
MusicGPT
Generate music based on natural language prompts using LLMs running locally
Stars: 793
MusicGPT is an application that allows running the latest music generation AI models locally in a performant way, supporting different music generation models transparently to the user. It can be interacted with through UI mode or CLI mode, generating music based on natural language prompts. The tool requires access to storage to save downloaded models and generated audios along with metadata. It is licensed under MIT License for the code and CC-BY-NC-4.0 License for the AI model weights.
README:
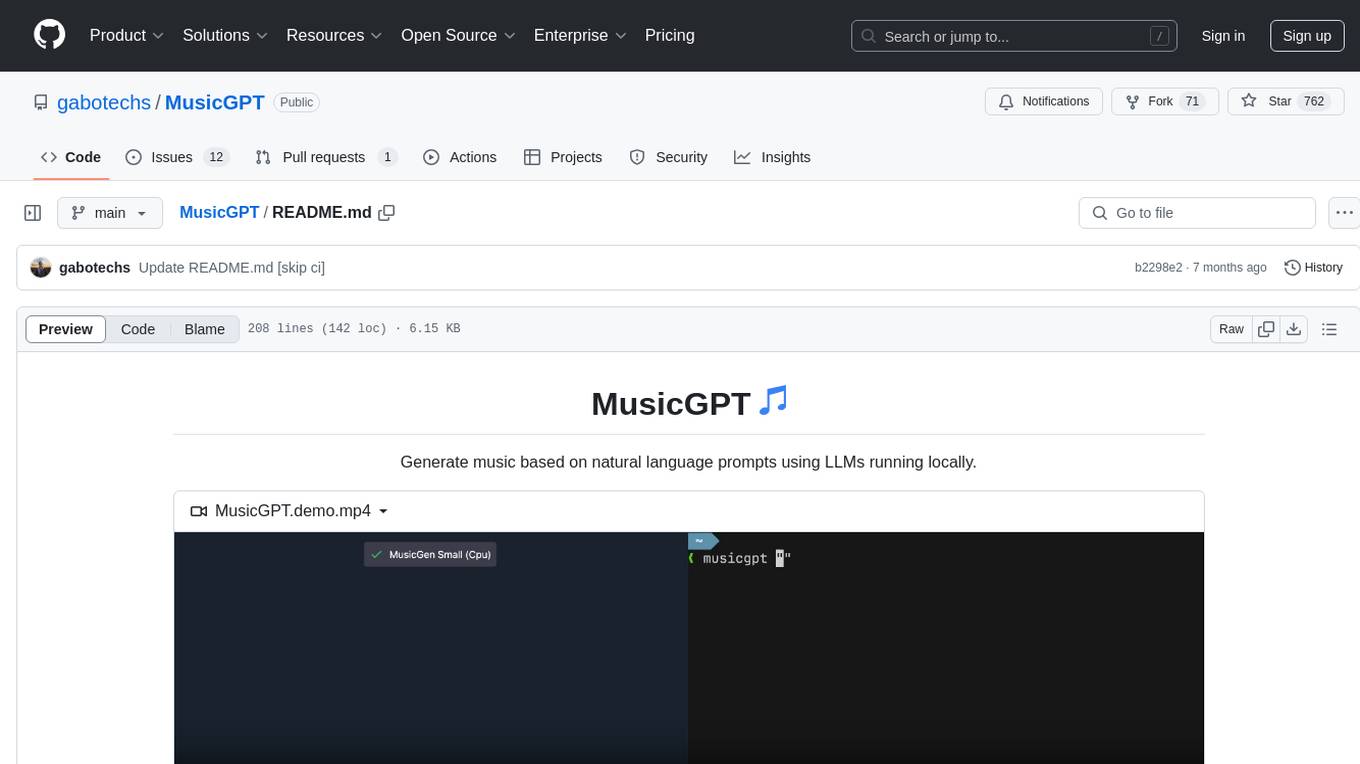
Generate music based on natural language prompts using LLMs running locally.
https://github.com/gabotechs/MusicGPT/assets/45515538/f0276e7c-70e5-42fc-817a-4d9ee9095b4c
☝️ Turn up the volume!
MusicGPT is an application that allows running the latest music generation AI models locally in a performant way, in any platform and without installing heavy dependencies like Python or machine learning frameworks.
Right now it only supports MusicGen by Meta, but the plan is to support different music generation models transparently to the user.
