
moai
moai is a PyTorch-based AI Model Development Kit (MDK) created to improve data-driven model workflows, design and reproducibility.
Stars: 53
moai is a PyTorch-based AI Model Development Kit (MDK) designed to improve data-driven model workflows, design, and understanding. It offers modularity via monads for model building blocks, reproducibility via configuration-based design, productivity via a data-driven domain modelling language (DML), extensibility via plugins, and understanding via inter-model performance and design aggregation. The tool provides specific integrated actions like play, train, evaluate, plot, diff, and reprod to support heavy data-driven workflows with analytics, knowledge extraction, and reproduction. moai relies on PyTorch, Lightning, Hydra, TorchServe, ONNX, Visdom, HiPlot, Kornia, Albumentations, and the wider open-source community for its functionalities.
README:
moai is a PyTorch-based AI Model Development Kit (MDK) that aims to improve data-driven model workflows, design and understanding. Since it is based on established open-source packages, it can be readily used to improve most AI workflows. To explore moai, simply install the package and follow the examples, having in mind that it is in early development alpha version, thus new features will be available soon.


- Modularity via Monads: Use moai's existing pool of modular model building blocks.
- Reproducibility via Configuration: moai manages the hyper-parameter sensitive AI R&D workflows via its built-in configuration-based design.
- Productivity via Minimizing Coding: moai offers a data-driven domain modelling language (DML) that can facilitate quick & easy model design.
- Extensibility via Plugins: Easily integrate external code using moai's built-in metaprogramming and external code integration.
- Understanding via Analysis: moai supports inter-model performance and design aggregation actions to consolidate knowledge between models and query differences.
moai offers a set of data-driven workflow functionalities through specific integrated actions. These consume moai configuration files that describe each action's executed context. As moai is built around these configuration files that define its context and describe each model's details, it offers actions that support heavy data-driven workflows with inter-model analytics, knowledge extraction and meticulous reproduction.
Details for each action follow:
-
moaiplayCONFIG_PATH


Using the play action, moai starts the playback of a dataset's train\val\test splits. moai's exporters can be used to the extract dataset specific statistics. moai's visualization engine can be used to showcase the dataset. Optionally, monad processing graphs can be defined to transform the data.
-
moaitrainCONFIG_PATH


The train action consumes a configuration file that defines the model that will be trained, the data that will be used to train and validate it, as well as configurating the engine around the training process.
The results include model states across training and logs including validation metrics and losses.
-
moaievaluateCONFIG_PATH


The evaluate action consumes a configuration file that defines the trained model that will be tested, the test data, as well as configurating the engine around the testing process.
The results include model aggregated and/or detailed metrics, and inference samples.
-
moaiplotPATH_TO_EXPERIMENTS


The plot action consumes various configuration files - usually from different versions of the same model - and generates a visualization consolidating and aggregating inter-model performance, providing the necessary means to analyze the behaviour of different hyper-parameters or model configurations.
-
moaidifflhs=PATH_TO_CONFIG_Arhs=PATH_TO_CONFIG_B


The diff action consumes two different configuration file - usually from different versions of the same model - and reports their differences related to hyper-parameterization, processing graph variations, etc..
-
moaireprodPATH_TO_RESOLVED_CONFIG


