
metaflow-service
:rocket: Metadata tracking and UI service for Metaflow!
Stars: 196
Metaflow Service is a metadata service implementation for Metaflow, providing a thin wrapper around a database to keep track of metadata associated with Flows, Runs, Steps, Tasks, and Artifacts. It includes features for managing DB migrations, launching compatible versions of the metadata service, and executing flows locally. The service can be run using Docker or as a standalone service, with options for testing and running unit/integration tests. Users can interact with the service via API endpoints or utility CLI tools.
README:
Metadata service implementation for Metaflow.
This provides a thin wrapper around a database and keeps track of metadata associated with metaflow entities such as Flows, Runs, Steps, Tasks, and Artifacts.
For more information, see Metaflow's admin docs
The service depends on the following Environment Variables to be set:
- MF_METADATA_DB_HOST [defaults to localhost]
- MF_METADATA_DB_PORT [defaults to 5432]
- MF_METADATA_DB_USER [defaults to postgres]
- MF_METADATA_DB_PSWD [defaults to postgres]
- MF_METADATA_DB_NAME [defaults to postgres]
Optionally you can also overrider the host and port the service runs on
- MF_METADATA_PORT [defaults to 8080]
- MF_MIGRATION_PORT [defaults to 8082]
- MF_METADATA_HOST [defaults to 0.0.0.0]
Create triggers to broadcast any database changes via pg_notify on channel NOTIFY:
-
DB_TRIGGER_CREATE- [
metadata_servicedefaults to 0] - [
ui_backend_servicedefaults to 1]
- [
pip3 install ./ python3 -m services.metadata_service.server
Swagger UI: http://localhost:8080/api/doc
Easiest way to run this project is to use docker-compose and there are two options:
-
docker-compose.yml- Assumes that Dockerfiles are pre-built and local changes are not included automatically
- See
docker buildsection on how to pre-build the Docker images
-
docker-compose.development.yml- Development version
- Includes automatic Dockerfile builds and mounts local
./servicesfolder inside the container
Running docker-compose.yml:
docker-compose up -d
Running docker-compose.development.yml (recommended during development):
docker-compose -f docker-compose.development.yml up
- Metadata service is available at port
:8080. - Migration service is available at port
:8082. - UI service is available at port
:8083.
to access the container run
docker exec -it metadata_service /bin/bash
within the container curl the service directly
curl localhost:8080/ping
Latest release of the image is available on dockerhub
docker pull netflixoss/metaflow_metadata_service
Be sure to set the proper env variables when running the image
docker run -e MF_METADATA_DB_HOST='<instance_name>.us-east-1.rds.amazonaws.com' \ -e MF_METADATA_DB_PORT=5432 \ -e MF_METADATA_DB_USER='postgres' \ -e MF_METADATA_DB_PSWD='postgres' \ -e MF_METADATA_DB_NAME='metaflow' \ -it -p 8082:8082 -p 8080:8080 metaflow_metadata_service
Tests are run using Tox and pytest.
Run following command to execute tests in Dockerized environment:
docker-compose -f docker-compose.test.yml up -V --abort-on-container-exit
Above command will make sure there's PostgreSQL database available.
Usage without Docker:
The test suite requires a PostgreSQL database, along with the following environment variables for connecting the tested services to the DB.
- MF_METADATA_DB_HOST=db_test
- MF_METADATA_DB_PORT=5432
- MF_METADATA_DB_USER=test
- MF_METADATA_DB_PSWD=test
- MF_METADATA_DB_NAME=test
# Run all tests tox # Run unit tests only tox -e unit # Run integration tests only tox -e integration # Run both unit & integrations tests in parallel tox -e unit,integration -p
With the metadata service up and running at http://localhost:8080, you are able to use this as the service when executing Flows with the Metaflow client locally via
METAFLOW_SERVICE_URL=http://localhost:8080 METAFLOW_DEFAULT_METADATA="service" python3 basicflow.py runAlternatively you can configure a default profile with the service URL for the Metaflow client to use. See Configuring metaflow for instructions.
The Migration service is a tool to help users manage underlying DB migrations and launch the most recent compatible version of the metadata service
Note that it is possible to run the two services independently and a Dockerfile is supplied for each service. However the default Dockerfile combines the two services.
