
mint-bench
Official Repo for ICLR 2024 paper MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback by Xingyao Wang*, Zihan Wang*, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng and Heng Ji.
Stars: 84
MINT benchmark aims to evaluate LLMs' ability to solve tasks with multi-turn interactions by (1) using tools and (2) leveraging natural language feedback.
README:
Official Repo for paper MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback by Xingyao Wang*, Zihan Wang*, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng and Heng Ji.
MINT benchmark aims to evaluate LLMs' ability to solve tasks with multi-turn interactions by (1) using tools and (2) leveraging natural language feedback.
🏆 Please visit our website for the leaderboard.
⚠️ WARNING: Evaluation of LLMs requires executing untrusted model-generated code. Users are strongly encouraged to sandbox the code execution so that it does not perform destructive actions on their host or network. We highly recommend using the provided docker image for isolated execution.
git clone https://github.com/xingyaoww/mint-bench
cd mint-benchYou can choose to use docker (recommended) or local setup as follows.
You only need to ensure that you have docker installed on your local computer following the official guide.
# Install Anaconda or Miniconda first if you don't have it already.
conda env create -f environment.yml
conda activate mint
# Install the MINT package
pip install -e .To evaluate huggingface-compatible open-source models, check instructions here.
To evaluate API-base closed-source models, set Your API Key:
# Obtain OpenAI API access from https://openai.com/blog/openai-api
# This key is necessary for all models since, by default, we use GPT-4 for feedback generation
export OPENAI_API_KEY='YOUR KEY HERE';
# The following keys are optional
# Will only be used if you use Bard or Claude as the evaluated model/feedback provider
# https://www.googlecloudcommunity.com/gc/AI-ML/Google-Bard-API/m-p/538517
export BARD_API_KEY='YOUR KEY HERE';
# https://docs.anthropic.com/claude/docs/getting-access-to-claude
export ANTHROPIC_API_KEY='YOUR KEY HERE';Please refer to docs/CONFIG.md if you want to evaluate a custom API-based model.
MINT uses configuration files to specify the experiment settings (e.g., which models to use, which datasets to use, etc.).
We provide a script mint/configs/config_variables.py to generate default config files for you.
Please refer to docs/CONFIG.md if you want to add an evaluated model, a different LLM that provides feedback, or different experiment setting (e.g., feedback type).
# Create configuration files for your experiment.
# By default configs will be saved to configs/ and model outputs will be saved to data/outputs
python mint/configs/generate_config.pyIf you want to use a docker environment for better isolation: We recommend using a terminal multiplexer (e.g., tmux) to start the docker for better management. Please make sure you have admin permission by adding the prefix "sudo" or have your admin add you to the docker user group. You will enter an interactive docker environment with all dependencies installed:
./scripts/docker/run_interactive.shRun the following once you are inside the docker container (for docker-setup), or you are in the conda environment (conda activate mint):
# Use this script to run the experiment
# You can specify which config file you want to run by modifying the script
# By default, we will run multiple configs in parallel and save output to `output.txt` in corresponding outputs folder
./scripts/run.sh
# If you want to run the experiment in debug mode (only run 1 config at a time), run the following
DEBUG_MODE=1 ./scripts/run.shAnalyze result: You can use the notebook scripts/notebook/analyze_output.ipynb to analyze the model you evaluated and reproduce tables and figures from the paper.
Alternatively, you can convert output by running python scripts/convert_outputs.py --data_dir data/outputs --output_dir YOUR_OUTPUT_DIR/ to get results breakdown by task name.
Visualize the results: The following code will starts a streamlit-based visualizer to visualize your directory.
streamlit run scripts/visualizer.py -- --data_dir data/outputsWe welcome contributions to this repo from the community!
To add your model to the benchmark, you can start a PR to merge your model outputs data/outputs into this repo. This will be automatically updated to the website.
Please refer to docs/CONTRIBUTING.md for more details about contributing models, tools, and data.
If you find this repo helpful, please cite our paper:
@misc{wang2023mint,
title={MINT: Evaluating LLMs in Multi-turn Interaction with Tools and Language Feedback},
author={Xingyao Wang and Zihan Wang and Jiateng Liu and Yangyi Chen and Lifan Yuan and Hao Peng and Heng Ji},
year={2023},
eprint={2309.10691},
archivePrefix={arXiv},
primaryClass={cs.CL}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mint-bench
Similar Open Source Tools
mint-bench
MINT benchmark aims to evaluate LLMs' ability to solve tasks with multi-turn interactions by (1) using tools and (2) leveraging natural language feedback.
