
mlstm_kernels
Tiled Flash Linear Attention library for fast and efficient mLSTM Kernels.
Stars: 52
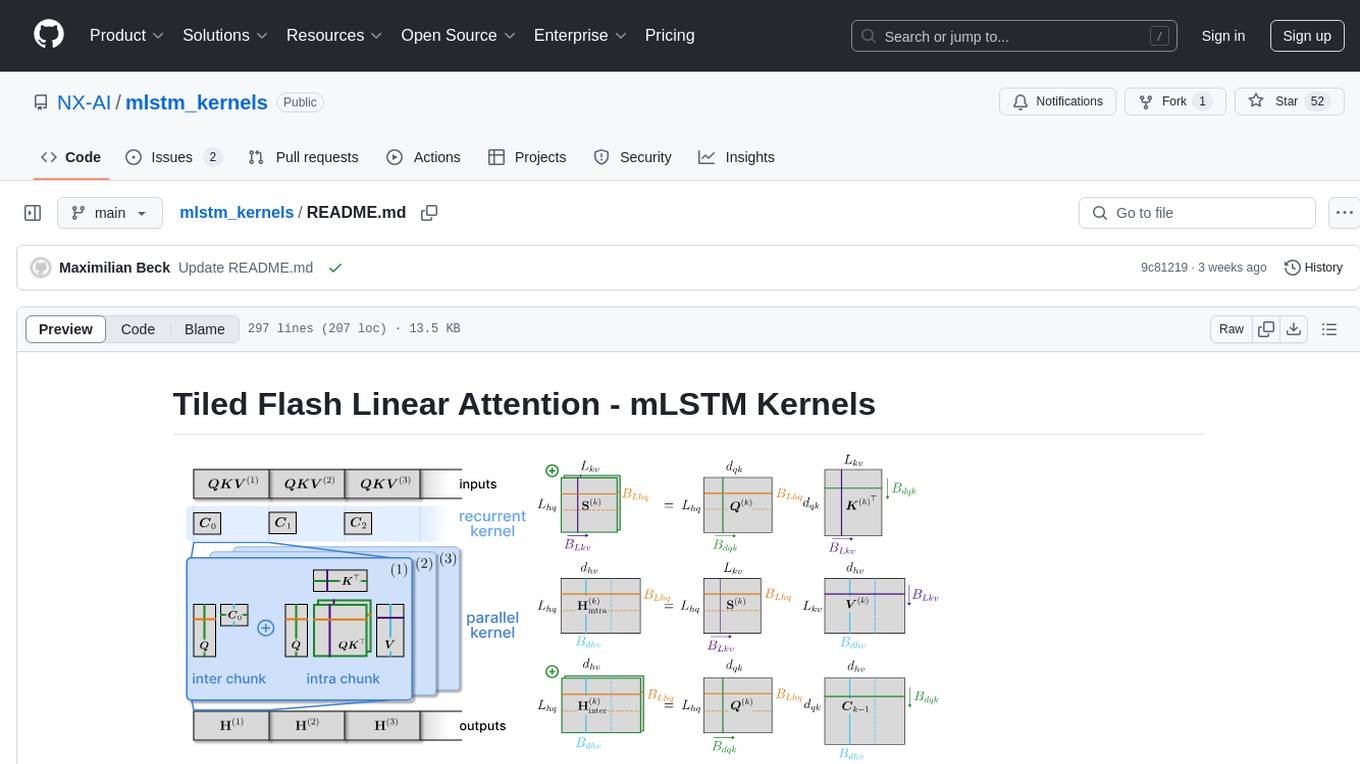
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.
README:


Paper: https://arxiv.org/abs/2503.14376
Authors: Maximilian Beck, Korbinian Pöppel, Phillip Lippe, Sepp Hochreiter
This library provides fast and efficient mLSTM training and inference Triton kernels. The chunkwise-parallel mLSTM Kernels are built on Tiled Flash Linear Attention (TFLA).
