
generative-fusion-decoding
Generative Fusion Decoding (GFD) is a novel framework for integrating Large Language Models (LLMs) into multi-modal text recognition systems like ASR and OCR, improving performance and efficiency by enabling seamless fusion without requiring re-training.
Stars: 61
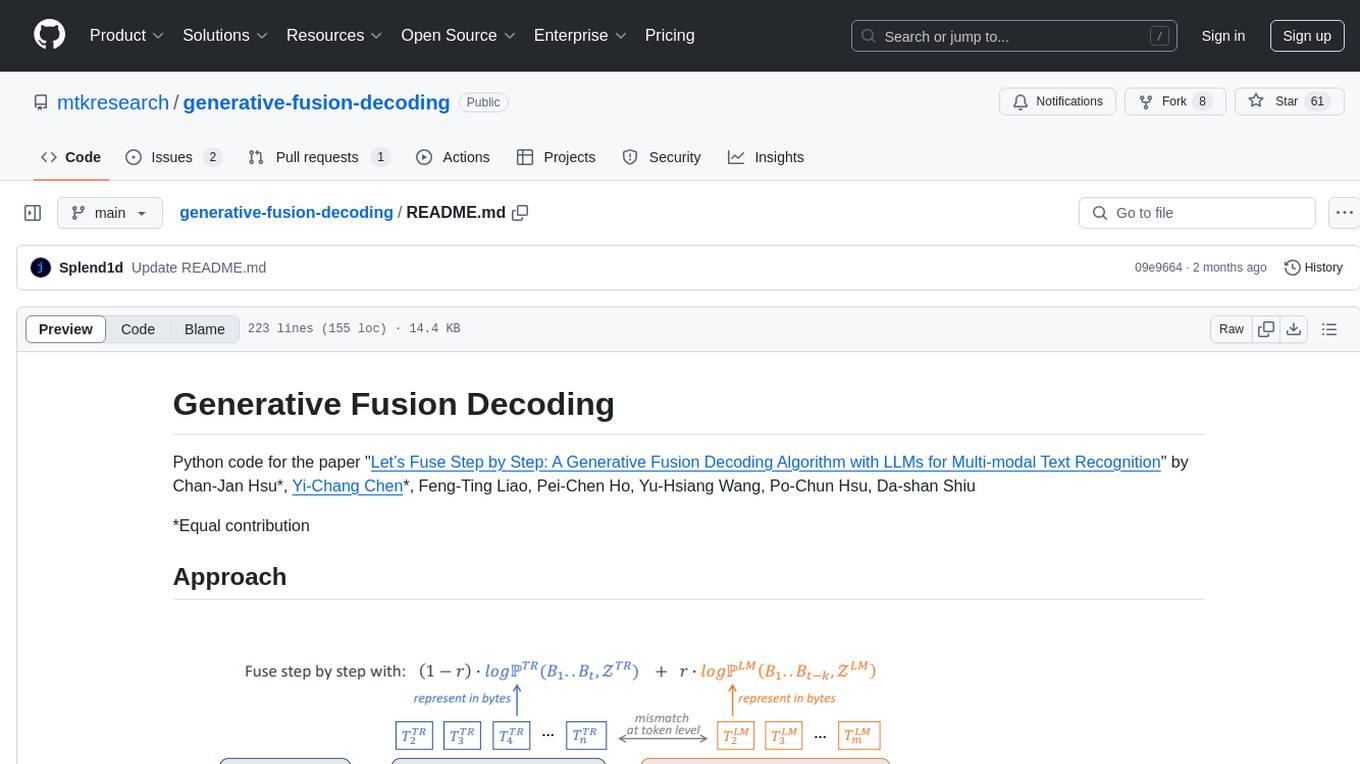
Generative Fusion Decoding (GFD) is a novel shallow fusion framework that integrates Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). GFD operates across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. It simplifies the complexity of aligning different model sample spaces, allows LLMs to correct errors in tandem with the recognition model, increases robustness in long-form speech recognition, and enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. GFD significantly improves performance in ASR and OCR tasks, offering a unified solution for leveraging existing pre-trained models through step-by-step fusion.
