
enhance_llm
大模型相关实践记录
Stars: 142
The enhance_llm repository contains three main parts: 1. Vector model domain fine-tuning based on llama_index and qwen fine-tuning BGE vector model. 2. Large model domain fine-tuning based on PEFT fine-tuning qwen1.5-7b-chat, with sft and dpo. 3. High-order retrieval enhanced generation (RAG) system based on the above domain work, implementing a two-stage RAG system. It includes query rewriting, recall reordering, retrieval reordering, multi-turn dialogue, and more. The repository also provides hardware and environment configurations along with star history and licensing information.
README:
微信公众号:西书北影。
本项目包含四部分:
1.向量模型垂域微调:基于llama_index和qwen微调BGE向量模型。http://t.csdnimg.cn/vSmRW
2.大模型垂域微调:基于PEFT微调qwen1.5-7b-chat,做了sft和dpo。http://t.csdnimg.cn/ndZ47
3.高阶检索增强生成(RAG)系统:基于以上垂域化工作,实现两阶段的RAG系统。增加了query改写、召回重排、检索重排、多轮对话等。http://t.csdnimg.cn/6nw4D
4.多模态大模型实现:基于qwen2和clip,使用MLP作为连接器,使得语言模型能懂图像。http://t.csdnimg.cn/9kDTy
5.deepresearch: 基于MCP工具开发的deepresearch的demo。支持同时检索本地知识库和网络信息。
显卡:L20(48GB) * 1 内存:100GB
1部分的Python环境配置是:
cd enhance_llm/ebedding_finetune
pip install -r requirements.txt
2.3部分的Python环境配置是:
cd enhance_llm
pip install -r requirements.txt
enhance_llm is licensed under Apache 2.0 License
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for enhance_llm
Similar Open Source Tools
enhance_llm
The enhance_llm repository contains three main parts: 1. Vector model domain fine-tuning based on llama_index and qwen fine-tuning BGE vector model. 2. Large model domain fine-tuning based on PEFT fine-tuning qwen1.5-7b-chat, with sft and dpo. 3. High-order retrieval enhanced generation (RAG) system based on the above domain work, implementing a two-stage RAG system. It includes query rewriting, recall reordering, retrieval reordering, multi-turn dialogue, and more. The repository also provides hardware and environment configurations along with star history and licensing information.

cosmos-rl
Cosmos-RL is a flexible and scalable Reinforcement Learning framework specialized for Physical AI applications. It provides a toolchain for large scale RL training workload with features like parallelism, asynchronous processing, low-precision training support, and a single-controller architecture. The system architecture includes Tensor Parallelism, Sequence Parallelism, Context Parallelism, FSDP Parallelism, and Pipeline Parallelism. It also utilizes a messaging system for coordinating policy and rollout replicas, along with dynamic NCCL Process Groups for fault-tolerant and elastic large-scale RL training.
