
openlrc
Transcribe and translate voice into LRC file using Whisper and LLMs (GPT, Claude, et,al). 使用whisper和LLM(GPT,Claude等)来转录、翻译你的音频为字幕文件。
Stars: 476

Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
README:



Open-Lyrics is a Python library that transcribes voice files using
faster-whisper, and translates/polishes the resulting text
into .lrc files in the desired language using LLM,
e.g. OpenAI-GPT, Anthropic-Claude.
- Well preprocessed audio to reduce hallucination (Loudness Norm & optional Noise Suppression).
- Context-aware translation to improve translation quality. Check prompt for details.
- Check here for an overview of the architecture.
- 2024.5.7:
- Add custom endpoint (base_url) support for OpenAI & Anthropic:
lrcer = LRCer(base_url_config={'openai': 'https://api.chatanywhere.tech', 'anthropic': 'https://example/api'})
- Generating bilingual subtitles
lrcer.run('./data/test.mp3', target_lang='zh-cn', bilingual_sub=True)
- Add custom endpoint (base_url) support for OpenAI & Anthropic:
- 2024.5.11: Add glossary into prompt, which is confirmed to improve domain specific translation. Check here for details.
- 2024.5.17: You can route model to arbitrary Chatbot SDK (either OpenAI or Anthropic) by setting
chatbot_modeltoprovider: model_nametogether with base_url_config:lrcer = LRCer(chatbot_model='openai: claude-3-haiku-20240307', base_url_config={'openai': 'https://api.g4f.icu/v1/'})
- 2024.6.25: Support Gemini as translation engine LLM, try using
gemini-1.5-flash:lrcer = LRCer(chatbot_model='gemini-1.5-flash')
- 2024.9.10: Now openlrc depends on
a specific commit of
faster-whisper, which is not published on PyPI. Install it from source:
pip install "faster-whisper @ https://github.com/SYSTRAN/faster-whisper/archive/8327d8cc647266ed66f6cd878cf97eccface7351.tar.gz" - 2024.12.19: Add
ModelConfigfor chat model routing, which is more flexible than model name string, The ModelConfig can be ModelConfig(provider='', model_name='', base_url='', proxy=''), e.g.:from openlrc import LRCer, ModelConfig, ModelProvider chatbot_model1 = ModelConfig( provider=ModelProvider.OPENAI, name='deepseek-chat', base_url='https://api.deepseek.com/beta', api_key='sk-APIKEY' ) chatbot_model2 = ModelConfig( provider=ModelProvider.OPENAI, name='gpt-4o-mini', api_key='sk-APIKEY' ) lrcer = LRCer(chatbot_model=chatbot_model1, retry_model=chatbot_model2)
-
Please install CUDA 11.x and cuDNN 8 for CUDA 11 first according to https://opennmt.net/CTranslate2/installation.html to enable
faster-whisper.faster-whisperalso needs cuBLAS for CUDA 11 installed.For Windows Users (click to expand)
(For Windows Users only) Windows user can Download the libraries from Purfview's repository:
Purfview's whisper-standalone-win provides the required NVIDIA libraries for Windows in a single archive. Decompress the archive and place the libraries in a directory included in the
PATH. -
Add LLM API keys, you can either:
- Add your OpenAI API key to environment variable
OPENAI_API_KEY. - Add your Anthropic API key to environment variable
ANTHROPIC_API_KEY. - Add your Google API Key to environment variable
GOOGLE_API_KEY.
- Add your OpenAI API key to environment variable
-
Install ffmpeg and add
bindirectory to yourPATH. -
This project can be installed from PyPI:
pip install openlrc
or install directly from GitHub:
pip install git+https://github.com/zh-plus/openlrc
-
Install latest fast-whisper from source:
pip install "faster-whisper @ https://github.com/SYSTRAN/faster-whisper/archive/8327d8cc647266ed66f6cd878cf97eccface7351.tar.gz" -
Install PyTorch:
pip install --force-reinstall torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
-
Fix the
typing-extensionsissue:pip install typing-extensions -U
from openlrc import LRCer
if __name__ == '__main__':
lrcer = LRCer()
# Single file
lrcer.run('./data/test.mp3',
target_lang='zh-cn') # Generate translated ./data/test.lrc with default translate prompt.
# Multiple files
lrcer.run(['./data/test1.mp3', './data/test2.mp3'], target_lang='zh-cn')
# Note we run the transcription sequentially, but run the translation concurrently for each file.
# Path can contain video
lrcer.run(['./data/test_audio.mp3', './data/test_video.mp4'], target_lang='zh-cn')
# Generate translated ./data/test_audio.lrc and ./data/test_video.srt
# Use glossary to improve translation
lrcer = LRCer(glossary='./data/aoe4-glossary.yaml')
# To skip translation process
lrcer.run('./data/test.mp3', target_lang='en', skip_trans=True)
# Change asr_options or vad_options, check openlrc.defaults for details
vad_options = {"threshold": 0.1}
lrcer = LRCer(vad_options=vad_options)
lrcer.run('./data/test.mp3', target_lang='zh-cn')
# Enhance the audio using noise suppression (consume more time).
lrcer.run('./data/test.mp3', target_lang='zh-cn', noise_suppress=True)
# Change the LLM model for translation
lrcer = LRCer(chatbot_model='claude-3-sonnet-20240229')
lrcer.run('./data/test.mp3', target_lang='zh-cn')
# Clear temp folder after processing done
lrcer.run('./data/test.mp3', target_lang='zh-cn', clear_temp=True)
# Change base_url
lrcer = LRCer(base_url_config={'openai': 'https://api.g4f.icu/v1',
'anthropic': 'https://example/api'})
# Route model to arbitrary Chatbot SDK
lrcer = LRCer(chatbot_model='openai: claude-3-sonnet-20240229',
base_url_config={'openai': 'https://api.g4f.icu/v1/'})
# Bilingual subtitle
lrcer.run('./data/test.mp3', target_lang='zh-cn', bilingual_sub=True)Check more details in Documentation.
Add glossary to improve domain specific translation. For example aoe4-glossary.yaml:
{
"aoe4": "帝国时代4",
"feudal": "封建时代",
"2TC": "双TC",
"English": "英格兰文明",
"scout": "侦察兵"
}lrcer = LRCer(glossary='./data/aoe4-glossary.yaml')
lrcer.run('./data/test.mp3', target_lang='zh-cn')or directly use dictionary to add glossary:
lrcer = LRCer(glossary={"aoe4": "帝国时代4", "feudal": "封建时代"})
lrcer.run('./data/test.mp3', target_lang='zh-cn')pricing data from OpenAI and Anthropic
| Model Name | Pricing for 1M Tokens (Input/Output) (USD) |
Cost for 1 Hour Audio (USD) |
|---|---|---|
gpt-3.5-turbo |
0.5, 1.5 | 0.01 |
gpt-4o-mini |
0.5, 1.5 | 0.01 |
gpt-4-0125-preview |
10, 30 | 0.5 |
gpt-4-turbo-preview |
10, 30 | 0.5 |
gpt-4o |
5, 15 | 0.25 |
claude-3-haiku-20240307 |
0.25, 1.25 | 0.015 |
claude-3-sonnet-20240229 |
3, 15 | 0.2 |
claude-3-opus-20240229 |
15, 75 | 1 |
claude-3-5-sonnet-20240620 |
3, 15 | 0.2 |
gemini-1.5-flash |
0.175, 2.1 | 0.01 |
gemini-1.0-pro |
0.5, 1.5 | 0.01 |
gemini-1.5-pro |
1.75, 21 | 0.1 |
deepseek-chat |
0.18, 2.2 | 0.01 |
Note the cost is estimated based on the token count of the input and output text. The actual cost may vary due to the language and audio speed.
For english audio, we recommend using deepseek-chat, gpt-4o-mini or gemini-1.5-flash.
For non-english audio, we recommend using claude-3-5-sonnet-20240620.

