
decipher
Effortlessly add AI-generated transcription subtitles to your videos
Stars: 519
Decipher is a tool that utilizes AI-generated transcription subtitles to automatically add subtitles to videos. It eliminates the need for manual transcription, making videos more accessible. The tool uses OpenAI's Whisper, a State-of-the-Art speech recognition system trained on a large dataset for improved robustness to accents, background noise, and technical language.
README:
AI-generated transcription subtitles are a way to automatically add subtitles to your videos by using artificial intelligence to transcribe the audio from the video. This eliminates the need for manual transcription and can make your videos more accessible to a wider audience. Decipher uses whisper to transcribe the audio taken from the video and create subtitles
Whisper is an automatic State-of-the-Art speech recognition system from OpenAI that has been trained on 680,000 hours of multilingual and multitask supervised data collected from the web. This large and diverse dataset leads to improved robustness to accents, background noise and technical language.
There are two different ways to begin using decipher, depending on your preferences:
Notes:
- Requires a (free) Google account
- Instructions are embedded in the Colab Notebook
Google Colab is a cloud-based platform for machine learning and data science, for free without the need for a powerful GPU of your own. It offers the option to borrow a powerful GPU (Tesla K80, T4, P4, or P100) on their server for free for a maximum of 12 hours per session. For those who require even more powerful GPUs and longer runtimes, Colab Pro/Pro+ options are available.
pip install git+https://github.com/dsymbol/decipher
or
git clone https://github.com/dsymbol/decipher
cd decipher && pip install .
Note: Do NOT use 'pip install decipher'. It installs a different package.
decipher gui
# or
python -m decipher guiThe transcribe subcommand allows you to transcribe a video file into a SubRip Subtitle (SRT) file.
It also has the option to automatically add the generated subtitles to the video.
The subtitle subcommand allows you to add subtitles to a video using an already existing SRT file.
This subcommand does not perform transcription, but rather assumes that the SRT file has already been created.
It is typically used by people who want to validate the accuracy of a transcription generated by the transcribe subcommand.
To get started right away:
decipher --helpYou can run decipher as a package if running it as a script doesn't work:
python -m decipher --helpGenerate SRT subtitles for video:
decipher transcribe -i video.mp4 --model smallBurn generated subtitles into video:
decipher subtitle -i video.mp4 --subtitle_file video.srt --subtitle_action burnGenerate and burn subtitles into video without validating transcription:
decipher transcribe -i video.mp4 --model small --subtitle_action burnFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for decipher
Similar Open Source Tools
decipher
Decipher is a tool that utilizes AI-generated transcription subtitles to automatically add subtitles to videos. It eliminates the need for manual transcription, making videos more accessible. The tool uses OpenAI's Whisper, a State-of-the-Art speech recognition system trained on a large dataset for improved robustness to accents, background noise, and technical language.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.
vector_companion
Vector Companion is an AI tool designed to act as a virtual companion on your computer. It consists of two personalities, Axiom and Axis, who can engage in conversations based on what is happening on the screen. The tool can transcribe audio output and user microphone input, take screenshots, and read text via OCR to create lifelike interactions. It requires specific prerequisites to run on Windows and uses VB Cable to capture audio. Users can interact with Axiom and Axis by running the main script after installation and configuration.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.
MusicGPT
MusicGPT is an application that allows running the latest music generation AI models locally in a performant way, supporting different music generation models transparently to the user. It can be interacted with through UI mode or CLI mode, generating music based on natural language prompts. The tool requires access to storage to save downloaded models and generated audios along with metadata. It is licensed under MIT License for the code and CC-BY-NC-4.0 License for the AI model weights.
ai-clone-whatsapp
This repository provides a tool to create an AI chatbot clone of yourself using your WhatsApp chats as training data. It utilizes the Torchtune library for finetuning and inference. The code includes preprocessing of WhatsApp chats, finetuning models, and chatting with the AI clone via a command-line interface. Supported models are Llama3-8B-Instruct and Mistral-7B-Instruct-v0.2. Hardware requirements include approximately 16 GB vRAM for QLoRa Llama3 finetuning with a 4k context length. The repository addresses common issues like adjusting parameters for training and preprocessing non-English chats.
whisplay-ai-chatbot
Whisplay-AI-Chatbot is a pocket-sized AI chatbot device built using a Raspberry Pi Zero 2w. It features a PiSugar Whisplay HAT with an LCD screen, on-board speaker, and microphone. Users can interact with the chatbot by pressing a button, speaking, and receiving responses, similar to a futuristic walkie-talkie. The tool supports various functionalities such as adjusting volume autonomously, resetting conversation history, local ASR and TTS capabilities, image generation, and integration with APIs like Google Gemini and Grok. It also offers support for LLM8850 AI Accelerator for offline capabilities like ASR, TTS, and LLM API. The chatbot saves conversation history and generated images in a data folder, and users can customize the tool with different enclosure cases available for Pi02 and Pi5 models.
