
mlp-mixer-pytorch
An All-MLP solution for Vision, from Google AI
Stars: 986
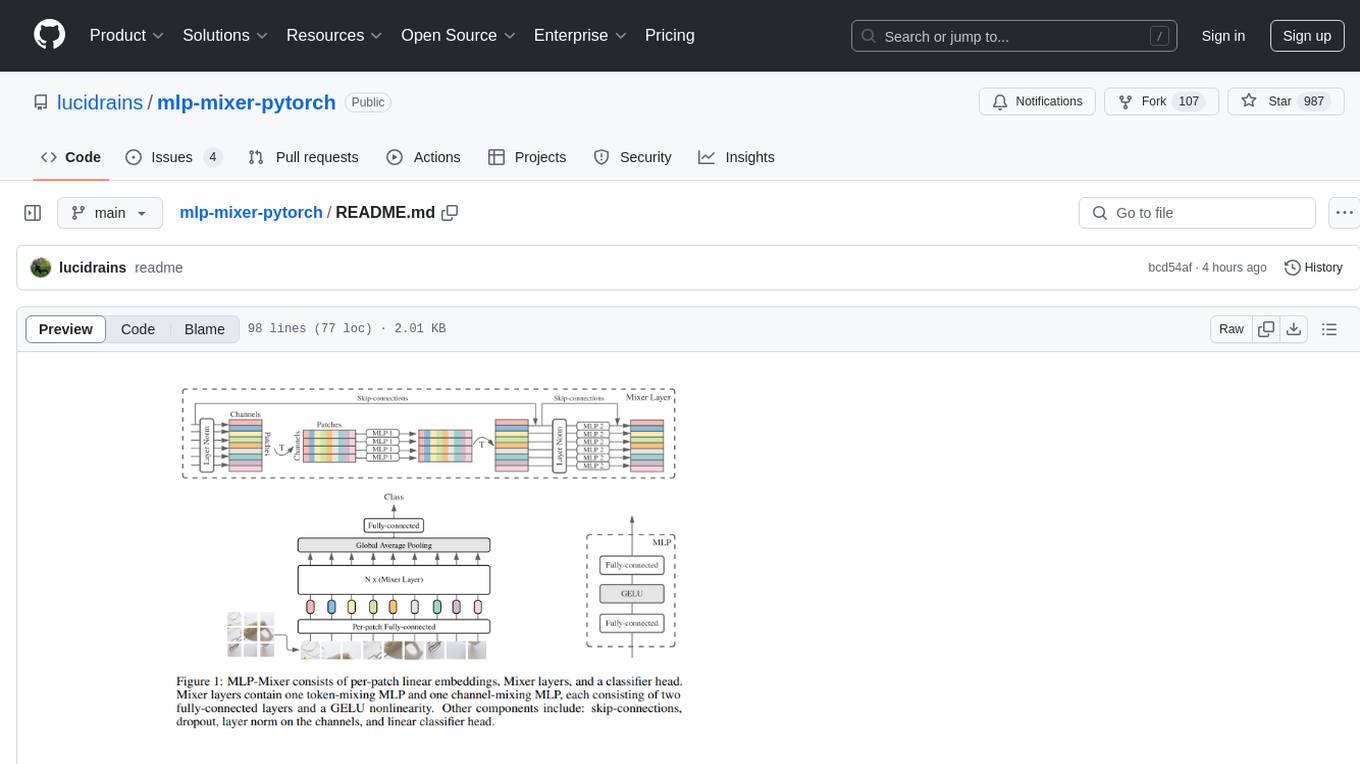
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.
README:

