
ArcticTraining
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs)
Stars: 56
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It offers modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data, enabling users to enhance LLM capabilities like code generation and complex reasoning with greater efficiency and flexibility.
README:

| Documentation | Blog |
- [2025/03] Snowflake Arctic Embed Joins ArcticTraining: Simple And Scalable Embedding Model Training
- [2025/01] ArcticTraining: Simplifying and Accelerating Post-Training for LLMs
- [2024/12] SwiftKV: Accelerating Enterprise LLM Workloads with Knowledge Preserving Compute Reduction
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It addresses challenges in current frameworks, such as limited support for rapid prototyping and the lack of native data generation tools, by offering modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data. These features enable users to enhance LLM capabilities, like code generation and complex reasoning, with greater efficiency and flexibility. Read more about ArcticTraining in our blog.
The projects folder contains various special projects we have released that build on-top of ArcticTraining. Each project includes it's own README and associated assets to get started:
To get started training a model with ArcticTraining, follow the steps below:
- Install the ArcticTraining package and its dependencies:
pip install arctic-training- Create a training recipe YAML that uses the built-in Supervised Fine-Tuning (SFT) trainer:
type: sft
micro_batch_size: 2
model:
name_or_path: meta-llama/Llama-3.1-8B-Instruct
data:
sources:
- HuggingFaceH4/ultrachat_200k
checkpoint:
- type: huggingface
save_end_of_training: true
output_dir: ./fine-tuned-model- Run the training recipe with the ArcticTraining CLI (see below). This will use the
DeepSpeedlauncher behind the scenes, you can pass any compatible DeepSpeed launcher arguments to the ArcticTraining CLI (e.g., --num_nodes, --num_gpus).
arctic_training path/to/sft-recipe.yamlTo customize the training workflow, you can modify the training recipe YAML we created in step 3 above. For example, you can change the model, dataset, checkpoint, or other settings to meet your specific requirements. A full list of configuration options can be found on the configuration documentation page.
If you want to create a new trainer, you can do so by subclassing the
Trainer or SFTTrainer classes and implementing the necessary
modifications. For example, you could create a new trainer from SFTTrainer
that uses a different loss function:
from arctic_training import SFTTrainer
class CustomTrainer(SFTTrainer):
name = "my_custom_trainer"
def loss(self, batch):
# Custom loss function implementation
return lossThis new trainer will be automatically registered with ArcticTraining when the
script containing the declaration of CustomTrainer is imported. By default,
ArcticTraining looks for a train.py in the current working directory to find
custom trainers. You can also specify a custom path to the trainers with the
code field in your training recipe:
type: my_custom_trainer
code: path/to/custom_trainers.py
model:
name_or_path: meta-llama/Llama-3.1-8B-Instruct
data:
sources:
- HuggingFaceH4/ultrachat_200kFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ArcticTraining
Similar Open Source Tools
ArcticTraining
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It offers modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data, enabling users to enhance LLM capabilities like code generation and complex reasoning with greater efficiency and flexibility.
archgw
Arch is an intelligent Layer 7 gateway designed to protect, observe, and personalize AI agents with APIs. It handles tasks related to prompts, including detecting jailbreak attempts, calling backend APIs, routing between LLMs, and managing observability. Built on Envoy Proxy, it offers features like function calling, prompt guardrails, traffic management, and observability. Users can build fast, observable, and personalized AI agents using Arch to improve speed, security, and personalization of GenAI apps.
rosa
ROSA is an AI Agent designed to interact with ROS-based robotics systems using natural language queries. It can generate system reports, read and parse ROS log files, adapt to new robots, and run various ROS commands using natural language. The tool is versatile for robotics research and development, providing an easy way to interact with robots and the ROS environment.

agentok
Agentok Studio is a tool built upon AG2, a powerful agent framework from Microsoft, offering intuitive visual tools to streamline the creation and management of complex agent-based workflows. It simplifies the process for creators and developers by generating native Python code with minimal dependencies, enabling users to create self-contained code that can be executed anywhere. The tool is currently under development and not recommended for production use, but contributions are welcome from the community to enhance its capabilities and functionalities.
