
pywhyllm
Experimental library integrating LLM capabilities to support causal analyses
Stars: 121
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments causal inference by suggesting potential confounders, relationships between variables, backdoor/frontdoor/iv sets, estimands, critiques of DAGs, latent confounders, and negative controls. The tool aims to enhance the causal analysis process by leveraging the capabilities of LLMs.
README:
PyWhy-LLM is an innovative library designed to augment human expertise by seamlessly integrating Large Language Models (LLMs) into the causal analysis process. It empowers users with access to knowledge previously only available through domain experts. As part of the DoWhy community, we aim to investigate and harness the capabilities of LLMs for enhancing causal analysis process.
For detailed usage instructions and tutorials, refer to Notebook.
To install PyWhy-LLM, you can use pip:
pip install pywhyllmPyWhy-LLM seamlessly integrates into your existing causal inference process. Import the necessary classes and start exploring the power of LLM-augmented causal analysis.
from pywhyllm import ModelSuggester, IdentificationSuggester, ValidationSuggester# Create instance of Modeler
modeler = Modeler()
# Suggest a set of potential confounders
suggested_confounders = modeler.suggest_confounders(variables=_variables, treatment=treatment, outcome=outcome, llm=gpt4)
# Suggest pair-wise relationship between variables
suggested_dag = modeler.suggest_relationships(variables=selected_variables, llm=gpt4)
plt.figure(figsize=(10, 5))
nx.draw(suggested_dag, with_labels=True, node_color='lightblue')
plt.show()# Create instance of Identifier
identifier = Identifier()
# Suggest a backdoor set, front door set, and iv set
suggested_backdoor = identifier.suggest_backdoor(llm=gpt4, treatment=treatment, outcome=outcome, confounders=suggested_confounders)
suggested_frontdoor = identifier.suggest_frontdoor(llm=gpt4, treatment=treatment, outcome=outcome, confounders=suggested_confounders)
suggested_iv = identifier.suggest_iv(llm=gpt4, treatment=treatment, outcome=outcome, confounders=suggested_confounders)
# Suggest an estimand based on the suggester backdoor set, front door set, and iv set
estimand = identifier.suggest_estimand(confounders=suggested_confounders, treatment=treatment, outcome=outcome, backdoor=suggested_backdoor, frontdoor=suggested_frontdoor, iv=suggested_iv, llm=gpt4) # Create instance of Validator
validator = Validator()
# Suggest a critique of the provided DAG
suggested_critiques_dag = validator.critique_graph(graph=suggested_dag, llm=gpt4)
# Suggest latent confounders
suggested_latent_confounders = validator.suggest_latent_confounders(treatment=treatment, outcome=outcome, llm=gpt4)
# Suggest negative controls
suggested_negative_controls = validator.suggest_negative_controls(variables=selected_variables, treatment=treatment, outcome=outcome, llm=gpt4)
plt.figure(figsize=(10, 5))
nx.draw(suggested_critiques_dag, with_labels=True, node_color='lightblue')
plt.show()This project welcomes contributions and suggestions. For a guide to contributing and a list of all contributors, check out CONTRIBUTING.md. Our contributor code of conduct is available here.
If you encounter an issue or have a specific request for DoWhy, please raise an issue.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pywhyllm
Similar Open Source Tools
pywhyllm
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments causal inference by suggesting potential confounders, relationships between variables, backdoor/frontdoor/iv sets, estimands, critiques of DAGs, latent confounders, and negative controls. The tool aims to enhance the causal analysis process by leveraging the capabilities of LLMs.
pywhy-llm
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments existing causal inference processes by suggesting potential confounders, relationships between variables, backdoor sets, front door sets, IV sets, estimands, critiques of DAGs, latent confounders, and negative controls. By leveraging LLMs and formalizing human-LLM collaboration, PyWhy-LLM aims to enhance causal analysis accessibility and insight.

langfair
LangFair is a Python library for bias and fairness assessments of large language models (LLMs). It offers a comprehensive framework for choosing bias and fairness metrics, demo notebooks, and a technical playbook. Users can tailor evaluations to their use cases with a Bring Your Own Prompts approach. The focus is on output-based metrics practical for governance audits and real-world testing.

beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.
GDPO
GDPO is a reinforcement learning optimization method designed for multi-reward training. It resolves reward advantages collapse by decoupling reward normalization across individual rewards, enabling more faithful preference optimization. The implementation includes easy-to-use training scripts for tool calling and math reasoning tasks. GDPO consistently outperforms existing approaches in training convergence and downstream evaluation performance.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