An All-MLP solution for Vision, from Google AI, in Pytorch.
No convolutions nor attention needed!
$ pip install mlp-mixer-pytorchimport torch
from mlp_mixer_pytorch import MLPMixer
model = MLPMixer(
image_size = 256,
channels = 3,
patch_size = 16,
dim = 512,
depth = 12,
num_classes = 1000
)
img = torch.randn(1, 3, 256, 256)
pred = model(img) # (1, 1000)Rectangular image
import torch
from mlp_mixer_pytorch import MLPMixer
model = MLPMixer(
image_size = (256, 128),
channels = 3,
patch_size = 16,
dim = 512,
depth = 12,
num_classes = 1000
)
img = torch.randn(1, 3, 256, 128)
pred = model(img) # (1, 1000)Video
import torch
from mlp_mixer_pytorch import MLPMixer3D
model = MLPMixer3D(
image_size = (256, 128),
time_size = 4,
time_patch_size = 2,
channels = 3,
patch_size = 16,
dim = 512,
depth = 12,
num_classes = 1000
)
video = torch.randn(1, 3, 4, 256, 128)
pred = model(video) # (1, 1000)@misc{tolstikhin2021mlpmixer,
title = {MLP-Mixer: An all-MLP Architecture for Vision},
author = {Ilya Tolstikhin and Neil Houlsby and Alexander Kolesnikov and Lucas Beyer and Xiaohua Zhai and Thomas Unterthiner and Jessica Yung and Daniel Keysers and Jakob Uszkoreit and Mario Lucic and Alexey Dosovitskiy},
year = {2021},
eprint = {2105.01601},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}@misc{hou2021vision,
title = {Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition},
author = {Qibin Hou and Zihang Jiang and Li Yuan and Ming-Ming Cheng and Shuicheng Yan and Jiashi Feng},
year = {2021},
eprint = {2106.12368},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mlp-mixer-pytorch
Similar Open Source Tools
mlp-mixer-pytorch
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
zenu
ZeNu is a high-performance deep learning framework implemented in pure Rust, featuring a pure Rust implementation for safety and performance, GPU performance comparable to PyTorch with CUDA support, a simple and intuitive API, and a modular design for easy extension. It supports various layers like Linear, Convolution 2D, LSTM, and optimizers such as SGD and Adam. ZeNu also provides device support for CPU and CUDA (NVIDIA GPU) with CUDA 12.3 and cuDNN 9. The project structure includes main library, automatic differentiation engine, neural network layers, matrix operations, optimization algorithms, CUDA implementation, and other support crates. Users can find detailed implementations like MNIST classification, CIFAR10 classification, and ResNet implementation in the examples directory. Contributions to ZeNu are welcome under the MIT License.
StarWhisper
StarWhisper is a multi-modal model repository developed under the support of the National Astronomical Observatory-Zhijiang Laboratory. It includes language models, temporal models, and multi-modal models ranging from 7B to 72B. The repository provides pre-trained models and technical reports for tasks such as pulsar identification, light curve classification, and telescope control. It aims to integrate astronomical knowledge using large models and explore the possibilities of solving specific astronomical problems through multi-modal approaches.
jsgrad
jsgrad is a modern ML library for JavaScript and TypeScript that aims to provide a fast and efficient way to run and train machine learning models. It is a rewrite of tinygrad in TypeScript, offering a clean and modern API with zero dependencies. The library supports multiple runtime backends such as WebGPU, WASM, and CLANG, making it versatile for various applications in browser and server environments. With a focus on simplicity and performance, jsgrad is designed to be easy to use for both model inference and training tasks.

ivy
Ivy is an open-source machine learning framework that enables users to convert code between different ML frameworks and write framework-agnostic code. It allows users to transpile code from one framework to another, making it easy to use building blocks from different frameworks in a single project. Ivy also serves as a flexible framework that breaks free from framework limitations, allowing users to publish code that is interoperable with various frameworks and future frameworks. Users can define trainable modules and layers using Ivy's stateful API, making it easy to build and train models across different backends.

ivy
Ivy is an open-source machine learning framework that enables you to: * 🔄 **Convert code into any framework** : Use and build on top of any model, library, or device by converting any code from one framework to another using `ivy.transpile`. * ⚒️ **Write framework-agnostic code** : Write your code once in `ivy` and then choose the most appropriate ML framework as the backend to leverage all the benefits and tools. Join our growing community 🌍 to connect with people using Ivy. **Let's** unify.ai **together 🦾**
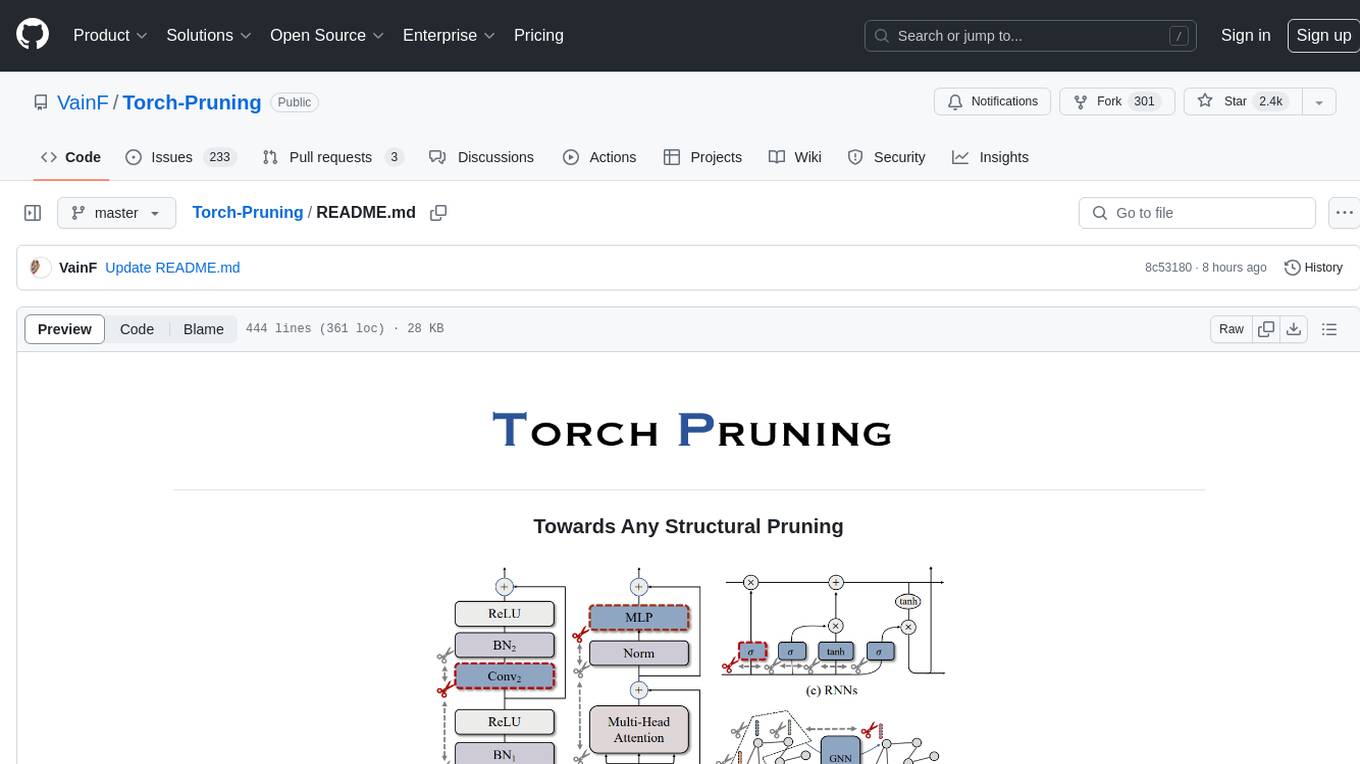
Torch-Pruning
Torch-Pruning (TP) is a library for structural pruning that enables pruning for a wide range of deep neural networks. It uses an algorithm called DepGraph to physically remove parameters. The library supports pruning off-the-shelf models from various frameworks and provides benchmarks for reproducing results. It offers high-level pruners, dependency graph for automatic pruning, low-level pruning functions, and supports various importance criteria and modules. Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions.

