
tldraw-llm-starter
A starter for working with tldraw and large language models.
Stars: 116
This repository is a collection of demos showcasing how to integrate tldraw with an LLM like GPT-4. It serves as a work in progress for inspiration and experimentation. Users can contribute new demos, prompts, strategies, and models. The installation process involves running 'npm install' to install dependencies. Usage instructions include creating OpenAI API keys and assistants on the platform.openai.com website, as well as setting up a '.env' file with necessary credentials. The server can be started with 'npm run dev'. The repository aims to demonstrate the potential synergy between tldraw and GPT-4 for various applications.
README:
This repository collects demos that show how you might use tldraw together with an LLM like GPT-4. It is very much a work in progress, please use it as inspiration and experimentation.
PRs welcome for new demos, prompts, strategies and models.
Run npm install to install dependencies.
- Create an OpenAI API key on the platform.openai.com website.
- Create an Assistant on the platform.openai.com website.
- Create a second Assistant on the platform.openai.com website.
- Create
.envfile at the root of this repo with both the key and the assistant's id.
OPENAI_API_KEY="sk-sk-etcetcetc"
OPENAI_ASSISTANT_ID="asst_etcetcetc"
OPENAI_FUNCTIONS_ASSISTANT_ID="asst_etcetcetc"
Run npm run dev to start the server.
See notes below on the different demos.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for tldraw-llm-starter
Similar Open Source Tools
tldraw-llm-starter
This repository is a collection of demos showcasing how to integrate tldraw with an LLM like GPT-4. It serves as a work in progress for inspiration and experimentation. Users can contribute new demos, prompts, strategies, and models. The installation process involves running 'npm install' to install dependencies. Usage instructions include creating OpenAI API keys and assistants on the platform.openai.com website, as well as setting up a '.env' file with necessary credentials. The server can be started with 'npm run dev'. The repository aims to demonstrate the potential synergy between tldraw and GPT-4 for various applications.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
engine-core
Engine Core is a project that demonstrates a pattern for enabling Large Language Models (LLMs) to undertake tasks with a dynamic system prompt and a collection of tool functions known as chat strategies. These strategies allow for the dynamic alteration of chat history, system prompts, and available tools on every run. The project includes example strategies such as demoStrategy, backendStrategy, and shellStrategy. Additionally, LLM integrations like Anthropic or OpenAI have been extracted into adapters to enable running the same app code and strategies while switching foundation models.
PythonDataScienceFullThrottle
PythonDataScienceFullThrottle is a comprehensive repository containing various Python scripts, libraries, and tools for data science enthusiasts. It includes a wide range of functionalities such as data preprocessing, visualization, machine learning algorithms, and statistical analysis. The repository aims to provide a one-stop solution for individuals looking to dive deep into the world of data science using Python.
dialog
Dialog is an API-focused tool designed to simplify the deployment of Large Language Models (LLMs) for programmers interested in AI. It allows users to deploy any LLM based on the structure provided by dialog-lib, enabling them to spend less time coding and more time training their models. The tool aims to humanize Retrieval-Augmented Generative Models (RAGs) and offers features for better RAG deployment and maintenance. Dialog requires a knowledge base in CSV format and a prompt configuration in TOML format to function effectively. It provides functionalities for loading data into the database, processing conversations, and connecting to the LLM, with options to customize prompts and parameters. The tool also requires specific environment variables for setup and configuration.

atomic_agents
Atomic Agents is a modular and extensible framework designed for creating powerful applications. It follows the principles of Atomic Design, emphasizing small and single-purpose components. Leveraging Pydantic for data validation and serialization, the framework offers a set of tools and agents that can be combined to build AI applications. It depends on the Instructor package and supports various APIs like OpenAI, Cohere, Anthropic, and Gemini. Atomic Agents is suitable for developers looking to create AI agents with a focus on modularity and flexibility.

ModernBERT
ModernBERT is a repository focused on modernizing BERT through architecture changes and scaling. It introduces FlexBERT, a modular approach to encoder building blocks, and heavily relies on .yaml configuration files to build models. The codebase builds upon MosaicBERT and incorporates Flash Attention 2. The repository is used for pre-training and GLUE evaluations, with a focus on reproducibility and documentation. It provides a collaboration between Answer.AI, LightOn, and friends.

NaLLM
The NaLLM project repository explores the synergies between Neo4j and Large Language Models (LLMs) through three primary use cases: Natural Language Interface to a Knowledge Graph, Creating a Knowledge Graph from Unstructured Data, and Generating a Report using static and LLM data. The repository contains backend and frontend code organized for easy navigation. It includes blog posts, a demo database, instructions for running demos, and guidelines for contributing. The project aims to showcase the potential of Neo4j and LLMs in various applications.

xef
xef.ai is a one-stop library designed to bring the power of modern AI to applications and services. It offers integration with Large Language Models (LLM), image generation, and other AI services. The library is packaged in two layers: core libraries for basic AI services integration and integrations with other libraries. xef.ai aims to simplify the transition to modern AI for developers by providing an idiomatic interface, currently supporting Kotlin. Inspired by LangChain and Hugging Face, xef.ai may transmit source code and user input data to third-party services, so users should review privacy policies and take precautions. Libraries are available in Maven Central under the `com.xebia` group, with `xef-core` as the core library. Developers can add these libraries to their projects and explore examples to understand usage.
generative_ai_with_langchain
Generative AI with LangChain is a code repository for building large language model (LLM) apps with Python, ChatGPT, and other LLMs. The repository provides code examples, instructions, and configurations for creating generative AI applications using the LangChain framework. It covers topics such as setting up the development environment, installing dependencies with Conda or Pip, using Docker for environment setup, and setting API keys securely. The repository also emphasizes stability, code updates, and user engagement through issue reporting and feedback. It aims to empower users to leverage generative AI technologies for tasks like building chatbots, question-answering systems, software development aids, and data analysis applications.