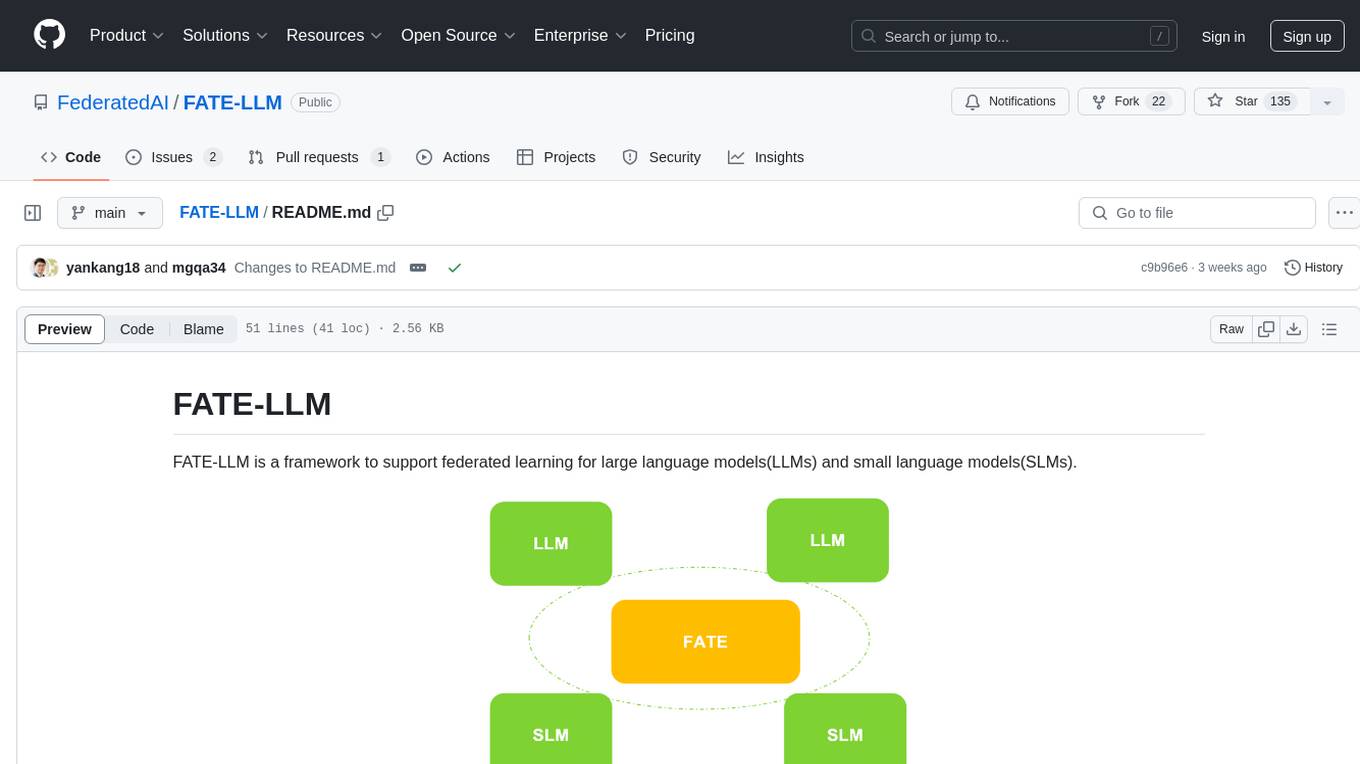
FATE-LLM
FATE-LLM is a framework supporting federated learning for large and small language models. It promotes training efficiency of federated LLMs using Parameter-Efficient methods, protects the IP of LLMs using FedIPR, and ensures data privacy during training and inference through privacy-preserving mechanisms.
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.

NeMo-Curator
NeMo Curator is a GPU-accelerated open-source framework designed for efficient large language model data curation. It provides scalable dataset preparation for tasks like foundation model pretraining, domain-adaptive pretraining, supervised fine-tuning, and parameter-efficient fine-tuning. The library leverages GPUs with Dask and RAPIDS to accelerate data curation, offering customizable and modular interfaces for pipeline expansion and model convergence. Key features include data download, text extraction, quality filtering, deduplication, downstream-task decontamination, distributed data classification, and PII redaction. NeMo Curator is suitable for curating high-quality datasets for large language model training.

crab
CRAB is a framework for building LLM agent benchmark environments in a Python-centric way. It is cross-platform and multi-environment, allowing the creation of agent environments supporting various deployment options. The framework offers easy-to-use configuration with the ability to add new actions and define environments seamlessly. CRAB also provides a novel benchmarking suite with tasks and evaluators defined in Python, along with a unique graph evaluator method for detailed metrics.
suaveui
SuaveUI is an experimental Progressive Web App chat user interface designed for interacting with local AI models. It provides a platform for users to easily communicate with AI models in a chat-like environment. The tool is built using React for the user interface and Node.js for the backend. Users can run SuaveUI using Docker or by cloning the repository and running a server. The project is still in the early alpha stage and is being actively developed to enhance its functionality and features.
