
datadreamer
Creation of annotated datasets from scratch using Generative AI and Foundation Computer Vision models
Stars: 77

DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.
README:



To generate your dataset with custom classes, you need to execute only two commands:
pip install datadreamer
datadreamer --class_names person moon robot
DataDreamer is an advanced toolkit engineered to facilitate the development of edge AI models, irrespective of initial data availability. Distinctive features of DataDreamer include:
-
Synthetic Data Generation: Eliminate the dependency on extensive datasets for AI training. DataDreamer empowers users to generate synthetic datasets from the ground up, utilizing advanced AI algorithms capable of producing high-quality, diverse images.
-
Knowledge Extraction from Foundational Models:
DataDreamerleverages the latent knowledge embedded within sophisticated, pre-trained AI models. This capability allows for the transfer of expansive understanding from these "Foundation models" to smaller, custom-built models, enhancing their capabilities significantly. -
Efficient and Potent Models: The primary objective of
DataDreameris to enable the creation of compact models that are both size-efficient for integration into any device and robust in performance for specialized tasks.
- 🚀 Quickstart
- 🌟 Overview
- 🛠️ Features
- 💻 Installation
- ⚙️ Hardware Requirements
- 📋 Usage
⚠️ Limitations- 📄 License
- 🙏 Acknowledgements
-
Prompt Generation: Automate the creation of image prompts using powerful language models.
Provided class names: ["horse", "robot"]
Generated prompt: "A photo of a horse and a robot coexisting peacefully in the midst of a serene pasture."
-
Image Generation: Generate synthetic datasets with state-of-the-art generative models.
-
Dataset Annotation: Leverage foundation models to label datasets automatically.
-
Edge Model Training: Train efficient small-scale neural networks for edge deployment. (not part of this library)


