
joplin-plugin-jarvis
Joplin (note-taking) assistant running a very intelligent system (GPT, Claude, Gemini, Ollama, Hugging Face)
Stars: 303
Jarvis is an AI note-taking assistant for Joplin, powered by online and offline LLMs (such as OpenAI's ChatGPT or GPT-4, Hugging Face, Google PaLM, Universal Sentence Encoder). You can chat with it (including prompt templates), use your personal notes as additional context in the chat, automatically annotate notes, perform semantic search, or compile an automatic review of the scientific literature.
README:
![]()
Jarvis (Joplin Assistant Running a Very Intelligent System) is an AI note-taking assistant for Joplin, powered by online and offline LLMs (such as OpenAI's ChatGPT or GPT-4, Hugging Face, Gemini, Universal Sentence Encoder). You can chat with it (including prompt templates), use your personal notes as additional context in the chat, automatically annotate notes, perform semantic search, or compile an automatic review of the scientific literature.
Community discussion: https://discourse.joplinapp.org/t/28316

-
Chat:
- Start a new note, or continue an existing conversation in a saved note. Place the cursor after your prompt and run the command
Chat with Jarvis(from the toolbar or Tools/Jarvis menu). Each time you run the command Jarvis will append its response to the note at the current cursor position (given the previous content that both of you created).
- Start a new note, or continue an existing conversation in a saved note. Place the cursor after your prompt and run the command
-
Chat with your notes:
- To add additional context to your conversation based on your notes, repeat the steps above but select the command
Chat with your notes(from the Tools/Jarvis menu) instead. Relevant short excerpts from your notes will be sent to the chat model in addition to the usual conversation prompt / context. To exclude certain notes from this feature, add the tag#exclude.from.jarvisto the notes you wish to exclude. You may combine regular chat and note-based chat on the same note. For more information see this guide.
- To add additional context to your conversation based on your notes, repeat the steps above but select the command
-
Related notes / semantic search:
- Find notes based on semantic similarity to the currently open note, to selected text, or to search queries. By default, this is done locally (offline), without sending the content of your notes to a remote server (online models can be selected). Notes are displayed in a dedicated panel. To run semantic search based on selected text, click on the
Find related notestoolbar button or context menu option. You may also write any query in the panel's search box.
- Find notes based on semantic similarity to the currently open note, to selected text, or to search queries. By default, this is done locally (offline), without sending the content of your notes to a remote server (online models can be selected). Notes are displayed in a dedicated panel. To run semantic search based on selected text, click on the
-
Annotate your notes:
- Run the command
Annotate note with Jarvisto add annotations to your notes: title, summary, links and / or tags. For more information see this guide.
- Run the command
-
Literature review:
- Run the command
Research with Jarvis, write what you're interested in, and optionally adjust the search parameters. Wait 2-3 minutes for all the output to appear in the note (depending on internet traffic). Jarvis will update the content as it finds new information on the web (using Semantic Scholar, Crossref, Elsevier, Springer & Wikipedia databases). In the end you will get a report with the following sections: title, prompt, research questions, queries, references, review and follow-up questions. For more information see this post.
- Run the command
-
Autocomplete anything:
-
Auto-complete with Jarviswill try to extend any text at the current cursor position in the editor.
-
-
Text generation:
- Run the command
Ask Jarvisand write your query in the pop-up window, or select a prompt text in the editor before running the command. You can also enhance your query with predefined (or customized) prompt templates from the dropdown lists.
- Run the command
-
Text editing:
- Select a text to edit, run the command
Edit selection with Jarvisand write your instructions in the pop-up window.
- Select a text to edit, run the command
- Install Jarvis from Joplin's plugin marketplace, or download it from github.
- Select a model for chatting with Jarvis, and a model for indexing your notes. Depending on your choice of models to connect Jarvis with, you may need to setup an API key in the plugin settings for OpenAI, Google AI, Hugging Face, or other supported services.
- To improve chat coherence, it may be helpful to increase
Memory tokensin the settings, especially when chatting with your notes. - For literature reviews, you can optionally add free API keys for Scopus/Elsevier as an additional powerful search engine and paper repository, and Springer as another paper repository. It is recommended to try both Scopus and Semantic Scholar as each has its pros and cons.
