Best AI tools for< Computer Vision Researcher >
Infographic
20 - AI tool Sites
Joseph Chet Redmon's Computer Vision Platform
The website is a platform maintained by Joseph Chet Redmon, a graduate student working on computer vision. It features information on his projects, publications, talks, and teaching activities. The site also includes details about the Darknet Neural Network Framework, tactics in Coq, and research work. Visitors can learn about computer vision, object recognition, and visual question answering through the resources provided on the site.

Andreas Geiger
Andreas Geiger is a website belonging to the Autonomous Vision Group (AVG) at the University of Tübingen in Germany. The group focuses on developing machine learning models for computer vision, natural language, and robotics with applications in self-driving, VR/AR, and scientific document analysis. The website showcases the research activities, achievements, publications, and projects of the AVG team, led by Prof. Dr.-Ing. Andreas Geiger. It also provides information on the team members, contact details, and links to related resources and platforms.
Rendered.ai
Rendered.ai is a platform that provides unlimited synthetic data for AI and ML applications, specifically focusing on computer vision. It helps in generating low-cost physically-accurate data to overcome bias and power innovation in AI and ML. The platform allows users to capture rare events and edge cases, acquire data that is difficult to obtain, overcome data labeling challenges, and simulate restricted or high-risk scenarios. Rendered.ai aims to revolutionize the use of synthetic data in AI and data analytics projects, with a vision that by 2030, synthetic data will surpass real data in AI models.
DataVLab Solutions
DataVLab Solutions is an AI-powered platform offering comprehensive image annotation and data labeling services for AI applications. They provide high-quality, scalable, and ethical data labeling solutions to enhance AI and machine learning models. With expertise in image, video, 3D annotation, custom AI projects, NLP, and text annotation, DataVLab Solutions caters to various industries such as energy infrastructure, autonomous vehicles, agriculture, medical, e-commerce, and insurance. Their advanced annotation process accelerates data labeling, ensuring precision and efficiency. Leveraging AI-driven tools, they offer tailor-made annotation workflows for unique AI challenges, delivering high-quality annotations for computer vision models, dynamic data, and spatial AI. The platform also provides training data and fine-tuning support for Large Language Models and generative AI applications.
InsightFace
InsightFace is an open-source deep face analysis library that provides a rich variety of state-of-the-art algorithms for face recognition, detection, and alignment. It is designed to be efficient for both training and deployment, making it suitable for research institutions and industrial organizations. InsightFace has achieved top rankings in various challenges and competitions, including the ECCV 2022 WCPA Challenge, NIST-FRVT 1:1 VISA, and WIDER Face Detection Challenge 2019.

Caffe
Caffe is a deep learning framework developed by Berkeley AI Research (BAIR) and community contributors. It is designed for speed, modularity, and expressiveness, allowing users to define models and optimization through configuration without hard-coding. Caffe supports both CPU and GPU training, making it suitable for research experiments and industry deployment. The framework is extensible, actively developed, and tracks the state-of-the-art in code and models. Caffe is widely used in academic research, startup prototypes, and large-scale industrial applications in vision, speech, and multimedia.