The reprod action consumes a previously logged and resolved configuration file, and facilitates its reproduction by re-executing it while adjusting to development environment differences.
moai stands on the shoulders of giants as it relies on various large scale open-source projects:
-
> 1.7.0needs to be customly installed on your system/environment. -
> 1.0.0is the currently supported training backend. -
Hydra
> 1.0drives moai's DML that sets up model configurations, and additionally manages the hyper-parameter complexity of modern AI models. -
> 0.5.3is needed to deploy models as services. -
> 1.11.0is needed to export models in an exchangeable format. -
Visdom is the currently supported visualization engine.
-
HiPlot drives moai's inter-model analytics.
-
Various PyTorch Open Source Projects:
- Kornia for a set of computer vision operations integrated as moai monads.
- Albumentations as the currently supported data augmentation framework.
-
The Wider Open Source Community that conducts accessible R&D and drives most of moai's capabilities.
To install the latest released moai package run:
pip install moai-mdk
Download the master branch source and install it by opening a command line on the source directory and running:
pip install . or pip install -e . (in editable form)
Visit the documentation site to learn about moai's DML and the overall MDK design and usage.
Examples can be found at conf/examples.
moai is Apache 2.0 licenced, as found in the corresponding LICENCE file.
However, some code integrated from external projects may carry their own licences.


If you use moai in your R&D workflows or find its code useful please consider citing:
@misc{moai,
key = {moai: PyTorch Model Development Kit},
title = {{\textit{moai}: Accelerating modern data-driven workflows}},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/moverseai/moai}},
}
Use a GitHub issue tracker
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for moai
Similar Open Source Tools
moai
moai is a PyTorch-based AI Model Development Kit (MDK) designed to improve data-driven model workflows, design, and understanding. It offers modularity via monads for model building blocks, reproducibility via configuration-based design, productivity via a data-driven domain modelling language (DML), extensibility via plugins, and understanding via inter-model performance and design aggregation. The tool provides specific integrated actions like play, train, evaluate, plot, diff, and reprod to support heavy data-driven workflows with analytics, knowledge extraction, and reproduction. moai relies on PyTorch, Lightning, Hydra, TorchServe, ONNX, Visdom, HiPlot, Kornia, Albumentations, and the wider open-source community for its functionalities.

slideflow
Slideflow is a deep learning library for digital pathology, offering a user-friendly interface for model development. It is designed for medical researchers and AI enthusiasts, providing an accessible platform for developing state-of-the-art pathology models. Slideflow offers customizable training pipelines, robust slide processing and stain normalization toolkit, support for weakly-supervised or strongly-supervised labels, built-in foundation models, multiple-instance learning, self-supervised learning, generative adversarial networks, explainability tools, layer activation analysis tools, uncertainty quantification, interactive user interface for model deployment, and more. It supports both PyTorch and Tensorflow, with optional support for Libvips for slide reading. Slideflow can be installed via pip, Docker container, or from source, and includes non-commercial add-ons for additional tools and pretrained models. It allows users to create projects, extract tiles from slides, train models, and provides evaluation tools like heatmaps and mosaic maps.
llm-interface
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.
modelscope-agent
ModelScope-Agent is a customizable and scalable Agent framework. A single agent has abilities such as role-playing, LLM calling, tool usage, planning, and memory. It mainly has the following characteristics: - **Simple Agent Implementation Process**: Simply specify the role instruction, LLM name, and tool name list to implement an Agent application. The framework automatically arranges workflows for tool usage, planning, and memory. - **Rich models and tools**: The framework is equipped with rich LLM interfaces, such as Dashscope and Modelscope model interfaces, OpenAI model interfaces, etc. Built in rich tools, such as **code interpreter**, **weather query**, **text to image**, **web browsing**, etc., make it easy to customize exclusive agents. - **Unified interface and high scalability**: The framework has clear tools and LLM registration mechanism, making it convenient for users to expand more diverse Agent applications. - **Low coupling**: Developers can easily use built-in tools, LLM, memory, and other components without the need to bind higher-level agents.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

