
conversational-agent-langchain
FastAPI Backend for a Conversational Agent using Cohere, (Azure) OpenAI, Langchain & Langgraph and Qdrant as VectorDB
Stars: 148

This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.
README:
This is a Rest-Backend for a Conversational Agent, that allows to embedd Documentes, search for them using Semantic Search, to QA based on Documents and do document processing with Large Language Models.
At the moment i am reworking to langgraph, therefore not all versions on main will work with all of the providers. I will update the providers in the next weeks. Please use the releases to get a working version.
- Complete Rework to Langgraph
- Adding Cohere
- Adding Ollama
If you want to use an Aleph Alpha only backend i would recommend my other backend: https://github.com/mfmezger/aleph-alpha-rag.
To run the complete system with docker use this command:
git clone https://github.com/mfmezger/conversational-agent-langchain.git
cd conversational-agent-langchainCreate a .env file from the .env-template and set the qdrant api key. For tests just set it to test. QDRANT_API_KEY="test"
Then start the system with
docker compose up -dThen go to http://127.0.0.1:8001/docs or http://127.0.0.1:8001/redoc to see the API documentation.
Frontend: localhost:8501 Qdrant Dashboard: localhost:6333/dashboard
This project is a conversational agent that uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries. The agent also includes a vector database and a REST API built with FastAPI.
Features
- Uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries.
- Includes a vector database to store and retrieve information.
- Provides a REST API built with FastAPI for easy integration with other applications.
- Has a basic gui.

Semantic search is an advanced search technique that aims to understand the meaning and context of a user's query, rather than matching keywords. It involves natural language processing (NLP) and machine learning algorithms to analyze and interpret user intent, synonyms, relationships between words, and the structure of content. By considering these factors, semantic search improves the accuracy and relevance of search results, providing a more intuitive and personalized user experience.

Langchain is a library for natural language processing and machine learning. FastAPI is a modern, fast (high-performance) web framework for building APIs with Python 3.7+ based on standard Python type hints. A Vectordatabase is a database that stores vectors, which can be used for similarity searches and other machine learning tasks.
Two ways to manage your api keys are available, the easiest approach is to sent the api token in the request as the token. Another possiblity is to create a .env file and add the api token there. If you use OpenAI from Azure or OpenAI directly you need to set the correct parameters in the .env file.
On Linux or Mac you need to adjust your /etc/hosts file to include the following line:
127.0.0.1 qdrantFirst install Python Dependencies:
You need to instal rye if you want to use it for syncing the requirements.lock file. Rye Installation.
rye sync
# or if you do not want to use rye
pip install -r requirements.lockStart the complete system with:
docker compose up -dTo run the Qdrant Database local just run:
docker compose up qdrantTo run the Backend use this command in the root directory:
poetry run uvicorn agent.api:app --reloadTo run the tests you can use this command:
poetry run coverage run -m pytest -o log_cli=true -vvv testsTo run the Frontend use this command in the root directory:
poetry run streamlit run gui.py --theme.base="dark"mypy rag --explicit-package-bases
Qdrant Dashboard is available at http://127.0.0.1:6333/dashboard. There you need to enter the api key.
To use the Qdrant API you need to set the correct parameters in the .env file. QDRANT_API_KEY is the API key for the Qdrant API. And you need to change it in the qdrant.yaml file in the config folder.
If you want to ingest large amount of data i would recommend you use the scripts located in agent/ingestion.
To Test the API i would recommend Bruno. The API Requests are store in ConvAgentBruno folder.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for conversational-agent-langchain
Similar Open Source Tools
conversational-agent-langchain
This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.

raggenie
RAGGENIE is a low-code RAG builder tool designed to simplify the creation of conversational AI applications. It offers out-of-the-box plugins for connecting to various data sources and building conversational AI on top of them, including integration with pre-built agents for actions. The tool is open-source under the MIT license, with a current focus on making it easy to build RAG applications and future plans for maintenance, monitoring, and transitioning applications from pilots to production.

vector-vein
VectorVein is a no-code AI workflow software inspired by LangChain and langflow, aiming to combine the powerful capabilities of large language models and enable users to achieve intelligent and automated daily workflows through simple drag-and-drop actions. Users can create powerful workflows without the need for programming, automating all tasks with ease. The software allows users to define inputs, outputs, and processing methods to create customized workflow processes for various tasks such as translation, mind mapping, summarizing web articles, and automatic categorization of customer reviews.
leettools
LeetTools is an AI search assistant that can perform highly customizable search workflows and generate customized format results based on both web and local knowledge bases. It provides an automated document pipeline for data ingestion, indexing, and storage, allowing users to focus on implementing workflows without worrying about infrastructure. LeetTools can run with minimal resource requirements on the command line with configurable LLM settings and supports different databases for various functions. Users can configure different functions in the same workflow to use different LLM providers and models.