This repository also contains an easy to extend library for any kind of runtime benchmarks, which we use to benchmark our mLSTM kernels, as well as full mLSTM Huggingface models.
At its core the mLSTM Kernel library contains several implementations of the mLSTM in JAX, PyTorch as well as kernels in Triton,
which build three toplevel modules within the mlstm_kernels library:
-
jax: Contains JAX native implementations of the mLSTM, as well as JAX Triton integrations. -
torch: Contains PyTorch native implementations of the mLSTM, as well the Triton integrations for PyTorch. It also contains the configurable PyTorch backend module for simple integration of the mLSTM kernels into your models (see below for further details). -
triton: Contains the Triton kernels for the mLSTM, as well as kernel launch parameter heuristics.
The utils module contains code for unit tests, additional analysis (such as the transfer behavior analysis from the TFLA paper) or the benchmark library, which is discussed in detail below.
Each of the three toplevel modules, contains three different types of implementations and kernels for the mLSTM:
-
chunkwise: Chunkwise kernels, that process chunks of the sequence in parallel. These include the TFLA kernels. -
parallel: Parallel kernels that process a sequence in parallel (like Attention). Overall the runtime of these kernels scales quadratically with sequence length. -
recurrent: Recurrent step kernels for text generation during inference.
Runtime comparison of mLSTM chunkwise kernels against other baselines on a NVIDA H100 GPU with a constant number of tokens. This means that as we increase the sequence length on the x-axis we proportionally decrease the batch size to keep the overall number of tokens constant. This is the same setup as for example in FlashAttention 3.

Left: Forward pass Right: Forward and backward pass
We benchmark the two mLSTM versions: mLSTM with exponential input gate (mLSTMexp) and mLSTM with sigmoid input gate (mLSTMsig)
-
mLSTMexp (limit chunk): mLSTMexp kernel with limited chunk size (
chunk_size=64). -
mLSTMexp (TFLA XL chunk): mLSTMexp TFLA kernel with unlimited chunk size (in this benchmark
chunk_size=128) -
mLSTMsig (TFLA XL chunk): mLSTMsig TFLA kernel with unlimited chunk size (in this benchmark
chunk_size=128)
In the following
limit_chunkmeans chunkwise kernels that are limited in chunk_size andxl_chunkmeans TFLA kernels.
For more details we refer to the TFLA paper.
You can find the conda environment file in the envs/ folder. We recommend to use the latest file, i.e. environment_pt251cu124.yaml
Then you can install the mLSTM kernels via pip: pip install mlstm_kernels
or by cloning the repository.
In this library we proivide PyTorch, JAX and Triton implementations of the mLSTM. For the Triton kernels, we provide wrappers in PyTorch and JAX.
There are two options to use our implementations and kernels:
This is the recommended option, if you want to use our mLSTM kernels in your own (language) model.
The backend module is implemented in mlstm_kernels/torch/backend_module.py and provides a configurable wrapper around all our mLSTM implementations and kernels.
Note: This is also how these kernels are implemented in our official implementation for the xLSTM 7B model (see xLSTM 7B model.py)
It allows to switch between training and inference mode and automatically selects the respective kernels.
For example the following code snippet configures the mLSTMBackend to use our TFLA mLSTMexp kernel:
# we use the mLSTMexp TFLA kernel
# we also configure to use the triton step kernel for inference
mlstm_backend_config = mLSTMBackendConfig(
chunkwise_kernel="chunkwise--triton_xl_chunk",
sequence_kernel="native_sequence__triton",
step_kernel="triton",
chunk_size=256,
return_last_states=False,
)
mlstm_backend = mLSTMBackend(mlstm_backend_config)
# run the backend
DEVICE = torch.device("cuda")
DTYPE = torch.bfloat16
B = 2
S = 512
DHQK = 128
DHHV = 256
NH = 4
# create input tensors
torch.manual_seed(1)
matQ = torch.randn((B, NH, S, DHQK), dtype=DTYPE, device=DEVICE)
matK = torch.randn((B, NH, S, DHQK), dtype=DTYPE, device=DEVICE)
matV = torch.randn((B, NH, S, DHHV), dtype=DTYPE, device=DEVICE)
vecI = torch.randn((B, NH, S), dtype=DTYPE, device=DEVICE)
vecF = 3.0 + torch.randn((B, NH, S), dtype=DTYPE, device=DEVICE)
matH = mlstm_backend(q=matQ, k=matK, v=matV, i=vecI, f=vecF)Quickstart: Have a look at the demo notebook demo/integrate_mlstm_via_backend_module_option1.ipynb.