README:
Python code for the paper "Let’s Fuse Step by Step: A Generative Fusion Decoding Algorithm with LLMs for Multi-modal Text Recognition" by Chan-Jan Hsu*, Yi-Chang Chen*, Feng-Ting Liao, Pei-Chen Ho, Yu-Hsiang Wang, Po-Chun Hsu, Da-shan Shiu
*Equal contribution

We introduce "Generative Fusion Decoding" (GFD), a novel shallow fusion framework, utilized to integrate Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). We derive the formulas necessary to enable GFD to operate across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. The framework is plug-and-play, compatible with various auto-regressive models, and does not require re-training for feature alignment, thus overcoming limitations of previous fusion techniques. We highlight three main advantages of GFD: First, by simplifying the complexity of aligning different model sample spaces, GFD allows LLMs to correct errors in tandem with the recognition model, reducing computation latencies. Second, the in-context learning ability of LLMs is fully capitalized by GFD, increasing robustness in long-form speech recognition and instruction aware speech recognition. Third, GFD enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. Our evaluation demonstrates that GFD significantly improves performance in ASR and OCR tasks, with ASR reaching state-of-the-art in the NTUML2021 benchmark. GFD provides a significant step forward in model integration, offering a unified solution that could be widely applicable to leveraging existing pre-trained models through step by step fusion.
-
Clone the repository:
git clone https://github.com/mtkresearch/generative-fusion-decoding.git cd generative-fusion-decoding -
Create a python virtual environment:
python -m venv venv source venv/bin/activate # On Windows use `venv\Scripts\activate` -
Install the required package:
pip install -r requirements.txt -
Run the setup script:
python setup.py install
We run GFD on 1*A6000 machine
Memory Breakdown: ASR - Whisper Large ~3GB, LLM - Breeze/Mistral ~14GB
🤗You can try it out hassle-free with Kaggle T4 GPUs here!
To run the script, the following three arguments are required:
-
--model_name: This argument specifies which type of model to use. There are two options:-
gfd: The generative fusion decoding method.
-
-
--setting: The argument specifies the configuration setting for the model. The available settings depend on themodel_name:-
asr-zhtw: The complete version of our method's configuration for testing on a Traditional Chinese sample. -
asr-zhtw-lmoff: Uses our custom beam search method on the ASR model, neglecting the output from the LLM (fusing_r = 0) for a Traditional Chinese sample. -
asr-en: The complete version of our method's configuration for testing on an English sample. -
asr-en-lmoff: Uses our custom beam search method on the ASR model, neglecting the output from the LLM (fusing_r = 0) for an English dataset sample.
-
-
--audio_file_path: The path to the audio file that you want to process. -
--result_output_path: The path where the output result will be saved.
Example Usage
python benchmarks/run_single_file.py --model_name gfd --setting asr-zhtw --audio_file_path demo_examples/zh_news.wav --result_output_path output.txt
To run the benchmark dataset, the following four arguments are required:
-
--dataset_name: Each dataset we tested has a short version name for easy reference. When you runbenchmarks/run_benchmark.py, the script will automatically download the specified dataset from Hugging Face. Below is a list of short version names of datasets used.- ml-lecture-long-2021: A dataset of long-form audio recordings from NTU 2021 machine learning lectures.
- formosa-long: A dataset of long-form audio recordings in Traditional Chinese.
- fleurs-hk: The Google Fleurs dataset using the split of yue_hant_hk.
- noisy-librispeech-10: Librispeech dataset with noises added to the audio (S/R = 10).
- noisy-librispeech-5: Librispeech dataset with noises added to the audio (S/R = 5).
- atco2: Air Traffic Control Voice Communication dataset.
-
--model_name: This argument specifies which type of model to use. There are two options:-
gfd: The generative fusion decoding method. -
whisper: The huggingface whisper generation method.
-
-
--setting: The argument specifies the configuration setting for the model. The available settings depend on themodel_name:For gfd:
-
asr-zhtw: The complete version of our method's configuration for testing on the Traditional Chinese dataset. -
asr-zhtw-lmoff: Uses our custom beam search method on the ASR model, neglecting the output from the LLM (fusing_r = 0) for Traditional Chinese dataset. -
asr-en: he complete version of our method's configuration for testing on the English dataset. -
asr-en-lmoff: Uses our custom beam search method on the ASR model, neglecting the output from the LLM (fusing_r = 0) for the English dataset.
