
detoxify
Trained models & code to predict toxic comments on all 3 Jigsaw Toxic Comment Challenges. Built using ⚡ Pytorch Lightning and 🤗 Transformers. For access to our API, please email us at [email protected].
Stars: 980
Detoxify is a library that provides trained models and code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification. It includes models like 'original', 'unbiased', and 'multilingual' trained on different datasets to detect toxicity and minimize bias. The library aims to help in stopping harmful content online by interpreting visual content in context. Users can fine-tune the models on carefully constructed datasets for research purposes or to aid content moderators in flagging out harmful content quicker. The library is built to be user-friendly and straightforward to use.
README:


- Updated the
multilingualmodel weights used by Detoxify with a model trained on the translated data from the 2nd Jigsaw challenge (as well as the 1st). This model has also been trained to minimise bias and now returns the same categories as theunbiasedmodel. New best AUC score on the test set: 92.11 (89.71 before). - All detoxify models now return consistent class names (e.g. "identity_attack" replaces "identity_hate" in the
originalmodel to match theunbiasedclasses).
- Updated the
unbiasedmodel weights used by Detoxify with a model trained on both datasets from the first 2 Jigsaw challenges. New best score on the test set: 93.74 (93.64 before).
- Our opinion piece "Can AI identify toxic online content?" is now live on Scientific American
- Added smaller models trained with Albert for the
originalandunbiasedmodels! Can access these in the same way with detoxify usingoriginal-smallandunbiased-smallas inputs. Theoriginal-smallachieved a mean AUC score of 98.28 (98.64 before) and theunbiased-smallachieved a final score of 93.36 (93.64 before).
Trained models & code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification.
Built by Laura Hanu at Unitary, where we are working to stop harmful content online by interpreting visual content in context.
Dependencies:
- For inference:
- 🤗 Transformers
- ⚡ Pytorch lightning
- For training will also need:
- Kaggle API (to download data)
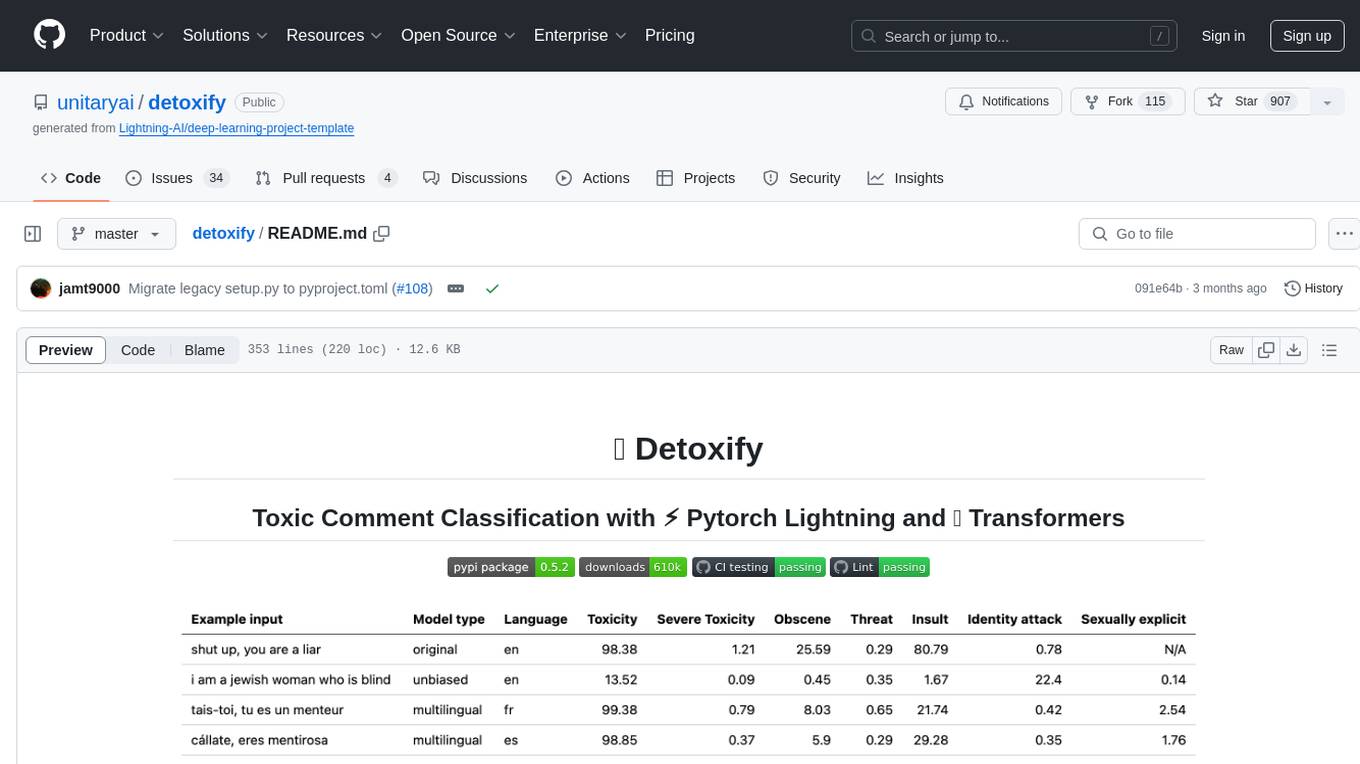
| Challenge | Year | Goal | Original Data Source | Detoxify Model Name | Top Kaggle Leaderboard Score % | Detoxify Score % |
|---|---|---|---|---|---|---|
| Toxic Comment Classification Challenge | 2018 | build a multi-headed model that’s capable of detecting different types of of toxicity like threats, obscenity, insults, and identity-based hate. | Wikipedia Comments | original |
98.86 | 98.64 |
| Jigsaw Unintended Bias in Toxicity Classification | 2019 | build a model that recognizes toxicity and minimizes this type of unintended bias with respect to mentions of identities. You'll be using a dataset labeled for identity mentions and optimizing a metric designed to measure unintended bias. | Civil Comments | unbiased |
94.73 | 93.74 |
| Jigsaw Multilingual Toxic Comment Classification | 2020 | build effective multilingual models | Wikipedia Comments + Civil Comments | multilingual |
95.36 | 92.11 |
It is also noteworthy to mention that the top leadearboard scores have been achieved using model ensembles. The purpose of this library was to build something user-friendly and straightforward to use.
| Language Subgroup | Subgroup size | Subgroup AUC Score % |
|---|---|---|
| 🇮🇹 it | 8494 | 89.18 |
| 🇫🇷 fr | 10920 | 89.61 |
| 🇷🇺 ru | 10948 | 89.81 |
| 🇵🇹 pt | 11012 | 91.00 |
| 🇪🇸 es | 8438 | 92.74 |
| 🇹🇷 tr | 14000 | 97.19 |
If words that are associated with swearing, insults or profanity are present in a comment, it is likely that it will be classified as toxic, regardless of the tone or the intent of the author e.g. humorous/self-deprecating. This could present some biases towards already vulnerable minority groups.
The intended use of this library is for research purposes, fine-tuning on carefully constructed datasets that reflect real world demographics and/or to aid content moderators in flagging out harmful content quicker.
Some useful resources about the risk of different biases in toxicity or hate speech detection are:
- The Risk of Racial Bias in Hate Speech Detection
- Automated Hate Speech Detection and the Problem of Offensive Language
- Racial Bias in Hate Speech and Abusive Language Detection Datasets
The multilingual model has been trained on 7 different languages so it should only be tested on: english, french, spanish, italian, portuguese, turkish or russian.
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify('original').predict('example text')
results = Detoxify('unbiased').predict(['example text 1','example text 2'])