If you directly want to use a specific kernel you can directly import the kernel from the respective module. The following code snippet import the TFLA mLSTMexp kernel and runs a forward pass.
import torch
# directly import mLSTMexp TFLA kernel
from mlstm_kernels.torch.chunkwise.triton_xl_chunk import mlstm_chunkwise__xl_chunk
# run the kernel
DEVICE = torch.device("cuda")
DTYPE = torch.bfloat16
B = 2
S = 512
DHQK = 128
DHHV = 256
NH = 4
torch.manual_seed(1)
matQ = torch.randn((B, NH, S, DHQK), dtype=DTYPE, device=DEVICE)
matK = torch.randn((B, NH, S, DHQK), dtype=DTYPE, device=DEVICE)
matV = torch.randn((B, NH, S, DHHV), dtype=DTYPE, device=DEVICE)
vecI = torch.randn((B, NH, S), dtype=DTYPE, device=DEVICE)
vecF = 3.0 + torch.randn((B, NH, S), dtype=DTYPE, device=DEVICE)
matH1 = mlstm_chunkwise__xl_chunk(
q=matQ, k=matK, v=matV, i=vecI, f=vecF, return_last_states=False, chunk_size=256
)You can also get a specific kernel function via its kernel specifier.
First, display all available kernels via get_available_mlstm_kernels().
This displays all kernels that can be used for training and that have a similar function signature such that they can be used interchangably.
# display all available mlstm chunkwise and parallel kernels
from mlstm_kernels.torch import get_available_mlstm_kernels
get_available_mlstm_kernels()['chunkwise--native_autograd',
'chunkwise--native_custbw',
'chunkwise--triton_limit_chunk',
'chunkwise--triton_xl_chunk',
'chunkwise--triton_xl_chunk_siging',
'parallel--native_autograd',
'parallel--native_custbw',
'parallel--native_stablef_autograd',
'parallel--native_stablef_custbw',
'parallel--triton_limit_headdim',
'parallel--native_siging_autograd',
'parallel--native_siging_custbw']
Then select a kernel via get_mlstm_kernel():
# select the kernel
from mlstm_kernels.torch import get_mlstm_kernel
mlstm_chunkwise_xl_chunk = get_mlstm_kernel("chunkwise--triton_xl_chunk")
matH2 = mlstm_chunkwise_xl_chunk(
q=matQ, k=matK, v=matV, i=vecI, f=vecF, return_last_states=False, chunk_size=256
)
torch.allclose(matH1, matH2, atol=1e-3, rtol=1e-3) # TrueQuickstart for option 2 and 3: Have a look at the demo notebook demo/integrate_mlstm_via_direct_import_option2and3.ipynb.
The JAX module mlstm_kernels.jax mirrors the PyTorch module mlstm_kernels.torch and can be used in the way as the PyTorch kernels with option 2.
The module mlstm_kernels.utils.benchmark contains a configurable benchmark library for benchmarking the runtime and GPU memory usage of kernels or models.
We use this library for all our benchmarks in the TFLA paper and the xLSTM 7B paper.
Step 1: To begin please have a look at mlstm_kernels/utils/benchmark/benchmarks/interface.py
At the core of the benchmark library, there is the BenchmarkInterface dataclass, which is the abstract base class that every new benchmark should inherit from.
The BenchmarkInterface dataclass holds generic benchmark parameters, defines the setup_benchmark function that must be overridden for every specific benchmark and also defines the function to benchmark benchmark_fn, which is the function that is benchmarked.
