
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs.
Stars: 174
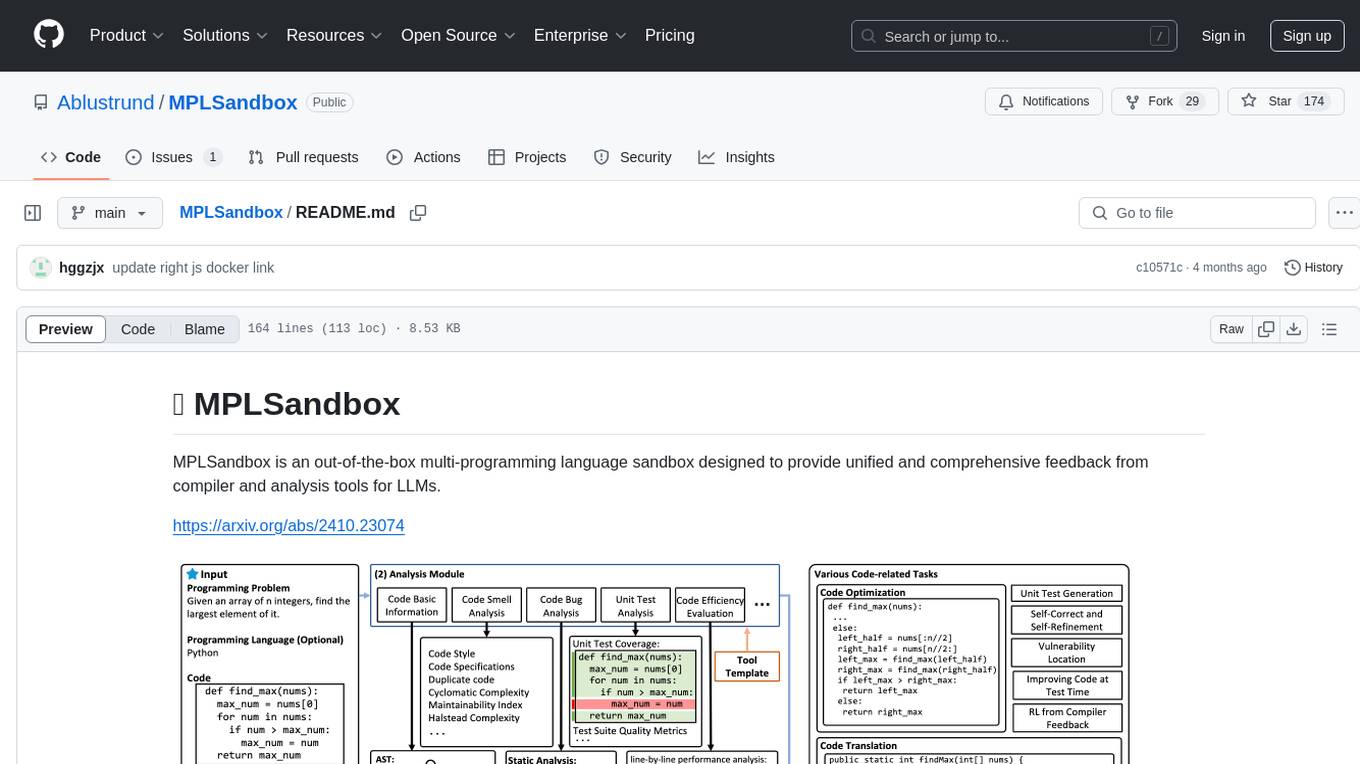
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.
README:
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs.
https://arxiv.org/abs/2410.23074
we propose MPLSandbox, an out-of-the-box sandbox designed to provide unified compiler feedback across multiple programming languages. Additionally, it integrates traditional code analysis tools, delivering comprehensive code information to LLMs from numerous perspectives. MPLSandbox simplifies code analysis for researchers, and can be seamlessly integrated into LLM training and application processes to enhance the performance of LLMs in a range of code-related tasks.
MPLSandbox consists of three core modules:
This Module can provide unified compiler feedback by compiling and executing the code. The code and unit test samples are sent to the sub-sandbox of the corresponding programming language for isolated execution to obtain compiler feedback. The sandbox ensures the program executes safely without jeopardizing the external environment or interrupting the training process
This module includes multiple traditional analysis tools to offer a comprehensive analysis report from numerous perspectives. It provides a comprehensive code analysis from multiple perspectives, such as static analysis (i.e., potential bug detection} and code smell analysis) and dynamic analysis (i.e., fuzz testing and efficiency analysis). Additionally, this module can also assess other input information besides the code, such as evaluating the coverage of unit tests for the code, aiding researchers in improving the quality of these unit tests.
This module integrates compilation feedback and various analysis results to accomplish a range of complex code-related tasks. It integrates these results for LLMs to improve the quality of generated code and enhance their performance on a range of code-related tasks.
The user can create and install MPLSandbox using the following command:
git clone [email protected]:Ablustrund/MPLSandbox.git
cd MPLSandbox
pip install .
# pip install -e . ## for editable modeFirst, users need to deploy the Docker images addresses on the host machine. After extensive testing, we have installed the necessary dependencies in Docker containers for various languages and packaged these custom Docker containers into the corresponding images as follows. We hope that users can directly use our open-source images because this can, to some extent, reduce the hassle of installing dependencies for various languages.
Python: mplsandbox-python-3.9.19-v1
Java: mplsandbox-java-11.0.12-v1
JavaScript: mplsandbox-javascript-22-v1
Go: mplsandbox-golang-1.17.0-v1
Ruby: mplsandbox-ruby-3.0.2-v1
TypeScript: mplsandbox-typescript-1-22-v1
Bash: mplsandbox-bash-v1
We recommend that users manually download these image files and then use the following command to import them into Docker:
docker load < <path_to_downloaded_image>If users wish to use custom images, we recommend modifying the DefaultImage class in /mplsandbox/const.py to define their own images.
Users can start mplsandbox and run it with the following lines of code:
from mplsandbox import MPLSANDBOX
data = {
"question":"Define get_sum_of_two_numbers():\n \"\"\"Write a function that takes two integers as input and returns their sum.\n\n -----Input-----\n \n The input consists of multiple test cases. Each test case contains two integers $a$ and $b$ ($-10^9 \\le a, b \\le 10^9$).\n \n -----Output-----\n \n For each test case, print the sum of the two integers.\n \n -----Example-----\n Input\n 3\n 1 2 ↵\n -1 1 ↵\n 1000000000 1000000000\n \n Output\n 3\n 0\n 2000000000\n \"\"\"",
