
open-repo-wiki
You don’t need to read the code to understand how to build!
Stars: 137
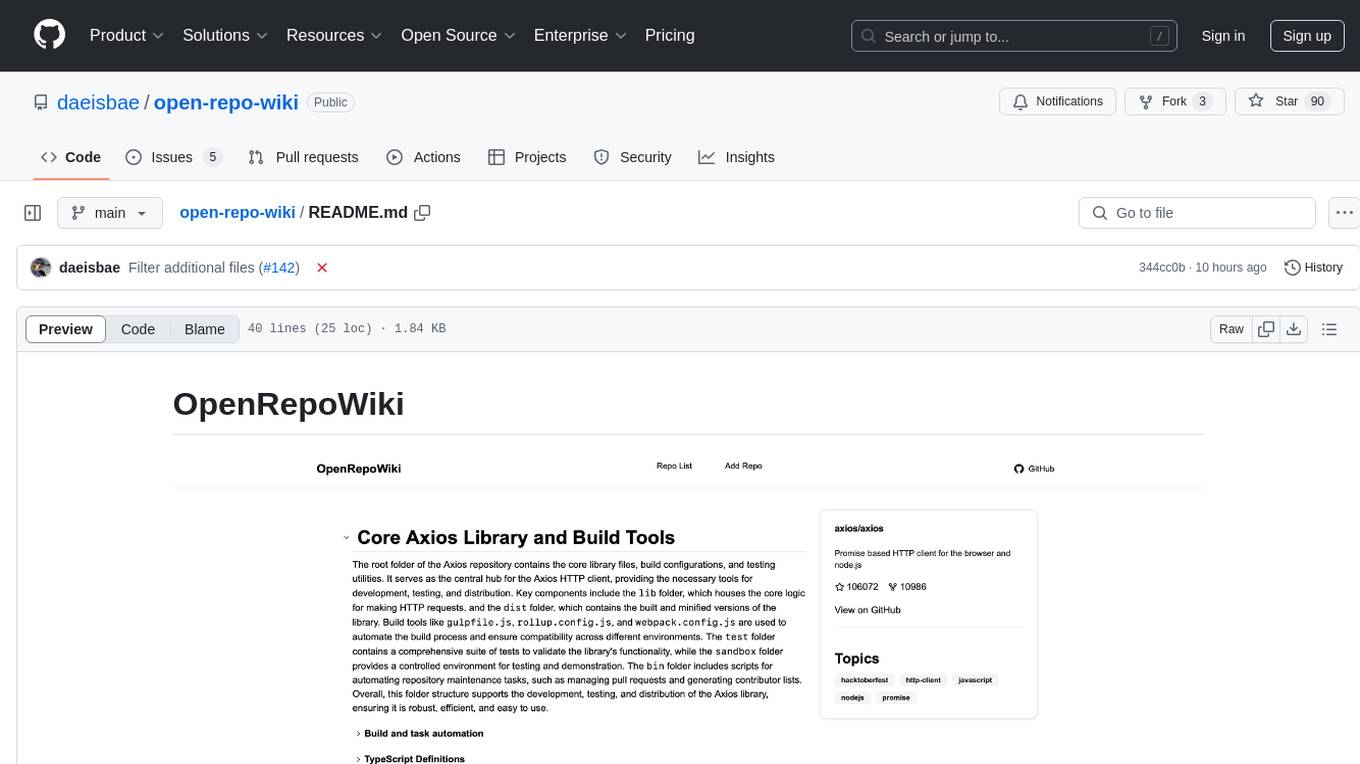
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.
README:

OpenRepoWiki is a tool that automatically generates a comprehensive wiki page for any given GitHub repository. I hate reading code, but I want to learn how to build stuffs from websites to databases. That's why I built OpenRepoWiki, where we can understand the purpose of that files and folders of a particular repository.
- Automated Wiki Generation: Creates a summarized overview of a repository's purpose, functionality, and core components.
- Codebase Analysis: Analyzes the code structure, identifies key files and functions, and explains their roles within the project.
- Link To That Code Block: The sky-blue highlighted code block will point to the Github link where it referenced.