Big Vision
Big Vision provides consulting services in AI, computer vision, and deep learning. They help businesses build specific AI-driven solutions, create intelligent processes, and establish best practices to reduce human effort and enable faster decision-making. Their enterprise-grade solutions are currently serving millions of requests every month, especially in critical production environments.
Roboflow
Roboflow is an AI tool designed for computer vision tasks, offering a platform that allows users to annotate, train, deploy, and perform inference on models. It provides integrations, ecosystem support, and features like notebooks, autodistillation, and supervision. Roboflow caters to various industries such as aerospace, agriculture, healthcare, finance, and more, with a focus on simplifying the development and deployment of computer vision models.
Lexset
Lexset is an AI tool that provides synthetic data generation services for computer vision model training. It offers a no-code interface to create unlimited data with advanced camera controls and lighting options. Users can simulate AI-scale environments, composite objects into images, and create custom 3D scenarios. Lexset also provides access to GPU nodes, dedicated support, and feature development assistance. The tool aims to improve object detection accuracy and optimize generalization on high-quality synthetic data.
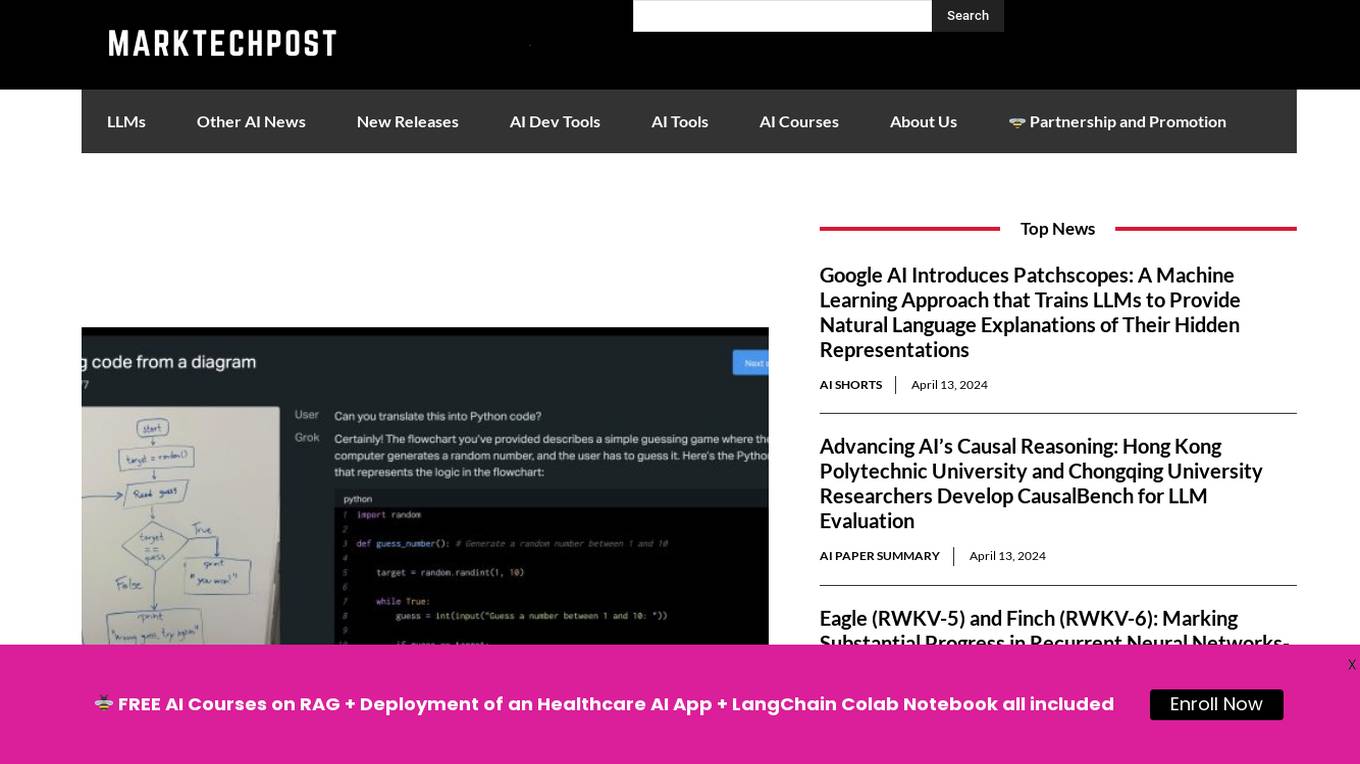
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.