"code": 'def get_sum_of_two_numbers():\n a, b = map(int, input().split(" "))\n print(a * b)\nget_sum_of_two_numbers()',
"unit_cases": {
"inputs": ["1 2", "3 4"],
"outputs": ["3", "7"]
},
"lang": "python"
} # or a JSON file path
executor = MPLSANDBOX(data)
result = executor.run(analysis_type="all")The specific descriptions of all fields in the data are as follows:
| Field | Description |
|---|---|
question |
(Required) Specifies the path to the code file to be executed. |
code |
(Required) Specifies the code to be executed. |
unit_cases |
(Required) Specifies the unit test cases, including inputs and expected outputs. |
lang |
(Optional) Specifies the language of the code. If not specified, it can be set to "AUTO" for automatic recognition. |
libraries |
(Optional) Specifies a list of dependency library names that need to be installed. |
client |
(Optional) Specifies the docker client instance to be used |
image |
(Optional) Specifies the docker image used to run the code. |
dockerfile |
(Optional) Specifies the path to the dockerfile used to build a custom docker image. |
keep_template |
(Optional) If it is set to True, the template files will be kept after the code is run. |
verbose |
(Optional) If it is set to True, verbose output will be enabled to assist with debugging and diagnosing issues. |
app |
(Optional) If it is set to True, app mode will be enabled, facilitating the deployment of services on the server. |
We also provide the following command-line interface to scan the data.json file and output the report to the report.txt file:
mplsandbox --data /path/to/your/data.json --report /path/to/your/report.txtMPLSandbox often serves as a node for emitting code-related signals, so configuring the corresponding services is very important. We have provided a simple service demo in the scripts directory, and users can run this demo with the following command:
cd scripts
python ./app.pyThen, users can access the service using the curl command or other methods, and the format example is in scripts/test_app.sh
./test_app.shWe are working hard to refactor and improve the open-source version of MPLSandbox to closely match the functionality of the version used internally by Meituan LLM Team. We are currently working hard to reconstruct analysis tools for languages such as Go, JavaScript, and Ruby to achieve better code analysis and automated testing.
@misc{dou2024MPLSandbox,
title={Multi-Programming Language Sandbox for LLMs},
author={Shihan Dou and Jiazheng Zhang and Jianxiang Zang and Yunbo Tao and Haoxiang Jia and Shichun Liu and Yuming Yang and Shenxi Wu and Shaoqing Zhang and Muling Wu and Changze Lv and Limao Xiong and Wenyu Zhan and Lin Zhang and Rongxiang Weng and Jingang Wang and Xunliang Cai and Yueming Wu and Ming Wen and Rui Zheng and Tao Ji and Yixin Cao and Tao Gui and Xipeng Qiu and Qi Zhang and Xuanjing Huang},
year={2024},
eprint={2410.23074},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2410.23074},
}@article{dou2024s,
title={What's Wrong with Your Code Generated by Large Language Models? An Extensive Study},
author={Dou, Shihan and Jia, Haoxiang and Wu, Shenxi and Zheng, Huiyuan and Zhou, Weikang and Wu, Muling and Chai, Mingxu and Fan, Jessica and Huang, Caishuang and Tao, Yunbo and others},
journal={arXiv preprint arXiv:2407.06153},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MPLSandbox
Similar Open Source Tools
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.