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.
nanoPerplexityAI
nanoPerplexityAI is an open-source implementation of a large language model service that fetches information from Google. It involves a simple architecture where the user query is checked by the language model, reformulated for Google search, and an answer is generated and saved in a markdown file. The tool requires minimal setup and is designed for easy visualization of answers.
vertex-ai-creative-studio
GenMedia Creative Studio is an application showcasing the capabilities of Google Cloud Vertex AI generative AI creative APIs. It includes features like Gemini for prompt rewriting and multimodal evaluation of generated images. The app is built with Mesop, a Python-based UI framework, enabling rapid development of web and internal apps. The Experimental folder contains stand-alone applications and upcoming features demonstrating cutting-edge generative AI capabilities, such as image generation, prompting techniques, and audio/video tools.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
genai-for-marketing
This repository provides a deployment guide for utilizing Google Cloud's Generative AI tools in marketing scenarios. It includes step-by-step instructions, examples of crafting marketing materials, and supplementary Jupyter notebooks. The demos cover marketing insights, audience analysis, trendspotting, content search, content generation, and workspace integration. Users can access and visualize marketing data, analyze trends, improve search experience, and generate compelling content. The repository structure includes backend APIs, frontend code, sample notebooks, templates, and installation scripts.
webwhiz
WebWhiz is an open-source tool that allows users to train ChatGPT on website data to build AI chatbots for customer queries. It offers easy integration, data-specific responses, regular data updates, no-code builder, chatbot customization, fine-tuning, and offline messaging. Users can create and train chatbots in a few simple steps by entering their website URL, automatically fetching and preparing training data, training ChatGPT, and embedding the chatbot on their website. WebWhiz can crawl websites monthly, collect text data and metadata, and process text data using tokens. Users can train custom data, but bringing custom open AI keys is not yet supported. The tool has no limitations on context size but may limit the number of pages based on the chosen plan. WebWhiz SDK is available on NPM, CDNs, and GitHub, and users can self-host it using Docker or manual setup involving MongoDB, Redis, Node, Python, and environment variables setup. For any issues, users can contact [email protected].
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.
chatflow
Chatflow is a tool that provides a chat interface for users to interact with systems using natural language. The engine understands user intent and executes commands for tasks, allowing easy navigation of complex websites/products. This approach enhances user experience, reduces training costs, and boosts productivity.

dataherald
Dataherald is a natural language-to-SQL engine built for enterprise-level question answering over structured data. It allows you to set up an API from your database that can answer questions in plain English. You can use Dataherald to: * Allow business users to get insights from the data warehouse without going through a data analyst * Enable Q+A from your production DBs inside your SaaS application * Create a ChatGPT plug-in from your proprietary data