To run the benchmark the BenchmarkInterface has the method run_benchmark.
The BenchmarkCreator defines the benchmark collection, i.e. the collection of benchmarks that can be run and configured together via a single config.
To create a new benchmark collection, with several benchmarks one has to implement a new BenchmarkCreator.
This is a function that takes as input a KernelSpec dataclass (containing the specification for the benchmark class) and a parameter dict with overrides. It then creates and returns the specified benchmark.
Step 2: Next have a look at mlstm_kernels/utils/benchmark/param_handling.py in order to understand how the benchmarks are configured through a unified config.
We use the dataclass KernelSpec to provide a unified interface to our kernel benchmarks. The kernel_name must be a unique specifier within a benchmark collection. The additional_params field are parameters that are overriden in the respective BenchmarkInterface class.
One level above is the BenchmarkConfig dataclass. This config class enables to configure sweeps over multiple KernelSpec dataclasses.
Step 3: Finally, have a look at mlstm_kernels/utils/benchmark/run_benchmark.py and a corresponding benchmark script, e.g. scripts/run_training_kernel_benchmarks.py.
The "benchmark loops" are implemented in run_benchmark.py. These take as input a BenchmarkConfig and a BenchmarkCreator and run every benchmark member specified in the kernel specs with every parameter combination.
The run_and_record_benchmarks() functions executes these loops, and records the results to disk via .csv files and plots.
Finally, in our case we create scripts that collect several configured benchmarks, which we can then run via different arguments, see for e.g. scripts/run_training_kernel_benchmarks.py.
You should now be able to understand the structure of our benchmark suites, i.e. collections of benchmarks that are run together.
In this repository we create several benchmark suites, for example the kernel benchmarks for the TFLA paper or the model benchmarks for the xLSTM 7B paper.
These are implemented in mlstm_kernels/utils/benchmark/benchmarks/training_kernel_benchmarks.py and mlstm_kernels/utils/benchmark/benchmarks/huggingface_model_benchmark.py, respectively.
Quickstart: For a quick start please have a look at the demo notebook: demo/kernel_speed_benchmark.ipynb.
The following command runs the mLSTM kernels from the figure above. Note that you need a large GPU memory in order to fit the long sequences and large embedding dimension of 4096 for a 7B model.
PYTHONPATH=. python scripts/run_training_kernel_benchmarks.py --consttoken_benchmark mlstm_triton --folder_suffix "mlstm_bench" --num_heads 16 --half_qkdim 1It will create a new subfolder in outputs_kernel_benchmarks/ that contains the results.
The unit tests cross-check the different kernel implementations on numerical deviations for different dtypes. You can run all of them with the following command:
pytest -s tests/torch
# make sure you are in a JAX GPU environment
pytest -s tests/jaxThe -s disables the log capturing so you see the results directly on the command line.
Each test will log the outputs to a new folder with the timestamp as name in the test_outputs/ directory.
Note: The the JAX tests were only tested on NVIDIA H100 GPUs.
Please cite our papers if you use this codebase, or otherwise find our work valuable:
@article{beck:25tfla,
title = {{Tiled Flash Linear Attention}: More Efficient Linear RNN and xLSTM Kernels},
author = {Maximilian Beck and Korbinian Pöppel and Phillip Lippe and Sepp Hochreiter},
year = {2025},
volume = {2503.14376},
journal = {arXiv},
primaryclass = {cs.LG},
url = {https://arxiv.org/abs/2503.14376}
}
@article{beck:25xlstm7b,
title = {{xLSTM 7B}: A Recurrent LLM for Fast and Efficient Inference},
author = {Maximilian Beck and Korbinian Pöppel and Phillip Lippe and Richard Kurle and Patrick M. Blies and Günter Klambauer and Sebastian Böck and Sepp Hochreiter},
year = {2025},
volume = {2503.13427},
journal = {arXiv},
primaryclass = {cs.LG},
url = {https://arxiv.org/abs/2503.13427}
}
@inproceedings{beck:24xlstm,
title={xLSTM: Extended Long Short-Term Memory},
author={Maximilian Beck and Korbinian Pöppel and Markus Spanring and Andreas Auer and Oleksandra Prudnikova and Michael Kopp and Günter Klambauer and Johannes Brandstetter and Sepp Hochreiter},
booktitle = {Thirty-eighth Conference on Neural Information Processing Systems},
year={2024},
url={https://arxiv.org/abs/2405.04517},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mlstm_kernels
Similar Open Source Tools
mlstm_kernels
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.
mirage
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.