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.
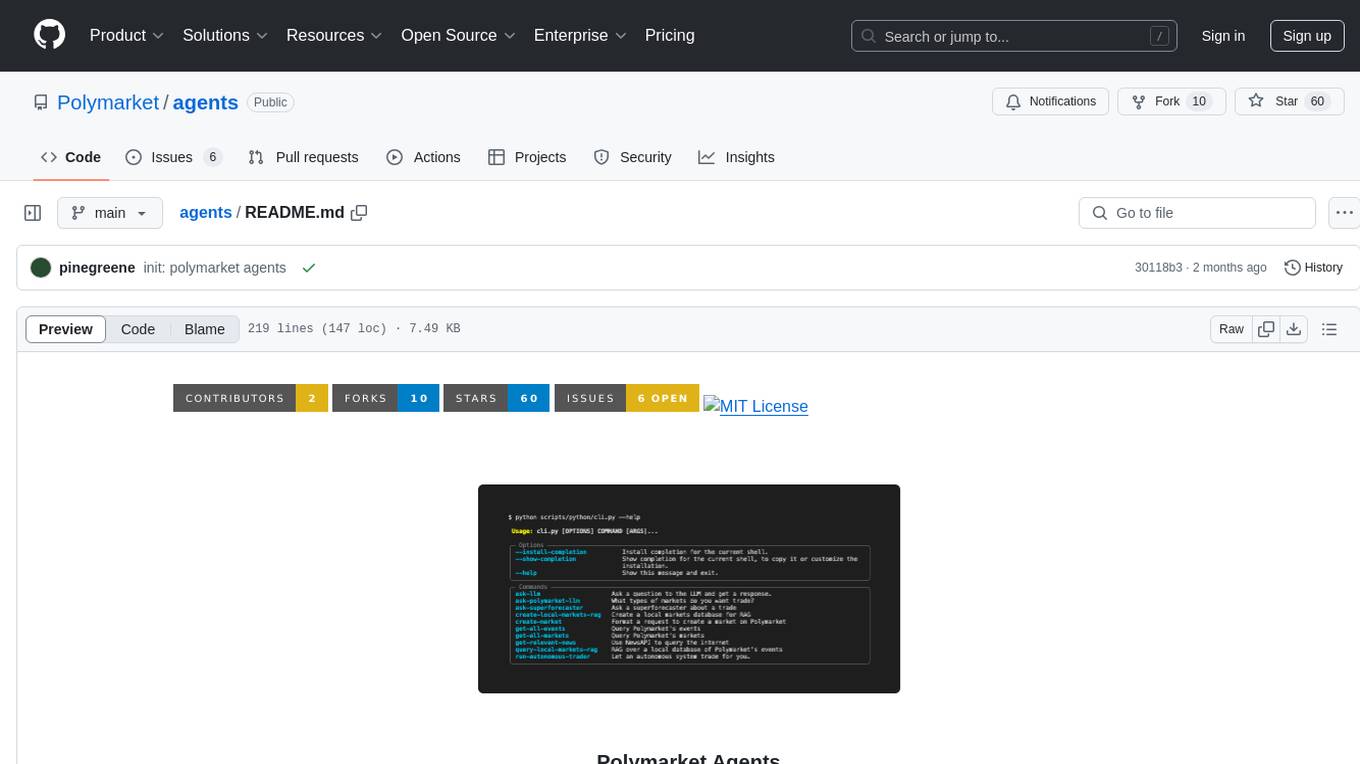
agents
Polymarket Agents is a developer framework and set of utilities for building AI agents to trade autonomously on Polymarket. It integrates with Polymarket API, provides AI agent utilities for prediction markets, supports local and remote RAG, sources data from various services, and offers comprehensive LLM tools for prompt engineering. The architecture features modular components like APIs and scripts for managing local environments, server set-up, and CLI for end-user commands.