OneKE
OneKE is a flexible dockerized system for schema-guided knowledge extraction, capable of extracting information from the web and raw PDF books across multiple domains like science and news. It employs a collaborative multi-agent approach and includes a user-customizable knowledge base to enable tailored extraction. OneKE offers various IE tasks support, data sources support, LLMs support, extraction method support, and knowledge base configuration. Users can start with examples using YAML, Python, or Web UI, and perform tasks like Named Entity Recognition, Relation Extraction, Event Extraction, Triple Extraction, and Open Domain IE. The tool supports different source formats like Plain Text, HTML, PDF, Word, TXT, and JSON files. Users can choose from various extraction models like OpenAI, DeepSeek, LLaMA, Qwen, ChatGLM, MiniCPM, and OneKE for information extraction tasks. Extraction methods include Schema Agent, Extraction Agent, and Reflection Agent. The tool also provides support for schema repository and case repository management, along with solutions for network issues. Contributors to the project include Ningyu Zhang, Haofen Wang, Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, and Huajun Chen.

monitors4codegen
This repository hosts the official code and data artifact for the paper 'Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context'. It introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding. The repository contains datasets, evaluation scripts, inference results, a language server client 'multilspy' for static analyses, and implementation of various monitors monitoring for different properties in 3 programming languages. The monitors guide Language Models to adhere to properties like valid identifier dereferences, correct number of arguments to method calls, typestate validity of method call sequences, and more.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

lmql
LMQL is a programming language designed for large language models (LLMs) that offers a unique way of integrating traditional programming with LLM interaction. It allows users to write programs that combine algorithmic logic with LLM calls, enabling model reasoning capabilities within the context of the program. LMQL provides features such as Python syntax integration, rich control-flow options, advanced decoding techniques, powerful constraints via logit masking, runtime optimization, sync and async API support, multi-model compatibility, and extensive applications like JSON decoding and interactive chat interfaces. The tool also offers library integration, flexible tooling, and output streaming options for easy model output handling.

artkit
ARTKIT is a Python framework developed by BCG X for automating prompt-based testing and evaluation of Gen AI applications. It allows users to develop automated end-to-end testing and evaluation pipelines for Gen AI systems, supporting multi-turn conversations and various testing scenarios like Q&A accuracy, brand values, equitability, safety, and security. The framework provides a simple API, asynchronous processing, caching, model agnostic support, end-to-end pipelines, multi-turn conversations, robust data flows, and visualizations. ARTKIT is designed for customization by data scientists and engineers to enhance human-in-the-loop testing and evaluation, emphasizing the importance of tailored testing for each Gen AI use case.