modelfusion
ModelFusion is an abstraction layer for integrating AI models into JavaScript and TypeScript applications, unifying the API for common operations such as text streaming, object generation, and tool usage. It provides features to support production environments, including observability hooks, logging, and automatic retries. You can use ModelFusion to build AI applications, chatbots, and agents. ModelFusion is a non-commercial open source project that is community-driven. You can use it with any supported provider. ModelFusion supports a wide range of models including text generation, image generation, vision, text-to-speech, speech-to-text, and embedding models. ModelFusion infers TypeScript types wherever possible and validates model responses. ModelFusion provides an observer framework and logging support. ModelFusion ensures seamless operation through automatic retries, throttling, and error handling mechanisms. ModelFusion is fully tree-shakeable, can be used in serverless environments, and only uses a minimal set of dependencies.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

pycm
PyCM is a Python library for multi-class confusion matrices, providing support for input data vectors and direct matrices. It is a comprehensive tool for post-classification model evaluation, offering a wide range of metrics for predictive models and accurate evaluation of various classifiers. PyCM is designed for data scientists who require diverse metrics for their models.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.

mLLMCelltype
mLLMCelltype is a multi-LLM consensus framework for automated cell type annotation in single-cell RNA sequencing (scRNA-seq) data. The tool integrates multiple large language models to improve annotation accuracy through consensus-based predictions. It offers advantages over single-model approaches by combining predictions from models like OpenAI GPT-5.2, Anthropic Claude-4.6/4.5, Google Gemini-3, and others. Researchers can incorporate mLLMCelltype into existing workflows without the need for reference datasets.

lagent
Lagent is a lightweight open-source framework that allows users to efficiently build large language model(LLM)-based agents. It also provides some typical tools to augment LLM. The overview of our framework is shown below:
bellman
Bellman is a unified interface to interact with language and embedding models, supporting various vendors like VertexAI/Gemini, OpenAI, Anthropic, VoyageAI, and Ollama. It consists of a library for direct interaction with models and a service 'bellmand' for proxying requests with one API key. Bellman simplifies switching between models, vendors, and common tasks like chat, structured data, tools, and binary input. It addresses the lack of official SDKs for major players and differences in APIs, providing a single proxy for handling different models. The library offers clients for different vendors implementing common interfaces for generating and embedding text, enabling easy interchangeability between models.
Ollama
Ollama SDK for .NET is a fully generated C# SDK based on OpenAPI specification using OpenApiGenerator. It supports automatic releases of new preview versions, source generator for defining tools natively through C# interfaces, and all modern .NET features. The SDK provides support for all Ollama API endpoints including chats, embeddings, listing models, pulling and creating new models, and more. It also offers tools for interacting with weather data and providing weather-related information to users.
For similar tasks
mlp-mixer-pytorch
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.
ppt2desc
ppt2desc is a command-line tool that converts PowerPoint presentations into detailed textual descriptions using vision language models. It interprets and describes visual elements, capturing the full semantic meaning of each slide in a machine-readable format. The tool supports various model providers and offers features like converting PPT/PPTX files to semantic descriptions, processing individual files or directories, visual elements interpretation, rate limiting for API calls, customizable prompts, and JSON output format for easy integration.
awesome-robotics-ai-companies
A curated list of companies in the robotics and artificially intelligent agents industry, including large companies, stable start-ups, non-profits, and government research labs. The list covers companies working on autonomous vehicles, robotics, artificial intelligence, machine learning, computer vision, and more. It aims to showcase industry innovators and important players in the field of robotics and AI.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.