- Either Google AI Studio or Deepseek API Key
- PostgreSQL (For storing the summarized repository information)
- Github API Key (To get more quota requesting the repository data)
- Amazon S3 (You can ignore the parameters if you are going to use it locally. You need to use certificate for your Database if you are going to host it.)
- Docker (If you are hosting locally)
- Copy
.env.exampleto.env - Configure all the variables given in
.env - Run
docker compose upordocker compose up -dto hide the output
- Create PostgreSQL instance
- Copy
.env.exampleto.env - Configure all the variables given in
.env - Install all the dependencies (
npm install) - Initialize the database by typing (
npm run db:init). If this does not work, you can install database manager GUI, connect to the database then manually execute SQL src/db/migrations/create_tables.sql - Build the server (
npm run build) - Run (
npm start)
- It's recommended if you can run bigger LLM than 14b parameter.
- You do not need to provide the API KEY
- Set LLM_PROVIDER to Ollama (It is going to connect to default ollama endpoint)
- Set LLM_MODELNAME to the model name you can see from Ollama using the command
ollama ls - It is recommended to set TOKEN_PROCESSING_CHARACTER_LIMIT between 10000-20000 (Approx 300-600 lines of code) if you are using low param LLM (ex. 8b, 14b)
Example:
LLM_PROVIDER=ollama
LLM_APIKEY=
LLM_MODELNAME=qwen2.5:14b
[!CAUTION] Before using this, it can easily use 1 million input / output tokens per Repository. Hence it is recommended to use cheaper LLM.
- If you are going to host it locally, you will only need to configure the Docker PostgreSQL container, Github API Key, and Google AI Studio or Deepseek API Key
Refer Documentation
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for open-repo-wiki
Similar Open Source Tools
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.
webwhiz
WebWhiz is an open-source tool that allows users to train ChatGPT on website data to build AI chatbots for customer queries. It offers easy integration, data-specific responses, regular data updates, no-code builder, chatbot customization, fine-tuning, and offline messaging. Users can create and train chatbots in a few simple steps by entering their website URL, automatically fetching and preparing training data, training ChatGPT, and embedding the chatbot on their website. WebWhiz can crawl websites monthly, collect text data and metadata, and process text data using tokens. Users can train custom data, but bringing custom open AI keys is not yet supported. The tool has no limitations on context size but may limit the number of pages based on the chosen plan. WebWhiz SDK is available on NPM, CDNs, and GitHub, and users can self-host it using Docker or manual setup involving MongoDB, Redis, Node, Python, and environment variables setup. For any issues, users can contact [email protected].
holohub
Holohub is a central repository for the NVIDIA Holoscan AI sensor processing community to share reference applications, operators, tutorials, and benchmarks. It includes example applications, community components, package configurations, and tutorials. Users and developers of the Holoscan platform are invited to reuse and contribute to this repository. The repository provides detailed instructions on prerequisites, building, running applications, contributing, and glossary terms. It also offers a searchable catalog of available components on the Holoscan SDK User Guide website.
AgentIQ
AgentIQ is a flexible library designed to seamlessly integrate enterprise agents with various data sources and tools. It enables true composability by treating agents, tools, and workflows as simple function calls. With features like framework agnosticism, reusability, rapid development, profiling, observability, evaluation system, user interface, and MCP compatibility, AgentIQ empowers developers to move quickly, experiment freely, and ensure reliability across agent-driven projects.

coral-cloud
Coral Cloud Resorts is a sample hospitality application that showcases Data Cloud, Agents, and Prompts. It provides highly personalized guest experiences through smart automation, content generation, and summarization. The app requires licenses for Data Cloud, Agents, Prompt Builder, and Einstein for Sales. Users can activate features, deploy metadata, assign permission sets, import sample data, and troubleshoot common issues. Additionally, the repository offers integration with modern web development tools like Prettier, ESLint, and pre-commit hooks for code formatting and linting.

OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.
qrev
QRev is an open-source alternative to Salesforce, offering AI agents to scale sales organizations infinitely. It aims to provide digital workers for various sales roles or a superagent named Qai. The tech stack includes TypeScript for frontend, NodeJS for backend, MongoDB for app server database, ChromaDB for vector database, SQLite for AI server SQL relational database, and Langchain for LLM tooling. The tool allows users to run client app, app server, and AI server components. It requires Node.js and MongoDB to be installed, and provides detailed setup instructions in the README file.

unitycatalog
Unity Catalog is an open and interoperable catalog for data and AI, supporting multi-format tables, unstructured data, and AI assets. It offers plugin support for extensibility and interoperates with Delta Sharing protocol. The catalog is fully open with OpenAPI spec and OSS implementation, providing unified governance for data and AI with asset-level access control enforced through REST APIs.
dravid
Dravid (DRD) is an advanced, AI-powered CLI coding framework designed to follow user instructions until the job is completed, including fixing errors. It can generate code, fix errors, handle image queries, manage file operations, integrate with external APIs, and provide a development server with error handling. Dravid is extensible and requires Python 3.7+ and CLAUDE_API_KEY. Users can interact with Dravid through CLI commands for various tasks like creating projects, asking questions, generating content, handling metadata, and file-specific queries. It supports use cases like Next.js project development, working with existing projects, exploring new languages, Ruby on Rails project development, and Python project development. Dravid's project structure includes directories for source code, CLI modules, API interaction, utility functions, AI prompt templates, metadata management, and tests. Contributions are welcome, and development setup involves cloning the repository, installing dependencies with Poetry, setting up environment variables, and using Dravid for project enhancements.

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.
describer
Describer is a tool that analyzes codebases using AI to generate architectural overviews, documentation, explanations, bug reports, and more. It scans all files in a directory and uses Google's Gemini AI to provide insights such as markdown architectural overviews, codebase summaries, code pattern analysis, codebase structure documentation, bug identification, and test idea generation. The tool respects .gitignore rules by default but allows users to include/exclude specific files or patterns for analysis.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
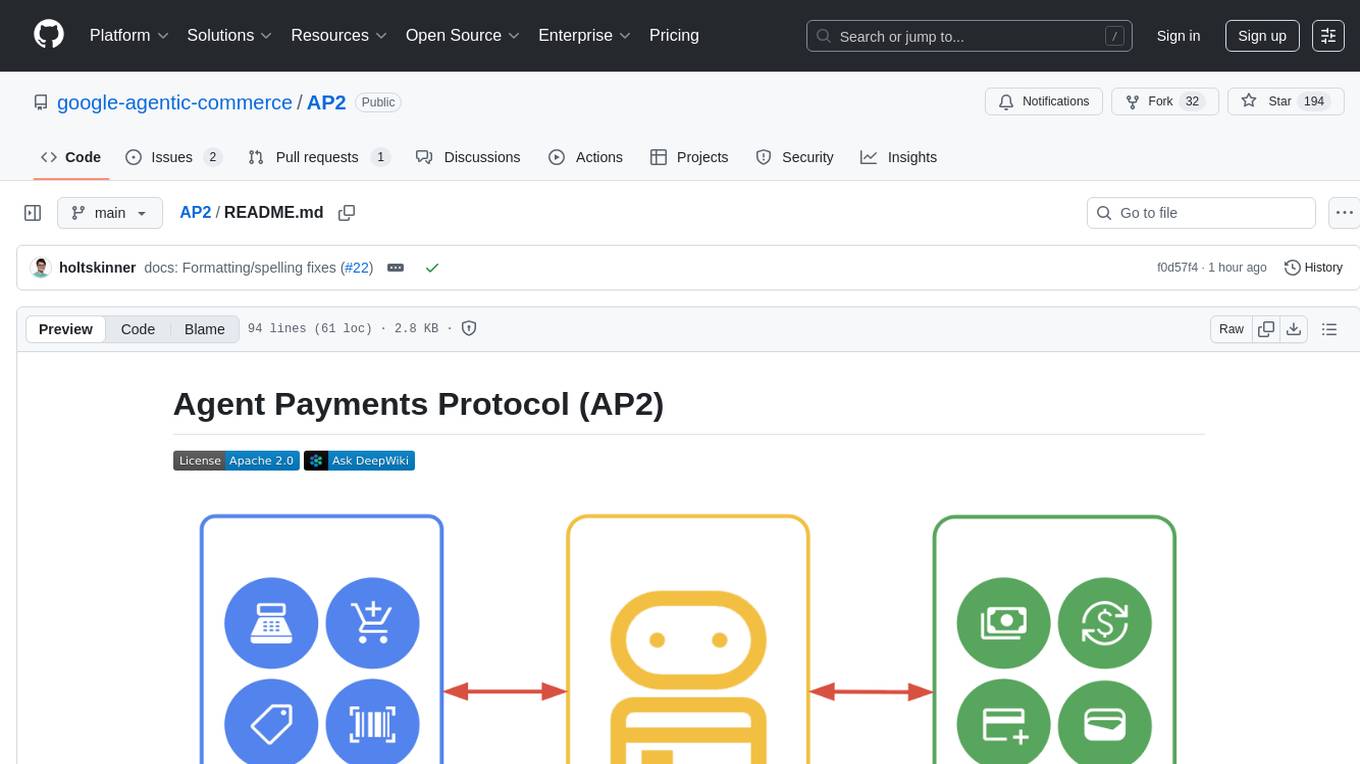
AP2