Ultralytics YOLO
Ultralytics YOLO is an advanced real-time object detection and image segmentation model that leverages cutting-edge advancements in deep learning and computer vision. It offers unparalleled performance in terms of speed and accuracy, making it suitable for various applications and easily adaptable to different hardware platforms. The comprehensive Ultralytics Docs provide resources to help users understand and utilize its features and capabilities, catering to both seasoned machine learning practitioners and newcomers to the field.
syntheticAIdata
syntheticAIdata is a platform that provides synthetic data for training vision AI models. Synthetic data is generated artificially, and it can be used to augment existing real-world datasets or to create new datasets from scratch. syntheticAIdata's platform is easy to use, and it can be integrated with leading cloud platforms. The company's mission is to make synthetic data accessible to everyone, and to help businesses overcome the challenges of acquiring high-quality data for training their vision AI models.
GptDemo.Net
GptDemo.Net is a website that provides a directory of AI tools and resources. The website includes a search engine that allows users to find AI tools based on their needs. GptDemo.Net also provides news and updates on the latest AI developments.
Chessvision.ai
Chessvision.ai is an AI-powered eBook reader that leverages Artificial Intelligence and Computer Vision to make chess eBooks interactive. It supports PDF, ePub, and DjVu formats, allowing users to analyze chess diagrams, add comments, search positions online, watch YouTube videos, and analyze with the engine. The application has gained popularity among chess players of all levels for its ability to enhance the study and learning experience through innovative technology.
GeoInfer
GeoInfer is a professional AI-powered geolocation platform that analyzes photographs to determine where they were taken. It uses visual-only inference technology to examine visual elements like architecture, terrain, vegetation, and environmental markers to identify geographic locations without requiring GPS metadata or EXIF data. The platform offers transparent accuracy levels for different use cases, including a Global Model with 1km-100km accuracy ideal for regional and city-level identification. Additionally, GeoInfer provides custom regional models for organizations requiring higher precision, such as meter-level accuracy for specific geographic areas. The platform is designed for professionals in various industries, including law enforcement, insurance fraud investigation, digital forensics, and security research.
Robovision
Robovision is a central platform to manage vision intelligence inside smart machines. Successfully introduce AI in dynamic environments without the need for AI experts.
Orbbec
Orbbec is a leading provider of 3D vision technology, offering a wide range of 3D cameras and sensors for various applications. With a focus on AI, optics, and advanced algorithms, Orbbec empowers developers and enterprises to create immersive experiences, precise measurements, and advanced visualizations. Their products include stereo vision cameras, ToF cameras, structured light cameras, camera computers, and lidar sensors, catering to industries such as manufacturing, healthcare, robotics, fitness, logistics, and retail.

PaperClip
PaperClip is an AI tool designed to help users keep track of their daily AI papers review. It allows users to memorize details from papers in machine learning, computer vision, and natural language processing. The tool offers an extension to easily find back important findings from AI research papers, ML blog posts, and news. PaperClip's AI runs locally, ensuring data privacy by not sending any information to external servers. Users can save and index their findings locally, with offline support for searching even without an internet connection. The tool also provides the ability to clean data by resetting saved bits in one click.

Visual Computing & Artificial Intelligence Lab at TUM
The Visual Computing & Artificial Intelligence Lab at TUM is a group of research enthusiasts advancing cutting-edge research at the intersection of computer vision, computer graphics, and artificial intelligence. Our research mission is to obtain highly-realistic digital replica of the real world, which include representations of detailed 3D geometries, surface textures, and material definitions of both static and dynamic scene environments. In our research, we heavily build on advances in modern machine learning, and develop novel methods that enable us to learn strong priors to fuel 3D reconstruction techniques. Ultimately, we aim to obtain holographic representations that are visually indistinguishable from the real world, ideally captured from a simple webcam or mobile phone. We believe this is a critical component in facilitating immersive augmented and virtual reality applications, and will have a substantial positive impact in modern digital societies.
Synthesis AI
Synthesis AI is a synthetic data platform that enables more capable and ethical computer vision AI. It provides on-demand labeled images and videos, photorealistic images, and 3D generative AI to help developers build better models faster. Synthesis AI's products include Synthesis Humans, which allows users to create detailed images and videos of digital humans with rich annotations; Synthesis Scenarios, which enables users to craft complex multi-human simulations across a variety of environments; and a range of applications for industries such as ID verification, automotive, avatar creation, virtual fashion, AI fitness, teleconferencing, visual effects, and security.
34 - Open Source Tools

