
mirage
Mirage Persistent Kernel: Compiling LLMs into a MegaKernel
Stars: 2141
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.
README:
| Join Slack | Roadmap | Blog Post |
Latest News 🔥
- [2025/06] We released Mirage Persistent Kernel (MPK), a compiler and runtime that automatically transforms multi-GPU LLM inference into a high-performance megakernel.
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.
The fastest way to try MPK is to install it directly from source:
git clone --recursive --branch mpk https://www.github.com/mirage-project/mirage
cd mirage
pip install -e . -v
export MIRAGE_HOME=$(pwd)
🔧[2025/06/19] We are working on pre-built binary wheels for MPK and will update the installation instructions once they are available.
Mirage allows you to compile LLMs from the Hugging Face model zoo into a megakernel using just a few dozen lines of Python—mainly to define the kernel’s inputs and outputs. See this demo script that compiles the Qwen3-8B model into a megakernel.
We start by running the demo with native Triton and FlashInfer kernels:
python demo/qwen3/demo.py
To compile and execute the megakernel using MPK:
python demo/qwen3/demo.py --use-mirage
To enable profiling (which visualizes the execution timeline of each task):
python demo/qwen3/demo.py --use-mirage --profiling
Once you've imported the Mirage package, you can instantiate a persistent kernel using the following API:
import mirage as mi
mpk = mi.PersistentKernel(
world_size=world_size,
mpi_rank=rank,
num_workers=96,
num_local_schedulers=48,
num_remote_schedulers=0,
meta_tensors=[step, tokens],
profiler_tensor=profiler_tensor,
)
-
world_sizeandmpi_rank: number of GPUs and current GPU rank. -
num_workers,num_local_schedulers,num_remote_schedulers: the number of workers, local schedulers, and remote schedulers. They must match the number of physical SMs (num_workers+ (num_local_schedulers+num_remote_schedulers) / 4). - The megakernel currently requires two meta tensors:
stepis an array of integer tracking the current decoding step, and is incremented by MPK after each decoding iteration;tokensis a tensor of shape [num_requests,seq_length] storing prompts and MPK generated tokens.
To attach an existing PyTorch.Tensor:
x = mpk.attach_input(torch_tensor=torch_tensor, name="torch_tensor_name")
-
nameis used by MPK to refer to the tensor in the generated megakernel in CUDA.
To allocate a new tensor:
y = mpk.new_tensor(
dims=(batch_size, hidden_size),
dtype=mi.bfloat16,
name="embed_out",
io_category="cuda_tensor",
)
-
dimsanddtypespecify the dimensions and data type of the tensor. -
nameis used by MPK to refer to this new tensor in the megakernel. -
io_categoryindicates how the tensor is allocated and must becuda_tensorornvshmem_tensor(the latter is required for remote GPU access, e.g., during all-reduce).
You can compose the LLM’s computation graph by chaining fused operations. For example: rmsnorm_linear_layer fuses an RMSNorm layer and a Linear layer in the megakernel.
mpk.rmsnorm_linear_layer(
input=x,
weight_norm=w_norm,
weight_linear=w_qkv,
output=attn_in,
grid_dim=(96, 1, 1),
block_dim=(128, 1, 1),
)
-
weight_normandweight_linearare the weight tensors for RMSNorm and Linear. -
inputandoutputare the input and output tensors of this fused layer. -
grid_dimandblock_dimspecifies the number of thread blocks (i.e., number of tasks in the task graph) and number of thread within each thread block. To minimize latency, it is suggested that the total number of thread blocks is a multiplier of the number of workers to avoid outliers.
Once the computation graph is defined, compile it with:
mpk.compile()
Then, run the optimized megakernel as:
mpk()
We welcome feedback, contributions, and collaborations from the community! Please join our Slack channel.
Please let us know if you encounter any bugs or have any suggestions by submitting an issue.
A paper describing Mirage's techniques is available on arxiv. Please cite Mirage as:
@inproceedings {wu2024mirage,
title={Mirage: A Multi-Level Superoptimizer for Tensor Programs},
author={Mengdi Wu and Xinhao Cheng and Shengyu Liu and Chunan Shi and Jianan Ji and Kit Ao and Praveen Velliengiri and Xupeng Miao and Oded Padon and Zhihao Jia},
booktitle = {19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25)},
year = {2025},
address = {Boston, MA},
publisher = {USENIX Association},
month = jul
}
@misc{cheng2025mpk,
title={Mirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs},
author={Xinhao Cheng and Zhihao Zhang and Yu Zhou and Jianan Ji and Jinchen Jiang and Zepeng Zhao and Ziruo Xiao and Zihao Ye and Yingyi Huang and Ruihang Lai and Hongyi Jin and Bohan Hou and Mengdi Wu and Yixin Dong and Anthony Yip and Zihao Ye and Songting Wang and Wenqin Yang and Xupeng Miao and Tianqi Chen and Zhihao Jia},
year={2025},
eprint={2512.22219},
archivePrefix={arXiv},
primaryClass={cs.DC},
url={https://arxiv.org/abs/2512.22219},
}
- Mirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs. Arxiv 2025. [arXiv]
- Mirage: A Multi-Level Superoptimizer for Tensor Programs. OSDI 2025. [PDF]
- Identity Testing for Circuits with Exponentiation Gates. ITCS 2026 [arXiv]
Mirage uses Apache License 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mirage
Similar Open Source Tools
mirage
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.