SeaGOAT
SeaGOAT is a local search tool that leverages vector embeddings to enable you to search your codebase semantically. It is designed to work on Linux, macOS, and Windows and can process files in various formats, including text, Markdown, Python, C, C++, TypeScript, JavaScript, HTML, Go, Java, PHP, and Ruby. SeaGOAT uses a vector database called ChromaDB and a local vector embedding engine to provide fast and accurate search results. It also supports regular expression/keyword-based matches. SeaGOAT is open-source and licensed under an open-source license, and users are welcome to examine the source code, raise concerns, or create pull requests to fix problems.

bia-bob
BIA `bob` is a Jupyter-based assistant for interacting with data using large language models to generate Python code. It can utilize OpenAI's chatGPT, Google's Gemini, Helmholtz' blablador, and Ollama. Users need respective accounts to access these services. Bob can assist in code generation, bug fixing, code documentation, GPU-acceleration, and offers a no-code custom Jupyter Kernel. It provides example notebooks for various tasks like bio-image analysis, model selection, and bug fixing. Installation is recommended via conda/mamba environment. Custom endpoints like blablador and ollama can be used. Google Cloud AI API integration is also supported. The tool is extensible for Python libraries to enhance Bob's functionality.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.
srcbook
Srcbook is an open-source interactive programming environment for TypeScript that allows users to create, run, and share reproducible programs and ideas. It features AI capabilities for exploring and iterating on ideas, supports exporting to valid markdown format, and enables diagraming with mermaid for rich annotations. Users can locally execute programs through a web interface, powered by Node.js under the Apache2 license.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.

log10
Log10 is a one-line Python integration to manage your LLM data. It helps you log both closed and open-source LLM calls, compare and identify the best models and prompts, store feedback for fine-tuning, collect performance metrics such as latency and usage, and perform analytics and monitor compliance for LLM powered applications. Log10 offers various integration methods, including a python LLM library wrapper, the Log10 LLM abstraction, and callbacks, to facilitate its use in both existing production environments and new projects. Pick the one that works best for you. Log10 also provides a copilot that can help you with suggestions on how to optimize your prompt, and a feedback feature that allows you to add feedback to your completions. Additionally, Log10 provides prompt provenance, session tracking and call stack functionality to help debug prompt chains. With Log10, you can use your data and feedback from users to fine-tune custom models with RLHF, and build and deploy more reliable, accurate and efficient self-hosted models. Log10 also supports collaboration, allowing you to create flexible groups to share and collaborate over all of the above features.
CoML
CoML (formerly MLCopilot) is an interactive coding assistant for data scientists and machine learning developers, empowered on large language models. It offers an out-of-the-box interactive natural language programming interface for data mining and machine learning tasks, integration with Jupyter lab and Jupyter notebook, and a built-in large knowledge base of machine learning to enhance the ability to solve complex tasks. The tool is designed to assist users in coding tasks related to data analysis and machine learning using natural language commands within Jupyter environments.
CLI
Bito CLI provides a command line interface to the Bito AI chat functionality, allowing users to interact with the AI through commands. It supports complex automation and workflows, with features like long prompts and slash commands. Users can install Bito CLI on Mac, Linux, and Windows systems using various methods. The tool also offers configuration options for AI model type, access key management, and output language customization. Bito CLI is designed to enhance user experience in querying AI models and automating tasks through the command line interface.
llm-applications
A comprehensive guide to building Retrieval Augmented Generation (RAG)-based LLM applications for production. This guide covers developing a RAG-based LLM application from scratch, scaling the major components, evaluating different configurations, implementing LLM hybrid routing, serving the application in a highly scalable and available manner, and sharing the impacts LLM applications have had on products.
testzeus-hercules
Hercules is the world’s first open-source testing agent designed to handle the toughest testing tasks for modern web applications. It turns simple Gherkin steps into fully automated end-to-end tests, making testing simple, reliable, and efficient. Hercules adapts to various platforms like Salesforce and is suitable for CI/CD pipelines. It aims to democratize and disrupt test automation, making top-tier testing accessible to everyone. The tool is transparent, reliable, and community-driven, empowering teams to deliver better software. Hercules offers multiple ways to get started, including using PyPI package, Docker, or building and running from source code. It supports various AI models, provides detailed installation and usage instructions, and integrates with Nuclei for security testing and WCAG for accessibility testing. The tool is production-ready, open core, and open source, with plans for enhanced LLM support, advanced tooling, improved DOM distillation, community contributions, extensive documentation, and a bounty program.
