
magika
Fast and accurate AI powered file content types detection
Stars: 10128
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.
README:





![]()
![]()
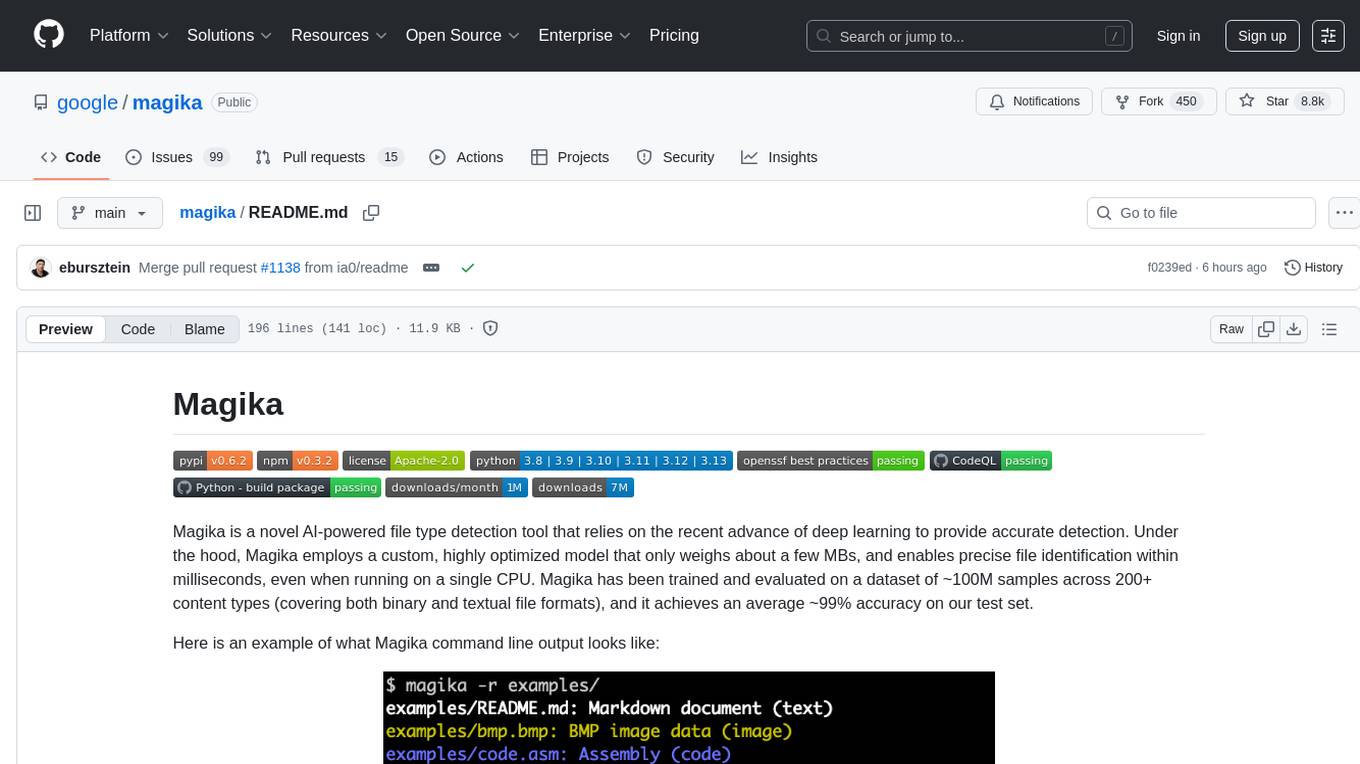
Magika is a novel AI-powered file type detection tool that relies on the recent advance of deep learning to provide accurate detection. Under the hood, Magika employs a custom, highly optimized model that only weighs about a few MBs, and enables precise file identification within milliseconds, even when running on a single CPU. Magika has been trained and evaluated on a dataset of ~100M samples across 200+ content types (covering both binary and textual file formats), and it achieves an average ~99% accuracy on our test set.
Here is an example of what Magika command line output looks like:

