
TriForce
[COLM 2024] TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
Stars: 188
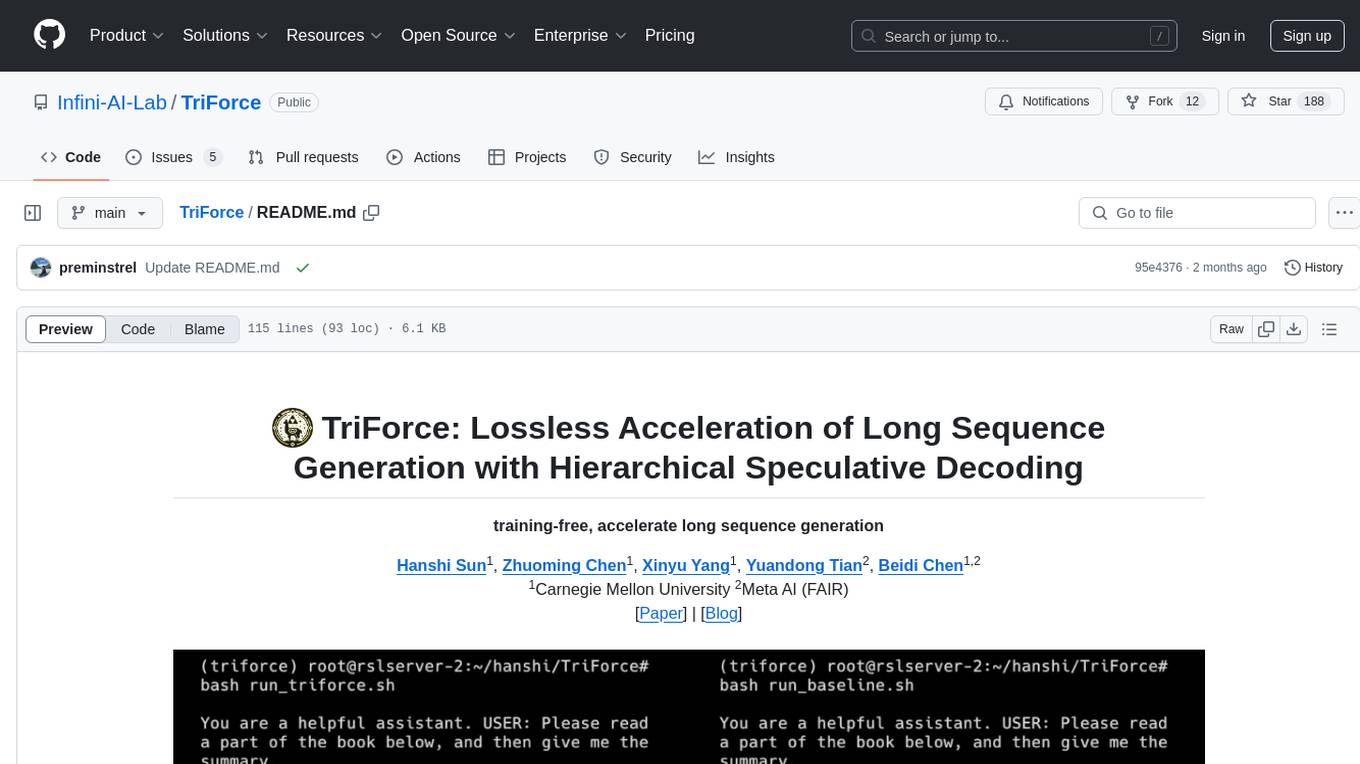
TriForce is a training-free tool designed to accelerate long sequence generation. It supports long-context Llama models and offers both on-chip and offloading capabilities. Users can achieve a 2.2x speedup on a single A100 GPU. TriForce also provides options for offloading with tensor parallelism or without it, catering to different hardware configurations. The tool includes a baseline for comparison and is optimized for performance on RTX 4090 GPUs. Users can cite the associated paper if they find TriForce useful for their projects.