Quantus
Quantus is a toolkit designed for the evaluation of neural network explanations. It offers more than 30 metrics in 6 categories for eXplainable Artificial Intelligence (XAI) evaluation. The toolkit supports different data types (image, time-series, tabular, NLP) and models (PyTorch, TensorFlow). It provides built-in support for explanation methods like captum, tf-explain, and zennit. Quantus is under active development and aims to provide a comprehensive set of quantitative evaluation metrics for XAI methods.
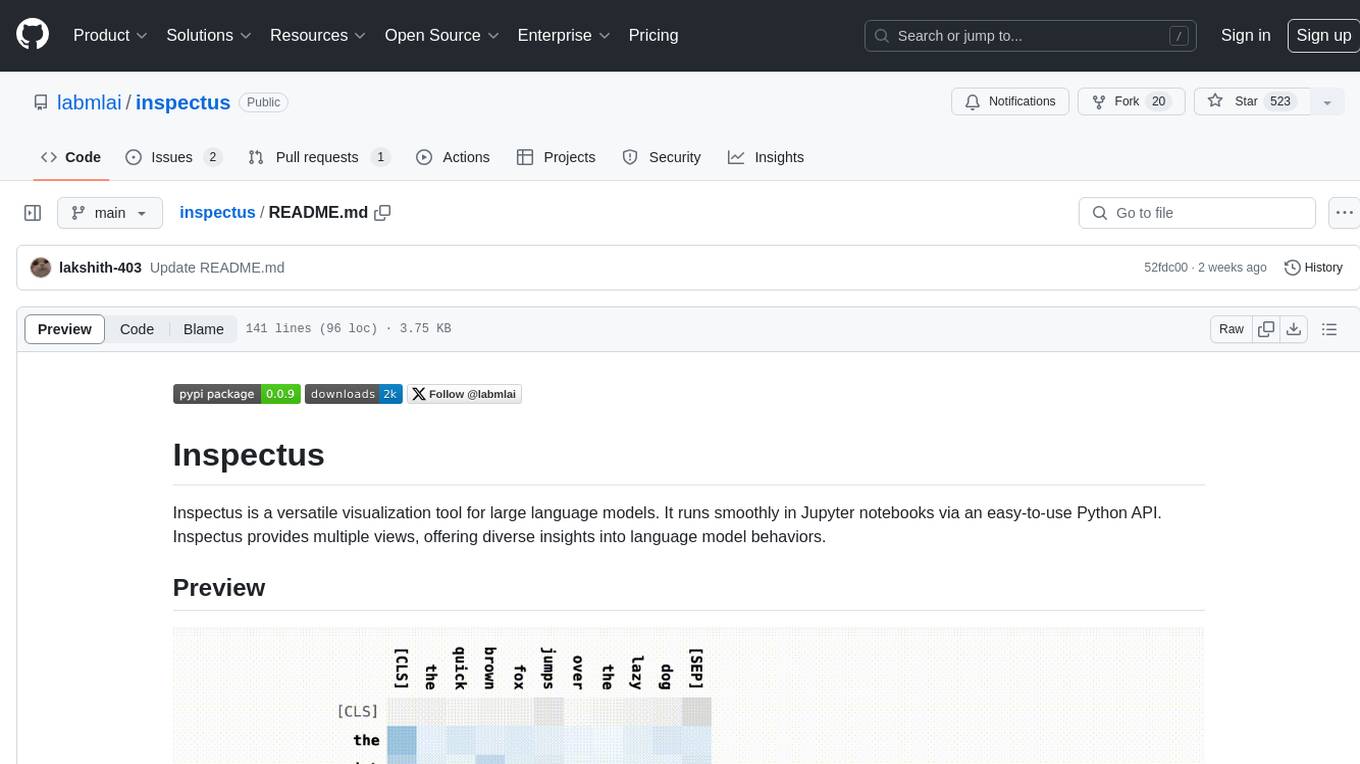
inspectus
Inspectus is a versatile visualization tool for large language models. It provides multiple views, including Attention Matrix, Query Token Heatmap, Key Token Heatmap, and Dimension Heatmap, to offer insights into language model behaviors. Users can interact with the tool in Jupyter notebooks through an easy-to-use Python API. Inspectus allows users to visualize attention scores between tokens, analyze how tokens focus on each other during processing, and explore the relationships between query and key tokens. The tool supports the visualization of attention maps from Huggingface transformers and custom attention maps, making it a valuable resource for researchers and developers working with language models.
topicGPT
TopicGPT is a repository containing scripts and prompts for the paper 'TopicGPT: Topic Modeling by Prompting Large Language Models' (NAACL'24). The 'topicgpt_python' package offers functions to generate high-level and specific topics, refine topics, assign topics to input text, and correct generated topics. It supports various APIs like OpenAI, VertexAI, Azure, Gemini, and vLLM for inference. Users can prepare data in JSONL format, run the pipeline using provided scripts, and evaluate topic alignment with ground-truth labels.
ragoon
RAGoon is a high-level library designed for batched embeddings generation, fast web-based RAG (Retrieval-Augmented Generation) processing, and quantized indexes processing. It provides NLP utilities for multi-model embedding production, high-dimensional vector visualization, and enhancing language model performance through search-based querying, web scraping, and data augmentation techniques.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.
LLM-Microscope
LLM-Microscope is a toolkit designed for quantifying and visualizing language model internals. It provides functions for calculating anisotropy, intrinsic dimension, and linearity score. The toolkit also includes a Logit Lens feature for analyzing model predictions and losses. Users can easily install the toolkit using pip and explore the functionalities through provided examples.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