Magika is used at scale to help improve Google users' safety by routing Gmail, Drive, and Safe Browsing files to the proper security and content policy scanners, processing hundreds billions samples on a weekly basis. Magika has also been integrated with VirusTotal (example) and abuse.ch (example).
{kind=link}
{kind=link}
For more context you can read our initial announcement post on Google's OSS blog, you can consult Magika's website, and you can read more in our research paper, published at the IEEE/ACM International Conference on Software Engineering (ICSE) 2025.
You can try Magika without installing anything by using our web demo, which runs locally in your browser!
- Available as a command line tool written in Rust, a Python API, and additional bindings for Rust, JavaScript/TypeScript (with an experimental npm package, which powers our web demo), and GoLang (WIP).
- Trained and evaluated on a dataset of ~100M files across 200+ content types.
- On our test set, Magika achieves ~99% average precision and recall, outperforming existing approaches -- especially on textual content types.
- After the model is loaded (which is a one-off overhead), the inference time is about 5ms per file, even when run on a single CPU.
- You can invoke Magika with even thousands of files at the same time. You can also use
-rfor recursively scanning a directory. - Near-constant inference time, independently from the file size; Magika only uses a limited subset of the file's content.
- Magika uses a per-content-type threshold system that determines whether to "trust" the prediction for the model, or whether to return a generic label, such as "Generic text document" or "Unknown binary data".
- The tolerance to errors can be controlled via different prediction modes, such as
high-confidence,medium-confidence, andbest-guess. - The client and the bindings are already open source, and more is coming soon!
Magika ships a CLI written in Rust, and can be installed in several ways.
Via magika python package:
pipx install magikaVia brew (macOS / Linux)
brew install magikaVia installer script:
curl -LsSf https://securityresearch.google/magika/install.sh | shor
powershell -ExecutionPolicy Bypass -c "irm https://securityresearch.google/magika/install.ps1 | iex"pip install magikanpm install magikaHere you can find a number of quick examples just to get you started.
To learn about Magika's inner workings, see the Core Concepts section of Magika's website.
% cd tests_data/basic && magika -r * | head
asm/code.asm: Assembly (code)
batch/simple.bat: DOS batch file (code)
c/code.c: C source (code)
css/code.css: CSS source (code)
csv/magika_test.csv: CSV document (code)
dockerfile/Dockerfile: Dockerfile (code)
docx/doc.docx: Microsoft Word 2007+ document (document)
docx/magika_test.docx: Microsoft Word 2007+ document (document)
eml/sample.eml: RFC 822 mail (text)
empty/empty_file: Empty file (inode)% magika ./tests_data/basic/python/code.py --json
[
{
"path": "./tests_data/basic/python/code.py",
"result": {
"status": "ok",
"value": {
"dl": {
"description": "Python source",
"extensions": [
"py",
"pyi"
],
"group": "code",
"is_text": true,
"label": "python",
"mime_type": "text/x-python"
},
"output": {
"description": "Python source",
"extensions": [
"py",
"pyi"
],
"group": "code",
"is_text": true,
"label": "python",
"mime_type": "text/x-python"
},
"score": 0.996999979019165
}
}
}
]% cat tests_data/basic/ini/doc.ini | magika -
-: INI configuration file (text)% magika --help
Determines file content types using AI
Usage: magika [OPTIONS] [PATH]...
Arguments:
[PATH]...
List of paths to the files to analyze.
Use a dash (-) to read from standard input (can only be used once).
Options:
-r, --recursive
Identifies files within directories instead of identifying the directory itself
--no-dereference
Identifies symbolic links as is instead of identifying their content by following them
--colors
Prints with colors regardless of terminal support
--no-colors
Prints without colors regardless of terminal support
-s, --output-score
Prints the prediction score in addition to the content type
-i, --mime-type
Prints the MIME type instead of the content type description
-l, --label
Prints a simple label instead of the content type description
--json
Prints in JSON format
--jsonl
Prints in JSONL format
--format <CUSTOM>
Prints using a custom format (use --help for details).
The following placeholders are supported:
%p The file path
%l The unique label identifying the content type
%d The description of the content type
%g The group of the content type
%m The MIME type of the content type
%e Possible file extensions for the content type
%s The score of the content type for the file
%S The score of the content type for the file in percent
%b The model output if overruled (empty otherwise)
%% A literal %
-h, --help
Print help (see a summary with '-h')
-V, --version
Print versionFor more examples and documentation about the CLI, see https://crates.io/crates/magika-cli.
>>> from magika import Magika
>>> m = Magika()
>>> res = m.identify_bytes(b'function log(msg) {console.log(msg);}')
>>> print(res.output.label)
javascript>>> from magika import Magika
>>> m = Magika()
>>> res = m.identify_path('./tests_data/basic/ini/doc.ini')
>>> print(res.output.label)
ini>>> from magika import Magika
>>> m = Magika()
>>> with open('./tests_data/basic/ini/doc.ini', 'rb') as f:
>>> res = m.identify_stream(f)
>>> print(res.output.label)
iniFor more examples and documentation about the Python module, see the Python Magika module section.
Please consult Magika's website for detailed documentation about:
- Core Concepts
- How Magika works
- Models & content types
- Prediction modes
- Understanding the output
- CLI & Bindings (Python module, JavaScript module, ...)
- Contributing
- FAQ
- ...
Please contact us directly at [email protected].
Apache 2.0; see LICENSE for details.
This project is not an official Google project. It is not supported by Google and Google specifically disclaims all warranties as to its quality, merchantability, or fitness for a particular purpose.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for magika
Similar Open Source Tools
magika
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.