To maintain context between translation segments, the process is sequential for each audio file.
- [x] [Efficiency] Batched translate/polish for GPT request (enable contextual ability).
- [x] [Efficiency] Concurrent support for GPT request.
- [x] [Translation Quality] Make translate prompt more robust according to https://github.com/openai/openai-cookbook.
- [x] [Feature] Automatically fix json encoder error using GPT.
- [x] [Efficiency] Asynchronously perform transcription and translation for multiple audio inputs.
- [x] [Quality] Improve batched translation/polish prompt according to gpt-subtrans.
- [x] [Feature] Input video support.
- [X] [Feature] Multiple output format support.
- [x] [Quality] Speech enhancement for input audio.
- [ ] [Feature] Preprocessor: Voice-music separation.
- [ ] [Feature] Align ground-truth transcription with audio.
- [ ] [Quality] Use multilingual language model to assess translation quality.
- [ ] [Efficiency] Add Azure OpenAI Service support.
- [ ] [Quality] Use claude for translation.
- [ ] [Feature] Add local LLM support.
- [X] [Feature] Multiple translate engine (Anthropic, Microsoft, DeepL, Google, etc.) support.
- [ ] [Feature] Build a electron + fastapi GUI for cross-platform application.
- [x] [Feature] Web-based streamlit GUI.
- [ ] Add fine-tuned whisper-large-v2 models for common languages.
- [x] [Feature] Add custom OpenAI & Anthropic endpoint support.
- [ ] [Feature] Add local translation model support (e.g. SakuraLLM).
- [ ] [Quality] Construct translation quality benchmark test for each patch.
- [ ] [Quality] Split subtitles using LLM (ref).
- [ ] [Quality] Trim extra long subtitle using LLM (ref).
- [ ] [Others] Add transcribed examples.
- [ ] Song
- [ ] Podcast
- [ ] Audiobook
- https://github.com/guillaumekln/faster-whisper
- https://github.com/m-bain/whisperX
- https://github.com/openai/openai-python
- https://github.com/openai/whisper
- https://github.com/machinewrapped/gpt-subtrans
- https://github.com/MicrosoftTranslator/Text-Translation-API-V3-Python
- https://github.com/streamlit/streamlit
@book{openlrc2024zh,
title = {zh-plus/openlrc},
url = {https://github.com/zh-plus/openlrc},
author = {Hao, Zheng},
date = {2024-09-10},
year = {2024},
month = {9},
day = {10},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for openlrc
Similar Open Source Tools
openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.
libllm
libLLM is an open-source project designed for efficient inference of large language models (LLM) on personal computers and mobile devices. It is optimized to run smoothly on common devices, written in C++14 without external dependencies, and supports CUDA for accelerated inference. Users can build the tool for CPU only or with CUDA support, and run libLLM from the command line. Additionally, there are API examples available for Python and the tool can export Huggingface models.