- This plugin sends your queries to your selected models (and only to these ones, whether they are online or offline models). See the table below for details.
- Research queries are also sent to the selected literature search engine (Semantic Scholar / Scopus).
- This plugin may use your OpenAI, Google AI or Hugging Face API key in order to do so (and use it for this sole purpose).
- You may incur charges (if you are a paying user) from these services by using this plugin.
- Therefore, it is recommended to check your usage statistics periodically.
- It is also recommended to rotate your API keys occasionally.
- The developer is not affiliated with any of the services above.
The following table shows what is sent to the selected chat / notes models when running each command.
| Command | User prompt | Current note | Other note excerpts | All notes | Web articles | Models |
|---|---|---|---|---|---|---|
| Ask Jarvis | x | chat | ||||
| Chat | x | x | chat | |||
| Chat w/ notes | x | x | x | chat, notes | ||
| Research | x | x | chat | |||
| Edit | x | chat | ||||
| Autocomplete | x | chat | ||||
| Annotate note | x | x | chat, notes | |||
| Find related notes | x | notes | ||||
| Update note DB | x | notes |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for joplin-plugin-jarvis
Similar Open Source Tools
joplin-plugin-jarvis
Jarvis is an AI note-taking assistant for Joplin, powered by online and offline LLMs (such as OpenAI's ChatGPT or GPT-4, Hugging Face, Google PaLM, Universal Sentence Encoder). You can chat with it (including prompt templates), use your personal notes as additional context in the chat, automatically annotate notes, perform semantic search, or compile an automatic review of the scientific literature.
raycast-g4f
Raycast-G4F is a free extension that allows users to leverage powerful AI models such as GPT-4 and Llama-3 within the Raycast app without the need for an API key. The extension offers features like streaming support, diverse commands, chat interaction with AI, web search capabilities, file upload functionality, image generation, and custom AI commands. Users can easily install the extension from the source code and benefit from frequent updates and a user-friendly interface. Raycast-G4F supports various providers and models, each with different capabilities and performance ratings, ensuring a versatile AI experience for users.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.
llm-python
A set of instructional materials, code samples and Python scripts featuring LLMs (GPT etc) through interfaces like llamaindex, langchain, Chroma (Chromadb), Pinecone etc. Mainly used to store reference code for my LangChain tutorials on YouTube.
slide-deck-ai
SlideDeck AI is a tool that leverages Generative Artificial Intelligence to co-create slide decks on any topic. Users can describe their topic and let SlideDeck AI generate a PowerPoint slide deck, streamlining the presentation creation process. The tool offers an iterative workflow with a conversational interface for creating and improving presentations. It uses Mistral Nemo Instruct to generate initial slide content, searches and downloads images based on keywords, and allows users to refine content through additional instructions. SlideDeck AI provides pre-defined presentation templates and a history of instructions for users to enhance their presentations.
obsidian-chat-cbt-plugin
ChatCBT is an AI-powered journaling assistant for Obsidian, inspired by cognitive behavioral therapy (CBT). It helps users reframe negative thoughts and rewire reactions to distressful situations. The tool provides kind and objective responses to uncover negative thinking patterns, store conversations privately, and summarize reframed thoughts. Users can choose between a cloud-based AI service (OpenAI) or a local and private service (Ollama) for handling data. ChatCBT is not a replacement for therapy but serves as a journaling assistant to help users gain perspective on their problems.
Synthalingua
Synthalingua is an advanced, self-hosted tool that leverages artificial intelligence to translate audio from various languages into English in near real time. It offers multilingual outputs and utilizes GPU and CPU resources for optimized performance. Although currently in beta, it is actively developed with regular updates to enhance capabilities. The tool is not intended for professional use but for fun, language learning, and enjoying content at a reasonable pace. Users must ensure speakers speak clearly for accurate translations. It is not a replacement for human translators and users assume their own risk and liability when using the tool.
rag-time
RAG Time is a 5-week AI learning series focusing on Retrieval-Augmented Generation (RAG) concepts. The repository contains code samples, step-by-step guides, and resources to help users master RAG. It aims to teach foundational and advanced RAG concepts, demonstrate real-world applications, and provide hands-on samples for practical implementation.