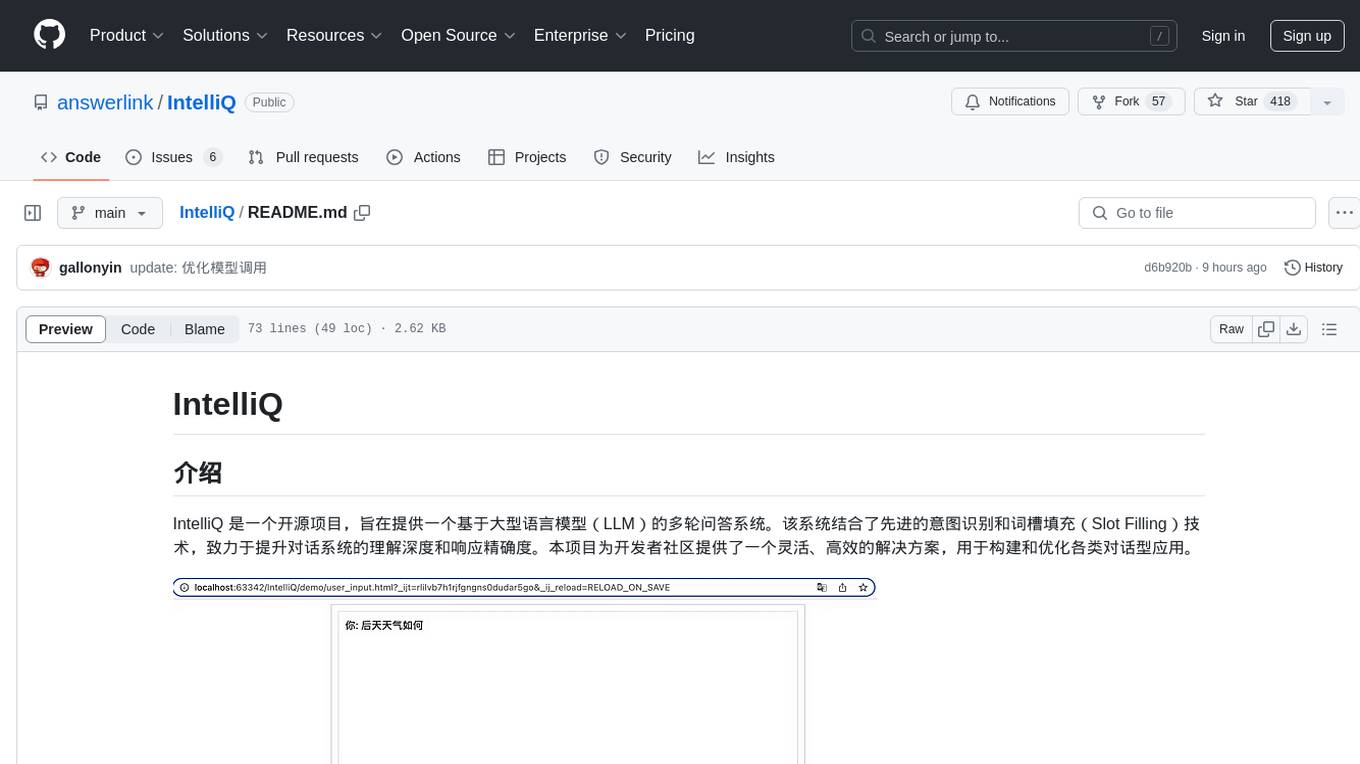
IntelliQ
IntelliQ is an open-source project aimed at providing a multi-turn question-answering system based on a large language model (LLM). The system combines advanced intent recognition and slot filling technology to enhance the depth of understanding and accuracy of responses in conversation systems. It offers a flexible and efficient solution for developers to build and optimize various conversational applications. The system features multi-turn dialogue management, intent recognition, slot filling, interface slot technology for real-time data retrieval and processing, adaptive learning for improving response accuracy and speed, and easy integration with detailed API documentation supporting multiple programming languages and platforms.
qgate-model
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.
OpenCatEsp32
OpenCat code running on BiBoard, a high-performance ESP32 quadruped robot development board. The board is mainly designed for developers and engineers working on multi-degree-of-freedom (MDOF) Multi-legged robots with up to 12 servos.
gemma
Gemma is a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. This repository contains an inference implementation and examples, based on the Flax and JAX frameworks. Gemma can run on CPU, GPU, and TPU, with model checkpoints available for download. It provides tutorials, reference implementations, and Colab notebooks for tasks like sampling and fine-tuning. Users can contribute to Gemma through bug reports and pull requests. The code is licensed under the Apache License, Version 2.0.
cad-recode
CAD-Recode is a 3D CAD reverse engineering method implemented in Python using the CadQuery library. It transforms point clouds into 3D CAD models by leveraging a pre-trained model and additional linear layers. The repository includes an inference demo for users to generate CAD models from point clouds. CAD-Recode has achieved state-of-the-art performance in CAD reconstruction benchmarks such as DeepCAD, Fusion360, and CC3D. Researchers and engineers can utilize this tool to reverse engineer CAD code from point clouds efficiently.