evalplus
EvalPlus is a rigorous evaluation framework for LLM4Code, providing HumanEval+ and MBPP+ tests to evaluate large language models on code generation tasks. It offers precise evaluation and ranking, coding rigorousness analysis, and pre-generated code samples. Users can use EvalPlus to generate code solutions, post-process code, and evaluate code quality. The tool includes tools for code generation and test input generation using various backends.

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.
witsy
Witsy is a generative AI desktop application that supports various models like OpenAI, Ollama, Anthropic, MistralAI, Google, Groq, and Cerebras. It offers features such as chat completion, image generation, scratchpad for content creation, prompt anywhere functionality, AI commands for productivity, expert prompts for specialization, LLM plugins for additional functionalities, read aloud capabilities, chat with local files, transcription/dictation, Anthropic Computer Use support, local history of conversations, code formatting, image copy/download, and more. Users can interact with the application to generate content, boost productivity, and perform various AI-related tasks.

ai00_server
AI00 RWKV Server is an inference API server for the RWKV language model based upon the web-rwkv inference engine. It supports VULKAN parallel and concurrent batched inference and can run on all GPUs that support VULKAN. No need for Nvidia cards!!! AMD cards and even integrated graphics can be accelerated!!! No need for bulky pytorch, CUDA and other runtime environments, it's compact and ready to use out of the box! Compatible with OpenAI's ChatGPT API interface. 100% open source and commercially usable, under the MIT license. If you are looking for a fast, efficient, and easy-to-use LLM API server, then AI00 RWKV Server is your best choice. It can be used for various tasks, including chatbots, text generation, translation, and Q&A.
agentops
AgentOps is a toolkit for evaluating and developing robust and reliable AI agents. It provides benchmarks, observability, and replay analytics to help developers build better agents. AgentOps is open beta and can be signed up for here. Key features of AgentOps include: - Session replays in 3 lines of code: Initialize the AgentOps client and automatically get analytics on every LLM call. - Time travel debugging: (coming soon!) - Agent Arena: (coming soon!) - Callback handlers: AgentOps works seamlessly with applications built using Langchain and LlamaIndex.
zeroclaw
ZeroClaw is a fast, small, and fully autonomous AI assistant infrastructure built with Rust. It features a lean runtime, cost-efficient deployment, fast cold starts, and a portable architecture. It is secure by design, fully swappable, and supports OpenAI-compatible provider support. The tool is designed for low-cost boards and small cloud instances, with a memory footprint of less than 5MB. It is suitable for tasks like deploying AI assistants, swapping providers/channels/tools, and pluggable everything.

candle-vllm
Candle-vllm is an efficient and easy-to-use platform designed for inference and serving local LLMs, featuring an OpenAI compatible API server. It offers a highly extensible trait-based system for rapid implementation of new module pipelines, streaming support in generation, efficient management of key-value cache with PagedAttention, and continuous batching. The tool supports chat serving for various models and provides a seamless experience for users to interact with LLMs through different interfaces.