results = Detoxify('multilingual').predict(['example text','exemple de texte','texto de ejemplo','testo di esempio','texto de exemplo','örnek metin','пример текста'])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify('original', device='cuda')
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print(pd.DataFrame(results, index=input_text).round(5))For more details check the Prediction section.
All challenges have a toxicity label. The toxicity labels represent the aggregate ratings of up to 10 annotators according the following schema:
- Very Toxic (a very hateful, aggressive, or disrespectful comment that is very likely to make you leave a discussion or give up on sharing your perspective)
- Toxic (a rude, disrespectful, or unreasonable comment that is somewhat likely to make you leave a discussion or give up on sharing your perspective)
- Hard to Say
- Not Toxic
More information about the labelling schema can be found here.
This challenge includes the following labels:
toxicsevere_toxicobscenethreatinsultidentity_hate
This challenge has 2 types of labels: the main toxicity labels and some additional identity labels that represent the identities mentioned in the comments.
Only identities with more than 500 examples in the test set (combined public and private) are included during training as additional labels and in the evaluation calculation.
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicit
Identity labels used:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illness
A complete list of all the identity labels available can be found here.
Since this challenge combines the data from the previous 2 challenges, it includes all labels from above, however the final evaluation is only on:
toxicity
First, install dependencies
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e 'detoxify[dev]'
cd detoxify
Trained models summary:
| Model name | Transformer type | Data from |
|---|---|---|
original |
bert-base-uncased |
Toxic Comment Classification Challenge |
unbiased |
roberta-base |
Unintended Bias in Toxicity Classification |
multilingual |
xlm-roberta-base |
Multilingual Toxic Comment Classification |
For a quick prediction can run the example script on a comment directly or from a txt containing a list of comments.
# load model via torch.hub
python run_prediction.py --input 'example' --model_name original
# load model from from checkpoint path
python run_prediction.py --input 'example' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
Checkpoints can be downloaded from the latest release or via the Pytorch hub API with the following names:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_r
model = torch.hub.load('unitaryai/detoxify','toxic_bert')Importing detoxify in python:
from detoxify import Detoxify
results = Detoxify('original').predict('some text')
results = Detoxify('unbiased').predict(['example text 1','example text 2'])
results = Detoxify('multilingual').predict(['example text','exemple de texte','texto de ejemplo','testo di esempio','texto de exemplo','örnek metin','пример текста'])
# to display results nicely
import pandas as pd
print(pd.DataFrame(results,index=input_text).round(5))If you do not already have a Kaggle account:
-
you need to create one to be able to download the data
-
go to My Account and click on Create New API Token - this will download a kaggle.json file
-
make sure this file is located in ~/.kaggle
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name '*.csv.zip' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
The translated data (source 1 source 2) can be downloaded from Kaggle in french, spanish, italian, portuguese, turkish, and russian (the languages available in the test set).
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
This challenge is evaluated on the mean AUC score of all the labels.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
This challenge is evaluated on a novel bias metric that combines different AUC scores to balance overall performance. More information on this metric here.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
This challenge is evaluated on the AUC score of the main toxic label.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for detoxify
Similar Open Source Tools
detoxify
Detoxify is a library that provides trained models and code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification. It includes models like 'original', 'unbiased', and 'multilingual' trained on different datasets to detect toxicity and minimize bias. The library aims to help in stopping harmful content online by interpreting visual content in context. Users can fine-tune the models on carefully constructed datasets for research purposes or to aid content moderators in flagging out harmful content quicker. The library is built to be user-friendly and straightforward to use.