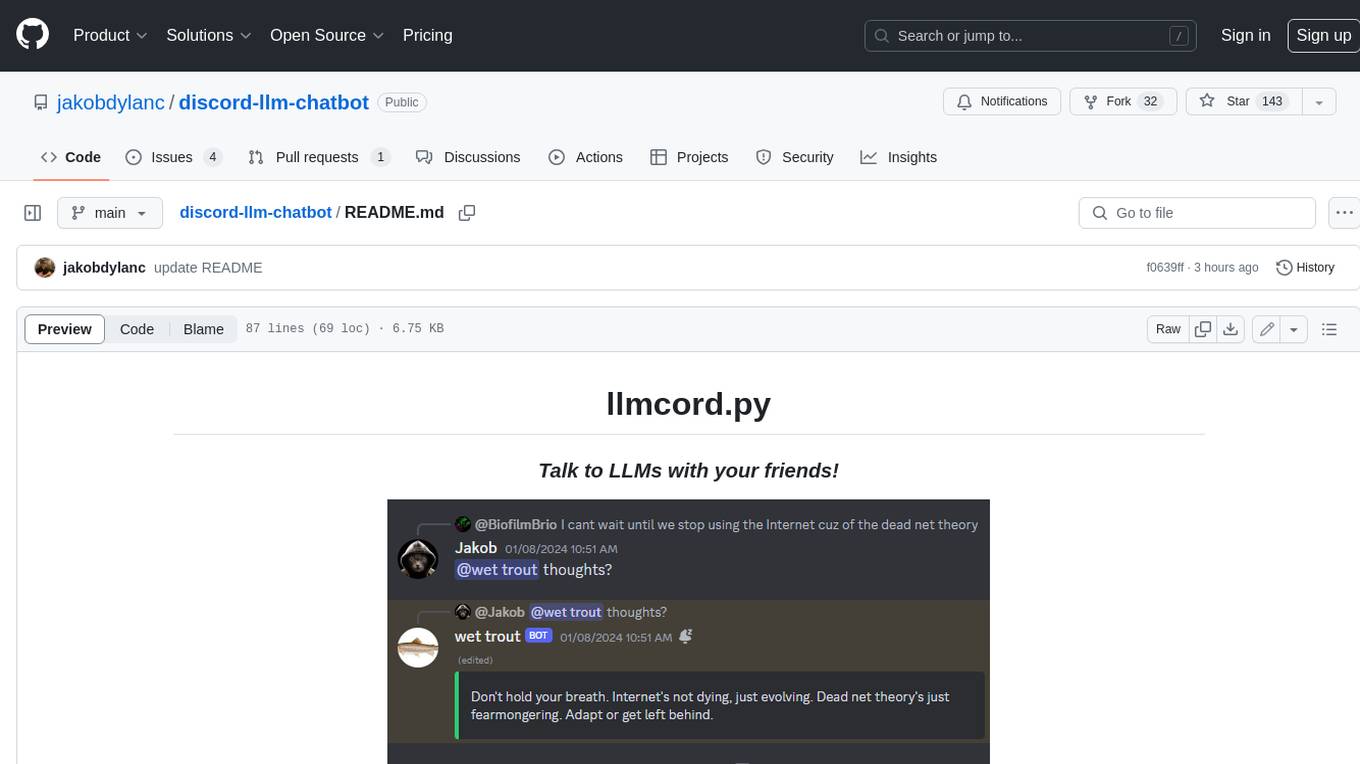
discord-llm-chatbot
llmcord.py enables collaborative LLM prompting in your Discord server. It works with practically any LLM, remote or locally hosted. ### Features ### Reply-based chat system Just @ the bot to start a conversation and reply to continue. Build conversations with reply chains! You can do things like: - Build conversations together with your friends - "Rewind" a conversation simply by replying to an older message - @ the bot while replying to any message in your server to ask a question about it Additionally: - Back-to-back messages from the same user are automatically chained together. Just reply to the latest one and the bot will see all of them. - You can seamlessly move any conversation into a thread. Just create a thread from any message and @ the bot inside to continue. ### Choose any LLM Supports remote models from OpenAI API, Mistral API, Anthropic API and many more thanks to LiteLLM. Or run a local model with ollama, oobabooga, Jan, LM Studio or any other OpenAI compatible API server. ### And more: - Supports image attachments when using a vision model - Customizable system prompt - DM for private access (no @ required) - User identity aware (OpenAI API only) - Streamed responses (turns green when complete, automatically splits into separate messages when too long, throttled to prevent Discord ratelimiting) - Displays helpful user warnings when appropriate (like "Only using last 20 messages", "Max 5 images per message", etc.) - Caches message data in a size-managed (no memory leaks) and per-message mutex-protected (no race conditions) global dictionary to maximize efficiency and minimize Discord API calls - Fully asynchronous - 1 Python file, ~200 lines of code
katrain
KaTrain is a tool designed for analyzing games and playing go with AI feedback from KataGo. Users can review their games to find costly moves, play against AI with immediate feedback, play against weakened AI versions, and generate focused SGF reviews. The tool provides various features such as previews, tutorials, installation instructions, and configuration options for KataGo. Users can play against AI, receive instant feedback on moves, explore variations, and request in-depth analysis. KaTrain also supports distributed training for contributing to KataGo's strength and training bigger models. The tool offers themes customization, FAQ section, and opportunities for support and contribution through GitHub issues and Discord community.
yuna-ai