The Agent Payments Protocol (AP2) repository contains code samples and demos showcasing the protocol. It includes curated scenarios demonstrating key components, utilizing the Agent Development Kit (ADK) and Gemini 2.5 Flash. Users are free to use any tools to build agents. The repository features various agents and servers, with source code located in specific directories. Users can run scenarios by following README instructions and using run scripts. Additionally, the repository provides guidance on setting up prerequisites, obtaining a Google API key, and installing the AP2 types package.
MCP2Lambda
MCP2Lambda is a server that acts as a bridge between MCP clients and AWS Lambda functions, allowing generative AI models to access and run Lambda functions as tools. It enables Large Language Models (LLMs) to interact with Lambda functions without code changes, providing access to private resources, AWS services, private networks, and the public internet. The server supports autodiscovery of Lambda functions and their invocation by name with parameters. It standardizes AI model access to external tools using the MCP protocol.
srcbook
Srcbook is an open-source interactive programming environment for TypeScript that allows users to create, run, and share reproducible programs and ideas. It features AI capabilities for exploring and iterating on ideas, supports exporting to valid markdown format, and enables diagraming with mermaid for rich annotations. Users can locally execute programs through a web interface, powered by Node.js under the Apache2 license.
For similar tasks
Awesome-LLM4EDA
LLM4EDA is a repository dedicated to showcasing the emerging progress in utilizing Large Language Models for Electronic Design Automation. The repository includes resources, papers, and tools that leverage LLMs to solve problems in EDA. It covers a wide range of applications such as knowledge acquisition, code generation, code analysis, verification, and large circuit models. The goal is to provide a comprehensive understanding of how LLMs can revolutionize the EDA industry by offering innovative solutions and new interaction paradigms.
DeGPT
DeGPT is a tool designed to optimize decompiler output using Large Language Models (LLM). It requires manual installation of specific packages and setting up API key for OpenAI. The tool provides functionality to perform optimization on decompiler output by running specific scripts.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
SinkFinder
SinkFinder + LLM is a closed-source semi-automatic vulnerability discovery tool that performs static code analysis on jar/war/zip files. It enhances the capability of LLM large models to verify path reachability and assess the trustworthiness score of the path based on the contextual code environment. Users can customize class and jar exclusions, depth of recursive search, and other parameters through command-line arguments. The tool generates rule.json configuration file after each run and requires configuration of the DASHSCOPE_API_KEY for LLM capabilities. The tool provides detailed logs on high-risk paths, LLM results, and other findings. Rules.json file contains sink rules for various vulnerability types with severity levels and corresponding sink methods.