The main milestones for the project are:
- [x] Text conditioned music generation
- [ ] Melody conditioned music generation
- [ ] Indeterminately long / infinite music streams
MusicGPT can be installed on Mac and Linux using brew:
brew install gabotechs/taps/musicgptDownload and install MusicGPT's executable file following this link.
Precompiled binaries are available for the following platforms:
Just downloading them and executing them should be enough.
If you want to run MusicGPT with a CUDA enabled GPU, this is the best way, as you only need to have the basic NVIDIA drivers installed in your system.
docker pull gabotechs/musicgptOnce the image is downloaded, you can run it with:
docker run -it --gpus all -p 8642:8642 -v ~/.musicgpt:/root/.local/share/musicgpt gabotechs/musicgpt --gpu --ui-exposeIf you have the Rust toolchain installed in your system, you can install it
with cargo.
cargo install musicgptThere are two ways of interacting with MusicGPT: the UI mode and the CLI mode.
This mode will display a chat-like web application for exchanging prompts with the LLM. It will:
- store your chat history
- allow you to play the generated music samples whenever you want
- generate music samples in the background
- allow you to use the UI in a device different from the one executing the LLMs
You can run the UI by just executing the following command:
musicgptYou can also choose different models for running inference, and whether to use a GPU or not, for example:
musicgpt --gpu --model medium[!WARNING]
Most models require really powerful hardware for running inference
If you want to use a CUDA enabled GPU, it's recommended that you run MusicGPT with Docker:
docker run -it --gpus all -p 8642:8642 -v ~/.musicgpt:/root/.local/share/musicgpt gabotechs/musicgpt --ui-expose --gpuThis mode will generate and play music directly in the terminal, allowing you to provide multiple prompts and playing audio as soon as it's generated. You can generate audio based on a prompt with the following command:
musicgpt "Create a relaxing LoFi song"By default, it produces a sample of 10s, which can be configured up to 30s:
musicgpt "Create a relaxing LoFi song" --secs 30There's multiple models available, it will use the smallest one by default, but you can opt into a bigger model:
musicgpt "Create a relaxing LoFi song" --model medium[!WARNING]
Most models require really powerful hardware for running inference
If you want to use a CUDA enabled GPU, it's recommended that you run MusicGPT with Docker:
docker run -it --gpus all -v ~/.musicgpt:/root/.local/share/musicgpt gabotechs/musicgpt --gpu "Create a relaxing LoFi song"You can review all the options available running:
musicgpt --helpThe following graph shows the inference time taken for generating 10 seconds of audio using different models on a Mac M1 Pro. For comparison, it's Python equivalent using https://github.com/huggingface/transformers is shown.
The command used for generating the 10 seconds of audio was:
musicgpt '80s pop track with bassy drums and synth'This is the Python script used for generating the 10 seconds of audio
import scipy
import time
from transformers import AutoProcessor, MusicgenForConditionalGeneration
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
inputs = processor(
text=["80s pop track with bassy drums and synth"],
padding=True,
return_tensors="pt",
)
start = time.time()
audio_values = model.generate(**inputs, max_new_tokens=500)
print(time.time() - start) # Log time taken in generation
sampling_rate = model.config.audio_encoder.sampling_rate
scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].numpy())
MusicGPT needs access to your storage in order to save downloaded models and generated audios along with some
metadata needed for the application to work properly. Assuming your username is foo, it will store the data
in the following locations:
- Windows:
C:\Users\foo\AppData\Roaming\gabotechs\musicgpt - MacOS:
/Users/foo/Library/Application\ Support/com.gabotechs.musicgpt - Linux:
/home/foo/.config/musicgpt
The code is licensed under a MIT License, but the AI model weights that get downloaded at application startup are licensed under the CC-BY-NC-4.0 License as they are generated based on the following repositories:
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MusicGPT
Similar Open Source Tools
MusicGPT
MusicGPT is an application that allows running the latest music generation AI models locally in a performant way, supporting different music generation models transparently to the user. It can be interacted with through UI mode or CLI mode, generating music based on natural language prompts. The tool requires access to storage to save downloaded models and generated audios along with metadata. It is licensed under MIT License for the code and CC-BY-NC-4.0 License for the AI model weights.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.