lotus
LOTUS (LLMs Over Tables of Unstructured and Structured Data) is a query engine that provides a declarative programming model and an optimized query engine for reasoning-based query pipelines over structured and unstructured data. It offers a simple and intuitive Pandas-like API with semantic operators for fast and easy LLM-powered data processing. The tool implements a semantic operator programming model, allowing users to write AI-based pipelines with high-level logic and leaving the rest of the work to the query engine. LOTUS supports various semantic operators like sem_map, sem_filter, sem_extract, sem_agg, sem_topk, sem_join, sem_sim_join, and sem_search, enabling users to perform tasks like mapping records, filtering data, aggregating records, and more. The tool also supports different model classes such as LM, RM, and Reranker for language modeling, retrieval, and reranking tasks respectively.
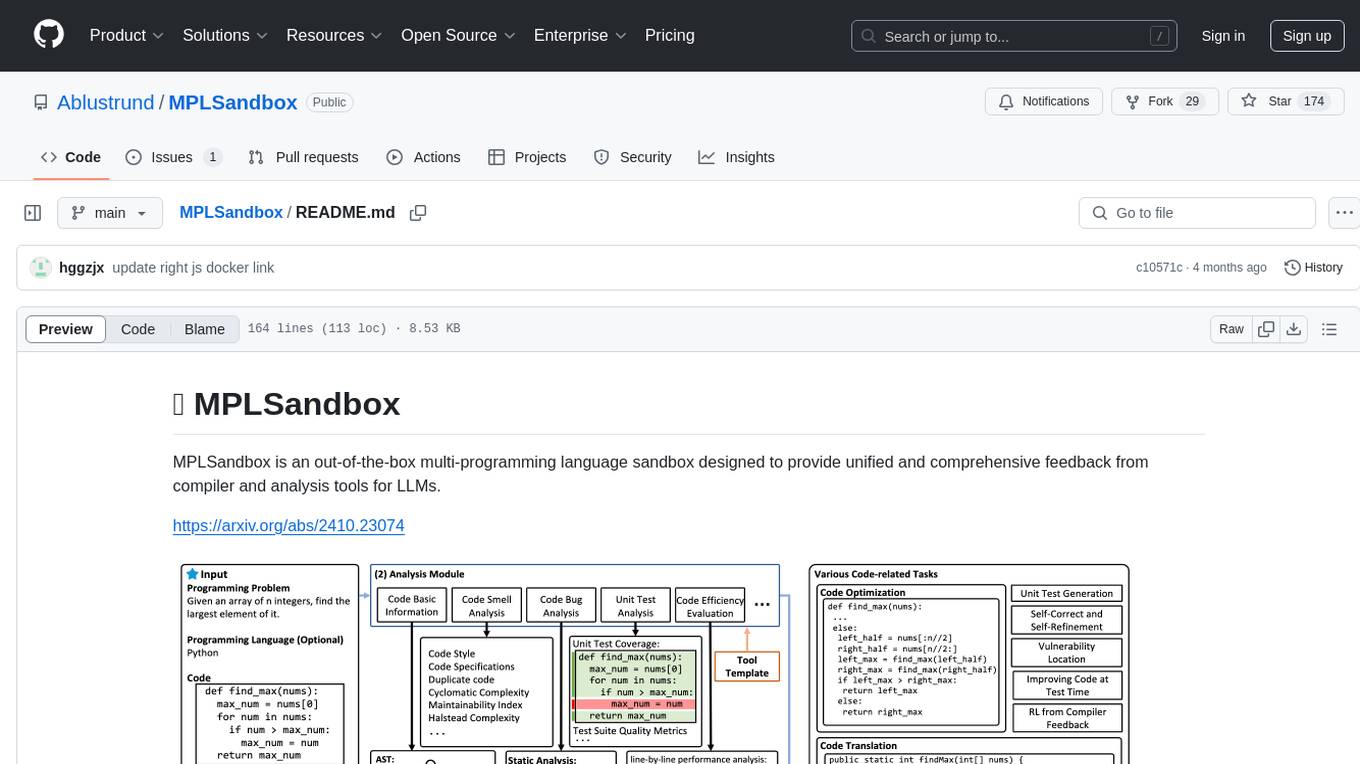
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
bionemo-framework
NVIDIA BioNeMo Framework is a collection of programming tools, libraries, and models for computational drug discovery. It accelerates building and adapting biomolecular AI models by providing domain-specific, optimized models and tooling for GPU-based computational resources. The framework offers comprehensive documentation and support for both community and enterprise users.