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
air
air is an R formatter and language server written in Rust. It is currently in alpha stage, so users should expect breaking changes in both the API and formatting results. The tool draws inspiration from various sources like roslyn, swift, rust-analyzer, prettier, biome, and ruff. It provides formatters and language servers, influenced by design decisions from these tools. Users can install air using standalone installers for macOS, Linux, and Windows, which automatically add air to the PATH. Developers can also install the dev version of the air CLI and VS Code extension for further customization and development.
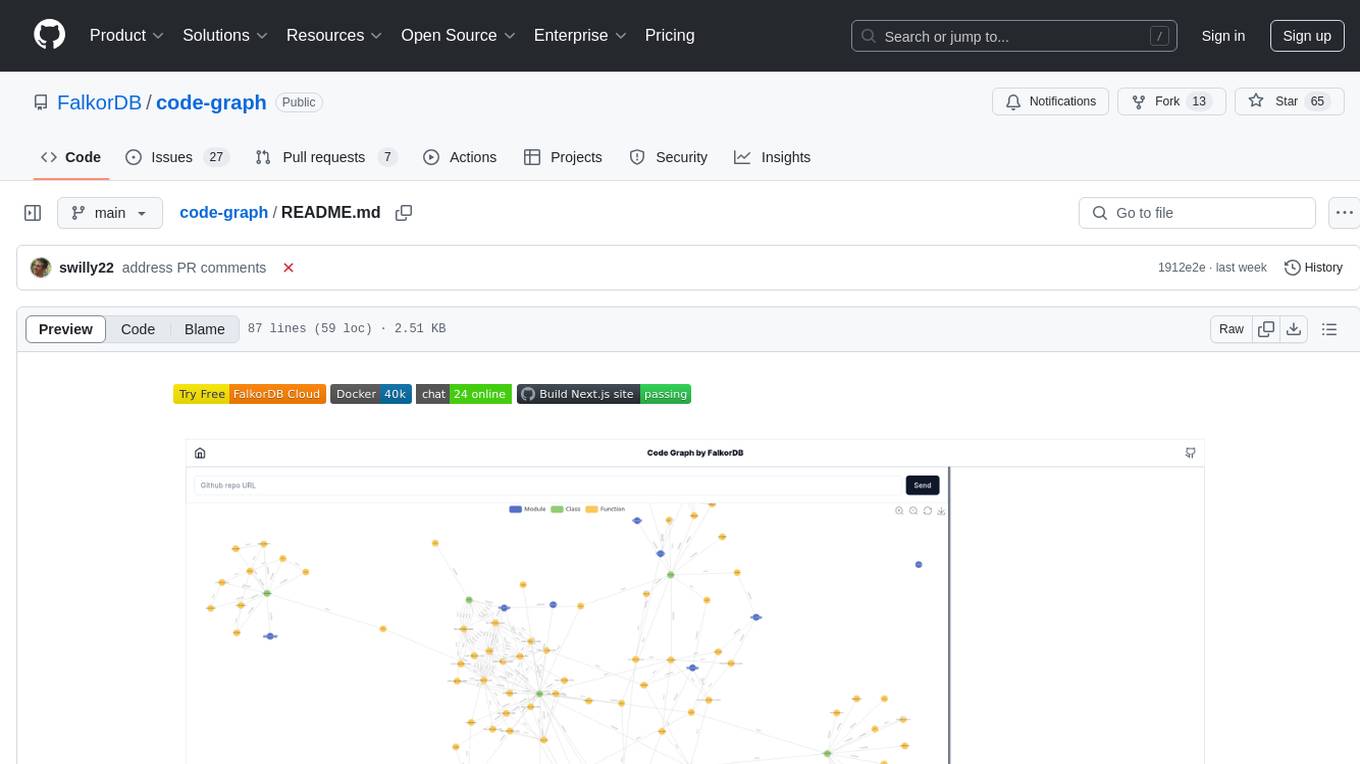
code-graph
Code-graph is a tool composed of FalkorDB Graph DB, Code-Graph-Backend, and Code-Graph-Frontend. It allows users to store and query graphs, manage backend logic, and interact with the website. Users can run the components locally by setting up environment variables and installing dependencies. The tool supports analyzing C & Python source files with plans to add support for more languages in the future. It provides a local repository analysis feature and a live demo accessible through a web browser.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.