MHA2MLA
This repository contains the code for the paper 'Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs'. It provides tools for fine-tuning and evaluating Llama models, converting models between different frameworks, processing datasets, and performing specific model training tasks like Partial-RoPE Fine-Tuning and Multiple-Head Latent Attention Fine-Tuning. The repository also includes commands for model evaluation using Lighteval and LongBench, along with necessary environment setup instructions.

AnglE
AnglE is a library for training state-of-the-art BERT/LLM-based sentence embeddings with just a few lines of code. It also serves as a general sentence embedding inference framework, allowing for inferring a variety of transformer-based sentence embeddings. The library supports various loss functions such as AnglE loss, Contrastive loss, CoSENT loss, and Espresso loss. It provides backbones like BERT-based models, LLM-based models, and Bi-directional LLM-based models for training on single or multi-GPU setups. AnglE has achieved significant performance on various benchmarks and offers official pretrained models for both BERT-based and LLM-based models.
docutranslate
Docutranslate is a versatile tool for translating documents efficiently. It supports multiple file formats and languages, making it ideal for businesses and individuals needing quick and accurate translations. The tool uses advanced algorithms to ensure high-quality translations while maintaining the original document's formatting. With its user-friendly interface, Docutranslate simplifies the translation process and saves time for users. Whether you need to translate legal documents, technical manuals, or personal letters, Docutranslate is the go-to solution for all your document translation needs.
flyto-core
Flyto-core is a powerful Python library for geospatial analysis and visualization. It provides a wide range of tools for working with geographic data, including support for various file formats, spatial operations, and interactive mapping. With Flyto-core, users can easily load, manipulate, and visualize spatial data to gain insights and make informed decisions. Whether you are a GIS professional, a data scientist, or a developer, Flyto-core offers a versatile and user-friendly solution for geospatial tasks.
celeste-python
Celeste AI is a type-safe, modality/provider-agnostic tool that offers unified interface for various providers like OpenAI, Anthropic, Gemini, Mistral, and more. It supports multiple modalities including text, image, audio, video, and embeddings, with full Pydantic validation and IDE autocomplete. Users can switch providers instantly, ensuring zero lock-in and a lightweight architecture. The tool provides primitives, not frameworks, for clean I/O operations.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.
For similar tasks
openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
ai-enhanced-audio-book