raglite
RAGLite is a Python toolkit for Retrieval-Augmented Generation (RAG) with PostgreSQL or SQLite. It offers configurable options for choosing LLM providers, database types, and rerankers. The toolkit is fast and permissive, utilizing lightweight dependencies and hardware acceleration. RAGLite provides features like PDF to Markdown conversion, multi-vector chunk embedding, optimal semantic chunking, hybrid search capabilities, adaptive retrieval, and improved output quality. It is extensible with a built-in Model Context Protocol server, customizable ChatGPT-like frontend, document conversion to Markdown, and evaluation tools. Users can configure RAGLite for various tasks like configuring, inserting documents, running RAG pipelines, computing query adapters, evaluating performance, running MCP servers, and serving frontends.

chromem-go
chromem-go is an embeddable vector database for Go with a Chroma-like interface and zero third-party dependencies. It enables retrieval augmented generation (RAG) and similar embeddings-based features in Go apps without the need for a separate database. The focus is on simplicity and performance for common use cases, allowing querying of documents with minimal memory allocations. The project is in beta and may introduce breaking changes before v1.0.0.
ollama-r
The Ollama R library provides an easy way to integrate R with Ollama for running language models locally on your machine. It supports working with standard data structures for different LLMs, offers various output formats, and enables integration with other libraries/tools. The library uses the Ollama REST API and requires the Ollama app to be installed, with GPU support for accelerating LLM inference. It is inspired by Ollama Python and JavaScript libraries, making it familiar for users of those languages. The installation process involves downloading the Ollama app, installing the 'ollamar' package, and starting the local server. Example usage includes testing connection, downloading models, generating responses, and listing available models.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.

wllama
Wllama is a WebAssembly binding for llama.cpp, a high-performance and lightweight language model library. It enables you to run inference directly on the browser without the need for a backend or GPU. Wllama provides both high-level and low-level APIs, allowing you to perform various tasks such as completions, embeddings, tokenization, and more. It also supports model splitting, enabling you to load large models in parallel for faster download. With its Typescript support and pre-built npm package, Wllama is easy to integrate into your React Typescript projects.
palimpzest
Palimpzest (PZ) is a tool for managing and optimizing workloads, particularly for data processing tasks. It provides a CLI tool and Python demos for users to register datasets, run workloads, and access results. Users can easily initialize their system, register datasets, and manage configurations using the CLI commands provided. Palimpzest also supports caching intermediate results and configuring for parallel execution with remote services like OpenAI and together.ai. The tool aims to streamline the workflow of working with datasets and optimizing performance for data extraction tasks.
basic-memory
Basic Memory is a tool that enables users to build persistent knowledge through natural conversations with Large Language Models (LLMs) like Claude. It uses the Model Context Protocol (MCP) to allow compatible LLMs to read and write to a local knowledge base stored in simple Markdown files on the user's computer. The tool facilitates creating structured notes during conversations, maintaining a semantic knowledge graph, and keeping all data local and under user control. Basic Memory aims to address the limitations of ephemeral LLM interactions by providing a structured, bi-directional, and locally stored knowledge management solution.