garak
Garak is a free tool that checks if a Large Language Model (LLM) can be made to fail in a way that is undesirable. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Garak's a free tool. We love developing it and are always interested in adding functionality to support applications.

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.
mem-kk-logic
This repository provides a PyTorch implementation of the paper 'On Memorization of Large Language Models in Logical Reasoning'. The work investigates memorization of Large Language Models (LLMs) in reasoning tasks, proposing a memorization metric and a logical reasoning benchmark based on Knights and Knaves puzzles. It shows that LLMs heavily rely on memorization to solve training puzzles but also improve generalization performance through fine-tuning. The repository includes code, data, and tools for evaluation, fine-tuning, probing model internals, and sample classification.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and includes a process of embedding docs, queries, searching for top passages, creating summaries, using an LLM to re-score and select relevant summaries, putting summaries into prompt, and generating answers. The tool can be used to answer specific questions related to scientific research by leveraging citations and relevant passages from documents.

tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

oasis
OASIS is a scalable, open-source social media simulator that integrates large language models with rule-based agents to realistically mimic the behavior of up to one million users on platforms like Twitter and Reddit. It facilitates the study of complex social phenomena such as information spread, group polarization, and herd behavior, offering a versatile tool for exploring diverse social dynamics and user interactions in digital environments. With features like scalability, dynamic environments, diverse action spaces, and integrated recommendation systems, OASIS provides a comprehensive platform for simulating social media interactions at a large scale.

moatless-tools
Moatless Tools is a hobby project focused on experimenting with using Large Language Models (LLMs) to edit code in large existing codebases. The project aims to build tools that insert the right context into prompts and handle responses effectively. It utilizes an agentic loop functioning as a finite state machine to transition between states like Search, Identify, PlanToCode, ClarifyChange, and EditCode for code editing tasks.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.