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.
ShapeLLM
ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. It supports single-view colored point cloud input and introduces a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants. The model extends the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks. ShapeLLM can be used for tasks such as training, zero-shot understanding, visual grounding, few-shot learning, and zero-shot learning on 3D MM-Vet.
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
mediapipe-rs
MediaPipe-rs is a Rust library designed for MediaPipe tasks on WasmEdge WASI-NN. It offers easy-to-use low-code APIs similar to mediapipe-python, with low overhead and flexibility for custom media input. The library supports various tasks like object detection, image classification, gesture recognition, and more, including TfLite models, TF Hub models, and custom models. Users can create task instances, run sessions for pre-processing, inference, and post-processing, and speed up processing by reusing sessions. The library also provides support for audio tasks using audio data from symphonia, ffmpeg, or raw audio. Users can choose between CPU, GPU, or TPU devices for processing.
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.
LL3DA
LL3DA is a Large Language 3D Assistant that responds to both visual and textual interactions within complex 3D environments. It aims to help Large Multimodal Models (LMM) comprehend, reason, and plan in diverse 3D scenes by directly taking point cloud input and responding to textual instructions and visual prompts. LL3DA achieves remarkable results in 3D Dense Captioning and 3D Question Answering, surpassing various 3D vision-language models. The code is fully released, allowing users to train customized models and work with pre-trained weights. The tool supports training with different LLM backends and provides scripts for tuning and evaluating models on various tasks.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.
FluxAIGridComparisons
FluxAIGridComparisons is a repository containing a collection of different image grids generated using Flux. These grids showcase various attributes such as hairstyles, clothing, nationalities, and ages. The repository serves as a visual comparison tool for exploring different characteristics within images.

Awesome-Robotics-3D
Awesome-Robotics-3D is a curated list of 3D Vision papers related to Robotics domain, focusing on large models like LLMs/VLMs. It includes papers on Policy Learning, Pretraining, VLM and LLM, Representations, and Simulations, Datasets, and Benchmarks. The repository is maintained by Zubair Irshad and welcomes contributions and suggestions for adding papers. It serves as a valuable resource for researchers and practitioners in the field of Robotics and Computer Vision.
ha-llmvision
LLM Vision is a Home Assistant integration that allows users to analyze images, videos, and camera feeds using multimodal LLMs. It supports providers such as OpenAI, Anthropic, Google Gemini, LocalAI, and Ollama. Users can input images and videos from camera entities or local files, with the option to downscale images for faster processing. The tool provides detailed instructions on setting up LLM Vision and each supported provider, along with usage examples and service call parameters.
DeepDanbooru
DeepDanbooru is an anime-style girl image tag estimation system written in Python. It allows users to estimate images using a live demo site. The tool requires specific packages to be installed and provides a structured dataset for training projects. Users can create training projects, download tags, filter datasets, and start training to estimate tags for images. The tool uses a specific dataset structure and project structure to facilitate the training process.
IG-LLM
IG-LLM is a framework for solving inverse-graphics problems by instruction-tuning a Large Language Model (LLM) to decode visual embeddings into graphics code. The framework demonstrates natural generalization across distribution shifts without special inductive biases. It provides training and evaluation data for various scenarios like CLEVR, 2D, SO(3), 6-DoF, and ShapeNet. The environment setup can be done using conda/micromamba or Dockerfile. Training can be initiated for each scenario with specific commands, and inference can be performed using the provided script.
TokenPacker
TokenPacker is a novel visual projector that compresses visual tokens by 75%∼89% with high efficiency. It adopts a 'coarse-to-fine' scheme to generate condensed visual tokens, achieving comparable or better performance across diverse benchmarks. The tool includes TokenPacker for general use and TokenPacker-HD for high-resolution image understanding. It provides training scripts, checkpoints, and supports various compression ratios and patch numbers.
mlp-mixer-pytorch
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.
Upscaler
Holloway's Upscaler is a consolidation of various compiled open-source AI image/video upscaling products for a CLI-friendly image and video upscaling program. It provides low-cost AI upscaling software that can run locally on a laptop, programmable for albums and videos, reliable for large video files, and works without GUI overheads. The repository supports hardware testing on various systems and provides important notes on GPU compatibility, video types, and image decoding bugs. Dependencies include ffmpeg and ffprobe for video processing. The user manual covers installation, setup pathing, calling for help, upscaling images and videos, and contributing back to the project. Benchmarks are provided for performance evaluation on different hardware setups.
automatic
Automatic is an Image Diffusion implementation with advanced features. It supports multiple diffusion models, built-in control for text, image, batch, and video processing, and is compatible with various platforms and backends. The tool offers optimized processing with the latest torch developments, built-in support for torch.compile, and multiple compile backends. It also features platform-specific autodetection, queue management, enterprise-level logging, and a built-in installer with automatic updates and dependency management. Automatic is mobile compatible and provides a main interface using StandardUI and ModernUI.
OpenAI-CLIP-Feature
This repository provides code for extracting image and text features using OpenAI CLIP models, supporting both global and local grid visual features. It aims to facilitate multi visual-and-language downstream tasks by allowing users to customize input and output grid resolution easily. The extracted features have shown comparable or superior results in image captioning tasks without hyperparameter tuning. The repo supports various CLIP models and provides detailed information on supported settings and results on MSCOCO image captioning. Users can get started by setting up experiments with the extracted features using X-modaler.
StableDiffusion.NET
StableDiffusion.NET is a tool for creating images from text prompts using stable diffusion models. It allows users to build models with various configurations and options, supporting GPU acceleration for faster processing. The tool provides flexibility in choosing backends and integrating native libraries. Users can easily convert text prompts into images with default or custom parameters, and save the resulting images in PNG format. Additionally, users can extend the tool's functionality by writing custom extensions or installing pre-built extension sets like HPPH.System.Drawing and HPPH.SkiaSharp.