Yuna AI is a unique AI companion designed to form a genuine connection with users. It runs exclusively on the local machine, ensuring privacy and security. The project offers features like text generation, language translation, creative content writing, roleplaying, and informal question answering. The repository provides comprehensive setup and usage guides for Yuna AI, along with additional resources and tools to enhance the user experience.
Transtation-KMP
Transtation is an easy-to-use and powerful translation software for Android/Desktop based on Kotlin Multiplatform + Compose Multiplatform. It allows users to translate one item using multiple engines simultaneously, utilize advanced Large Language Models for translation, chat with LLMs for translation, translate long text, support plugin development, image translation, and screen translation. The application is designed for Chinese users and serves as a reference for learning Jetpack Compose or Compose Multiplatform. It features Kotlin Multiplatform, Compose Multiplatform, MVVM, Kotlin Coroutine, Flow, SqlDelight, synchronized translation with multiple engines, plugin development, and makes use of Kotlin language features like lazy loading, Coroutine, sealed classes, and reflection. The application gradually adapts to Android13 with features like setting application language separately and supporting Monet icon.

second-brain-ai-assistant-course
This open-source course teaches how to build an advanced RAG and LLM system using LLMOps and ML systems best practices. It helps you create an AI assistant that leverages your personal knowledge base to answer questions, summarize documents, and provide insights. The course covers topics such as LLM system architecture, pipeline orchestration, large-scale web crawling, model fine-tuning, and advanced RAG features. It is suitable for ML/AI engineers and data/software engineers & data scientists looking to level up to production AI systems. The course is free, with minimal costs for tools like OpenAI's API and Hugging Face's Dedicated Endpoints. Participants will build two separate Python applications for offline ML pipelines and online inference pipeline.
SurfSense
SurfSense is a tool designed to help users save and organize content from the internet into a personal Knowledge Graph. It allows users to capture web browsing sessions and webpage content using a Chrome extension, enabling easy retrieval and recall of saved information. SurfSense offers features like powerful search capabilities, natural language interaction with saved content, self-hosting options, and integration with GraphRAG for meaningful content relations. The tool eliminates the need for web scraping by directly reading data from the DOM, making it a convenient solution for managing online information.