llamafile
llamafile is a tool that enables users to distribute and run Large Language Models (LLMs) with a single file. It combines llama.cpp with Cosmopolitan Libc to create a framework that simplifies the complexity of LLMs into a single-file executable called a 'llamafile'. Users can run these executable files locally on most computers without the need for installation, making open LLMs more accessible to developers and end users. llamafile also provides example llamafiles for various LLM models, allowing users to try out different LLMs locally. The tool supports multiple CPU microarchitectures, CPU architectures, and operating systems, making it versatile and easy to use.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.
vector_companion
Vector Companion is an AI tool designed to act as a virtual companion on your computer. It consists of two personalities, Axiom and Axis, who can engage in conversations based on what is happening on the screen. The tool can transcribe audio output and user microphone input, take screenshots, and read text via OCR to create lifelike interactions. It requires specific prerequisites to run on Windows and uses VB Cable to capture audio. Users can interact with Axiom and Axis by running the main script after installation and configuration.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
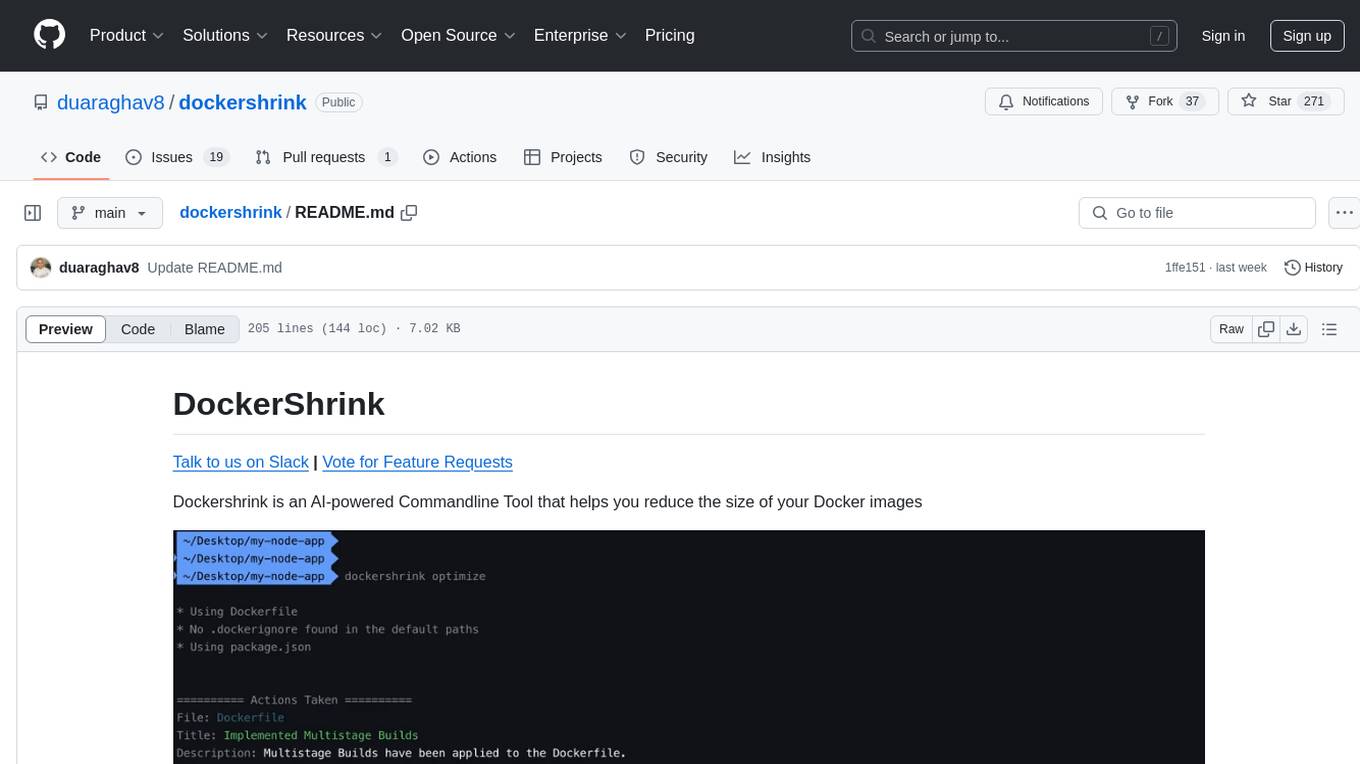
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.