modelbench
ModelBench is a tool for running safety benchmarks against AI models and generating detailed reports. It is part of the MLCommons project and is designed as a proof of concept to aggregate measures, relate them to specific harms, create benchmarks, and produce reports. The tool requires LlamaGuard for evaluating responses and a TogetherAI account for running benchmarks. Users can install ModelBench from GitHub or PyPI, run tests using Poetry, and create benchmarks by providing necessary API keys. The tool generates static HTML pages displaying benchmark scores and allows users to dump raw scores and manage cache for faster runs. ModelBench is aimed at enabling users to test their own models and create tests and benchmarks.

reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.
cody-vs
Sourcegraph’s AI code assistant, Cody for Visual Studio, enhances developer productivity by providing a natural and intuitive way to work. It offers features like chat, auto-edit, prompts, and works with various IDEs. Cody focuses on team productivity, offering whole codebase context and shared prompts for consistency. Users can choose from different LLM models like Claude, Gemini Pro, and OpenAI's GPT. Engineered for enterprise use, Cody supports flexible deployment and enterprise security. Suitable for any programming language, Cody excels with Python, Go, JavaScript, and TypeScript code.
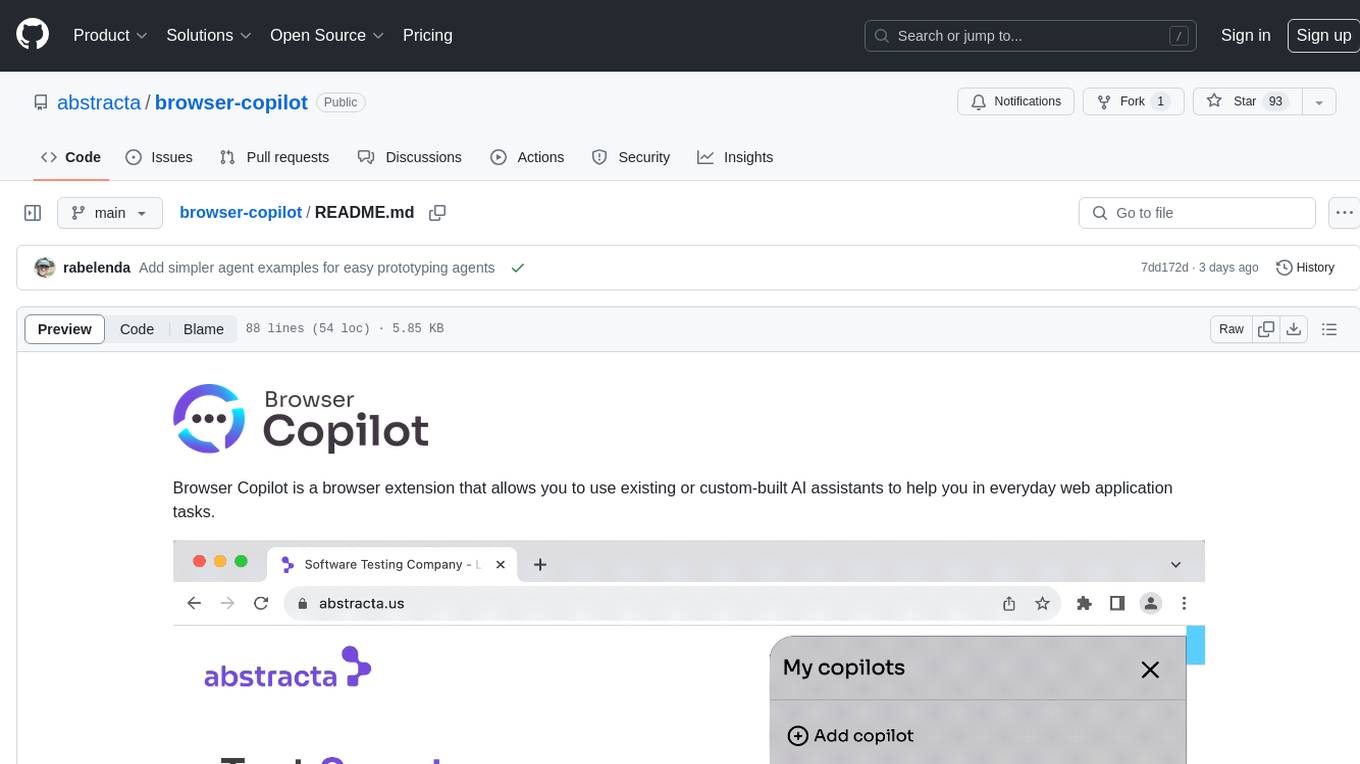
browser-copilot
Browser Copilot is a browser extension that enables users to utilize AI assistants for various web application tasks. It provides a versatile UI and framework to implement copilots that can automate tasks, extract information, interact with web applications, and utilize service APIs. Users can easily install copilots, start chats, save prompts, and toggle the copilot on or off. The project also includes a sample copilot implementation for testing purposes and encourages community contributions to expand the catalog of copilots.
TagUI
TagUI is an open-source RPA tool that allows users to automate repetitive tasks on their computer, including tasks on websites, desktop apps, and the command line. It supports multiple languages and offers features like interacting with identifiers, automating data collection, moving data between TagUI and Excel, and sending Telegram notifications. Users can create RPA robots using MS Office Plug-ins or text editors, run TagUI on the cloud, and integrate with other RPA tools. TagUI prioritizes enterprise security by running on users' computers and not storing data. It offers detailed logs, enterprise installation guides, and support for centralised reporting.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.