM may be updated e.g. to incorporate the latest web knowledge.
-
Live websites:
- WorkArena: The demo instance is mostly fixed in time to a specific version but ServiceNow sometimes pushes minor modifications.
- AssistantBench and GAIA: These rely on the agent navigating the open web. The experience may change depending on which country or region, some websites might be in different languages by default.
- Stochastic Agents: Setting the temperature of the LLM to 0 can reduce most stochasticity.
- Non-deterministic tasks: For a fixed seed, the changes should be minimal
-
Studycontains a dict of information about reproducibility, including benchmark version, package version and commit hash - The
Studyclass allows automatic upload of your results toreproducibility_journal.csv. This makes it easier to populate a large amount of reference points. For this feature, you need togit clonethe repository and install viapip install -e .. - Reproduced results in the leaderboard. For agents that are reprocudibile, we encourage users to try to reproduce the results and upload them to the leaderboard. There is a special column containing information about all reproduced results of an agent on a benchmark.
- ReproducibilityAgent: You can run this agent on an existing study and it will try to re-run the same actions on the same task seeds. A visual diff of the two prompts will be displayed in the AgentInfo HTML tab of AgentXray. You will be able to inspect on some tasks what kind of changes between the two executions. Note: this is a beta feature and will need some adaptation for your own agent.
if you want to download HF models more quickly
pip install hf-transfer
pip install torch
export HF_HUB_ENABLE_HF_TRANSFER=1
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AgentLab
Similar Open Source Tools
AgentLab
AgentLab is an open, easy-to-use, and extensible framework designed to accelerate web agent research. It provides features for developing and evaluating agents on various benchmarks supported by BrowserGym. The framework allows for large-scale parallel agent experiments using ray, building blocks for creating agents over BrowserGym, and a unified LLM API for OpenRouter, OpenAI, Azure, or self-hosted using TGI. AgentLab also offers reproducibility features, a unified LeaderBoard, and supports multiple benchmarks like WebArena, WorkArena, WebLinx, VisualWebArena, AssistantBench, GAIA, Mind2Web-live, and MiniWoB.
PostTrainBench
PostTrainBench is a benchmark designed to measure the ability of command-line interface (CLI) agents to post-train pre-trained large language models (LLMs). The agents are tasked with improving the performance of a base LLM on a given benchmark using an evaluation script and 10 hours on an H100 GPU. The benchmark scores are computed after post-training, and the setup evaluates an agent's capability to conduct AI research and development. The repository provides a platform for collaborative contributions to expand tasks and agent scaffolds, with the potential for co-authorship on research papers.

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
swt-bench
SWT-Bench is a benchmark tool for evaluating large language models on testing generation for real world software issues collected from GitHub. It tasks a language model with generating a reproducing test that fails in the original state of the code base and passes after a patch resolving the issue has been applied. The tool operates in unit test mode or reproduction script mode to assess model predictions and success rates. Users can run evaluations on SWT-Bench Lite using the evaluation harness with specific commands. The tool provides instructions for setting up and building SWT-Bench, as well as guidelines for contributing to the project. It also offers datasets and evaluation results for public access and provides a citation for referencing the work.

AgentBench
AgentBench is a benchmark designed to evaluate Large Language Models (LLMs) as autonomous agents in various environments. It includes 8 distinct environments such as Operating System, Database, Knowledge Graph, Digital Card Game, and Lateral Thinking Puzzles. The tool provides a comprehensive evaluation of LLMs' ability to operate as agents by offering Dev and Test sets for each environment. Users can quickly start using the tool by following the provided steps, configuring the agent, starting task servers, and assigning tasks. AgentBench aims to bridge the gap between LLMs' proficiency as agents and their practical usability.

weblinx
WebLINX is a Python library and dataset for real-world website navigation with multi-turn dialogue. The repository provides code for training models reported in the WebLINX paper, along with a comprehensive API to work with the dataset. It includes modules for data processing, model evaluation, and utility functions. The modeling directory contains code for processing, training, and evaluating models such as DMR, LLaMA, MindAct, Pix2Act, and Flan-T5. Users can install specific dependencies for HTML processing, video processing, model evaluation, and library development. The evaluation module provides metrics and functions for evaluating models, with ongoing work to improve documentation and functionality.

maxtext
MaxText is a high-performance, highly scalable, open-source LLM written in pure Python/Jax and targeting Google Cloud TPUs and GPUs for training and inference. MaxText achieves high MFUs and scales from single host to very large clusters while staying simple and "optimization-free" thanks to the power of Jax and the XLA compiler. MaxText aims to be a launching off point for ambitious LLM projects both in research and production. We encourage users to start by experimenting with MaxText out of the box and then fork and modify MaxText to meet their needs.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.
ProactiveAgent
Proactive Agent is a project aimed at constructing a fully active agent that can anticipate user's requirements and offer assistance without explicit requests. It includes a data collection and generation pipeline, automatic evaluator, and training agent. The project provides datasets, evaluation scripts, and prompts to finetune LLM for proactive agent. Features include environment sensing, assistance annotation, dynamic data generation, and construction pipeline with a high F1 score on the test set. The project is intended for coding, writing, and daily life scenarios, distributed under Apache License 2.0.
giskard-oss
Giskard-oss is an Evaluation & Testing framework for AI systems that aims to control risks of performance, bias, and security issues. It focuses on LLM systems, with plans for a new scan and a rewrite of RAGET for version 3. The repository is structured as a Python workspace with three packages: giskard-core, giskard-checks, and giskard-agents. Developers can use the Makefile for common tasks, and contributions from the AI community are welcome. The project encourages stars for visibility and offers sponsorship options for support.