The ai-enhanced-audio-book repository contains AI-enhanced audio plugins developed using C++, JUCE, libtorch, RTNeural, and other libraries. It showcases neural networks learning to emulate guitar amplifiers through waveforms. Users can visit the official website for more information and obtain a copy of the book from the publisher Taylor and Francis/ Routledge/ Focal.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
Chenyme-AAVT
Chenyme-AAVT is a user-friendly tool that provides automatic video and audio recognition and translation. It leverages the capabilities of Whisper, a powerful speech recognition model, to accurately identify speech in videos and audios. The recognized speech is then translated using ChatGPT or KIMI, ensuring high-quality translations. With Chenyme-AAVT, you can quickly generate字幕 files and merge them with the original video, making video translation a breeze. The tool supports various languages, allowing you to translate videos and audios into your desired language. Additionally, Chenyme-AAVT offers features such as VAD (Voice Activity Detection) to enhance recognition accuracy, GPU acceleration for faster processing, and support for multiple字幕 formats. Whether you're a content creator, translator, or anyone looking to make video translation more efficient, Chenyme-AAVT is an invaluable tool.
MoneyPrinterTurbo
MoneyPrinterTurbo is a tool that can automatically generate video content based on a provided theme or keyword. It can create video scripts, materials, subtitles, and background music, and then compile them into a high-definition short video. The tool features a web interface and an API interface, supporting AI-generated video scripts, customizable scripts, multiple HD video sizes, batch video generation, customizable video segment duration, multilingual video scripts, multiple voice synthesis options, subtitle generation with font customization, background music selection, access to high-definition and copyright-free video materials, and integration with various AI models like OpenAI, moonshot, Azure, and more. The tool aims to simplify the video creation process and offers future plans to enhance voice synthesis, add video transition effects, provide more video material sources, offer video length options, include free network proxies, enable real-time voice and music previews, support additional voice synthesis services, and facilitate automatic uploads to YouTube platform.
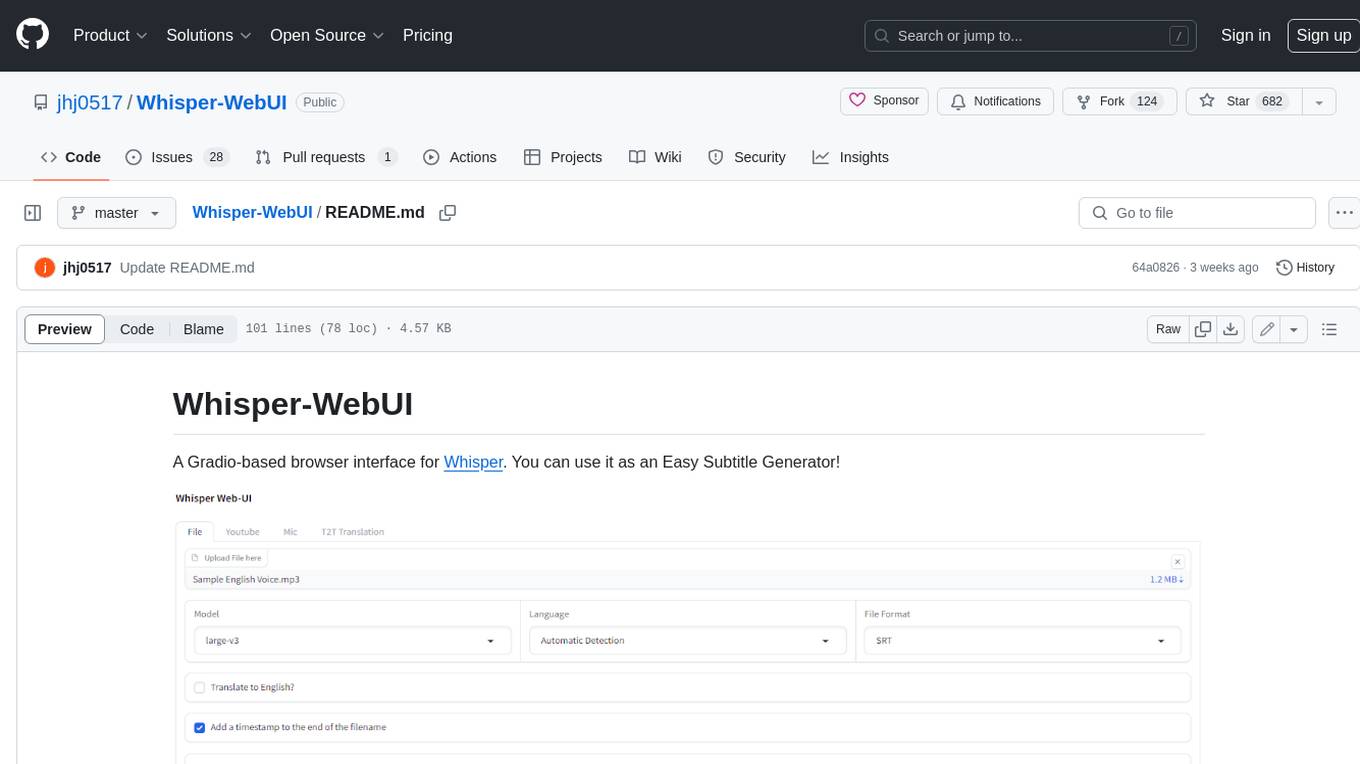
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.

FunClip
FunClip is an open-source, locally deployed automated video clipping tool that leverages Alibaba TONGYI speech lab's FunASR Paraformer series models for speech recognition on videos. Users can select text segments or speakers from recognition results to obtain corresponding video clips. It integrates industrial-grade models for accurate predictions and offers hotword customization and speaker recognition features. The tool is user-friendly with Gradio interaction, supporting multi-segment clipping and providing full video and target segment subtitles. FunClip is suitable for users looking to automate video clipping tasks with advanced AI capabilities.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.