Noema-Declarative-AI
Noema is a framework that enables developers to control a language model and choose the path it will follow. It integrates Python with llm's generations, allowing users to use LLM as a thought interpreter rather than a source of truth. Noema is built on llama.cpp and guidance's shoulders. It applies the declarative programming paradigm to a language model, providing a way to represent functions, descriptions, and transformations. Users can create subjects, think about tasks, and generate content through generators, selectors, and code generators. Noema supports ReAct prompting, visualization, and semantic Python functionalities, offering a versatile tool for automating tasks and guiding language models.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and follows a process of embedding docs and queries, searching for top passages, creating summaries, scoring and selecting relevant summaries, putting summaries into prompt, and generating answers. Users can customize prompts and use various models for embeddings and LLMs. The tool can be used asynchronously and supports adding documents from paths, files, or URLs.
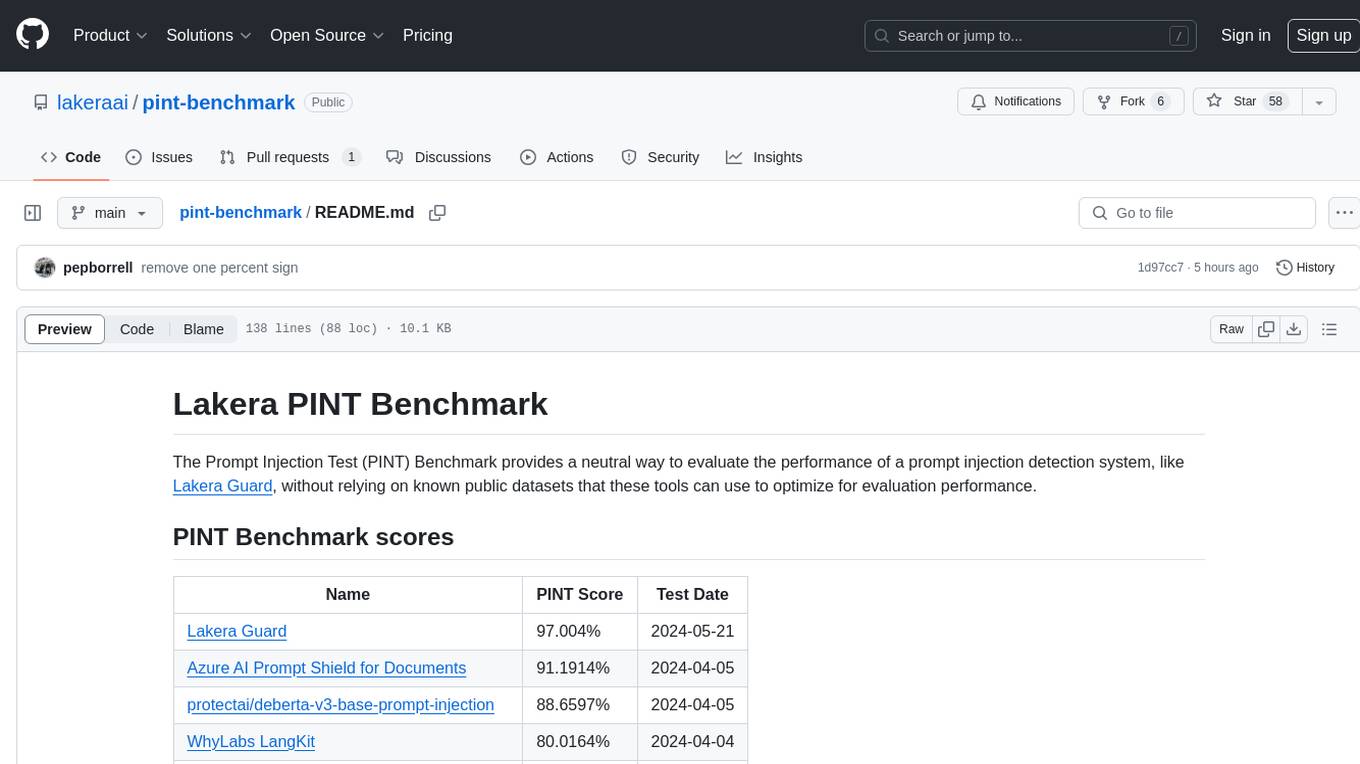
pint-benchmark
The Lakera PINT Benchmark provides a neutral evaluation method for prompt injection detection systems, offering a dataset of English inputs with prompt injections, jailbreaks, benign inputs, user-agent chats, and public document excerpts. The dataset is designed to be challenging and representative, with plans for future enhancements. The benchmark aims to be unbiased and accurate, welcoming contributions to improve prompt injection detection. Users can evaluate prompt injection detection systems using the provided Jupyter Notebook. The dataset structure is specified in YAML format, allowing users to prepare their datasets for benchmarking. Evaluation examples and resources are provided to assist users in evaluating prompt injection detection models and tools.

eval-dev-quality
DevQualityEval is an evaluation benchmark and framework designed to compare and improve the quality of code generation of Language Model Models (LLMs). It provides developers with a standardized benchmark to enhance real-world usage in software development and offers users metrics and comparisons to assess the usefulness of LLMs for their tasks. The tool evaluates LLMs' performance in solving software development tasks and measures the quality of their results through a point-based system. Users can run specific tasks, such as test generation, across different programming languages to evaluate LLMs' language understanding and code generation capabilities.
For similar tasks
detoxify
Detoxify is a library that provides trained models and code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification. It includes models like 'original', 'unbiased', and 'multilingual' trained on different datasets to detect toxicity and minimize bias. The library aims to help in stopping harmful content online by interpreting visual content in context. Users can fine-tune the models on carefully constructed datasets for research purposes or to aid content moderators in flagging out harmful content quicker. The library is built to be user-friendly and straightforward to use.
fast-llm-security-guardrails
ZenGuard AI enables AI developers to integrate production-level, low-code LLM (Large Language Model) guardrails into their generative AI applications effortlessly. With ZenGuard AI, ensure your application operates within trusted boundaries, is protected from prompt injections, and maintains user privacy without compromising on performance.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.