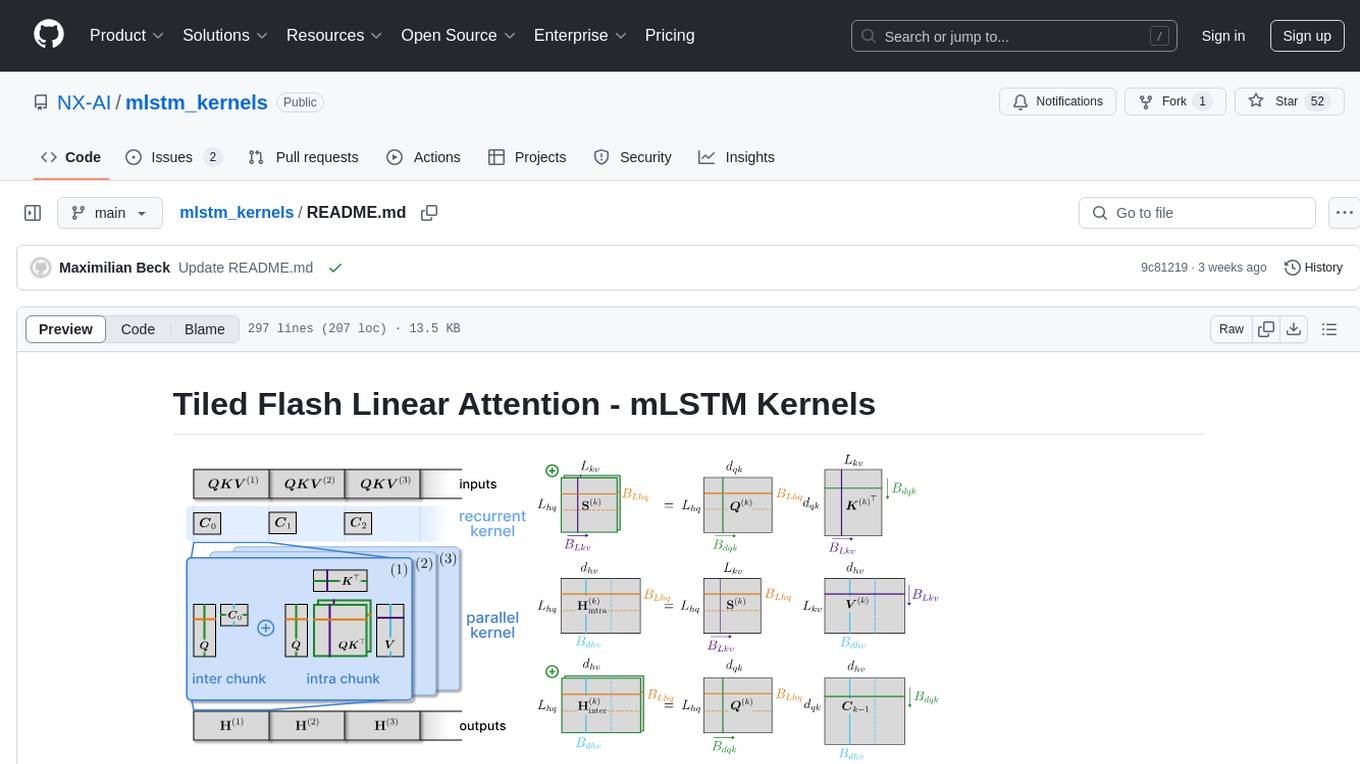
mlstm_kernels
This repository provides fast and efficient mLSTM training and inference Triton kernels built on Tiled Flash Linear Attention (TFLA). It includes implementations in JAX, PyTorch, and Triton, with chunkwise, parallel, and recurrent kernels for mLSTM. The repository also contains a benchmark library for runtime benchmarks and full mLSTM Huggingface models.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.