HiNote
HiNote is an AI-programmed Obsidian plugin that allows users to extract highlighted text from notes, add comments, generate AI comments, and engage in dialogue with the highlighted text. Users can highlight text in various formats, export it as knowledge card images, create new notes, and enjoy extended features in the main view. The plugin supports features like highlighted text retrieval, highlight comments, export as image, export as note, AI comment generation, AI chat, and premium features like a Flashcard system for effective memorization.
crawlchat
CrawlChat is an open sourced AI-powered platform that transforms technical documentation into intelligent chatbots. It allows users to connect documentation from various sources and deploy AI assistants that can answer questions across multiple channels. The platform includes services like front-facing React app, Express app, Discord bot, Slack app, and more. Users can self-host the platform using Dockerfiles and set up environment variables for easy deployment. Local development is quick and easy, allowing users to contribute by starting the necessary services and making improvements or adding features.
For similar tasks
joplin-plugin-jarvis
Jarvis is an AI note-taking assistant for Joplin, powered by online and offline LLMs (such as OpenAI's ChatGPT or GPT-4, Hugging Face, Google PaLM, Universal Sentence Encoder). You can chat with it (including prompt templates), use your personal notes as additional context in the chat, automatically annotate notes, perform semantic search, or compile an automatic review of the scientific literature.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.
For similar jobs

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).
thepipe
The Pipe is a multimodal-first tool for feeding files and web pages into vision-language models such as GPT-4V. It is best for LLM and RAG applications that require a deep understanding of tricky data sources. The Pipe is available as a hosted API at thepi.pe, or it can be set up locally.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.
blog
这是一个程序员关于 ChatGPT 学习过程的记录,其中包括了 ChatGPT 的使用技巧、相关工具和资源的整理,以及一些个人见解和思考。 **使用技巧** * **充值 OpenAI API**:可以通过 https://beta.openai.com/account/api-keys 进行充值,支持信用卡和 PayPal。 * **使用专梯**:推荐使用稳定的专梯,可以有效提高 ChatGPT 的访问速度和稳定性。 * **使用魔法**:可以通过 https://my.x-air.app:666/#/register?aff=32853 访问 ChatGPT,无需魔法即可访问。 * **下载各种 apk**:可以通过 https://apkcombo.com 下载各种安卓应用的 apk 文件。 * **ChatGPT 官网**:ChatGPT 的官方网站是 https://ai.com。 * **Midjourney**:Midjourney 是一个生成式 AI 图像平台,可以通过 https://midjourney.com 访问。 * **文本转视频**:可以通过 https://www.d-id.com 将文本转换为视频。 * **国内大模型**:国内也有很多大模型,如阿里巴巴的通义千问、百度文心一言、讯飞星火、阿里巴巴通义听悟等。 * **查看 OpenAI 状态**:可以通过 https://status.openai.com/ 查看 OpenAI 的服务状态。 * **Canva 画图**:Canva 是一个在线平面设计平台,可以通过 https://www.canva.cn 进行画图。 **相关工具和资源** * **文字转语音**:可以通过 https://modelscope.cn/models?page=1&tasks=text-to-speech&type=audio 找到文字转语音的模型。 * **可好好玩玩的项目**: * https://github.com/sunner/ChatALL * https://github.com/labring/FastGPT * https://github.com/songquanpeng/one-api * **个人博客**: * https://baoyu.io/ * https://gorden-sun.notion.site/527689cd2b294e60912f040095e803c5?v=4f6cc12006c94f47aee4dc909511aeb5 * **srt 2 lrc 歌词**:可以通过 https://gotranscript.com/subtitle-converter 将 srt 格式的字幕转换为 lrc 格式的歌词。 * **5 种速率限制**:OpenAI API 有 5 种速率限制:RPM(每分钟请求数)、RPD(每天请求数)、TPM(每分钟 tokens 数量)、TPD(每天 tokens 数量)、IPM(每分钟图像数量)。 * **扣子平台**:coze.cn 是一个扣子平台,可以提供各种扣子。 * **通过云函数免费使用 GPT-3.5**:可以通过 https://juejin.cn/post/7353849549540589587 免费使用 GPT-3.5。 * **不蒜子 统计网页基数**:可以通过 https://busuanzi.ibruce.info/ 统计网页的基数。 * **视频总结和翻译网页**:可以通过 https://glarity.app/zh-CN 总结和翻译视频。 * **视频翻译和配音工具**:可以通过 https://github.com/jianchang512/pyvideotrans 翻译和配音视频。 * **文字生成音频**:可以通过 https://www.cnblogs.com/jijunjian/p/18118366 将文字生成音频。 * **memo ai**:memo.ac 是一个多模态 AI 平台,可以将视频链接、播客链接、本地音视频转换为文字,支持多语言转录后翻译,还可以将文字转换为新的音频。 * **视频总结工具**:可以通过 https://summarize.ing/ 总结视频。 * **可每天免费玩玩**:可以通过 https://www.perplexity.ai/ 每天免费玩玩。 * **Suno.ai**:Suno.ai 是一个 AI 语言模型,可以通过 https://bibigpt.co/ 访问。 * **CapCut**:CapCut 是一个视频编辑软件,可以通过 https://www.capcut.cn/ 下载。 * **Valla.ai**:Valla.ai 是一个多模态 AI 模型,可以通过 https://www.valla.ai/ 访问。 * **Viggle.ai**:Viggle.ai 是一个 AI 视频生成平台,可以通过 https://viggle.ai 访问。 * **使用免费的 GPU 部署文生图大模型**:可以通过 https://www.cnblogs.com/xuxiaona/p/18088404 部署文生图大模型。 * **语音转文字**:可以通过 https://speech.microsoft.com/portal 将语音转换为文字。 * **投资界的 ai**:可以通过 https://reportify.cc/ 了解投资界的 ai。 * **抓取小视频 app 的各种信息**:可以通过 https://github.com/NanmiCoder/MediaCrawler 抓取小视频 app 的各种信息。 * **马斯克 Grok1 开源**:马斯克的 Grok1 模型已经开源,可以通过 https://github.com/xai-org/grok-1 访问。 * **ChatALL**:ChatALL 是一个跨端支持的聊天机器人,可以通过 https://github.com/sunner/ChatALL 访问。 * **零一万物**:零一万物是一个 AI 平台,可以通过 https://www.01.ai/cn 访问。 * **智普**:智普是一个 AI 语言模型,可以通过 https://chatglm.cn/ 访问。 * **memo ai 下载**:可以通过 https://memo.ac/ 下载 memo ai。 * **ffmpeg 学习**:可以通过 https://www.ruanyifeng.com/blog/2020/01/ffmpeg.html 学习 ffmpeg。 * **自动生成文章小工具**:可以通过 https://www.cognition-labs.com/blog 生成文章。 * **简易商城**:可以通过 https://www.cnblogs.com/whuanle/p/18086537 搭建简易商城。 * **物联网**:可以通过 https://www.cnblogs.com/xuxiaona/p/18088404 学习物联网。 * **自定义表单、自定义列表、自定义上传和下载、自定义流程、自定义报表**:可以通过 https://www.cnblogs.com/whuanle/p/18086537 实现自定义表单、自定义列表、自定义上传和下载、自定义流程、自定义报表。 **个人见解和思考** * ChatGPT 是一个强大的工具,可以用来提高工作效率和创造力。 * ChatGPT 的使用门槛较低,即使是非技术人员也可以轻松上手。 * ChatGPT 的发展速度非常快,未来可能会对各个行业产生深远的影响。 * 我们应该理性看待 ChatGPT,既要看到它的优点,也要意识到它的局限性。 * 我们应该积极探索 ChatGPT 的应用场景,为社会创造价值。
joplin-plugin-jarvis
Jarvis is an AI note-taking assistant for Joplin, powered by online and offline LLMs (such as OpenAI's ChatGPT or GPT-4, Hugging Face, Google PaLM, Universal Sentence Encoder). You can chat with it (including prompt templates), use your personal notes as additional context in the chat, automatically annotate notes, perform semantic search, or compile an automatic review of the scientific literature.

vectara-answer
Vectara Answer is a sample app for Vectara-powered Summarized Semantic Search (or question-answering) with advanced configuration options. For examples of what you can build with Vectara Answer, check out Ask News, LegalAid, or any of the other demo applications.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.