There are two ways to install the datadreamer library:
Using pip:
To install with pip:
pip install datadreamerUsing Docker (for Linux/Windows):
Pull Docker Image from GHCR:
docker pull ghcr.io/luxonis/datadreamer:latestOr build Docker Image from source:
# Clone the repository
git clone https://github.com/luxonis/datadreamer.git
cd datadreamer
# Build Docker Image
docker build -t datadreamer .Run Docker Container (assuming it's GHCR image, otherwise replace ghcr.io/luxonis/datadreamer:latest with datadreamer)
Run on CPU:
docker run --rm -v "$(pwd):/app" ghcr.io/luxonis/datadreamer:latest --save_dir generated_dataset --device cpuRun on GPU, make sure to have nvidia-docker installed:
docker run --rm --gpus all -v "$(pwd):/app" ghcr.io/luxonis/datadreamer:latest --save_dir generated_dataset --device cudaThese commands mount the current directory ($(pwd)) to the /app directory inside the container, allowing you to access files from your local machine.
To ensure optimal performance and compatibility with the libraries used in this project, the following hardware specifications are recommended:
-
GPU: A CUDA-compatible GPU with a minimum of 16 GB memory. This is essential for libraries liketorch,torchvision,transformers, anddiffusers, which leverage CUDA for accelerated computing in machine learning and image processing tasks. -
RAM: At least 16 GB of system RAM, although more (32 GB or above) is beneficial for handling large datasets and intensive computations.
The datadreamer/pipelines/generate_dataset_from_scratch.py (datadreamer command) script is a powerful tool for generating and annotating images with specific objects. It uses advanced models to both create images and accurately annotate them with bounding boxes for designated objects.
Run the following command in your terminal to use the script:
datadreamer --save_dir <directory> --class_names <objects> --prompts_number <number> [additional options]or using a .yaml config file
datadreamer --config <path-to-config>-
--save_dir(required): Path to the directory for saving generated images and annotations. -
--class_names(required): Space-separated list of object names for image generation and annotation. Example:person moon robot. -
--prompts_number(optional): Number of prompts to generate for each object. Defaults to10. -
--annotate_only(optional): Only annotate the images without generating new ones, prompt and image generator will be skipped. Defaults toFalse.
-
--task: Choose between detection and classification. Default isdetection. -
--dataset_format: Format of the dataset. Defaults toraw. Supported values:raw,yolo,coco,luxonis-dataset,cls-single. -
--split_ratios: Split ratios for train, validation, and test sets. Defaults to[0.8, 0.1, 0.1]. -
--num_objects_range: Range of objects in a prompt. Default is 1 to 3. -
--prompt_generator: Choose betweensimple,lm(language model) andtiny(tiny LM). Default issimple. -
--image_generator: Choose image generator, e.g.,sdxl,sdxl-turboorsdxl-lightning. Default issdxl-turbo. -
--image_annotator: Specify the image annotator, likeowlv2for object detection orclipfor image classification. Default isowlv2. -
--conf_threshold: Confidence threshold for annotation. Default is0.15. -
--annotation_iou_threshold: Intersection over Union (IoU) threshold for annotation. Default is0.2. -
--prompt_prefix: Prefix to add to every image generation prompt. Default is"". -
--prompt_suffix: Suffix to add to every image generation prompt, e.g., for adding details like resolution. Default is", hd, 8k, highly detailed". -
--negative_prompt: Negative prompts to guide the generation away from certain features. Default is"cartoon, blue skin, painting, scrispture, golden, illustration, worst quality, low quality, normal quality:2, unrealistic dream, low resolution, static, sd character, low quality, low resolution, greyscale, monochrome, nose, cropped, lowres, jpeg artifacts, deformed iris, deformed pupils, bad eyes, semi-realistic worst quality, bad lips, deformed mouth, deformed face, deformed fingers, bad anatomy". -
--use_tta: Toggle test time augmentation for object detection. Default isFalse. -
--synonym_generator: Enhance class names with synonyms. Default isnone. Other options arellm,wordnet. -
--use_image_tester: Use image tester for image generation. Default isFalse. -
--image_tester_patience: Patience level for image tester. Default is1. -
--lm_quantization: Quantization to use for Mistral language model. Choose betweennoneand4bit. Default isnone. -
--annotator_size: Size of the annotator model to use. Choose betweenbaseandlarge. Default isbase. -
--batch_size_prompt: Batch size for prompt generation. Default is 64. -
--batch_size_annotation: Batch size for annotation. Default is1. -
--batch_size_image: Batch size for image generation. Default is1. -
--device: Choose betweencudaandcpu. Default iscuda. -
--seed: Set a random seed for image and prompt generation. Default is42. -
--config: A path to an optional.yamlconfig file specifying the pipeline's arguments.
| Model Category | Model Names | Description/Notes |
|---|---|---|
| Prompt Generation | Mistral-7B-Instruct-v0.1 | Semantically rich prompts |
| TinyLlama-1.1B-Chat-v1.0 | Tiny LM | |
| Simple random generator | Joins randomly chosen object names | |
| Image Generation | SDXL-1.0 | Slow and accurate (1024x1024 images) |
| SDXL-Turbo | Fast and less accurate (512x512 images) | |
| SDXL-Lightning | Fast and accurate (1024x1024 images) | |
