
intelligence-layer-sdk
a unified framework for leveraging LLMs
Stars: 69
The Aleph Alpha Intelligence Layer️ offers a comprehensive suite of development tools for crafting solutions that harness the capabilities of large language models (LLMs). With a unified framework for LLM-based workflows, it facilitates seamless AI product development, from prototyping and prompt experimentation to result evaluation and deployment. The Intelligence Layer SDK provides features such as Composability, Evaluability, and Traceability, along with examples to get started. It supports local installation using poetry, integration with Docker, and access to LLM endpoints for tutorials and tasks like Summarization, Question Answering, Classification, Evaluation, and Parameter Optimization. The tool also offers pre-configured tasks for tasks like Classify, QA, Search, and Summarize, serving as a foundation for custom development.
README:
The Aleph Alpha Intelligence Layer️ offers a comprehensive suite of development tools for crafting solutions that harness the capabilities of large language models (LLMs). With a unified framework for LLM-based workflows, it facilitates seamless AI product development, from prototyping and prompt experimentation to result evaluation and deployment.
The key features of the Intelligence Layer are:
- Composability: Streamline your journey from prototyping to scalable deployment. The Intelligence Layer SDK offers seamless integration with diverse evaluation methods, manages concurrency, and orchestrates smaller tasks into complex workflows.
- Evaluability: Continuously evaluate your AI applications against your quantitative quality requirements. With the Intelligence Layer SDK you can quickly iterate on different solution strategies, ensuring confidence in the performance of your final product. Take inspiration from the provided evaluations for summary and search when building a custom evaluation logic for your own use case.
- Traceability: At the core of the Intelligence Layer is the belief that all AI processes must be auditable and traceable. We provide full observability by seamlessly logging each step of every workflow. This enhances your debugging capabilities and offers greater control post-deployment when examining model responses.
- Examples: Get started by following our hands-on examples, demonstrating how to use the Intelligence Layer SDK and interact with its API.
- Aleph Alpha Intelligence Layer
- Table of contents
- Installation
- Getting started
- Models
- Example index
- References
- License
- For Developers
Clone the Intelligence Layer repository from GitHub.
git clone [email protected]:Aleph-Alpha/intelligence-layer-sdk.gitThe Intelligence Layer uses poetry, which serves as the package manager and manages the virtual environments.
We recommend installing poetry globally, while still isolating it in a virtual environment, using pipx, following the official instructions.
Afterward, simply run poetry install to create a new virtual environment and install all project dependencies.
poetry installThe environment can be activated via poetry shell. See the official poetry documentation for more information.
To install the Aleph-Alpha Intelligence Layer from the JFrog artifactory in you project, you have to add this information to your poetry setup via the following four steps. First, add the artifactory as a source to your project via
poetry source add --priority=explicit artifactory https://alephalpha.jfrog.io/artifactory/api/pypi/python/simpleSecond, to install the poetry environment, export your JFrog credentials to the environment
export [email protected]
export POETRY_HTTP_BASIC_ARTIFACTORY_PASSWORD=your-token-hereThird, add the Intelligence Layer to the project
poetry add --source artifactory intelligence-layerFourth, execute
poetry installNow the Intelligence Layer should be available as a Python package and ready to use.
from intelligence_layer.core import TaskIn VSCode, to enable auto-import up to the second depth, where all symbols are exported, add the following entry to your ./.vscode/settings.json:
"python.analysis.packageIndexDepths": [
{
"name": "intelligence_layer",
"depth": 2
}
]To use the Intelligence Layer in Docker, a few settings are needed to not leak your GitHub token.
You will need your GitHub token set in your environment.
In order to modify the git config add the following to your docker container:
RUN apt-get -y update
RUN apt-get -y install git curl gcc python3-dev
RUN pip install poetry
RUN poetry install --no-dev --no-interaction --no-ansi \
&& rm -f ~/.gitconfig📘 Not sure where to start? Familiarize yourself with the Intelligence Layer using the below notebooks as interactive tutorials. If you prefer you can also read about the concepts first.
The tutorials aim to guide you through implementing several common use-cases with the Intelligence Layer. They introduce you to key concepts and enable you to create your own use-cases. In general the tutorials are build in a way that you can simply hop into the topic you are most interested in. However, for starters we recommend to read through the Summarization tutorial first. It explains the core concepts of the intelligence layer in more depth while for the other tutorials we assume that these concepts are known.
The tutorials require access to an LLM endpoint. You can choose between using the Aleph Alpha API (https://api.aleph-alpha.com) or an on-premise setup by configuring the appropriate environment variables. To configure the environment variables, create a .env file in the root directory of the project and copy the contents of the .env.example file into it.