Also note that at runtime the migration service and the metadata service are completely disjoint and do not communicate with each other
Note may need to do a rolling restart to get latest version of the image if you don't have it already
You can manage the migration either via the api provided or with the utility cli provided with migration_tools.py
- check status and note version you are on
- Api:
/db_schema_status - cli:
python3 migration_tools.py db-status
- Api:
- see if there are migrations to be run
- if there are any migrations to be run
is_up_to_dateshould be false and a list of migrations to be applied will be shown underunapplied_migrations
- if there are any migrations to be run
- take backup of db
- in case anything goes wrong it is a good idea to take a back up of the db
- migrations may cause downtime depending on what is being run as part of the migration
- Note concurrent updates are not supported. it may be advisable to reduce your cluster size to a single node
- upgrade db schema
- Api:
/upgrade - cli:
python3 migration_tools.py upgrade
- Api:
- check status again to verify you are on up to date version
- Api:
/db_schema_status - cli:
python3 migration_tools.py db-status - Note that
is_up_to_dateshould be set to True andmigration_in_progressshould be set to False
- Api:
- do a rolling restart of the metadata service cluster
- In order for the migration to be effective a full restart of the containers is required
- latest available version of service should be ready
- cli:
python3 migration_tools.py metadata-service-version
- cli:
- If you had previously scaled down your cluster it should be safe to return it to the desired number of containers
Within the published metaflow_metadata_service image the migration service is packaged along with the latest version of the metadata service compatible with every version of the db. This means that multiple versions of the metadata service comes bundled with the image, each is installed under a different virtual env.
When the container spins up, the migration service is launched first and determines what virtualenv to activate depending on the schema version of the DB. This will determine which version of the metadata service will run.
See the release docs
There are several ways to get in touch with us:
- Open an issue at: https://github.com/Netflix/metaflow-service
- Email us at: [email protected]
- Chat with us on: http://chat.metaflow.org
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for metaflow-service
Similar Open Source Tools
metaflow-service
Metaflow Service is a metadata service implementation for Metaflow, providing a thin wrapper around a database to keep track of metadata associated with Flows, Runs, Steps, Tasks, and Artifacts. It includes features for managing DB migrations, launching compatible versions of the metadata service, and executing flows locally. The service can be run using Docker or as a standalone service, with options for testing and running unit/integration tests. Users can interact with the service via API endpoints or utility CLI tools.
0chain
Züs is a high-performance cloud on a fast blockchain offering privacy and configurable uptime. It uses erasure code to distribute data between data and parity servers, allowing flexibility for IT managers to design for security and uptime. Users can easily share encrypted data with business partners through a proxy key sharing protocol. The ecosystem includes apps like Blimp for cloud migration, Vult for personal cloud storage, and Chalk for NFT artists. Other apps include Bolt for secure wallet and staking, Atlus for blockchain explorer, and Chimney for network participation. The QoS protocol challenges providers based on response time, while the privacy protocol enables secure data sharing. Züs supports hybrid and multi-cloud architectures, allowing users to improve regulatory compliance and security requirements.

vulnerability-analysis
The NVIDIA AI Blueprint for Vulnerability Analysis for Container Security showcases accelerated analysis on common vulnerabilities and exposures (CVE) at an enterprise scale, reducing mitigation time from days to seconds. It enables security analysts to determine software package vulnerabilities using large language models (LLMs) and retrieval-augmented generation (RAG). The blueprint is designed for security analysts, IT engineers, and AI practitioners in cybersecurity. It requires NVAIE developer license and API keys for vulnerability databases, search engines, and LLM model services. Hardware requirements include L40 GPU for pipeline operation and optional LLM NIM and Embedding NIM. The workflow involves LLM pipeline for CVE impact analysis, utilizing LLM planner, agent, and summarization nodes. The blueprint uses NVIDIA NIM microservices and Morpheus Cybersecurity AI SDK for vulnerability analysis.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.
aides-jeunes
The user interface (and the main server) of the simulator of aids and social benefits for young people. It is based on the free socio-fiscal simulator Openfisca.
seer
Seer is a service that provides AI capabilities to Sentry by running inference on Sentry issues and providing user insights. It is currently in early development and not yet compatible with self-hosted Sentry instances. The tool requires access to internal Sentry resources and is intended for internal Sentry employees. Users can set up the environment, download model artifacts, integrate with local Sentry, run evaluations for Autofix AI agent, and deploy to a sandbox staging environment. Development commands include applying database migrations, creating new migrations, running tests, and more. The tool also supports VCRs for recording and replaying HTTP requests.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and enhancing collaboration between teams. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, setting project and model configuration, launching and monitoring training jobs, and media upload and prediction. The SDK also includes tutorial-style Jupyter notebooks demonstrating its usage.