VisionLLM
VisionLLM is a series of large language models designed for vision-centric tasks. The latest version, VisionLLM v2, is a generalist multimodal model that supports hundreds of vision-language tasks, including visual understanding, perception, and generation.
Grounded_3D-LLM
Grounded 3D-LLM is a unified generative framework that utilizes referent tokens to reference 3D scenes, enabling the handling of sequences that interleave 3D and textual data. It transforms 3D vision tasks into language formats through task-specific prompts, curating grounded language datasets and employing Contrastive Language-Scene Pre-training (CLASP) to bridge the gap between 3D vision and language models. The model covers tasks like 3D visual question answering, dense captioning, object detection, and language grounding.

HolmesVAD
Holmes-VAD is a framework for unbiased and explainable Video Anomaly Detection using multimodal instructions. It addresses biased detection in challenging events by leveraging precise temporal supervision and rich multimodal instructions. The framework includes a largescale VAD instruction-tuning benchmark, VAD-Instruct50k, created with single-frame annotations and a robust video captioner. It offers accurate anomaly localization and comprehensive explanations through a customized solution for interpretable video anomaly detection.

VideoRefer
VideoRefer Suite is a tool designed to enhance the fine-grained spatial-temporal understanding capabilities of Video Large Language Models (Video LLMs). It consists of three primary components: Model (VideoRefer) for perceiving, reasoning, and retrieval for user-defined regions at any specified timestamps, Dataset (VideoRefer-700K) for high-quality object-level video instruction data, and Benchmark (VideoRefer-Bench) to evaluate object-level video understanding capabilities. The tool can understand any object within a video.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.
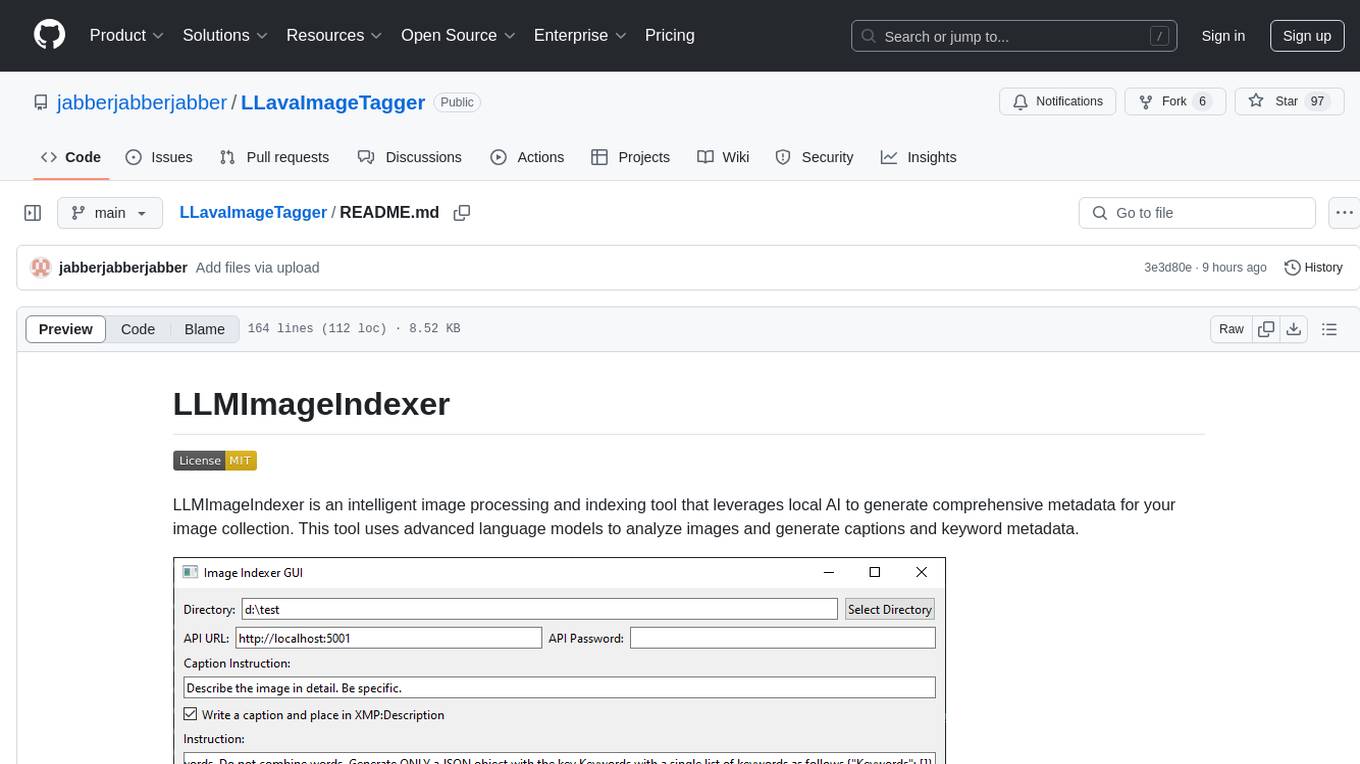
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
sdnext
SD.Next is an Image Diffusion implementation with advanced features. It offers multiple UI options, diffusion models, and built-in controls for text, image, batch, and video processing. The tool is multiplatform, supporting Windows, Linux, MacOS, nVidia, AMD, IntelArc/IPEX, DirectML, OpenVINO, ONNX+Olive, and ZLUDA. It provides optimized processing with the latest torch developments, including model compile, quantize, and compress functionalities. SD.Next also features Interrogate/Captioning with various models, queue management, automatic updates, and mobile compatibility.
VideoTree
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.

VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.
Video-Super-Resolution-Library
Intel® Library for Video Super Resolution (Intel® Library for VSR) is a project that offers a variety of algorithms, including machine learning and deep learning implementations, to convert low-resolution videos to high resolution. It enhances the RAISR algorithm to provide better visual quality and real-time performance for upscaling on Intel® Xeon® platforms and Intel® GPUs. The project is developed in C++ and utilizes Intel® AVX-512 on Intel® Xeon® Scalable Processor family and OpenCL support on Intel® GPUs. It includes an FFmpeg plugin inside a Docker container for ease of testing and deployment.
VASA-1-hack
VASA-1-hack is a repository containing the VASA implementation separated from EMOPortraits, with all components properly configured for standalone training. It provides detailed setup instructions, prerequisites, project structure, configuration details, running training modes, troubleshooting tips, monitoring training progress, development information, and acknowledgments. The repository aims to facilitate training volumetric avatar models with configurable parameters and logging levels for efficient debugging and testing.

ComfyUI
ComfyUI is a powerful and modular visual AI engine and application that allows users to design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. It provides a user-friendly environment for creating complex Stable Diffusion workflows without the need for coding. ComfyUI supports various models for image editing, video processing, audio manipulation, 3D modeling, and more. It offers features like smart memory management, support for different GPU types, loading and saving workflows as JSON files, and offline functionality. Users can also use API nodes to access paid models from external providers through the online Comfy API.
20 - OpenAI Gpts
Media AI Visionary
Leading AI & Media Expert: In-depth, Ethical, Insightful, developed on OpenAI
AI-Driven Lab
recommends AI research these days in Japanese using AI-driven's-lab articles

Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!
AI Tools Guru
Find the best AI tools. Want to add your tool? Fill the form: https://forms.gle/uqMaC2EFZzh3Y4yT6
Gary Marcus AI Critic Simulator
Humorous AI critic known for skepticism, contradictory arguments, and combining Animal and Machine Learning related Terms.


Personalized ML+AI Learning Program
Interactive ML/AI tutor providing structured daily lessons.

AI for Medical Imaging GPT
Expert in medical imaging AI, adept in machine learning tools.