For whisper:
-
whisper-zhtw: The configuration for the Traditional Chinese dataset. -
whisper-en: The configuration for the English dataset.
-
-
--output_dir: The argument specifies the path to the directory where the model output will be stored. The outputs of the model will be stored in two subfolders:-
temp_results: Stores the result of each sample to a JSON file. -
ds_result: Stores the whole dataset along with the model predictions.
-
Example Usage
Here are some example commands for different configuration:
- Using
gfdmodel withasr-zhtwsetting onml-lecture-2021-longdataset
python benchmarks/run_benchmark.py --dataset_name ml-lecture-2021-long --model_name gfd --setting asr-zhtw --output_dir result/
- Using
whispermodel withwhisper-zhtwsetting onml-lecture-2021-longdataset
python benchmarks/run_benchmark.py --dataset_name ml-lecture-2021-long --model_name whisper --setting whisper-zhtw --output_dir result/
Using Multiple GPUs
If you have multiple GPUs, you can change the device configuration in the config file.
There are configurations for GFD and Whisper model under config_files/model, including Traditional Chinese and English for both models.
- GFD:
- Traditional Chinese:
gfd-asr-zhtw.yaml - English:
gfd-asr-en.yaml
- Traditional Chinese:
- Whisper:
- Traditional Chinese:
whisper-zhtw.yaml - English:
whisper-en.yaml
- Traditional Chinese:
In config_files/prompt, it also includes task-specific configurations of Automatic Speech Recognition (ASR) and Language Model (LLM) prompts for gfd. The naming rule for prompt configuration file is {short version dataset name}_prompt.yaml.
The general configuration files gfd-asr-zhtw.yaml and gfd-asr-en.yaml contain various configuration options. Below are the meanings and choices for each argument, divided into three parts based on the likelihood of needing to reset them.
-
asr_model_path: Path to the Automatic Speech Recognition (ASR) model for speech recognition. -
llm_model_path: Path to the Language Model (LLM) for language processing task. -
lang: Language code for the ASR model, 'en' for English and 'zh' for Chinese. -
asr_device: Device to run the ASR model on. -
llm_device: Device to run the LLM on.
-
force_character_mode: Output mode of characters whenlang == 'zh', options include'tc'for traditional Chinese characters,'sc'for simplified Chinese characters andNonefor no specific mode specified -
seg_with_overlap: Default isFalse. When set toTrue, the audio will be segmented with a short interval of overlap. If set tofalse, the audio will be segmented without any overlap. -
fusing_strategy: Default issimple. The fusing score of ASR and LLM will be the weighted sum of ASR score and LLM score. score =fusing_r*llm_score+1-fusing_r*asr_score. -
use_cache: Default isdynamic. When set todynamic, the model will run with key-value (kv) cache enabled, which speeds up the processing, especially for long-from audio. If set toNone, the kv cache will be disabled. If you are facing memory issues, consider setting it toNoneto release memory. -
fusing_r: Fusing ratio used in the fusing strategy to combine ASR and LLM outputs. -
asr_attn_implementation: ASR attention implementation, options including "eager" (manual implementation of the attention), "sdpa" (attention using torch.nn.functional.scaled_dot_product_attention), or "flash_attention_2" (attention using Dao-AILab/flash-attention). By default, if available, SDPA will be used for torch>=2.1.1. The default is otherwise the manual "eager" implementation. -
llm_attn_implementation: LLM attention implementation, options including "eager" (manual implementation of the attention), "sdpa" (attention using torch.nn.functional.scaled_dot_product_attention), or "flash_attention_2" (attention using Dao-AILab/flash-attention). By default, if available, SDPA will be used for torch>=2.1.1. The default is otherwise the manual "eager" implementation. -
llm_temp: LLM temperature parameter to modulate the next token probabilities. -
transcription_cutoff: Transcription cutoff limit. This argument specified the maximum number of tokens to retain from the previous transcription. If the previous transcription exceeds this limit, it will be truncated to the specified length.