LLM_AppDev-HandsOn
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.
ai-town
AI Town is a virtual town where AI characters live, chat, and socialize. This project provides a deployable starter kit for building and customizing your own version of AI Town. It features a game engine, database, vector search, auth, text model, deployment, pixel art generation, background music generation, and local inference. You can customize your own simulation by creating characters and stories, updating spritesheets, changing the background, and modifying the background music.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
For similar tasks
MusicGPT
MusicGPT is an application that allows running the latest music generation AI models locally in a performant way, supporting different music generation models transparently to the user. It can be interacted with through UI mode or CLI mode, generating music based on natural language prompts. The tool requires access to storage to save downloaded models and generated audios along with metadata. It is licensed under MIT License for the code and CC-BY-NC-4.0 License for the AI model weights.
markpdfdown
MarkPDFDown is a powerful tool that leverages multimodal large language models to transcribe PDF files into Markdown format. It simplifies the process of converting PDF documents into clean, editable Markdown text by accurately extracting text, preserving formatting, and handling complex document structures including tables, formulas, and diagrams.
Bavarder
Bavarder is an AI-powered chit-chat tool designed for informal conversations about unimportant matters. Users can engage in light-hearted discussions with the AI, simulating casual chit-chat scenarios. The tool provides a platform for users to interact with AI in a fun and entertaining way, offering a unique experience of engaging with artificial intelligence in a conversational manner.

ChaKt-KMP
ChaKt is a multiplatform app built using Kotlin and Compose Multiplatform to demonstrate the use of Generative AI SDK for Kotlin Multiplatform to generate content using Google's Generative AI models. It features a simple chat based user interface and experience to interact with AI. The app supports mobile, desktop, and web platforms, and is built with Kotlin Multiplatform, Kotlin Coroutines, Compose Multiplatform, Generative AI SDK, Calf - File picker, and BuildKonfig. Users can contribute to the project by following the guidelines in CONTRIBUTING.md. The app is licensed under the MIT License.
Neurite
Neurite is an innovative project that combines chaos theory and graph theory to create a digital interface that explores hidden patterns and connections for creative thinking. It offers a unique workspace blending fractals with mind mapping techniques, allowing users to navigate the Mandelbrot set in real-time. Nodes in Neurite represent various content types like text, images, videos, code, and AI agents, enabling users to create personalized microcosms of thoughts and inspirations. The tool supports synchronized knowledge management through bi-directional synchronization between mind-mapping and text-based hyperlinking. Neurite also features FractalGPT for modular conversation with AI, local AI capabilities for multi-agent chat networks, and a Neural API for executing code and sequencing animations. The project is actively developed with plans for deeper fractal zoom, advanced control over node placement, and experimental features.
weixin-dyh-ai
WeiXin-Dyh-AI is a backend management system that supports integrating WeChat subscription accounts with AI services. It currently supports integration with Ali AI, Moonshot, and Tencent Hyunyuan. Users can configure different AI models to simulate and interact with AI in multiple modes: text-based knowledge Q&A, text-to-image drawing, image description, text-to-voice conversion, enabling human-AI conversations on WeChat. The system allows hierarchical AI prompt settings at system, subscription account, and WeChat user levels. Users can configure AI model types, providers, and specific instances. The system also supports rules for allocating models and keys at different levels. It addresses limitations of WeChat's messaging system and offers features like text-based commands and voice support for interactions with AI.
Senparc.AI
Senparc.AI is an AI extension package for the Senparc ecosystem, focusing on LLM (Large Language Models) interaction. It provides modules for standard interfaces and basic functionalities, as well as interfaces using SemanticKernel for plug-and-play capabilities. The package also includes a library for supporting the 'PromptRange' ecosystem, compatible with various systems and frameworks. Users can configure different AI platforms and models, define AI interface parameters, and run AI functions easily. The package offers examples and commands for dialogue, embedding, and DallE drawing operations.
catai
CatAI is a tool that allows users to run GGUF models on their computer with a chat UI. It serves as a local AI assistant inspired by Node-Llama-Cpp and Llama.cpp. The tool provides features such as auto-detecting programming language, showing original messages by clicking on user icons, real-time text streaming, and fast model downloads. Users can interact with the tool through a CLI that supports commands for installing, listing, setting, serving, updating, and removing models. CatAI is cross-platform and supports Windows, Linux, and Mac. It utilizes node-llama-cpp and offers a simple API for asking model questions. Additionally, developers can integrate the tool with node-llama-cpp@beta for model management and chatting. The configuration can be edited via the web UI, and contributions to the project are welcome. The tool is licensed under Llama.cpp's license.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.