
Arcade-Learning-Environment
The Arcade Learning Environment (ALE) -- a platform for AI research.
Stars: 2211
The Arcade Learning Environment (ALE) is a simple framework that allows researchers and hobbyists to develop AI agents for Atari 2600 games. It is built on top of the Atari 2600 emulator Stella and separates the details of emulation from agent design. The ALE currently supports three different interfaces: C++, Python, and OpenAI Gym.
README:



The Arcade Learning Environment (ALE) is a simple framework that allows researchers and hobbyists to develop AI agents for Atari 2600 games. It is built on top of the Atari 2600 emulator Stella and separates the details of emulation from agent design. This video depicts over 50 games currently supported in the ALE.
For an overview of our goals for the ALE read The Arcade Learning Environment: An Evaluation Platform for General Agents. If you use ALE in your research, we ask that you please cite this paper in reference to the environment. See the Citing section for BibTeX entries.
- Object-oriented framework with support to add agents and games.
- Emulation core uncoupled from rendering and sound generation modules for fast emulation with minimal library dependencies.
- Automatic extraction of game score and end-of-game signal for more than 100 Atari 2600 games.
- Multi-platform code (compiled and tested under macOS, Windows, and several Linux distributions).
- Python bindings through pybind11.
- Native support for Gymnasium, a maintained fork of OpenAI Gym.
- Visualization tools.
- Atari roms are packaged within the pip package
The ALE currently supports three different interfaces: C++, Python, and Gymnasium.
You simply need to install the ale-py package distributed via PyPI:
pip install ale-pyNote: Make sure you're using an up-to-date version of pip or the installation may fail.
You can now import the ALE in your Python projects with providing a direct interface to Stella for interacting with games
from ale_py import ALEInterface, roms
ale = ALEInterface()
ale.loadROM(roms.get_rom_path("breakout"))
ale.reset_game()
reward = ale.act(0) # noop
screen_obs = ale.getScreenRGB()For simplicity for installing ale-py with Gymnasium, pip install "gymnasium[atari]" shall install all necessary modules and ROMs. See Gymnasium introductory page for description of the API to interface with the environment.
import gymnasium as gym
import ale_py
gym.register_envs(ale_py) # unnecessary but helpful for IDEs
env = gym.make('ALE/Breakout-v5', render_mode="human") # remove render_mode in training
obs, info = env.reset()
episode_over = False
while not episode_over:
action = policy(obs) # to implement - use `env.action_space.sample()` for a random policy
obs, reward, terminated, truncated, info = env.step(action)
episode_over = terminated or truncated
env.close()To run with continuous actions, you can simply modify the call to gym.make above with:
env = gym.make('ALE/Breakout-v5', continuous=True, render_mode="human")For all the environments available and their description, see gymnasium atari page.
The following instructions will assume you have a valid C++17 compiler and vcpkg installed.
We use CMake as a first class citizen, and you can use the ALE directly with any CMake project. To compile and install the ALE you can run
mkdir build && cd build
cmake ../ -DCMAKE_BUILD_TYPE=Release
cmake --build . --target installThere are optional flags -DSDL_SUPPORT=ON/OFF to toggle SDL support (i.e., display_screen and sound support; OFF by default), -DBUILD_CPP_LIB=ON/OFF to build
the ale-lib C++ target (ON by default), and -DBUILD_PYTHON_LIB=ON/OFF to build the pybind11 wrapper (ON by default).
Finally, you can link against the ALE in your own CMake project as follows
find_package(ale REQUIRED)
target_link_libraries(YourTarget ale::ale-lib)If you use the ALE in your research, we ask that you please cite the following.
M. G. Bellemare, Y. Naddaf, J. Veness and M. Bowling. The Arcade Learning Environment: An Evaluation Platform for General Agents, Journal of Artificial Intelligence Research, Volume 47, pages 253-279, 2013.
In BibTeX format:
@Article{bellemare13arcade,
author = {{Bellemare}, M.~G. and {Naddaf}, Y. and {Veness}, J. and {Bowling}, M.},
title = {The Arcade Learning Environment: An Evaluation Platform for General Agents},
journal = {Journal of Artificial Intelligence Research},
year = "2013",
month = "jun",
volume = "47",
pages = "253--279",
}If you use the ALE with sticky actions (flag repeat_action_probability), or if
you use the different game flavours (mode and difficulty switches), we ask you
that you also cite the following:
M. C. Machado, M. G. Bellemare, E. Talvitie, J. Veness, M. J. Hausknecht, M. Bowling. Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents, Journal of Artificial Intelligence Research, Volume 61, pages 523-562, 2018.
In BibTex format:
@Article{machado18arcade,
author = {Marlos C. Machado and Marc G. Bellemare and Erik Talvitie and Joel Veness and Matthew J. Hausknecht and Michael Bowling},
title = {Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents},
journal = {Journal of Artificial Intelligence Research},
volume = {61},
pages = {523--562},
year = {2018}
}If you use the CALE (Continuous ALE), we ask you that you also cite the following:
Jesse Farebrother and Pablo Samuel Castro. Cale: Continuous arcade learning environment.Ad-vances in Neural Information Processing Systems, 2024.
In BibTex format:
@article{farebrother2024cale,
title={C{ALE}: Continuous Arcade Learning Environment},
author={Jesse Farebrother and Pablo Samuel Castro},
journal={Advances in Neural Information Processing Systems},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Arcade-Learning-Environment
Similar Open Source Tools
Arcade-Learning-Environment
The Arcade Learning Environment (ALE) is a simple framework that allows researchers and hobbyists to develop AI agents for Atari 2600 games. It is built on top of the Atari 2600 emulator Stella and separates the details of emulation from agent design. The ALE currently supports three different interfaces: C++, Python, and OpenAI Gym.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.