PDEBench
PDEBench provides a diverse and comprehensive set of benchmarks for scientific machine learning, including challenging and realistic physical problems. The repository consists of code for generating datasets, uploading and downloading datasets, training and evaluating machine learning models as baselines. It features a wide range of PDEs, realistic and difficult problems, ready-to-use datasets with various conditions and parameters. PDEBench aims for extensibility and invites participation from the SciML community to improve and extend the benchmark.
lantern
Lantern is an open-source PostgreSQL database extension designed to store vector data, generate embeddings, and handle vector search operations efficiently. It introduces a new index type called 'lantern_hnsw' for vector columns, which speeds up 'ORDER BY ... LIMIT' queries. Lantern utilizes the state-of-the-art HNSW implementation called usearch. Users can easily install Lantern using Docker, Homebrew, or precompiled binaries. The tool supports various distance functions, index construction parameters, and operator classes for efficient querying. Lantern offers features like embedding generation, interoperability with pgvector, parallel index creation, and external index graph generation. It aims to provide superior performance metrics compared to other similar tools and has a roadmap for future enhancements such as cloud-hosted version, hardware-accelerated distance metrics, industry-specific application templates, and support for version control and A/B testing of embeddings.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.
AirspeedVelocity.jl
AirspeedVelocity.jl is a tool designed to simplify benchmarking of Julia packages over their lifetime. It provides a CLI to generate benchmarks, compare commits/tags/branches, plot benchmarks, and run benchmark comparisons for every submitted PR as a GitHub action. The tool freezes the benchmark script at a specific revision to prevent old history from affecting benchmarks. Users can configure options using CLI flags and visualize benchmark results. AirspeedVelocity.jl can be used to benchmark any Julia package and offers features like generating tables and plots of benchmark results. It also supports custom benchmarks and can be integrated into GitHub actions for automated benchmarking of PRs.
TriForce
TriForce is a training-free tool designed to accelerate long sequence generation. It supports long-context Llama models and offers both on-chip and offloading capabilities. Users can achieve a 2.2x speedup on a single A100 GPU. TriForce also provides options for offloading with tensor parallelism or without it, catering to different hardware configurations. The tool includes a baseline for comparison and is optimized for performance on RTX 4090 GPUs. Users can cite the associated paper if they find TriForce useful for their projects.

ai2-scholarqa-lib
Ai2 Scholar QA is a system for answering scientific queries and literature review by gathering evidence from multiple documents across a corpus and synthesizing an organized report with evidence for each claim. It consists of a retrieval component and a three-step generator pipeline. The retrieval component fetches relevant evidence passages using the Semantic Scholar public API and reranks them. The generator pipeline includes quote extraction, planning and clustering, and summary generation. The system is powered by the ScholarQA class, which includes components like PaperFinder and MultiStepQAPipeline. It requires environment variables for Semantic Scholar API and LLMs, and can be run as local docker containers or embedded into another application as a Python package.
ice-score
ICE-Score is a tool designed to instruct large language models to evaluate code. It provides a minimum viable product (MVP) for evaluating generated code snippets using inputs such as problem, output, task, aspect, and model. Users can also evaluate with reference code and enable zero-shot chain-of-thought evaluation. The tool is built on codegen-metrics and code-bert-score repositories and includes datasets like CoNaLa and HumanEval. ICE-Score has been accepted to EACL 2024.

datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.