To use the Aleph Alpha API, that is set as the default host URL, set the AA_TOKEN variable to your Aleph Alpha access token, and you are good to go.
To use an on-premises setup, set the CLIENT_URL variable to your host URL.
| Order | Topic | Description | Notebook 📓 |
|---|---|---|---|
| 1 | Summarization | Summarize a document | summarization.ipynb |
| 2 | Question Answering | Various approaches for QA | qa.ipynb |
| 3 | Classification | Learn about two methods of classification | classification.ipynb |
| 4 | Evaluation | Evaluate LLM-based methodologies | evaluation.ipynb |
| 5 | Parameter Optimization | Compare Task configuration for optimization | parameter_optimization.ipynb |
| 6 | Attention Manipulation | Use TextControls for Attention Manipulation (AtMan) |
attention_manipulation_with_text_controls.ipynb |
| 7 | Elo QA Evaluation | Evaluate QA tasks in an Elo ranking | elo_qa_eval.ipynb |
| 8 | Quickstart Task | Build a custom Task for your use case |
quickstart_task.ipynb |
| 9 | Document Index | Connect your proprietary knowledge base | document_index.ipynb |
| 10 | Human Evaluation | Connect to Argilla for manual evaluation | human_evaluation.ipynb |
| 11 | Performance tips | Contains some small tips for performance | performance_tips.ipynb |
| 12 | Deployment | Shows how to deploy a Task in a minimal FastAPI app. | fastapi_tutorial.ipynb |
| 13 | Issue Classification | Deploy a Task in Kubernetes to classify Jira issues | Found in adjacent repository |
| 14 | Evaluate with Studio | Shows how to evaluate your Task using Studio |
evaluate_with_studio.ipynb |
The how-tos are quick lookups about how to do things. Compared to the tutorials, they are shorter and do not explain the concepts they are using in-depth.
| Tutorial | Description |
|---|---|
| Tasks | |
| ...define a task | How to come up with a new task and formulate it |
| ...implement a task | Implement a formulated task and make it run with the Intelligence Layer |
| ...debug and log a task | Tools for logging and debugging in tasks |
| Analysis Pipeline | |
| ...implement a simple evaluation and aggregation logic | Basic examples of evaluation and aggregation logic |
| ...create a dataset | Create a dataset used for running a task |
| ...run a task on a dataset | Run a task on a whole dataset instead of single examples |
| ...resume a run after a crash | Resume a run after a crash or exception occurred |
| ...evaluate multiple runs | Evaluate (multiple) runs in a single evaluation |
| ...aggregate multiple evaluations | Aggregate (multiple) evaluations in a single aggregation |
| ...retrieve data for analysis | Retrieve experiment data in multiple different ways |
| ...implement a custom human evaluation | Necessary steps to create an evaluation with humans as a judge via Argilla |
| ...implement elo evaluations | Evaluate runs and create ELO ranking for them |
| ...implement incremental evaluation | Implement and run an incremental evaluation |
| Studio | |
| ...use Studio with traces | Submitting Traces to Studio for debugging |
| ...upload existing datasets | Upload Datasets to Studio |
| ...execute a benchmark | Execute a benchmark |
Currently, we support a bunch of models accessible via the Aleph Alpha API. Depending on your local setup, you may even have additional models available.
| Model | Description |
|---|---|
| LuminousControlModel | Any control-type model based on the first Luminous generation, specifically luminous-base-control, luminous-extended-control and luminous-supreme-control. |
| Pharia1ChatModel | Pharia-1 based models prompted for multi-turn interactions. Includes pharia-1-llm-7b-control and pharia-1-llm-7b-control-aligned. |
| Llama3InstructModel | Llama-3 based models prompted for one-turn instruction answering. Includes llama-3-8b-instruct, llama-3-70b-instruct, llama-3.1-8b-instruct and llama-3.1-70b-instruct. |
| Llama3ChatModel | Llama-3 based models prompted for multi-turn interactions. Includes llama-3-8b-instruct, llama-3-70b-instruct, llama-3.1-8b-instruct and llama-3.1-70b-instruct. |
To give you a starting point for using the Intelligence Layer, we provide some pre-configured Tasks that are ready to use out-of-the-box, as well as an accompanying "Getting started" guide in the form of Jupyter Notebooks.