| Image Annotation | OWLv2 | Open-Vocabulary object detector |
| CLIP | Zero-shot-image-classification |
datadreamer --save_dir path/to/save_directory --class_names person moon robot --prompts_number 20 --prompt_generator simple --num_objects_range 1 3 --image_generator sdxl-turboor using a .yaml config file (if arguments are provided with the config file in the command, they will override the ones in the config file):
datadreamer --save_dir path/to/save_directory --config configs/det_config.yamlThis command generates images for the specified objects, saving them and their annotations in the given directory. The script allows customization of the generation process through various parameters, adapting to different needs and hardware configurations.
See /configs folder for some examples of the .yaml config files.
The dataset comprises two primary components: images and their corresponding annotations, stored as JSON files.
save_dir/
│
├── image_1.jpg
├── image_2.jpg
├── ...
├── image_n.jpg
├── prompts.json
└── annotations.json- Detection Annotations (detection_annotations.json):
- Each entry corresponds to an image and contains bounding boxes and labels for objects in the image.
- Format:
{
"image_path": {
"boxes": [[x_min, y_min, x_max, y_max], ...],
"labels": [label_index, ...]
},
...
"class_names": ["class1", "class2", ...]
}- Classification Annotations (classification_annotations.json):
- Each entry corresponds to an image and contains labels for the image.
- Format:
{
"image_path": {
"labels": [label_index, ...]
},
...
"class_names": ["class1", "class2", ...]
}While the datadreamer library leverages advanced Generative models to synthesize datasets and Foundation models for annotation, there are inherent limitations to consider:
-
Incomplete Object Representation: Occasionally, the generative models might not include all desired objects in the synthetic images. This could result from the complexity of the scene or limitations within the model's learned patterns. -
Annotation Accuracy: The annotations created by foundation computer vision models may not always be precise. These models strive for accuracy, but like all automated systems, they are not infallible and can sometimes produce erroneous or ambiguous labels. However, we have implemented several strategies to mitigate these issues, such as Test Time Augmentation (TTA), usage of synonyms for class names and careful selection of the confidence/IOU thresholds.
Despite these limitations, the datasets created by datadreamer provide a valuable foundation for developing and training models, especially for edge computing scenarios where data availability is often a challenge. The synthetic and annotated data should be seen as a stepping stone, granting a significant head start in the model development process.
This project is licensed under the Apache License, Version 2.0 - see the LICENSE file for details.
The above license does not cover the models. Please see the license of each model in the table above.
This library was made possible by the use of several open-source projects, including Transformers, Diffusers, and others listed in the requirements.txt.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for datadreamer
Similar Open Source Tools
datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.
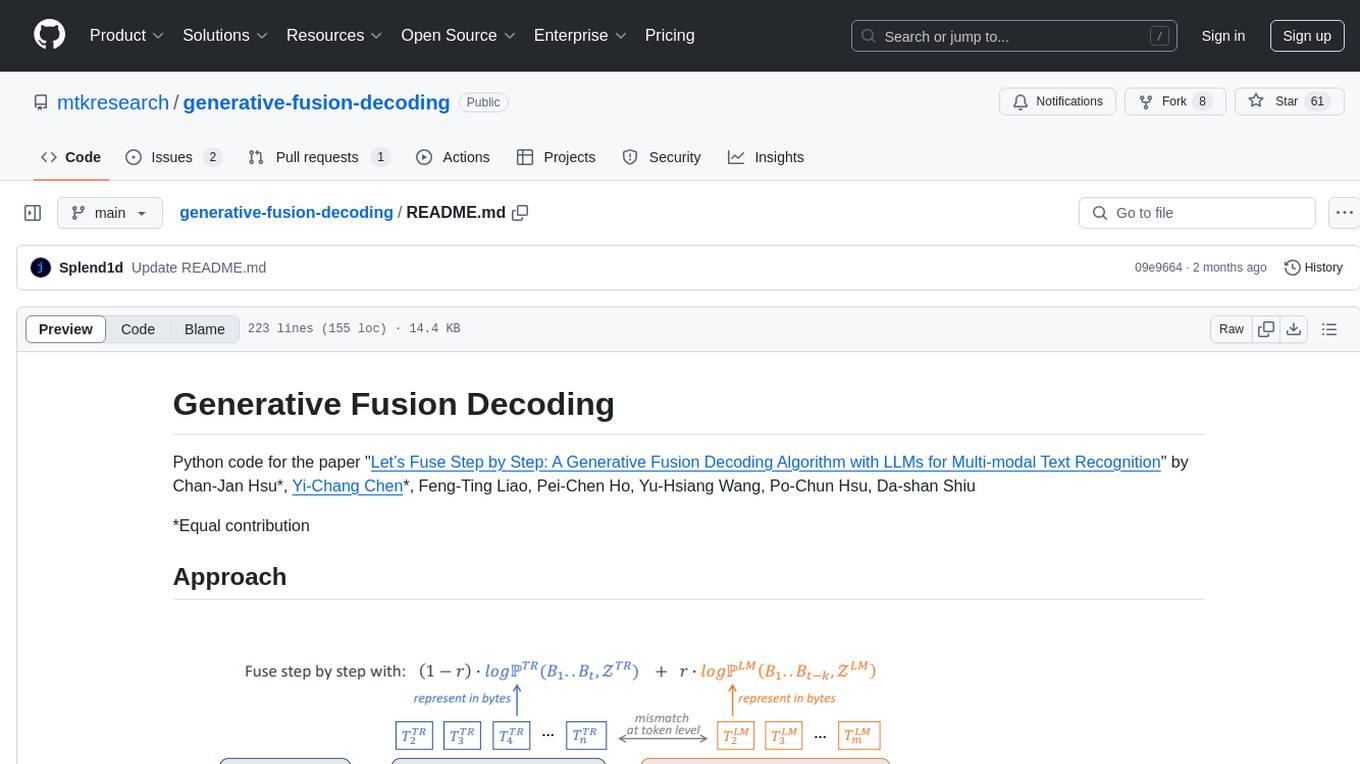
generative-fusion-decoding
Generative Fusion Decoding (GFD) is a novel shallow fusion framework that integrates Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). GFD operates across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. It simplifies the complexity of aligning different model sample spaces, allows LLMs to correct errors in tandem with the recognition model, increases robustness in long-form speech recognition, and enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. GFD significantly improves performance in ASR and OCR tasks, offering a unified solution for leveraging existing pre-trained models through step-by-step fusion.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.
mergekit
Mergekit is a toolkit for merging pre-trained language models. It uses an out-of-core approach to perform unreasonably elaborate merges in resource-constrained situations. Merges can be run entirely on CPU or accelerated with as little as 8 GB of VRAM. Many merging algorithms are supported, with more coming as they catch my attention.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
lantern
Lantern is an open-source PostgreSQL database extension designed to store vector data, generate embeddings, and handle vector search operations efficiently. It introduces a new index type called 'lantern_hnsw' for vector columns, which speeds up 'ORDER BY ... LIMIT' queries. Lantern utilizes the state-of-the-art HNSW implementation called usearch. Users can easily install Lantern using Docker, Homebrew, or precompiled binaries. The tool supports various distance functions, index construction parameters, and operator classes for efficient querying. Lantern offers features like embedding generation, interoperability with pgvector, parallel index creation, and external index graph generation. It aims to provide superior performance metrics compared to other similar tools and has a roadmap for future enhancements such as cloud-hosted version, hardware-accelerated distance metrics, industry-specific application templates, and support for version control and A/B testing of embeddings.