-
repetition_penalty: The penalty applied to repeated tokens during the generation process. A higher value increases the penalty, making the model less likely to repeat the same tokens. If therepetition_penaltyis greater than therepetition_penalty_threshold, the penalty is applied. -
repetition_penalty_last: Repetition penalty for the last tokens, which specifies the number of last tokens to apply the repetition penalty to. -
repetition_penalty_window: The window size for applying the repetition penalty. The penalty is applied to tokens within this window size from the current token being processed. For example, ifrepetition_penalty_windowis set to50, the penalty will be applied to tokens within the last 50 tokens from the current token. -
repetition_penalty_threshold: The threshold for applying the repetition penalty. If therepetition_penaltyis greater than this threshold, the penalty mechanism is activated. -
beam_terminated_strategy: Beam search termination strategy. The default iswhen_all_ended, which terminates beam search when all beams reaches the end. -
beam_select_strategy: Beam selection strategy, options including'best'which selects the beam with highest score, and'longest'which selects the beam with longest transcription result -
beam_max_decode_len: Maximum decode length for beam search, which specifies the maximum length of the decoded sequence during beam search. -
beam_max_len_diff: Maximum length difference for beam search, which specifies the maximum difference in length between the beams during beam search. -
beam_max_len: Maximum length for beam search, which specifies the maximum length of the beam search. A default value of-1means no limit. -
beam_min_len: Minimum length for beam search. -
logprob_min: Minimum log probability for the LLM output.
After running the model on the benchmark dataset, you can evaluate the result by calculating the Mixed Error Rates (MER) using the provided benchmarks/calculate_mer.py script. The script requireds the following arguments:
-
--dataset_name: The short version name of the benchmark dataset that you want to evalute. -
--output_dir: The output directory that stores the output from the model.
Example Usage
python benchmarks/calculate_mer.py --dataset_name ml-lecture-2021-long --output_dir result/
The table below shows the comparison of each method on multiple datasets:
| Dataset | GFD | GFD Ablation* | Whisper(5beams) |
|---|---|---|---|
| NTUML2021-long | 6.05 | 6.09 | 9.56 |
| FormosaSpeech-long | 20.37 | 22.35 | 23.78 |
| Fleurs-HK | 5.91 | 7.06 | 6.87 |
| Librispeech-Noise (S/R = 10) | 5.07 | 5.33 | 5.16 |
| Librispeech-Noise (S/R = 5) | 7.09 | 7.37 | 7.28 |
*In this setting, we set fusing_r = 0, which corresponds to running whisper with our custom beam search algorithm. Both GFD Ablation and Whisper are baselines of GFD.
| Dataset | GFD | GFD | GFD Ablation | GFD Ablation |
|---|---|---|---|---|
| ASR prompting | yes | no | yes | no |
| LLM prompting | yes | yes | NA | NA |
| ATCO-2 | - | - | 31.48 / 42.68** | - |
** The former score is computed using the results processed with Whisper EnglishTextNormalizer. The latter score is derived from transcription results that are only converted to lowercase without further normalization They correspond to the Norm and Raw column in the paper respectively.
Warning: This project uses tokenizers with custom tokenizer functions mostly to deal with byte string tokenizations, and has only been tested with the Mistral and Breeze models. Using other models may result in errors or unexpected behavior. Please ensure compatibility before using it with other models.
If you like our work, please site:
@article{hsu2024let,
title={Let's Fuse Step by Step: A Generative Fusion Decoding Algorithm with LLMs for Multi-modal Text Recognition},
author={Hsu, Chan-Jan and Chen, Yi-Chang and Liao, Feng-Ting and Ho, Pei-Chen and Wang, Yu-Hsiang and Hsu, Po-Chun and Shiu, Da-Shan},
journal={arXiv preprint arXiv:2405.14259},
year={2024}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for generative-fusion-decoding
Similar Open Source Tools
generative-fusion-decoding
Generative Fusion Decoding (GFD) is a novel shallow fusion framework that integrates Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). GFD operates across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. It simplifies the complexity of aligning different model sample spaces, allows LLMs to correct errors in tandem with the recognition model, increases robustness in long-form speech recognition, and enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. GFD significantly improves performance in ASR and OCR tasks, offering a unified solution for leveraging existing pre-trained models through step-by-step fusion.

datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.

mflux
MFLUX is a line-by-line port of the FLUX implementation in the Huggingface Diffusers library to Apple MLX. It aims to run powerful FLUX models from Black Forest Labs locally on Mac machines. The codebase is minimal and explicit, prioritizing readability over generality and performance. Models are implemented from scratch in MLX, with tokenizers from the Huggingface Transformers library. Dependencies include Numpy and Pillow for image post-processing. Installation can be done using `uv tool` or classic virtual environment setup. Command-line arguments allow for image generation with specified models, prompts, and optional parameters. Quantization options for speed and memory reduction are available. LoRA adapters can be loaded for fine-tuning image generation. Controlnet support provides more control over image generation with reference images. Current limitations include generating images one by one, lack of support for negative prompts, and some LoRA adapters not working.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.
llm-consortium
LLM Consortium is a plugin for the `llm` package that implements a model consortium system with iterative refinement and response synthesis. It orchestrates multiple learned language models to collaboratively solve complex problems through structured dialogue, evaluation, and arbitration. The tool supports multi-model orchestration, iterative refinement, advanced arbitration, database logging, configurable parameters, hundreds of models, and the ability to save and load consortium configurations.

cortex
Cortex is a tool that simplifies and accelerates the process of creating applications utilizing modern AI models like chatGPT and GPT-4. It provides a structured interface (GraphQL or REST) to a prompt execution environment, enabling complex augmented prompting and abstracting away model connection complexities like input chunking, rate limiting, output formatting, caching, and error handling. Cortex offers a solution to challenges faced when using AI models, providing a simple package for interacting with NL AI models.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.
playword
PlayWord is a tool designed to supercharge web test automation experience with AI. It provides core features such as enabling browser operations and validations using natural language inputs, as well as monitoring interface to record and dry-run test steps. PlayWord supports multiple AI services including Anthropic, Google, and OpenAI, allowing users to select the appropriate provider based on their requirements. The tool also offers features like assertion handling, frame handling, custom variables, test recordings, and an Observer module to track user interactions on web pages. With PlayWord, users can interact with web pages using natural language commands, reducing the need to worry about element locators and providing AI-powered adaptation to UI changes.

stark
STaRK is a large-scale semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. It provides natural-sounding and practical queries crafted to incorporate rich relational information and complex textual properties, closely mirroring real-life scenarios. The benchmark aims to assess how effectively large language models can handle the interplay between textual and relational requirements in queries, using three diverse knowledge bases constructed from public sources.
ice-score
ICE-Score is a tool designed to instruct large language models to evaluate code. It provides a minimum viable product (MVP) for evaluating generated code snippets using inputs such as problem, output, task, aspect, and model. Users can also evaluate with reference code and enable zero-shot chain-of-thought evaluation. The tool is built on codegen-metrics and code-bert-score repositories and includes datasets like CoNaLa and HumanEval. ICE-Score has been accepted to EACL 2024.
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.
For similar tasks
generative-fusion-decoding
Generative Fusion Decoding (GFD) is a novel shallow fusion framework that integrates Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). GFD operates across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. It simplifies the complexity of aligning different model sample spaces, allows LLMs to correct errors in tandem with the recognition model, increases robustness in long-form speech recognition, and enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. GFD significantly improves performance in ASR and OCR tasks, offering a unified solution for leveraging existing pre-trained models through step-by-step fusion.
For similar jobs
generative-fusion-decoding
Generative Fusion Decoding (GFD) is a novel shallow fusion framework that integrates Large Language Models (LLMs) into multi-modal text recognition systems such as automatic speech recognition (ASR) and optical character recognition (OCR). GFD operates across mismatched token spaces of different models by mapping text token space to byte token space, enabling seamless fusion during the decoding process. It simplifies the complexity of aligning different model sample spaces, allows LLMs to correct errors in tandem with the recognition model, increases robustness in long-form speech recognition, and enables fusing recognition models deficient in Chinese text recognition with LLMs extensively trained on Chinese. GFD significantly improves performance in ASR and OCR tasks, offering a unified solution for leveraging existing pre-trained models through step-by-step fusion.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.