README:

training-free, accelerate long sequence generation
 serving LWM-Text-Chat-128K with offloading on 2x RTX 4090s (prefill 127K contexts)
serving LWM-Text-Chat-128K with offloading on 2x RTX 4090s (prefill 127K contexts)
 TriForce Framework
TriForce Framework
conda create -n TriForce python=3.9
conda activate TriForce
pip install -r requirements.txt
pip install flash-attn --no-build-isolation # install flash-attnCurrently, only long-context Llama models are supported (including Llama2-7B-128K, Llama2-13B-128K, LWM-Text-128K, LWM-Text-Chat-128K).
On-chip results can be reproduced on an A100 by running the following command. --prefill specifies the context length of the prompt, and --budget specifies the budget of the retrieval cache. chunk_size specifies the chunk size of the KV cache. top_p and temp are the sampling hyperparameters, which are set to 0.9 and 0.6 by default. gamma is the number of speculative decoding steps. You should observe a 2.2x speedup by running the following command on a single A100. gs contains 20 samples from PG-19, 128k contains 128K samples, and lwm contains samples from NarrativeQA.
# TriForce, on A100
CUDA_VISIBLE_DEVICES=0 python test/on_chip.py --prefill 124928 --budget 4096 \
--chunk_size 8 --top_p 0.9 --temp 0.6 --gamma 6Our framework supports tensor parallelism for offloading settings. The --nproc_per_node should be set to the number of GPUs used for offloading. The following command demonstrates how to use tensor parallelism with 2 GPUs. It should be noted that RTX 4090s do not support CUDA Graph for tensor parallelism (while A100 does). Therefore, we disabled CUDA Graph for this setting. --on_chip specifies the number of layers' KV cache that are on-chip, which can be adjusted based on hardware. The performance of offloading significantly depends on the bandwidth of PCIE. In order to get accurate results, it is best to ensure that the bandwidth is not used by other programs.
# TriForce, on 2x RTX 4090 GPUs
CUDA_VISIBLE_DEVICES=0,1 OMP_NUM_THREADS=48 torchrun --nproc_per_node=2 \
test/offloading_TP.py --budget 12288 --prefill 130048 --dataset gs \
--target llama-7B-128K --on_chip 9 --gamma 16We recommend using 2x RTX 4090s for offloading since the encoding time is much shorter and the generation latency is lower. But if you only have 1x RTX 4090, you can still run the following command. Since the budget is smaller, the average accepted token length is shorter.
# TriForce, CUDA Graph
# Huggingface backend, and cuda graph may take some extra HBM
CUDA_VISIBLE_DEVICES=0 python test/offloading.py --prefill 130048 \
--chunk_size 8 --temp 0.6 --top_p 0.9 --gamma 12 --dataset gs \
--budget 8192 --target llama-7B-128K
# TriForce, overlapping computation and loading
# overlapping may take some extra HBM
CUDA_VISIBLE_DEVICES=0,1 OMP_NUM_THREADS=48 torchrun --nproc_per_node=1 \
test/offloading_TP.py --budget 8192 --prefill 130048 --dataset gs \
--target llama-7B-128K --on_chip 0 --gamma 12For offloading, we provide an implementation of the auto-regressive baseline for comparison purposes. If the performance of TriForce does not meet expectations, which may be due to low PCIE bandwidth, we advise evaluating the baseline's performance on identical hardware. To demonstrate how to execute the baseline with different hardware configurations, here are the commands for running it on two RTX 4090 GPUs and separately on a single RTX 4090 GPU.