easy-dataset
Easy Dataset is a specialized application designed to streamline the creation of fine-tuning datasets for Large Language Models (LLMs). It offers an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning. With Easy Dataset, users can transform domain knowledge into structured datasets compatible with all OpenAI-format compatible LLM APIs, making the fine-tuning process accessible and efficient.
fastserve-ai
FastServe-AI is a machine learning serving tool focused on GenAI & LLMs with simplicity as the top priority. It allows users to easily serve custom models by implementing the 'handle' method for 'FastServe'. The tool provides a FastAPI server for custom models and can be deployed using Lightning AI Studio. Users can install FastServe-AI via pip and run it to serve their own GPT-like LLM models in minutes.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.
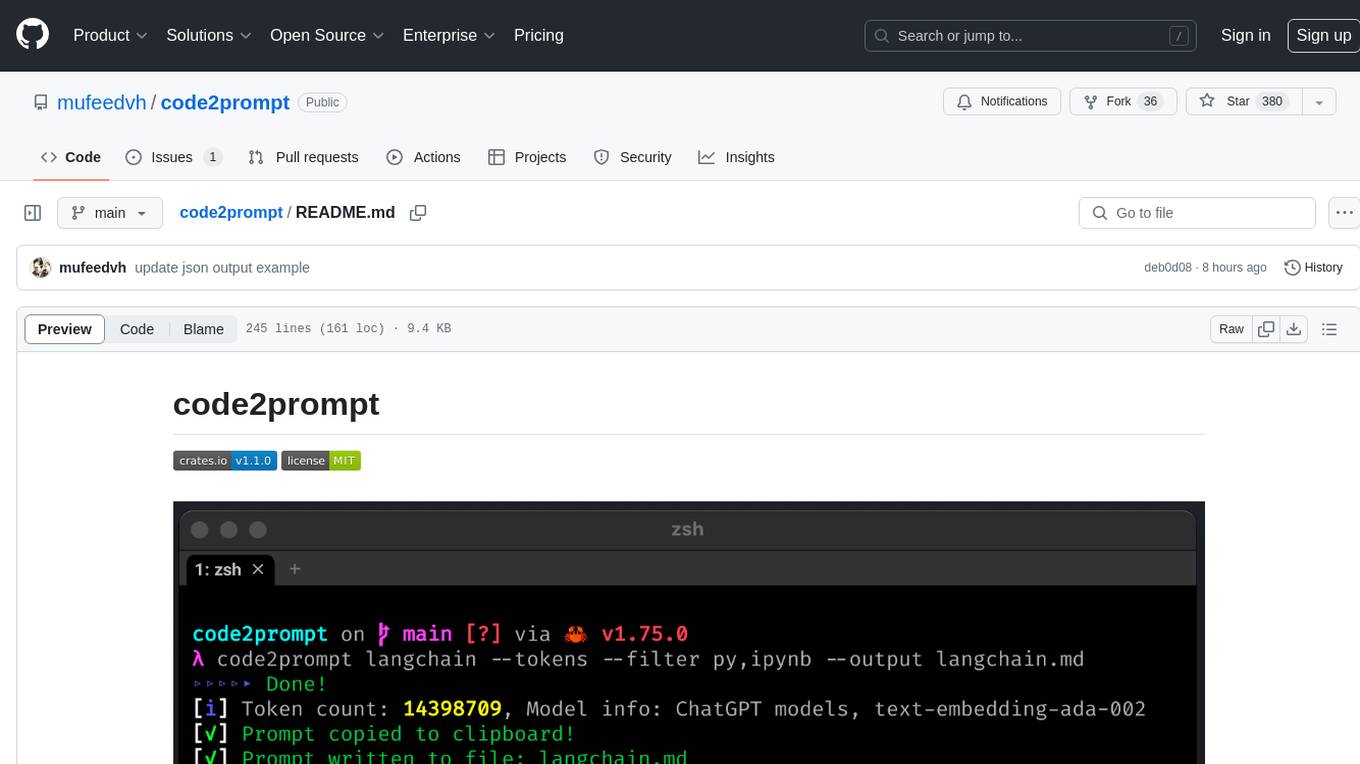
code2prompt
code2prompt is a command-line tool that converts your codebase into a single LLM prompt with a source tree, prompt templating, and token counting. It automates generating LLM prompts from codebases of any size, customizing prompt generation with Handlebars templates, respecting .gitignore, filtering and excluding files using glob patterns, displaying token count, including Git diff output, copying prompt to clipboard, saving prompt to an output file, excluding files and folders, adding line numbers to source code blocks, and more. It helps streamline the process of creating LLM prompts for code analysis, generation, and other tasks.
NExT-GPT
NExT-GPT is an end-to-end multimodal large language model that can process input and generate output in various combinations of text, image, video, and audio. It leverages existing pre-trained models and diffusion models with end-to-end instruction tuning. The repository contains code, data, and model weights for NExT-GPT, allowing users to work with different modalities and perform tasks like encoding, understanding, reasoning, and generating multimodal content.
quickvid
QuickVid is an open-source video summarization tool that uses AI to generate summaries of YouTube videos. It is built with Whisper, GPT, LangChain, and Supabase. QuickVid can be used to save time and get the essence of any YouTube video with intelligent summarization.
Unity-MCP
Unity-MCP is an AI helper designed for game developers using Unity. It facilitates a wide range of tasks in Unity Editor and running games on any platform by connecting to AI via TCP connection. The tool allows users to chat with AI like with a human, supports local and remote usage, and offers various default AI tools. Users can provide detailed information for classes, fields, properties, and methods using the 'Description' attribute in C# code. Unity-MCP enables instant C# code compilation and execution, provides access to assets and C# scripts, and offers tools for proper issue understanding and project data manipulation. It also allows users to find and call methods in the codebase, work with Unity API, and access human-readable descriptions of code elements.