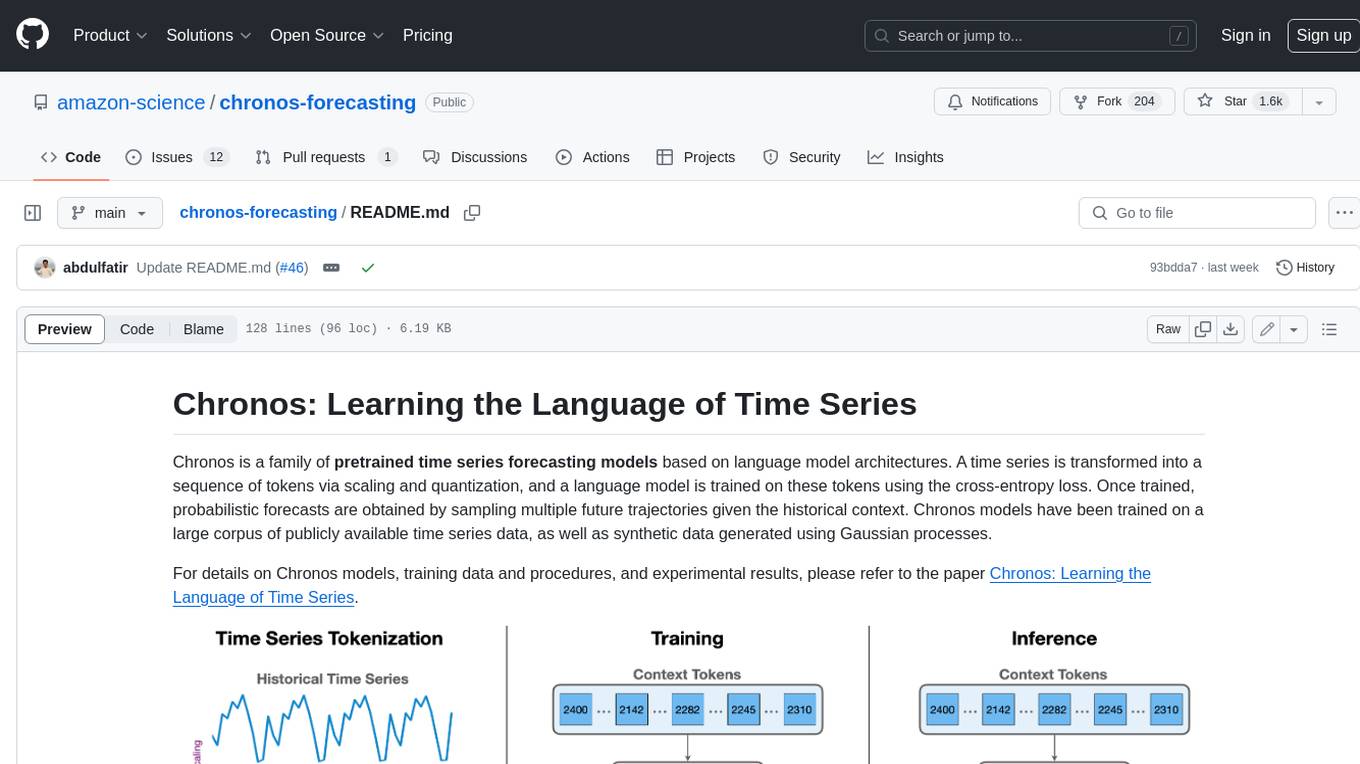
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.
fl_caption
FL Caption is an offline real-time subtitle software written in Flutter and Rust, powered by LLM and the Whisper inference framework based on candle. It allows users to download and unzip the software, select a suitable voice model, set language preferences, and start running subtitles. Users can troubleshoot model download issues and CUDA acceleration problems by following the provided instructions. FL Caption provides a user-friendly interface for generating subtitles in real-time.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.
For similar tasks
enhance_llm
The enhance_llm repository contains three main parts: 1. Vector model domain fine-tuning based on llama_index and qwen fine-tuning BGE vector model. 2. Large model domain fine-tuning based on PEFT fine-tuning qwen1.5-7b-chat, with sft and dpo. 3. High-order retrieval enhanced generation (RAG) system based on the above domain work, implementing a two-stage RAG system. It includes query rewriting, recall reordering, retrieval reordering, multi-turn dialogue, and more. The repository also provides hardware and environment configurations along with star history and licensing information.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

one-click-llms
The one-click-llms repository provides templates for quickly setting up an API for language models. It includes advanced inferencing scripts for function calling and offers various models for text generation and fine-tuning tasks. Users can choose between Runpod and Vast.AI for different GPU configurations, with recommendations for optimal performance. The repository also supports Trelis Research and offers templates for different model sizes and types, including multi-modal APIs and chat models.

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.
fms-fsdp
The 'fms-fsdp' repository is a companion to the Foundation Model Stack, providing a (pre)training example to efficiently train FMS models, specifically Llama2, using native PyTorch features like FSDP for training and SDPA implementation of Flash attention v2. It focuses on leveraging FSDP for training efficiently, not as an end-to-end framework. The repo benchmarks training throughput on different GPUs, shares strategies, and provides installation and training instructions. It trained a model on IBM curated data achieving high efficiency and performance metrics.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.