unitycatalog
Unity Catalog is an open and interoperable catalog for data and AI, supporting multi-format tables, unstructured data, and AI assets. It offers plugin support for extensibility and interoperates with Delta Sharing protocol. The catalog is fully open with OpenAPI spec and OSS implementation, providing unified governance for data and AI with asset-level access control enforced through REST APIs.
LLM-Engineers-Handbook
The LLM Engineer's Handbook is an official repository containing a comprehensive guide on creating an end-to-end LLM-based system using best practices. It covers data collection & generation, LLM training pipeline, a simple RAG system, production-ready AWS deployment, comprehensive monitoring, and testing and evaluation framework. The repository includes detailed instructions on setting up local and cloud dependencies, project structure, installation steps, infrastructure setup, pipelines for data processing, training, and inference, as well as QA, tests, and running the project end-to-end.

geti-sdk
The Intel® Geti™ SDK is a python package that enables teams to rapidly develop AI models by easing the complexities of model development and fostering collaboration. It provides tools to interact with an Intel® Geti™ server via the REST API, allowing for project creation, downloading, uploading, deploying for local inference with OpenVINO, configuration management, training job monitoring, media upload, and prediction. The repository also includes tutorial-style Jupyter notebooks demonstrating SDK usage.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
For similar tasks
metaflow-service
Metaflow Service is a metadata service implementation for Metaflow, providing a thin wrapper around a database to keep track of metadata associated with Flows, Runs, Steps, Tasks, and Artifacts. It includes features for managing DB migrations, launching compatible versions of the metadata service, and executing flows locally. The service can be run using Docker or as a standalone service, with options for testing and running unit/integration tests. Users can interact with the service via API endpoints or utility CLI tools.
langchain-google
LangChain Google is a repository containing three packages with Google integrations: langchain-google-genai for Google Generative AI models, langchain-google-vertexai for Google Cloud Generative AI on Vertex AI, and langchain-google-community for other Google product integrations. The repository is organized as a monorepo with a structure including libs for different packages, and files like pyproject.toml and Makefile for building, linting, and testing. It provides guidelines for contributing, local development dependencies installation, formatting, linting, working with optional dependencies, and testing with unit and integration tests. The focus is on maintaining unit test coverage and avoiding excessive integration tests, with annotations for GCP infrastructure-dependent tests.
dravid
Dravid (DRD) is an advanced, AI-powered CLI coding framework designed to follow user instructions until the job is completed, including fixing errors. It can generate code, fix errors, handle image queries, manage file operations, integrate with external APIs, and provide a development server with error handling. Dravid is extensible and requires Python 3.7+ and CLAUDE_API_KEY. Users can interact with Dravid through CLI commands for various tasks like creating projects, asking questions, generating content, handling metadata, and file-specific queries. It supports use cases like Next.js project development, working with existing projects, exploring new languages, Ruby on Rails project development, and Python project development. Dravid's project structure includes directories for source code, CLI modules, API interaction, utility functions, AI prompt templates, metadata management, and tests. Contributions are welcome, and development setup involves cloning the repository, installing dependencies with Poetry, setting up environment variables, and using Dravid for project enhancements.
OnAIR
The On-board Artificial Intelligence Research (OnAIR) Platform is a framework that enables AI algorithms written in Python to interact with NASA's cFS. It is intended to explore research concepts in autonomous operations in a simulated environment. The platform provides tools for generating environments, handling telemetry data through Redis, running unit tests, and contributing to the repository. Users can set up a conda environment, configure telemetry and Redis examples, run simulations, and conduct unit tests to ensure the functionality of their AI algorithms. The platform also includes guidelines for licensing, copyright, and contributions to the repository.
gemma
Gemma is a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. This repository contains an inference implementation and examples, based on the Flax and JAX frameworks. Gemma can run on CPU, GPU, and TPU, with model checkpoints available for download. It provides tutorials, reference implementations, and Colab notebooks for tasks like sampling and fine-tuning. Users can contribute to Gemma through bug reports and pull requests. The code is licensed under the Apache License, Version 2.0.