cortex
Cortex is a tool that simplifies and accelerates the process of creating applications utilizing modern AI models like chatGPT and GPT-4. It provides a structured interface (GraphQL or REST) to a prompt execution environment, enabling complex augmented prompting and abstracting away model connection complexities like input chunking, rate limiting, output formatting, caching, and error handling. Cortex offers a solution to challenges faced when using AI models, providing a simple package for interacting with NL AI models.
For similar tasks
mlstm_kernels
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.
dravid
Dravid (DRD) is an advanced, AI-powered CLI coding framework designed to follow user instructions until the job is completed, including fixing errors. It can generate code, fix errors, handle image queries, manage file operations, integrate with external APIs, and provide a development server with error handling. Dravid is extensible and requires Python 3.7+ and CLAUDE_API_KEY. Users can interact with Dravid through CLI commands for various tasks like creating projects, asking questions, generating content, handling metadata, and file-specific queries. It supports use cases like Next.js project development, working with existing projects, exploring new languages, Ruby on Rails project development, and Python project development. Dravid's project structure includes directories for source code, CLI modules, API interaction, utility functions, AI prompt templates, metadata management, and tests. Contributions are welcome, and development setup involves cloning the repository, installing dependencies with Poetry, setting up environment variables, and using Dravid for project enhancements.
OnAIR
The On-board Artificial Intelligence Research (OnAIR) Platform is a framework that enables AI algorithms written in Python to interact with NASA's cFS. It is intended to explore research concepts in autonomous operations in a simulated environment. The platform provides tools for generating environments, handling telemetry data through Redis, running unit tests, and contributing to the repository. Users can set up a conda environment, configure telemetry and Redis examples, run simulations, and conduct unit tests to ensure the functionality of their AI algorithms. The platform also includes guidelines for licensing, copyright, and contributions to the repository.
gemma
Gemma is a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. This repository contains an inference implementation and examples, based on the Flax and JAX frameworks. Gemma can run on CPU, GPU, and TPU, with model checkpoints available for download. It provides tutorials, reference implementations, and Colab notebooks for tasks like sampling and fine-tuning. Users can contribute to Gemma through bug reports and pull requests. The code is licensed under the Apache License, Version 2.0.
metaflow-service
Metaflow Service is a metadata service implementation for Metaflow, providing a thin wrapper around a database to keep track of metadata associated with Flows, Runs, Steps, Tasks, and Artifacts. It includes features for managing DB migrations, launching compatible versions of the metadata service, and executing flows locally. The service can be run using Docker or as a standalone service, with options for testing and running unit/integration tests. Users can interact with the service via API endpoints or utility CLI tools.
firebase-ios-sdk
This repository contains the source code for all Apple platform Firebase SDKs except FirebaseAnalytics. Firebase is an app development platform with tools to help you build, grow, and monetize your app. It provides installation methods like Standard pod install, Swift Package Manager, Installing from the GitHub repo, and Experimental Carthage. Development requires Xcode 16.2 or later, and supports CocoaPods and Swift Package Manager. The repository includes instructions for adding a new Firebase Pod, managing headers and imports, code formatting, running unit tests, running sample apps, and generating coverage reports. Specific component instructions are provided for Firebase AI Logic, Firebase Auth, Firebase Database, Firebase Dynamic Links, Firebase Performance Monitoring, Firebase Storage, and Push Notifications. Firebase also offers beta support for macOS, Catalyst, and tvOS, with community support for visionOS and watchOS.
langchain-google
LangChain Google is a repository containing three packages with Google integrations: langchain-google-genai for Google Generative AI models, langchain-google-vertexai for Google Cloud Generative AI on Vertex AI, and langchain-google-community for other Google product integrations. The repository is organized as a monorepo with a structure including libs for different packages, and files like pyproject.toml and Makefile for building, linting, and testing. It provides guidelines for contributing, local development dependencies installation, formatting, linting, working with optional dependencies, and testing with unit and integration tests. The focus is on maintaining unit test coverage and avoiding excessive integration tests, with annotations for GCP infrastructure-dependent tests.
For similar jobs

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.