generative-ai
The 'Generative AI' repository provides a C# library for interacting with Google's Generative AI models, specifically the Gemini models. It allows users to access and integrate the Gemini API into .NET applications, supporting functionalities such as listing available models, generating content, creating tuned models, working with large files, starting chat sessions, and more. The repository also includes helper classes and enums for Gemini API aspects. Authentication methods include API key, OAuth, and various authentication modes for Google AI and Vertex AI. The package offers features for both Google AI Studio and Google Cloud Vertex AI, with detailed instructions on installation, usage, and troubleshooting.
mlstm_kernels
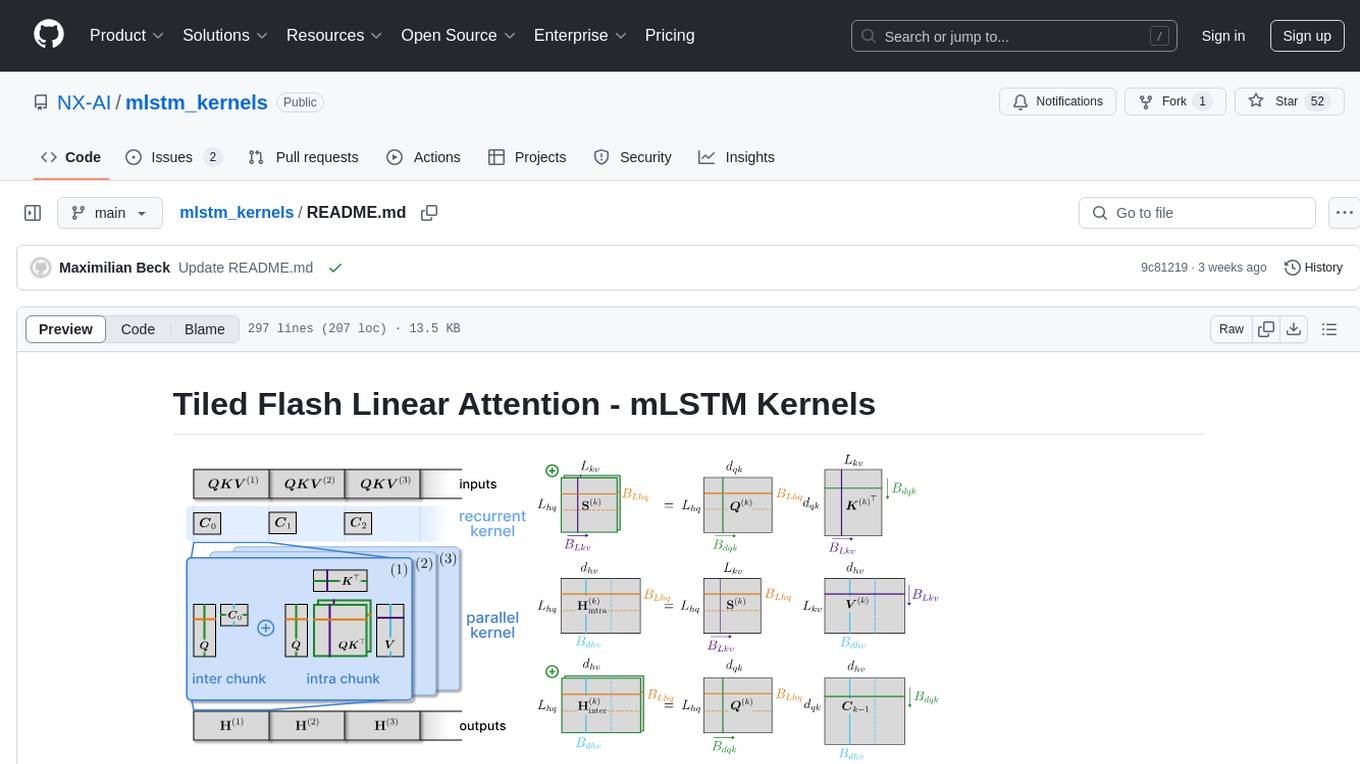
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.
pywhyllm
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments causal inference by suggesting potential confounders, relationships between variables, backdoor/frontdoor/iv sets, estimands, critiques of DAGs, latent confounders, and negative controls. The tool aims to enhance the causal analysis process by leveraging the capabilities of LLMs.