refact-lsp
Refact Agent is a small executable written in Rust as part of the Refact Agent project. It lives inside your IDE to keep AST and VecDB indexes up to date, supporting connection graphs between definitions and usages in popular programming languages. It functions as an LSP server, offering code completion, chat functionality, and integration with various tools like browsers, databases, and debuggers. Users can interact with it through a Text UI in the command line.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
aimeos-laravel
Aimeos Laravel is a professional, full-featured, and ultra-fast Laravel ecommerce package that can be easily integrated into existing Laravel applications. It offers a wide range of features including multi-vendor, multi-channel, and multi-warehouse support, fast performance, support for various product types, subscriptions with recurring payments, multiple payment gateways, full RTL support, flexible pricing options, admin backend, REST and GraphQL APIs, modular structure, SEO optimization, multi-language support, AI-based text translation, mobile optimization, and high-quality source code. The package is highly configurable and extensible, making it suitable for e-commerce SaaS solutions, marketplaces, and online shops with millions of vendors.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.
For similar tasks
magika
Magika is a novel AI-powered file type detection tool that relies on deep learning to provide accurate detection. It employs a custom, highly optimized model to enable precise file identification within milliseconds. Trained on a dataset of ~100M samples across 200+ content types, achieving an average ~99% accuracy. Used at scale by Google to improve user safety by routing files to security scanners. Available as a command line tool in Rust, Python API, and bindings for Rust, JavaScript/TypeScript, and GoLang.
For similar jobs

ciso-assistant-community
CISO Assistant is a tool that helps organizations manage their cybersecurity posture and compliance. It provides a centralized platform for managing security controls, threats, and risks. CISO Assistant also includes a library of pre-built frameworks and tools to help organizations quickly and easily implement best practices.
PurpleLlama
Purple Llama is an umbrella project that aims to provide tools and evaluations to support responsible development and usage of generative AI models. It encompasses components for cybersecurity and input/output safeguards, with plans to expand in the future. The project emphasizes a collaborative approach, borrowing the concept of purple teaming from cybersecurity, to address potential risks and challenges posed by generative AI. Components within Purple Llama are licensed permissively to foster community collaboration and standardize the development of trust and safety tools for generative AI.
vpnfast.github.io
VPNFast is a lightweight and fast VPN service provider that offers secure and private internet access. With VPNFast, users can protect their online privacy, bypass geo-restrictions, and secure their internet connection from hackers and snoopers. The service provides high-speed servers in multiple locations worldwide, ensuring a reliable and seamless VPN experience for users. VPNFast is easy to use, with a user-friendly interface and simple setup process. Whether you're browsing the web, streaming content, or accessing sensitive information, VPNFast helps you stay safe and anonymous online.
taranis-ai
Taranis AI is an advanced Open-Source Intelligence (OSINT) tool that leverages Artificial Intelligence to revolutionize information gathering and situational analysis. It navigates through diverse data sources like websites to collect unstructured news articles, utilizing Natural Language Processing and Artificial Intelligence to enhance content quality. Analysts then refine these AI-augmented articles into structured reports that serve as the foundation for deliverables such as PDF files, which are ultimately published.
NightshadeAntidote
Nightshade Antidote is an image forensics tool used to analyze digital images for signs of manipulation or forgery. It implements several common techniques used in image forensics including metadata analysis, copy-move forgery detection, frequency domain analysis, and JPEG compression artifacts analysis. The tool takes an input image, performs analysis using the above techniques, and outputs a report summarizing the findings.
h4cker
This repository is a comprehensive collection of cybersecurity-related references, scripts, tools, code, and other resources. It is carefully curated and maintained by Omar Santos. The repository serves as a supplemental material provider to several books, video courses, and live training created by Omar Santos. It encompasses over 10,000 references that are instrumental for both offensive and defensive security professionals in honing their skills.

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.
admyral
Admyral is an open-source Cybersecurity Automation & Investigation Assistant that provides a unified console for investigations and incident handling, workflow automation creation, automatic alert investigation, and next step suggestions for analysts. It aims to tackle alert fatigue and automate security workflows effectively by offering features like workflow actions, AI actions, case management, alert handling, and more. Admyral combines security automation and case management to streamline incident response processes and improve overall security posture. The tool is open-source, transparent, and community-driven, allowing users to self-host, contribute, and collaborate on integrations and features.