# baseline, 2x RTX 4090s
CUDA_VISIBLE_DEVICES=0,1 OMP_NUM_THREADS=48 torchrun --nproc_per_node=2 \
test/offloading_TP.py --budget 0 --prefill 130048 --dataset demo \
--target lwm-128K --on_chip 12 --baseline
# baseline, 1x RTX 4090
CUDA_VISIBLE_DEVICES=0,1 OMP_NUM_THREADS=48 torchrun --nproc_per_node=1 \
test/offloading_TP.py --budget 0 --prefill 130048 --dataset demo \
--target lwm-128K --on_chip 2 --baselineIf you find TriForce useful or relevant to your project and research, please kindly cite our paper:
@article{sun2024triforce,
title={Triforce: Lossless acceleration of long sequence generation with hierarchical speculative decoding},
author={Sun, Hanshi and Chen, Zhuoming and Yang, Xinyu and Tian, Yuandong and Chen, Beidi},
journal={arXiv preprint arXiv:2404.11912},
year={2024}
}-
Environment Issues
Ensure you are using
transformers==4.37.2because theapply_rotary_pos_embAPI has changed in more recent versions of transformers. Additionally, some environment issues (e.g., incompatibility with the latest flash-attn) can be resolved by settingtorch==2.2.1+cu121andflash_attn==2.5.7. For more details, please refer to issue #7.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for TriForce
Similar Open Source Tools
TriForce
TriForce is a training-free tool designed to accelerate long sequence generation. It supports long-context Llama models and offers both on-chip and offloading capabilities. Users can achieve a 2.2x speedup on a single A100 GPU. TriForce also provides options for offloading with tensor parallelism or without it, catering to different hardware configurations. The tool includes a baseline for comparison and is optimized for performance on RTX 4090 GPUs. Users can cite the associated paper if they find TriForce useful for their projects.
mirage
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.

llm-analysis
llm-analysis is a tool designed for Latency and Memory Analysis of Transformer Models for Training and Inference. It automates the calculation of training or inference latency and memory usage for Large Language Models (LLMs) or Transformers based on specified model, GPU, data type, and parallelism configurations. The tool helps users to experiment with different setups theoretically, understand system performance, and optimize training/inference scenarios. It supports various parallelism schemes, communication methods, activation recomputation options, data types, and fine-tuning strategies. Users can integrate llm-analysis in their code using the `LLMAnalysis` class or use the provided entry point functions for command line interface. The tool provides lower-bound estimations of memory usage and latency, and aims to assist in achieving feasible and optimal setups for training or inference.
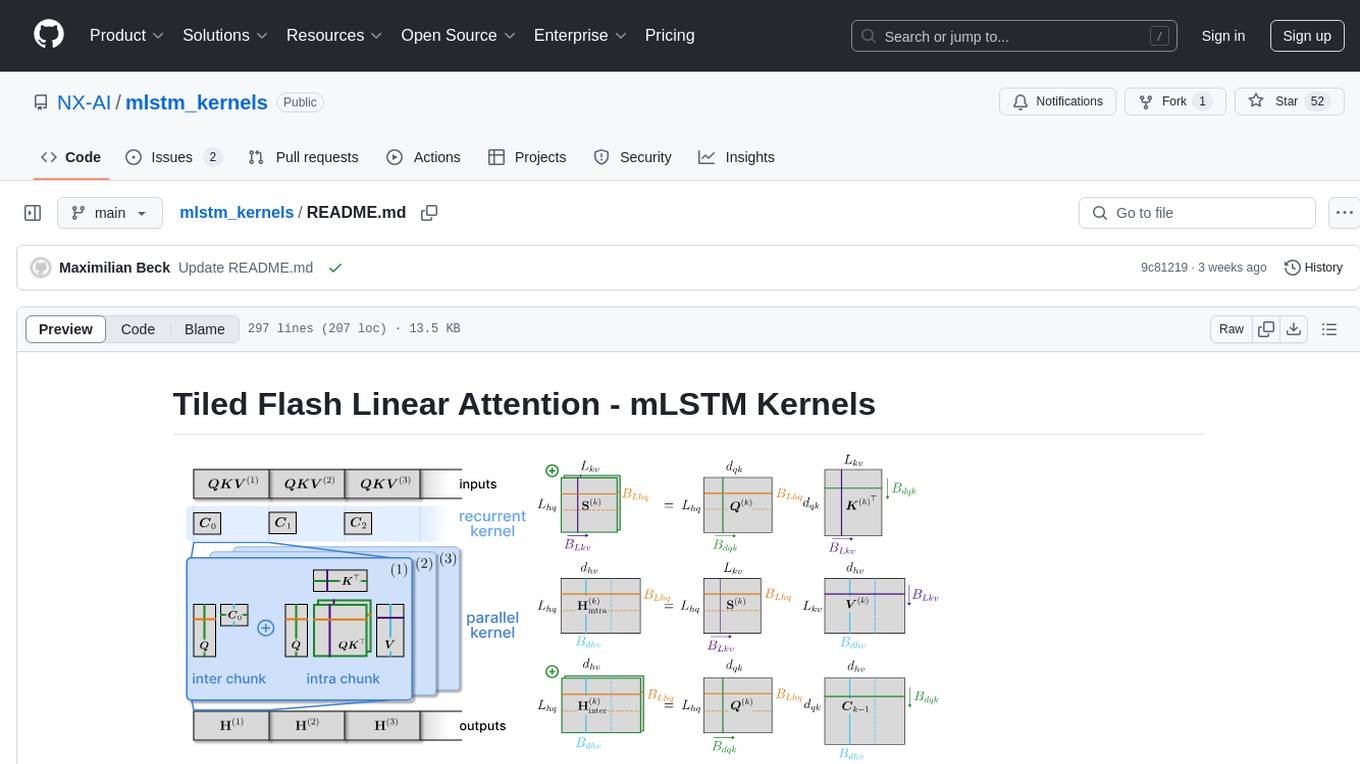
mlstm_kernels
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.