BitMat
BitMat is a Python package designed to optimize matrix multiplication operations by utilizing custom kernels written in Triton. It leverages the principles outlined in the "1bit-LLM Era" paper, specifically utilizing packed int8 data to enhance computational efficiency and performance in deep learning and numerical computing tasks.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.

llm-memorization
The 'llm-memorization' project is a tool designed to index, archive, and search conversations with a local LLM using a SQLite database enriched with automatically extracted keywords. It aims to provide personalized context at the start of a conversation by adding memory information to the initial prompt. The tool automates queries from local LLM conversational management libraries, offers a hybrid search function, enhances prompts based on posed questions, and provides an all-in-one graphical user interface for data visualization. It supports both French and English conversations and prompts for bilingual use.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**
agentdojo
AgentDojo is a dynamic environment designed to evaluate prompt injection attacks and defenses for large language models (LLM) agents. It provides a benchmark script to run different suites and tasks with specified LLM models, defenses, and attacks. The tool is under active development, and users can inspect the results through dedicated documentation pages and the Invariant Benchmark Registry.
For similar tasks
ArcticTraining
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It offers modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data, enabling users to enhance LLM capabilities like code generation and complex reasoning with greater efficiency and flexibility.
comfyui-photoshop
ComfyUI for Photoshop is a plugin that integrates with an AI-powered image generation system to enhance the Photoshop experience with features like unlimited generative fill, customizable back-end, AI-powered artistry, and one-click transformation. The plugin requires a minimum of 6GB graphics memory and 12GB RAM. Users can install the plugin and set up the ComfyUI workflow using provided links and files. Additionally, specific files like Check points, Loras, and Detailer Lora are required for different functionalities. Support and contributions are encouraged through GitHub.
Document-Knowledge-Mining-Solution-Accelerator
The Document Knowledge Mining Solution Accelerator leverages Azure OpenAI and Azure AI Document Intelligence to ingest, extract, and classify content from various assets, enabling chat-based insight discovery, analysis, and prompt guidance. It uses OCR and multi-modal LLM to extract information from documents like text, handwritten text, charts, graphs, tables, and form fields. Users can customize the technical architecture and data processing workflow. Key features include ingesting and extracting real-world entities, chat-based insights discovery, text and document data analysis, prompt suggestion guidance, and multi-modal information processing.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.
enhance_llm
The enhance_llm repository contains three main parts: 1. Vector model domain fine-tuning based on llama_index and qwen fine-tuning BGE vector model. 2. Large model domain fine-tuning based on PEFT fine-tuning qwen1.5-7b-chat, with sft and dpo. 3. High-order retrieval enhanced generation (RAG) system based on the above domain work, implementing a two-stage RAG system. It includes query rewriting, recall reordering, retrieval reordering, multi-turn dialogue, and more. The repository also provides hardware and environment configurations along with star history and licensing information.
fms-fsdp
The 'fms-fsdp' repository is a companion to the Foundation Model Stack, providing a (pre)training example to efficiently train FMS models, specifically Llama2, using native PyTorch features like FSDP for training and SDPA implementation of Flash attention v2. It focuses on leveraging FSDP for training efficiently, not as an end-to-end framework. The repo benchmarks training throughput on different GPUs, shares strategies, and provides installation and training instructions. It trained a model on IBM curated data achieving high efficiency and performance metrics.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.