| Type | Task | Description |
|---|---|---|
| Classify | EmbeddingBasedClassify | Classify a short text by computing its similarity with example texts for each class. |
| Classify | PromptBasedClassify | Classify a short text by assessing each class' probability using zero-shot prompting. |
| Classify | PromptBasedClassifyWithDefinitions | Classify a short text by assessing each class' probability using zero-shot prompting. Each class is defined by a natural language description. |
| Classify | KeywordExtract | Generate matching labels for a short text. |
| QA | MultipleChunkRetrieverQa | Answer a question based on an entire knowledge base. Recommended for most RAG-QA use-cases. |
| QA | LongContextQa | Answer a question based on one document of any length. |
| QA | MultipleChunkQa | Answer a question based on a list of short texts. |
| QA | SingleChunkQa | Answer a question based on a short text. |
| QA | RetrieverBasedQa (deprecated) | Answer a question based on a document base using a BaseRetriever implementation. |
| Search | Search | Search for texts in a document base using a BaseRetriever implementation. |
| Search | ExpandChunks | Expand chunks retrieved with a BaseRetriever implementation. |
| Summarize | SteerableLongContextSummarize | Condense a long text into a summary with a natural language instruction. |
| Summarize | SteerableSingleChunkSummarize | Condense a short text into a summary with a natural language instruction. |
| Summarize | RecursiveSummarize | Recursively condense a text into a summary. |
Note that we do not expect the above use cases to solve all of your issues. Instead, we encourage you to think of our pre-configured use cases as a foundation to fast-track your development process. By leveraging these tasks, you gain insights into the framework's capabilities and best practices.
We encourage you to copy and paste these use cases directly into your own project. From here, you can customize everything, including the prompt, model, and more intricate functional logic. For more information, check the tutorials and the how-tos
The full code documentation can be found in our read-the-docs here
This project can only be used after signing the agreement with Aleph Alpha®. Please refer to the LICENSE file for more details.
For further information check out our different guides and documentations:
- Concepts.md for an overview of what Intelligence Layer is and how it works.
- style_guide.md on how we write and document code.
- RELEASE.md for the release process of IL.
- CHANGELOG.md for the latest changes.
- Share the details of your problem with us.
- Write your code according to our style guide.
- Add doc strings to your code as described here.
- Write tests for new features (Executing Tests).
- Add an how_to and/or notebook as a documentation (check out this for guidance).
- Update the Changelog with your changes.
- Request a review for the MR, so that it can be merged.
If you want to execute all tests, you first need to spin up your docker container and execute the commands with your own GITLAB_TOKEN.
export GITLAB_TOKEN=...
echo $GITLAB_TOKEN | docker login registry.gitlab.aleph-alpha.de -u your_email@for_gitlab --password-stdin
docker compose pull to update containersAfterwards simply run docker compose up --build. You can then either run the tests in your IDE or via the terminal.
In VSCode
- Sidebar > Testing
- Select pytest as framework for the tests
- Select
intelligence_layer/testsas source of the tests
You can then run the tests from the sidebar.
In a terminal In order to run a local proxy of the CI pipeline (required to merge) you can run
scripts/all.sh
This will run linters and all tests.
The scripts to run single steps can also be found in the scripts folder.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for intelligence-layer-sdk
Similar Open Source Tools
intelligence-layer-sdk
The Aleph Alpha Intelligence Layer️ offers a comprehensive suite of development tools for crafting solutions that harness the capabilities of large language models (LLMs). With a unified framework for LLM-based workflows, it facilitates seamless AI product development, from prototyping and prompt experimentation to result evaluation and deployment. The Intelligence Layer SDK provides features such as Composability, Evaluability, and Traceability, along with examples to get started. It supports local installation using poetry, integration with Docker, and access to LLM endpoints for tutorials and tasks like Summarization, Question Answering, Classification, Evaluation, and Parameter Optimization. The tool also offers pre-configured tasks for tasks like Classify, QA, Search, and Summarize, serving as a foundation for custom development.
home-llm
Home LLM is a project that provides the necessary components to control your Home Assistant installation with a completely local Large Language Model acting as a personal assistant. The goal is to provide a drop-in solution to be used as a "conversation agent" component by Home Assistant. The 2 main pieces of this solution are Home LLM and Llama Conversation. Home LLM is a fine-tuning of the Phi model series from Microsoft and the StableLM model series from StabilityAI. The model is able to control devices in the user's house as well as perform basic question and answering. The fine-tuning dataset is a custom synthetic dataset designed to teach the model function calling based on the device information in the context. Llama Conversation is a custom component that exposes the locally running LLM as a "conversation agent" in Home Assistant. This component can be interacted with in a few ways: using a chat interface, integrating with Speech-to-Text and Text-to-Speech addons, or running the oobabooga/text-generation-webui project to provide access to the LLM via an API interface.