coral-cloud
Coral Cloud Resorts is a sample hospitality application that showcases Data Cloud, Agents, and Prompts. It provides highly personalized guest experiences through smart automation, content generation, and summarization. The app requires licenses for Data Cloud, Agents, Prompt Builder, and Einstein for Sales. Users can activate features, deploy metadata, assign permission sets, import sample data, and troubleshoot common issues. Additionally, the repository offers integration with modern web development tools like Prettier, ESLint, and pre-commit hooks for code formatting and linting.
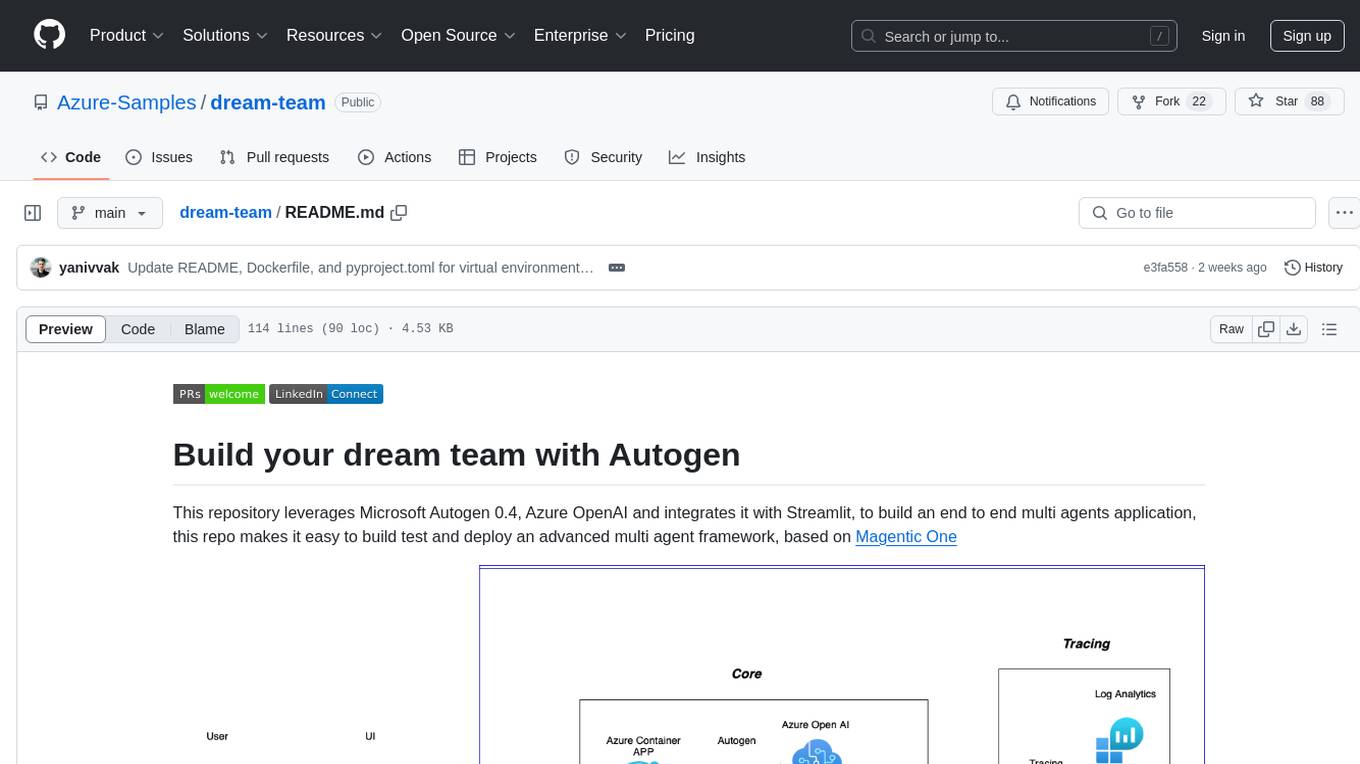
dream-team
Build your dream team with Autogen is a repository that leverages Microsoft Autogen 0.4, Azure OpenAI, and Streamlit to create an end-to-end multi-agent application. It provides an advanced multi-agent framework based on Magentic One, with features such as a friendly UI, single-line deployment, secure code execution, managed identities, and observability & debugging tools. Users can deploy Azure resources and the app with simple commands, work locally with virtual environments, install dependencies, update configurations, and run the application. The repository also offers resources for learning more about building applications with Autogen.
For similar tasks
conversational-agent-langchain
This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.
semantic-router
Semantic Router is a superfast decision-making layer for your LLMs and agents. Rather than waiting for slow LLM generations to make tool-use decisions, we use the magic of semantic vector space to make those decisions — _routing_ our requests using _semantic_ meaning.

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.
luna-ai
Luna AI is a virtual streamer driven by a 'brain' composed of ChatterBot, GPT, Claude, langchain, chatglm, text-generation-webui, 讯飞星火, 智谱AI. It can interact with viewers in real-time during live streams on platforms like Bilibili, Douyin, Kuaishou, Douyu, or chat with you locally. Luna AI uses natural language processing and text-to-speech technologies like Edge-TTS, VITS-Fast, elevenlabs, bark-gui, VALL-E-X to generate responses to viewer questions and can change voice using so-vits-svc, DDSP-SVC. It can also collaborate with Stable Diffusion for drawing displays and loop custom texts. This project is completely free, and any identical copycat selling programs are pirated, please stop them promptly.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

cria
Cria is a Python library designed for running Large Language Models with minimal configuration. It provides an easy and concise way to interact with LLMs, offering advanced features such as custom models, streams, message history management, and running multiple models in parallel. Cria simplifies the process of using LLMs by providing a straightforward API that requires only a few lines of code to get started. It also handles model installation automatically, making it efficient and user-friendly for various natural language processing tasks.

beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.