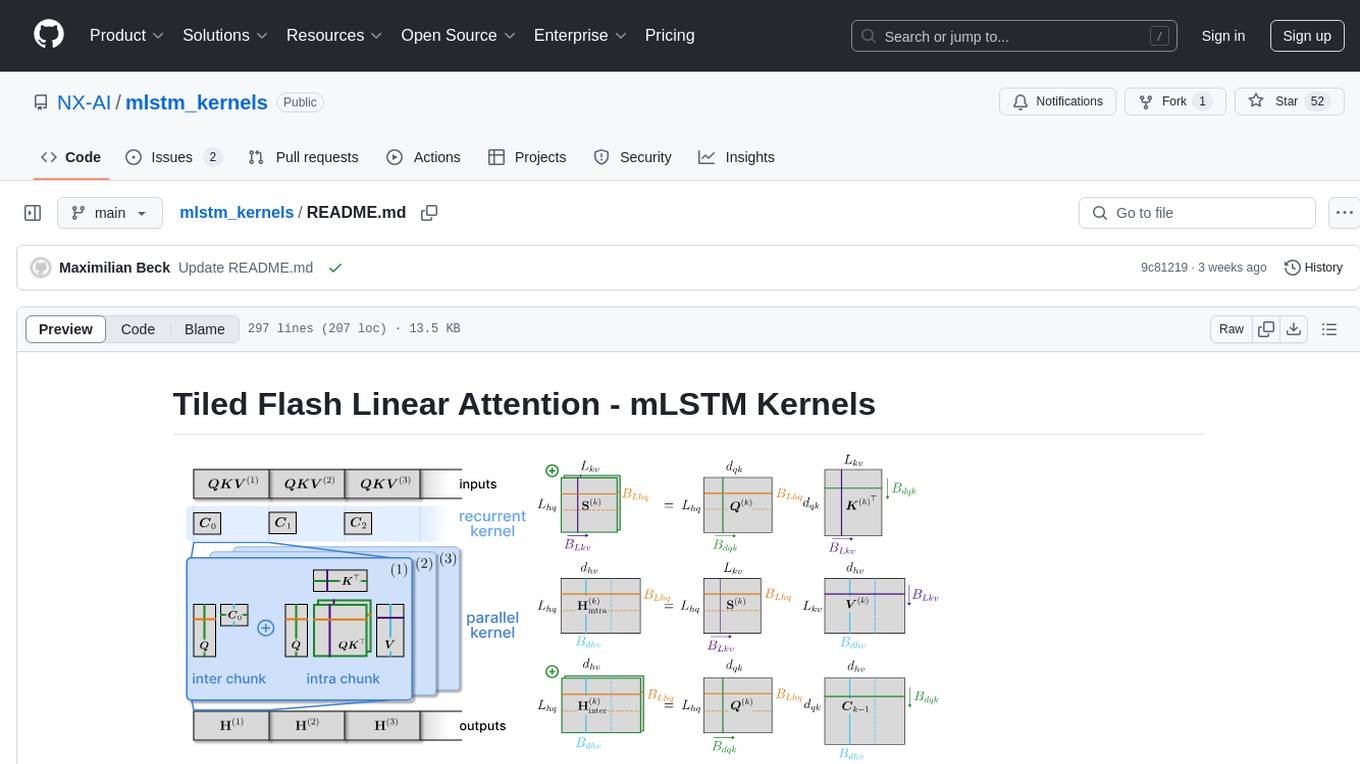
mlstm_kernels
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.
firebase-ios-sdk
This repository contains the source code for all Apple platform Firebase SDKs except FirebaseAnalytics. Firebase is an app development platform with tools to help you build, grow, and monetize your app. It provides installation methods like Standard pod install, Swift Package Manager, Installing from the GitHub repo, and Experimental Carthage. Development requires Xcode 16.2 or later, and supports CocoaPods and Swift Package Manager. The repository includes instructions for adding a new Firebase Pod, managing headers and imports, code formatting, running unit tests, running sample apps, and generating coverage reports. Specific component instructions are provided for Firebase AI Logic, Firebase Auth, Firebase Database, Firebase Dynamic Links, Firebase Performance Monitoring, Firebase Storage, and Push Notifications. Firebase also offers beta support for macOS, Catalyst, and tvOS, with community support for visionOS and watchOS.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.