LaVague
LaVague is an open-source Large Action Model framework that uses advanced AI techniques to compile natural language instructions into browser automation code. It leverages Selenium or Playwright for browser actions. Users can interact with LaVague through an interactive Gradio interface to automate web interactions. The tool requires an OpenAI API key for default examples and offers a Playwright integration guide. Contributors can help by working on outlined tasks, submitting PRs, and engaging with the community on Discord. The project roadmap is available to track progress, but users should exercise caution when executing LLM-generated code using 'exec'.
air-script
AirScript is a domain-specific language for expressing AIR constraints for STARKs, with the goal of enabling writing and auditing constraints without the need to learn a specific programming language. It also aims to perform automated optimizations and output constraint evaluator code in multiple target languages. The project is organized into several crates including Parser, MIR, AIR, Winterfell code generator, ACE code generator, and AirScript CLI for transpiling AIRs to target languages.
erlang-red
Erlang-Red is an experimental Erlang backend designed to replace Node-RED's existing NodeJS backend, aiming for 100% compatibility with existing Node-RED flow code. It brings the advantages of low-code visual flow-based programming to Erlang, a language designed for message passing and concurrency. The tool allows for creating data flows that describe concurrent processing with guaranteed concurrency and performance. Erlang-Red provides a visual flow editor for creating and testing flows, supporting various Node-RED core nodes and Erlang-specific nodes. The development process is flow-driven, with test flows ensuring correct node functionality. The tool can be deployed locally using Docker or on platforms like Fly.io and Heroku. Contributions in the form of Erlang code, Node-RED test flows, and Elixir code are welcome, with a focus on replicating Node-RED functionality in alternative programming languages.
tribe
Tribe AI is a low code tool designed to rapidly build and coordinate multi-agent teams. It leverages the langgraph framework to customize and coordinate teams of agents, allowing tasks to be split among agents with different strengths for faster and better problem-solving. The tool supports persistent conversations, observability, tool calling, human-in-the-loop functionality, easy deployment with Docker, and multi-tenancy for managing multiple users and teams.
Instruct2Act
Instruct2Act is a framework that utilizes Large Language Models to map multi-modal instructions to sequential actions for robotic manipulation tasks. It generates Python programs using the LLM model for perception, planning, and action. The framework leverages foundation models like SAM and CLIP to convert high-level instructions into policy codes, accommodating various instruction modalities and task demands. Instruct2Act has been validated on robotic tasks in tabletop manipulation domains, outperforming learning-based policies in several tasks.

pluto
Pluto is a development tool dedicated to helping developers **build cloud and AI applications more conveniently** , resolving issues such as the challenging deployment of AI applications and open-source models. Developers are able to write applications in familiar programming languages like **Python and TypeScript** , **directly defining and utilizing the cloud resources necessary for the application within their code base** , such as AWS SageMaker, DynamoDB, and more. Pluto automatically deduces the infrastructure resource needs of the app through **static program analysis** and proceeds to create these resources on the specified cloud platform, **simplifying the resources creation and application deployment process**.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