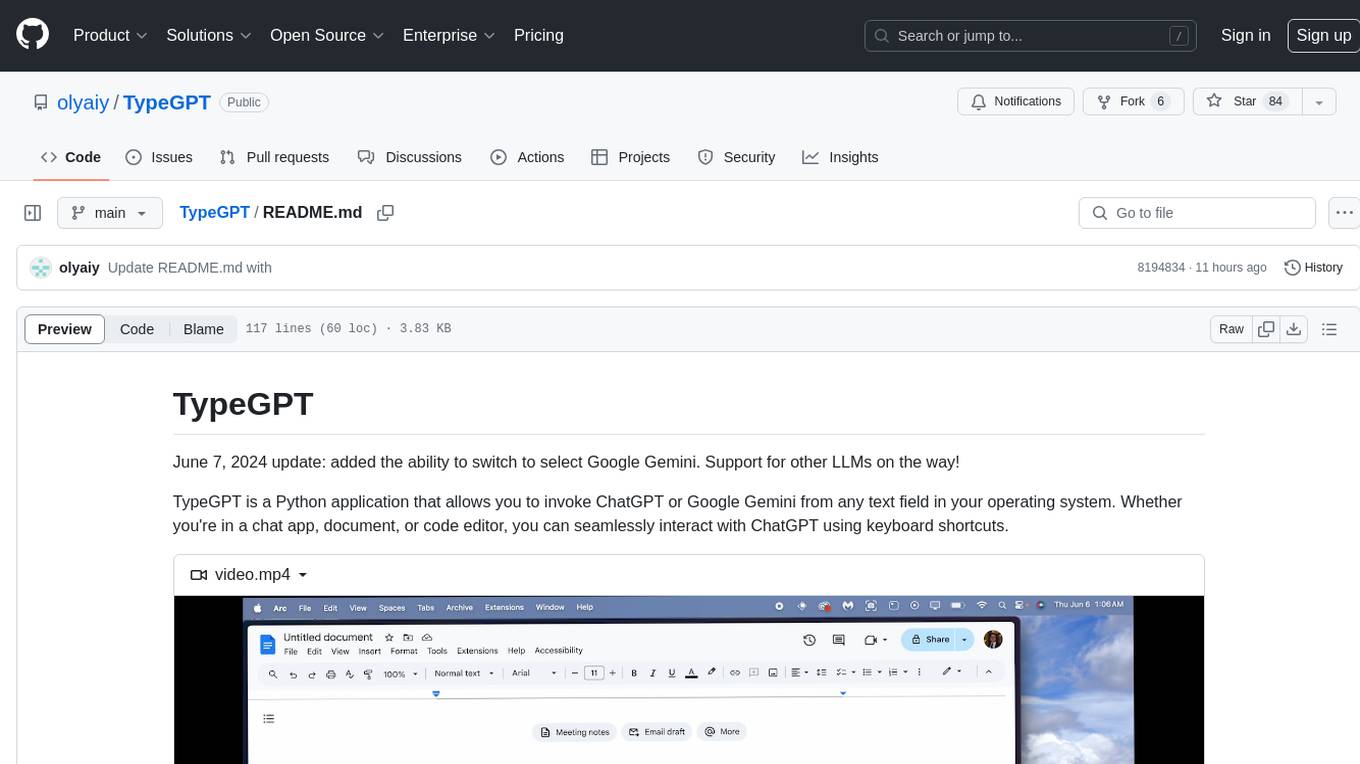
TypeGPT
TypeGPT is a Python application that enables users to interact with ChatGPT or Google Gemini from any text field in their operating system using keyboard shortcuts. It provides global accessibility, keyboard shortcuts for communication, and clipboard integration for larger text inputs. Users need to have Python 3.x installed along with specific packages and API keys from OpenAI for ChatGPT access. The tool allows users to run the program normally or in the background, manage processes, and stop the program. Users can use keyboard shortcuts like `/ask`, `/see`, `/stop`, `/chatgpt`, `/gemini`, `/check`, and `Shift + Cmd + Enter` to interact with the application in any text field. Customization options are available by modifying files like `keys.txt` and `system_prompt.txt`. Contributions are welcome, and future plans include adding support for other APIs and a user-friendly GUI.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.