poml
POML (Prompt Orchestration Markup Language) is a novel markup language designed to bring structure, maintainability, and versatility to advanced prompt engineering for Large Language Models (LLMs). It addresses common challenges in prompt development, such as lack of structure, complex data integration, format sensitivity, and inadequate tooling. POML provides a systematic way to organize prompt components, integrate diverse data types seamlessly, and manage presentation variations, empowering developers to create more sophisticated and reliable LLM applications.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.
CoolCline
CoolCline is a proactive programming assistant that combines the best features of Cline, Roo Code, and Bao Cline. It seamlessly collaborates with your command line interface and editor, providing the most powerful AI development experience. It optimizes queries, allows quick switching of LLM Providers, and offers auto-approve options for actions. Users can configure LLM Providers, select different chat modes, perform file and editor operations, integrate with the command line, automate browser tasks, and extend capabilities through the Model Context Protocol (MCP). Context mentions help provide explicit context, and installation is easy through the editor's extension panel or by dragging and dropping the `.vsix` file. Local setup and development instructions are available for contributors.

llm-memorization
The 'llm-memorization' project is a tool designed to index, archive, and search conversations with a local LLM using a SQLite database enriched with automatically extracted keywords. It aims to provide personalized context at the start of a conversation by adding memory information to the initial prompt. The tool automates queries from local LLM conversational management libraries, offers a hybrid search function, enhances prompts based on posed questions, and provides an all-in-one graphical user interface for data visualization. It supports both French and English conversations and prompts for bilingual use.

TaskWeaver
TaskWeaver is a code-first agent framework designed for planning and executing data analytics tasks. It interprets user requests through code snippets, coordinates various plugins to execute tasks in a stateful manner, and preserves both chat history and code execution history. It supports rich data structures, customized algorithms, domain-specific knowledge incorporation, stateful execution, code verification, easy debugging, security considerations, and easy extension. TaskWeaver is easy to use with CLI and WebUI support, and it can be integrated as a library. It offers detailed documentation, demo examples, and citation guidelines.
For similar tasks
Awesome-LLM4EDA
LLM4EDA is a repository dedicated to showcasing the emerging progress in utilizing Large Language Models for Electronic Design Automation. The repository includes resources, papers, and tools that leverage LLMs to solve problems in EDA. It covers a wide range of applications such as knowledge acquisition, code generation, code analysis, verification, and large circuit models. The goal is to provide a comprehensive understanding of how LLMs can revolutionize the EDA industry by offering innovative solutions and new interaction paradigms.
DeGPT
DeGPT is a tool designed to optimize decompiler output using Large Language Models (LLM). It requires manual installation of specific packages and setting up API key for OpenAI. The tool provides functionality to perform optimization on decompiler output by running specific scripts.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
SinkFinder
SinkFinder + LLM is a closed-source semi-automatic vulnerability discovery tool that performs static code analysis on jar/war/zip files. It enhances the capability of LLM large models to verify path reachability and assess the trustworthiness score of the path based on the contextual code environment. Users can customize class and jar exclusions, depth of recursive search, and other parameters through command-line arguments. The tool generates rule.json configuration file after each run and requires configuration of the DASHSCOPE_API_KEY for LLM capabilities. The tool provides detailed logs on high-risk paths, LLM results, and other findings. Rules.json file contains sink rules for various vulnerability types with severity levels and corresponding sink methods.
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
air
air is an R formatter and language server written in Rust. It is currently in alpha stage, so users should expect breaking changes in both the API and formatting results. The tool draws inspiration from various sources like roslyn, swift, rust-analyzer, prettier, biome, and ruff. It provides formatters and language servers, influenced by design decisions from these tools. Users can install air using standalone installers for macOS, Linux, and Windows, which automatically add air to the PATH. Developers can also install the dev version of the air CLI and VS Code extension for further customization and development.
code-graph
Code-graph is a tool composed of FalkorDB Graph DB, Code-Graph-Backend, and Code-Graph-Frontend. It allows users to store and query graphs, manage backend logic, and interact with the website. Users can run the components locally by setting up environment variables and installing dependencies. The tool supports analyzing C & Python source files with plans to add support for more languages in the future. It provides a local repository analysis feature and a live demo accessible through a web browser.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.