chatdev
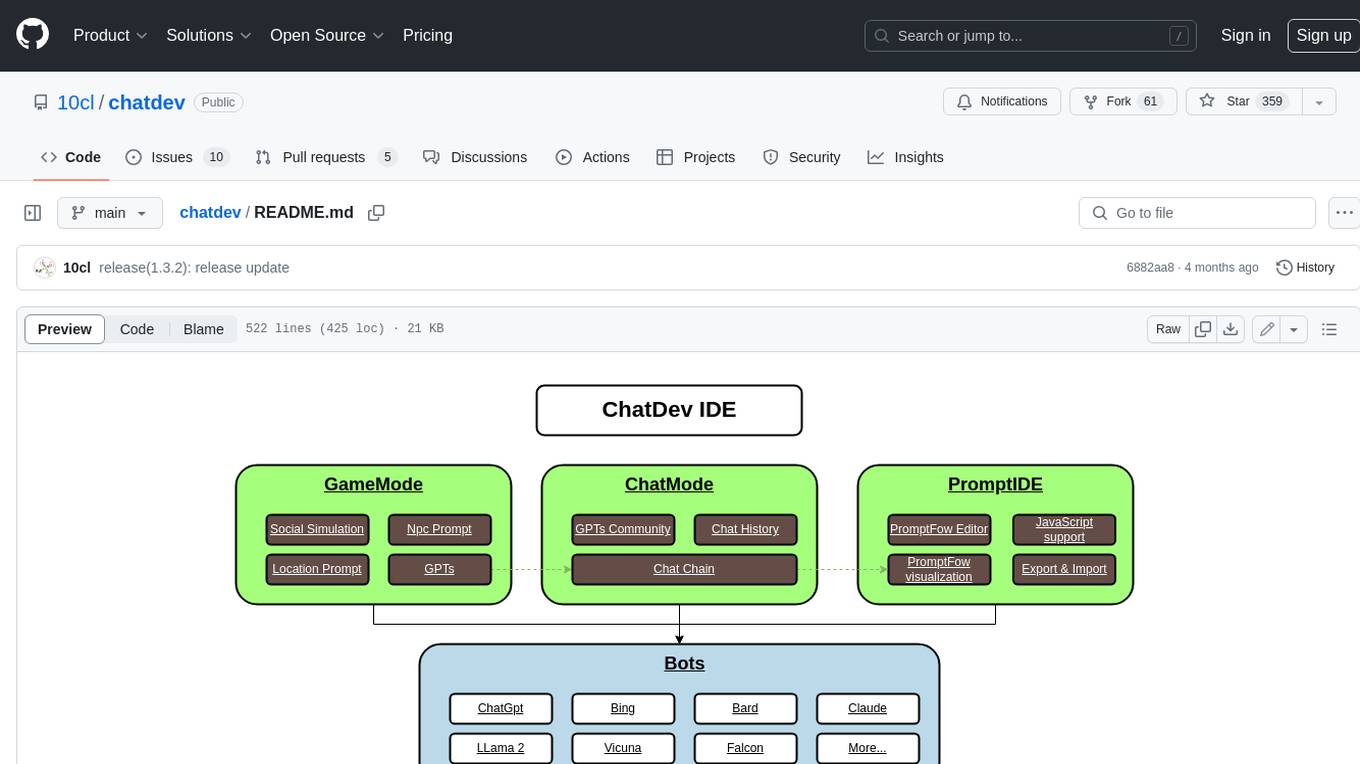
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.

dataherald
Dataherald is a natural language-to-SQL engine built for enterprise-level question answering over structured data. It allows you to set up an API from your database that can answer questions in plain English. You can use Dataherald to: * Allow business users to get insights from the data warehouse without going through a data analyst * Enable Q+A from your production DBs inside your SaaS application * Create a ChatGPT plug-in from your proprietary data
generative-ai-use-cases
Generative AI Use Cases (GenU) is an application that provides well-architected implementation with business use cases for utilizing generative AI in business operations. It offers a variety of standard use cases leveraging generative AI, such as chat interaction, text generation, summarization, meeting minutes generation, writing assistance, translation, web content extraction, image generation, video generation, video analysis, diagram generation, voice chat, RAG technique, custom agent creation, and custom use case building. Users can experience generative AI use cases, perform RAG technique, use custom agents, and create custom use cases using GenU.
azure-ai-document-processing-samples
This repository contains a collection of code samples that demonstrate how to use various Azure AI capabilities to process documents. The samples help engineering teams establish techniques with Azure AI Foundry, Azure OpenAI, Azure AI Document Intelligence, and Azure AI Language services to build solutions for extracting structured data, classifying, and analyzing documents. The techniques simplify custom model training, improve reliability in document processing, and simplify document processing workflows by providing reusable code and patterns that can be easily modified and evaluated for most use cases.

katib
Katib is a Kubernetes-native project for automated machine learning (AutoML). Katib supports Hyperparameter Tuning, Early Stopping and Neural Architecture Search. Katib is the project which is agnostic to machine learning (ML) frameworks. It can tune hyperparameters of applications written in any language of the users’ choice and natively supports many ML frameworks, such as TensorFlow, Apache MXNet, PyTorch, XGBoost, and others. Katib can perform training jobs using any Kubernetes Custom Resources with out of the box support for Kubeflow Training Operator, Argo Workflows, Tekton Pipelines and many more.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
BeamNGpy
BeamNGpy is an official Python library providing an API to interact with BeamNG.tech, a video game focused on academia and industry. It allows remote control of vehicles, AI-controlled vehicles, dynamic sensor models, access to road network and scenario objects, and multiple clients. The library comes with low-level functions and higher-level interfaces for complex actions. BeamNGpy requires BeamNG.tech for usage and offers compatibility information for different versions. It also provides troubleshooting tips and encourages user contributions.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.