garak
Garak is a free tool that checks if a Large Language Model (LLM) can be made to fail in a way that is undesirable. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Garak's a free tool. We love developing it and are always interested in adding functionality to support applications.
sec-code-bench
SecCodeBench is a benchmark suite for evaluating the security of AI-generated code, specifically designed for modern Agentic Coding Tools. It addresses challenges in existing security benchmarks by ensuring test case quality, employing precise evaluation methods, and covering Agentic Coding Tools. The suite includes 98 test cases across 5 programming languages, focusing on functionality-first evaluation and dynamic execution-based validation. It offers a highly extensible testing framework for end-to-end automated evaluation of agentic coding tools, generating comprehensive reports and logs for analysis and improvement.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.

verifiers
Verifiers is a library of modular components for creating RL environments and training LLM agents. It includes an async GRPO implementation built around the `transformers` Trainer, is supported by `prime-rl` for large-scale FSDP training, and can easily be integrated into any RL framework which exposes an OpenAI-compatible inference client. The library provides tools for creating and evaluating RL environments, training LLM agents, and leveraging OpenAI-compatible models for various tasks. Verifiers aims to be a reliable toolkit for building on top of, minimizing fork proliferation in the RL infrastructure ecosystem.
ice-score
ICE-Score is a tool designed to instruct large language models to evaluate code. It provides a minimum viable product (MVP) for evaluating generated code snippets using inputs such as problem, output, task, aspect, and model. Users can also evaluate with reference code and enable zero-shot chain-of-thought evaluation. The tool is built on codegen-metrics and code-bert-score repositories and includes datasets like CoNaLa and HumanEval. ICE-Score has been accepted to EACL 2024.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

stark
STaRK is a large-scale semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. It provides natural-sounding and practical queries crafted to incorporate rich relational information and complex textual properties, closely mirroring real-life scenarios. The benchmark aims to assess how effectively large language models can handle the interplay between textual and relational requirements in queries, using three diverse knowledge bases constructed from public sources.
llmgraph
llmgraph is a tool that enables users to create knowledge graphs in GraphML, GEXF, and HTML formats by extracting world knowledge from large language models (LLMs) like ChatGPT. It supports various entity types and relationships, offers cache support for efficient graph growth, and provides insights into LLM costs. Users can customize the model used and interact with different LLM providers. The tool allows users to generate interactive graphs based on a specified entity type and Wikipedia link, making it a valuable resource for knowledge graph creation and exploration.
kvpress
This repository implements multiple key-value cache pruning methods and benchmarks using transformers, aiming to simplify the development of new methods for researchers and developers in the field of long-context language models. It provides a set of 'presses' that compress the cache during the pre-filling phase, with each press having a compression ratio attribute. The repository includes various training-free presses, special presses, and supports KV cache quantization. Users can contribute new presses and evaluate the performance of different presses on long-context datasets.
For similar tasks

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.
datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.

hcaptcha-challenger
hCaptcha Challenger is a tool designed to gracefully face hCaptcha challenges using a multimodal large language model. It does not rely on Tampermonkey scripts or third-party anti-captcha services, instead implementing interfaces for 'AI vs AI' scenarios. The tool supports various challenge types such as image labeling, drag and drop, and advanced tasks like self-supervised challenges and Agentic Workflow. Users can access documentation in multiple languages and leverage resources for tasks like model training, dataset annotation, and model upgrading. The tool aims to enhance user experience in handling hCaptcha challenges with innovative AI capabilities.
llm-swarm
llm-swarm is a tool designed to manage scalable open LLM inference endpoints in Slurm clusters. It allows users to generate synthetic datasets for pretraining or fine-tuning using local LLMs or Inference Endpoints on the Hugging Face Hub. The tool integrates with huggingface/text-generation-inference and vLLM to generate text at scale. It manages inference endpoint lifetime by automatically spinning up instances via `sbatch`, checking if they are created or connected, performing the generation job, and auto-terminating the inference endpoints to prevent idling. Additionally, it provides load balancing between multiple endpoints using a simple nginx docker for scalability. Users can create slurm files based on default configurations and inspect logs for further analysis. For users without a Slurm cluster, hosted inference endpoints are available for testing with usage limits based on registration status.

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.