AlwaysReddy
AlwaysReddy is a simple LLM assistant with no UI that you interact with entirely using hotkeys. It can easily read from or write to your clipboard, and voice chat with you via TTS and STT. Here are some of the things you can use AlwaysReddy for: - Explain a new concept to AlwaysReddy and have it save the concept (in roughly your words) into a note. - Ask AlwaysReddy "What is X called?" when you know how to roughly describe something but can't remember what it is called. - Have AlwaysReddy proofread the text in your clipboard before you send it. - Ask AlwaysReddy "From the comments in my clipboard, what do the r/LocalLLaMA users think of X?" - Quickly list what you have done today and get AlwaysReddy to write a journal entry to your clipboard before you shutdown the computer for the day.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.

ComfyUI-TopazVideoAI
ComfyUI-TopazVideoAI is a tool designed to facilitate the usage of TopazVideoAI for creating short AI-generated videos. Users can connect this node between video output and video save to enhance the quality of videos. The tool requires a licensed installation of TopazVideoAI and provides instructions for setting up environment variables and paths. It is recommended to use upscale factors of 2 or 4 to avoid errors. The tool encodes and decodes videos as image batches, which may result in longer processing times compared to the TopazVideoAI GUI. Common errors include 'No such filter: 'tvai_up'' which can be resolved by ensuring the correct ffmpeg path and removing conflicting ffmpeg installations.
ChatGPT-OpenAI-Smart-Speaker
ChatGPT Smart Speaker is a project that enables speech recognition and text-to-speech functionalities using OpenAI and Google Speech Recognition. It provides scripts for running on PC/Mac and Raspberry Pi, allowing users to interact with a smart speaker setup. The project includes detailed instructions for setting up the required hardware and software dependencies, along with customization options for the OpenAI model engine, language settings, and response randomness control. The Raspberry Pi setup involves utilizing the ReSpeaker hardware for voice feedback and light shows. The project aims to offer an advanced smart speaker experience with features like wake word detection and response generation using AI models.
second-brain-agent
The Second Brain AI Agent Project is a tool designed to empower personal knowledge management by automatically indexing markdown files and links, providing a smart search engine powered by OpenAI, integrating seamlessly with different note-taking methods, and enhancing productivity by accessing information efficiently. The system is built on LangChain framework and ChromaDB vector store, utilizing a pipeline to process markdown files and extract text and links for indexing. It employs a Retrieval-augmented generation (RAG) process to provide context for asking questions to the large language model. The tool is beneficial for professionals, students, researchers, and creatives looking to streamline workflows, improve study sessions, delve deep into research, and organize thoughts and ideas effortlessly.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.
renumics-rag
Renumics RAG is a retrieval-augmented generation assistant demo that utilizes LangChain and Streamlit. It provides a tool for indexing documents and answering questions based on the indexed data. Users can explore and visualize RAG data, configure OpenAI and Hugging Face models, and interactively explore questions and document snippets. The tool supports GPU and CPU setups, offers a command-line interface for retrieving and answering questions, and includes a web application for easy access. It also allows users to customize retrieval settings, embeddings models, and database creation. Renumics RAG is designed to enhance the question-answering process by leveraging indexed documents and providing detailed answers with sources.
For similar tasks
OpenAI-Whisper-GUI
OpenAI Whisper GUI is a modern GUI application designed to transcribe and translate audio/video files using OpenAI Whisper. It features a modern UI with light/dark mode, the ability to export transcribed text, add subtitles to videos, and more. The latest version includes updates to widgets, layouts, and themes, as well as new features such as a config handler, GPU info retrieval, a new app logo, settings interface, and bug fixes like code refactoring and fixing Cuda not found warning message. Users can easily install the tool by cloning the GitHub repository and running setup.py and main.py scripts. For more information, users can visit the OpenAI Whisper GitHub repository.
decipher
Decipher is a tool that utilizes AI-generated transcription subtitles to automatically add subtitles to videos. It eliminates the need for manual transcription, making videos more accessible. The tool uses OpenAI's Whisper, a State-of-the-Art speech recognition system trained on a large dataset for improved robustness to accents, background noise, and technical language.
story-flicks
This project enables users to create story videos by inputting a story theme, utilizing a large language model to generate AI-generated images, story content, audio, and subtitles. The backend is built with Python and FastAPI, while the frontend utilizes React, Ant Design, and Vite.