TriForce
TriForce is a training-free tool designed to accelerate long sequence generation. It supports long-context Llama models and offers both on-chip and offloading capabilities. Users can achieve a 2.2x speedup on a single A100 GPU. TriForce also provides options for offloading with tensor parallelism or without it, catering to different hardware configurations. The tool includes a baseline for comparison and is optimized for performance on RTX 4090 GPUs. Users can cite the associated paper if they find TriForce useful for their projects.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

stark
STaRK is a large-scale semi-structure retrieval benchmark on Textual and Relational Knowledge Bases. It provides natural-sounding and practical queries crafted to incorporate rich relational information and complex textual properties, closely mirroring real-life scenarios. The benchmark aims to assess how effectively large language models can handle the interplay between textual and relational requirements in queries, using three diverse knowledge bases constructed from public sources.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.
AgentKit
AgentKit is a framework for constructing complex human thought processes from simple natural language prompts. It offers a unified way to represent and execute these processes as graphs, making it easy to design and tune agents without any programming experience. AgentKit can be used for a variety of tasks, including generating text, answering questions, and making decisions.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
raft
RAFT (Reusable Accelerated Functions and Tools) is a C++ header-only template library with an optional shared library that contains fundamental widely-used algorithms and primitives for machine learning and information retrieval. The algorithms are CUDA-accelerated and form building blocks for more easily writing high performance applications.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.
ice-score
ICE-Score is a tool designed to instruct large language models to evaluate code. It provides a minimum viable product (MVP) for evaluating generated code snippets using inputs such as problem, output, task, aspect, and model. Users can also evaluate with reference code and enable zero-shot chain-of-thought evaluation. The tool is built on codegen-metrics and code-bert-score repositories and includes datasets like CoNaLa and HumanEval. ICE-Score has been accepted to EACL 2024.

rtdl-num-embeddings
This repository provides the official implementation of the paper 'On Embeddings for Numerical Features in Tabular Deep Learning'. It focuses on transforming scalar continuous features into vectors before integrating them into the main backbone of tabular neural networks, showcasing improved performance. The embeddings for continuous features are shown to enhance the performance of tabular DL models and are applicable to various conventional backbones, offering efficiency comparable to Transformer-based models. The repository includes Python packages for practical usage, exploration of metrics and hyperparameters, and reproducing reported results for different algorithms and datasets.
Numpy.NET
Numpy.NET is the most complete .NET binding for NumPy, empowering .NET developers with extensive functionality for scientific computing, machine learning, and AI. It provides multi-dimensional arrays, matrices, linear algebra, FFT, and more via a strong typed API. Numpy.NET does not require a local Python installation, as it uses Python.Included to package embedded Python 3.7. Multi-threading must be handled carefully to avoid deadlocks or access violation exceptions. Performance considerations include overhead when calling NumPy from C# and the efficiency of data transfer between C# and Python. Numpy.NET aims to match the completeness of the original NumPy library and is generated using CodeMinion by parsing the NumPy documentation. The project is MIT licensed and supported by JetBrains.
For similar tasks
mirage
Mirage Persistent Kernel (MPK) is a compiler and runtime system that automatically transforms LLM inference into a single megakernel—a fused GPU kernel that performs all necessary computation and communication within a single kernel launch. This end-to-end GPU fusion approach reduces LLM inference latency by 1.2× to 6.7×, all while requiring minimal developer effort.

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.
zml
ZML is a high-performance AI inference stack built for production, using Zig language, MLIR, and Bazel. It allows users to create exciting AI projects, run pre-packaged models like MNIST, TinyLlama, OpenLLama, and Meta Llama, and compile models for accelerator runtimes. Users can also run tests, explore examples, and contribute to the project. ZML is licensed under the Apache 2.0 license.
edgeai
Embedded inference of Deep Learning models is quite challenging due to high compute requirements. TI’s Edge AI software product helps optimize and accelerate inference on TI’s embedded devices. It supports heterogeneous execution of DNNs across cortex-A based MPUs, TI’s latest generation C7x DSP, and DNN accelerator (MMA). The solution simplifies the product life cycle of DNN development and deployment by providing a rich set of tools and optimized libraries.
sdnext
SD.Next is an Image Diffusion implementation with advanced features. It offers multiple UI options, diffusion models, and built-in controls for text, image, batch, and video processing. The tool is multiplatform, supporting Windows, Linux, MacOS, nVidia, AMD, IntelArc/IPEX, DirectML, OpenVINO, ONNX+Olive, and ZLUDA. It provides optimized processing with the latest torch developments, including model compile, quantize, and compress functionalities. SD.Next also features Interrogate/Captioning with various models, queue management, automatic updates, and mobile compatibility.

tt-xla
TT-XLA is a repository that enables running PyTorch and JAX models on Tenstorrent's AI hardware. It serves as a backend integration between the JAX ecosystem and Tenstorrent's ML accelerators using the PJRT (Portable JAX Runtime) interface. It supports ingestion of PyTorch models through PyTorch/XLA and JAX models via jit compile, providing a StableHLO (SHLO) graph to TT-MLIR compiler.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.