ichigo
Ichigo is a local real-time voice AI tool that uses an early fusion technique to extend a text-based LLM to have native 'listening' ability. It is an open research experiment with improved multiturn capabilities and the ability to refuse processing inaudible queries. The tool is designed for open data, open weight, on-device Siri-like functionality, inspired by Meta's Chameleon paper. Ichigo offers a web UI demo and Gradio web UI for users to interact with the tool. It has achieved enhanced MMLU scores, stronger context handling, advanced noise management, and improved multi-turn capabilities for a robust user experience.
open-mercato
Open Mercato is a modern, AI-supportive platform designed for shipping enterprise-grade CRMs, ERPs, and commerce backends. It offers modular architecture, custom entities, multi-tenancy, RBAC, data indexing, event workflows, and more. The tool is built with a modern stack including Next.js, TypeScript, zod, Awilix DI, MikroORM, and bcryptjs. It also features an AI Assistant for schema discovery, API execution, and hybrid search. Open Mercato provides data encryption, migration guides, Docker setups, standalone app creation, and follows a spec-driven development approach. The Enterprise Edition offers additional support, SLA options, and advanced features beyond the open-source Core version.
biniou
biniou is a self-hosted webui for various GenAI (generative artificial intelligence) tasks. It allows users to generate multimedia content using AI models and chatbots on their own computer, even without a dedicated GPU. The tool can work offline once deployed and required models are downloaded. It offers a wide range of features for text, image, audio, video, and 3D object generation and modification. Users can easily manage the tool through a control panel within the webui, with support for various operating systems and CUDA optimization. biniou is powered by Huggingface and Gradio, providing a cross-platform solution for AI content generation.
For similar tasks
moai
moai is a PyTorch-based AI Model Development Kit (MDK) designed to improve data-driven model workflows, design, and understanding. It offers modularity via monads for model building blocks, reproducibility via configuration-based design, productivity via a data-driven domain modelling language (DML), extensibility via plugins, and understanding via inter-model performance and design aggregation. The tool provides specific integrated actions like play, train, evaluate, plot, diff, and reprod to support heavy data-driven workflows with analytics, knowledge extraction, and reproduction. moai relies on PyTorch, Lightning, Hydra, TorchServe, ONNX, Visdom, HiPlot, Kornia, Albumentations, and the wider open-source community for its functionalities.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.