Chenyme-AAVT
Chenyme-AAVT is a user-friendly tool that provides automatic video and audio recognition and translation. It leverages the capabilities of Whisper, a powerful speech recognition model, to accurately identify speech in videos and audios. The recognized speech is then translated using ChatGPT or KIMI, ensuring high-quality translations. With Chenyme-AAVT, you can quickly generate字幕 files and merge them with the original video, making video translation a breeze. The tool supports various languages, allowing you to translate videos and audios into your desired language. Additionally, Chenyme-AAVT offers features such as VAD (Voice Activity Detection) to enhance recognition accuracy, GPU acceleration for faster processing, and support for multiple字幕 formats. Whether you're a content creator, translator, or anyone looking to make video translation more efficient, Chenyme-AAVT is an invaluable tool.
MoneyPrinterTurbo
MoneyPrinterTurbo is a tool that can automatically generate video content based on a provided theme or keyword. It can create video scripts, materials, subtitles, and background music, and then compile them into a high-definition short video. The tool features a web interface and an API interface, supporting AI-generated video scripts, customizable scripts, multiple HD video sizes, batch video generation, customizable video segment duration, multilingual video scripts, multiple voice synthesis options, subtitle generation with font customization, background music selection, access to high-definition and copyright-free video materials, and integration with various AI models like OpenAI, moonshot, Azure, and more. The tool aims to simplify the video creation process and offers future plans to enhance voice synthesis, add video transition effects, provide more video material sources, offer video length options, include free network proxies, enable real-time voice and music previews, support additional voice synthesis services, and facilitate automatic uploads to YouTube platform.
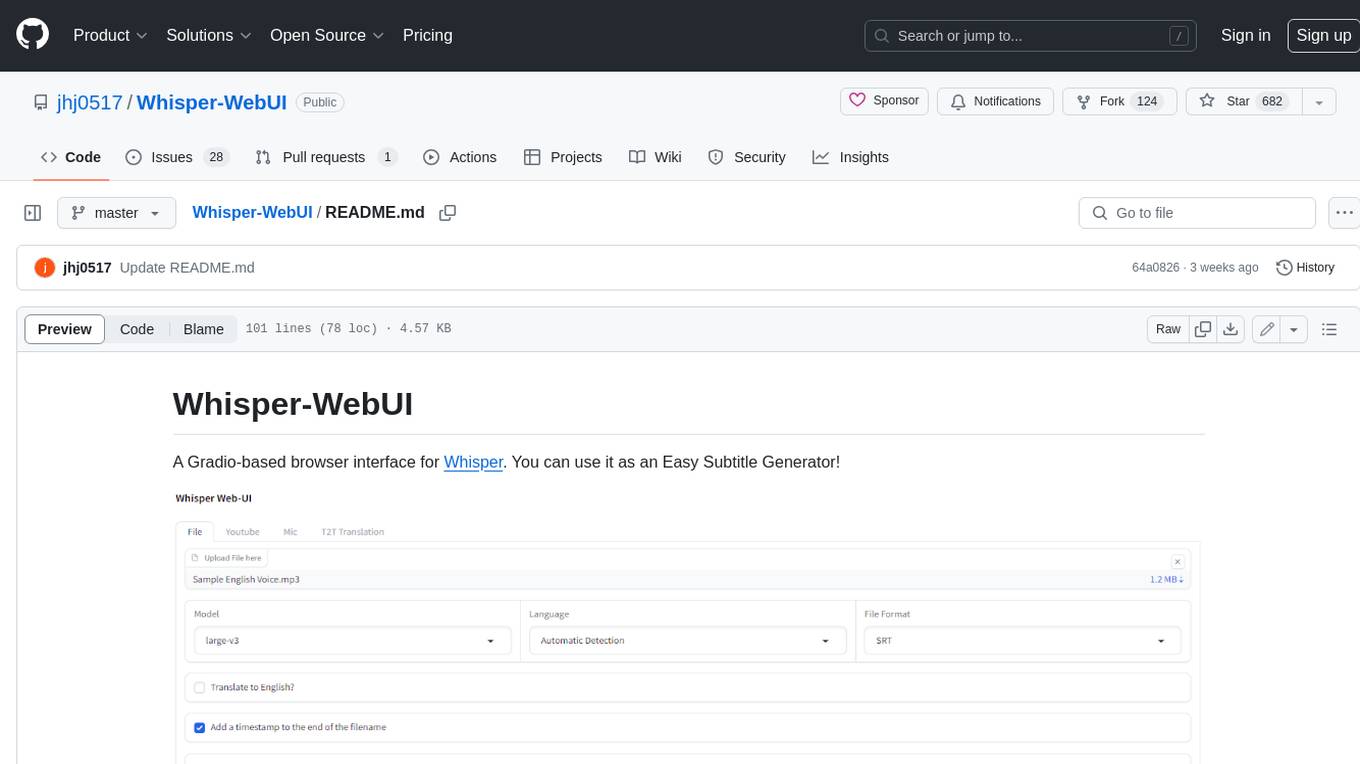
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.