exllamav2
ExLlamaV2 is an inference library designed for running local LLMs on modern consumer GPUs. The library supports paged attention via Flash Attention 2.5.7+, offers a new dynamic generator with features like dynamic batching, smart prompt caching, and K/V cache deduplication. It also provides an API for local or remote inference using TabbyAPI, with extended features like HF model downloading and support for HF Jinja2 chat templates. ExLlamaV2 aims to optimize performance and speed across different GPU models, with potential future optimizations and variations in speeds. The tool can be integrated with TabbyAPI for OpenAI-style web API compatibility and supports a standalone web UI called ExUI for single-user interaction with chat and notebook modes. ExLlamaV2 also offers support for text-generation-webui and lollms-webui through specific loaders and bindings.

exllamav2
ExLlamaV2 is an inference library for running local LLMs on modern consumer GPUs. It is a faster, better, and more versatile codebase than its predecessor, ExLlamaV1, with support for a new quant format called EXL2. EXL2 is based on the same optimization method as GPTQ and supports 2, 3, 4, 5, 6, and 8-bit quantization. It allows for mixing quantization levels within a model to achieve any average bitrate between 2 and 8 bits per weight. ExLlamaV2 can be installed from source, from a release with prebuilt extension, or from PyPI. It supports integration with TabbyAPI, ExUI, text-generation-webui, and lollms-webui. Key features of ExLlamaV2 include: - Faster and better kernels - Cleaner and more versatile codebase - Support for EXL2 quantization format - Integration with various web UIs and APIs - Community support on Discord
ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.

NineRec
NineRec is a benchmark dataset suite for evaluating transferable recommendation models. It provides datasets for pre-training and transfer learning in recommender systems, focusing on multimodal and foundation model tasks. The dataset includes user-item interactions, item texts in multiple languages, item URLs, and raw images. Researchers can use NineRec to develop more effective and efficient methods for pre-training recommendation models beyond end-to-end training. The dataset is accompanied by code for dataset preparation, training, and testing in PyTorch environment.

torchtune
Torchtune is a PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. It provides native-PyTorch implementations of popular LLMs using composable and modular building blocks, easy-to-use and hackable training recipes for popular fine-tuning techniques, YAML configs for easily configuring training, evaluation, quantization, or inference recipes, and built-in support for many popular dataset formats and prompt templates to help you quickly get started with training.
For similar tasks

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
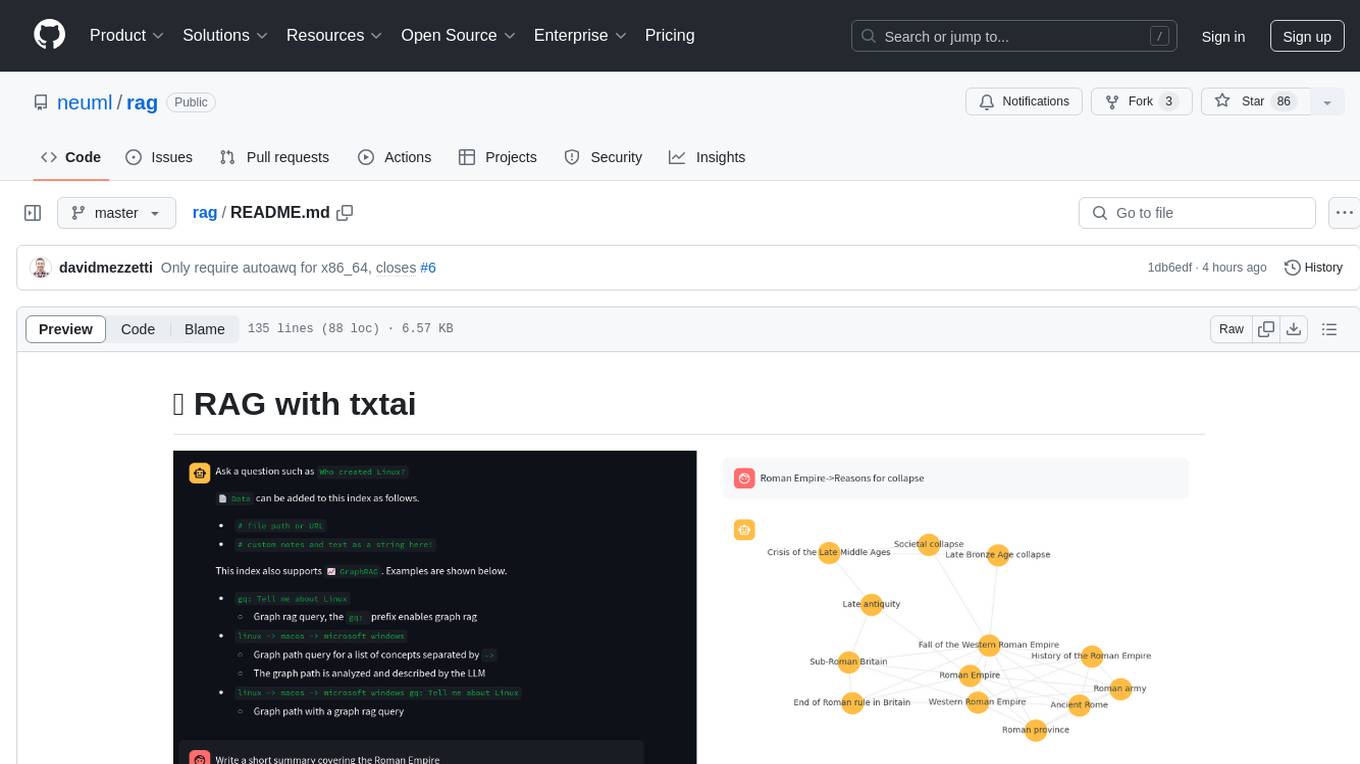
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.