kvpress
This repository implements multiple key-value cache pruning methods and benchmarks using transformers, aiming to simplify the development of new methods for researchers and developers in the field of long-context language models. It provides a set of 'presses' that compress the cache during the pre-filling phase, with each press having a compression ratio attribute. The repository includes various training-free presses, special presses, and supports KV cache quantization. Users can contribute new presses and evaluate the performance of different presses on long-context datasets.

rtdl-num-embeddings
This repository provides the official implementation of the paper 'On Embeddings for Numerical Features in Tabular Deep Learning'. It focuses on transforming scalar continuous features into vectors before integrating them into the main backbone of tabular neural networks, showcasing improved performance. The embeddings for continuous features are shown to enhance the performance of tabular DL models and are applicable to various conventional backbones, offering efficiency comparable to Transformer-based models. The repository includes Python packages for practical usage, exploration of metrics and hyperparameters, and reproducing reported results for different algorithms and datasets.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.

datadreamer
DataDreamer is an advanced toolkit designed to facilitate the development of edge AI models by enabling synthetic data generation, knowledge extraction from pre-trained models, and creation of efficient and potent models. It eliminates the need for extensive datasets by generating synthetic datasets, leverages latent knowledge from pre-trained models, and focuses on creating compact models suitable for integration into any device and performance for specialized tasks. The toolkit offers features like prompt generation, image generation, dataset annotation, and tools for training small-scale neural networks for edge deployment. It provides hardware requirements, usage instructions, available models, and limitations to consider while using the library.
For similar tasks
TriForce
TriForce is a training-free tool designed to accelerate long sequence generation. It supports long-context Llama models and offers both on-chip and offloading capabilities. Users can achieve a 2.2x speedup on a single A100 GPU. TriForce also provides options for offloading with tensor parallelism or without it, catering to different hardware configurations. The tool includes a baseline for comparison and is optimized for performance on RTX 4090 GPUs. Users can cite the associated paper if they find TriForce useful for their projects.
hume-python-sdk
The Hume AI Python SDK allows users to integrate Hume APIs directly into their Python applications. Users can access complete documentation, quickstart guides, and example notebooks to get started. The SDK is designed to provide support for Hume's expressive communication platform built on scientific research. Users are encouraged to create an account at beta.hume.ai and stay updated on changes through Discord. The SDK may undergo breaking changes to improve tooling and ensure reliable releases in the future.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.
mimir
MIMIR is a Python package designed for measuring memorization in Large Language Models (LLMs). It provides functionalities for conducting experiments related to membership inference attacks on LLMs. The package includes implementations of various attacks such as Likelihood, Reference-based, Zlib Entropy, Neighborhood, Min-K% Prob, Min-K%++, Gradient Norm, and allows users to extend it by adding their own datasets and attacks.
agentdojo
AgentDojo is a dynamic environment designed to evaluate prompt injection attacks and defenses for large language models (LLM) agents. It provides a benchmark script to run different suites and tasks with specified LLM models, defenses, and attacks. The tool is under active development, and users can inspect the results through dedicated documentation pages and the Invariant Benchmark Registry.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.