PDEBench
PDEBench provides a diverse and comprehensive set of benchmarks for scientific machine learning, including challenging and realistic physical problems. The repository consists of code for generating datasets, uploading and downloading datasets, training and evaluating machine learning models as baselines. It features a wide range of PDEs, realistic and difficult problems, ready-to-use datasets with various conditions and parameters. PDEBench aims for extensibility and invites participation from the SciML community to improve and extend the benchmark.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
gem
GEM is an open-source General Experience Maker designed for training Large Language Models (LLMs) in dynamic environments. Similar to OpenAI Gym for traditional Reinforcement Learning, GEM provides a variety of environments with standardized interfaces for seamless integration with existing LLM training frameworks. It offers tool integration, flexible wrappers, async vectorized environment execution, multi-environment training, and more to simplify LLM agent training.

Jlama
Jlama is a modern Java inference engine designed for large language models. It supports various model types such as Gemma, Llama, Mistral, GPT-2, BERT, and more. The tool implements features like Flash Attention, Mixture of Experts, and supports different model quantization formats. Built with Java 21 and utilizing the new Vector API for faster inference, Jlama allows users to add LLM inference directly to their Java applications. The tool includes a CLI for running models, a simple UI for chatting with LLMs, and examples for different model types.
AgentKit
AgentKit is a framework for constructing complex human thought processes from simple natural language prompts. It offers a unified way to represent and execute these processes as graphs, making it easy to design and tune agents without any programming experience. AgentKit can be used for a variety of tasks, including generating text, answering questions, and making decisions.

KaibanJS
KaibanJS is a JavaScript-native framework for building multi-agent AI systems. It enables users to create specialized AI agents with distinct roles and goals, manage tasks, and coordinate teams efficiently. The framework supports role-based agent design, tool integration, multiple LLMs support, robust state management, observability and monitoring features, and a real-time agentic Kanban board for visualizing AI workflows. KaibanJS aims to empower JavaScript developers with a user-friendly AI framework tailored for the JavaScript ecosystem, bridging the gap in the AI race for non-Python developers.
pywhy-llm
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments existing causal inference processes by suggesting potential confounders, relationships between variables, backdoor sets, front door sets, IV sets, estimands, critiques of DAGs, latent confounders, and negative controls. By leveraging LLMs and formalizing human-LLM collaboration, PyWhy-LLM aims to enhance causal analysis accessibility and insight.
LlmTornado
LLM Tornado is a .NET library designed to simplify the consumption of various large language models (LLMs) from providers like OpenAI, Anthropic, Cohere, Google, Azure, Groq, and self-hosted APIs. It acts as an aggregator, allowing users to easily switch between different LLM providers with just a change in argument. Users can perform tasks such as chatting with documents, voice calling with AI, orchestrating assistants, generating images, and more. The library exposes capabilities through vendor extensions, making it easy to integrate and use multiple LLM providers simultaneously.
For similar tasks
AISystem
This open-source project, also known as **Deep Learning System** or **AI System (AISys)**, aims to explore and learn about the system design of artificial intelligence and deep learning. The project is centered around the full-stack content of AI systems that ZOMI has accumulated,整理, and built during his work. The goal is to collaborate with all friends who are interested in AI open-source projects to jointly promote learning and discussion.
Arcade-Learning-Environment
The Arcade Learning Environment (ALE) is a simple framework that allows researchers and hobbyists to develop AI agents for Atari 2600 games. It is built on top of the Atari 2600 emulator Stella and separates the details of emulation from agent design. The ALE currently supports three different interfaces: C++, Python, and OpenAI Gym.
awesome-robotics-ai-companies
A curated list of companies in the robotics and artificially intelligent agents industry, including large companies, stable start-ups, non-profits, and government research labs. The list covers companies working on autonomous vehicles, robotics, artificial intelligence, machine learning, computer vision, and more. It aims to showcase industry innovators and important players in the field of robotics and AI.
ragstack-ai
RAGStack is an out-of-the-box solution simplifying Retrieval Augmented Generation (RAG) in GenAI apps. RAGStack includes the best open-source for implementing RAG, giving developers a comprehensive Gen AI Stack leveraging LangChain, CassIO, and more. RAGStack leverages the LangChain ecosystem and is fully compatible with LangSmith for monitoring your AI deployments.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
Data-Science-EBooks
This repository contains a collection of resources in the form of eBooks related to Data Science, Machine Learning, and similar topics.
tldraw-llm-starter
This repository is a collection of demos showcasing how to integrate tldraw with an LLM like GPT-4. It serves as a work in progress for inspiration and experimentation. Users can contribute new demos, prompts, strategies, and models. The installation process involves running 'npm install' to install dependencies. Usage instructions include creating OpenAI API keys and assistants on the platform.openai.com website, as well as setting up a '.env' file with necessary credentials. The server can be started with 'npm run dev'. The repository aims to demonstrate the potential synergy between tldraw and GPT-4 for various applications.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.