fuse-med-ml
FuseMedML is a Python framework designed to accelerate machine learning-based discovery in the medical field by promoting code reuse. It provides a flexible design concept where data is stored in a nested dictionary, allowing easy handling of multi-modality information. The framework includes components for creating custom models, loss functions, metrics, and data processing operators. Additionally, FuseMedML offers 'batteries included' key components such as fuse.data for data processing, fuse.eval for model evaluation, and fuse.dl for reusable deep learning components. It supports PyTorch and PyTorch Lightning libraries and encourages the creation of domain extensions for specific medical domains.

zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.
For similar tasks
pywhy-llm
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments existing causal inference processes by suggesting potential confounders, relationships between variables, backdoor sets, front door sets, IV sets, estimands, critiques of DAGs, latent confounders, and negative controls. By leveraging LLMs and formalizing human-LLM collaboration, PyWhy-LLM aims to enhance causal analysis accessibility and insight.

OneKE
OneKE is a flexible dockerized system for schema-guided knowledge extraction, capable of extracting information from the web and raw PDF books across multiple domains like science and news. It employs a collaborative multi-agent approach and includes a user-customizable knowledge base to enable tailored extraction. OneKE offers various IE tasks support, data sources support, LLMs support, extraction method support, and knowledge base configuration. Users can start with examples using YAML, Python, or Web UI, and perform tasks like Named Entity Recognition, Relation Extraction, Event Extraction, Triple Extraction, and Open Domain IE. The tool supports different source formats like Plain Text, HTML, PDF, Word, TXT, and JSON files. Users can choose from various extraction models like OpenAI, DeepSeek, LLaMA, Qwen, ChatGLM, MiniCPM, and OneKE for information extraction tasks. Extraction methods include Schema Agent, Extraction Agent, and Reflection Agent. The tool also provides support for schema repository and case repository management, along with solutions for network issues. Contributors to the project include Ningyu Zhang, Haofen Wang, Yujie Luo, Xiangyuan Ru, Kangwei Liu, Lin Yuan, Mengshu Sun, Lei Liang, Zhiqiang Zhang, Jun Zhou, Lanning Wei, Da Zheng, and Huajun Chen.
pywhyllm
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments causal inference by suggesting potential confounders, relationships between variables, backdoor/frontdoor/iv sets, estimands, critiques of DAGs, latent confounders, and negative controls. The tool aims to enhance the causal analysis process by leveraging the capabilities of LLMs.
For similar jobs
pywhy-llm
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments existing causal inference processes by suggesting potential confounders, relationships between variables, backdoor sets, front door sets, IV sets, estimands, critiques of DAGs, latent confounders, and negative controls. By leveraging LLMs and formalizing human-LLM collaboration, PyWhy-LLM aims to enhance causal analysis accessibility and insight.
pywhyllm
PyWhy-LLM is an innovative library that integrates Large Language Models (LLMs) into the causal analysis process, empowering users with knowledge previously only available through domain experts. It seamlessly augments causal inference by suggesting potential confounders, relationships between variables, backdoor/frontdoor/iv sets, estimands, critiques of DAGs, latent confounders, and negative controls. The tool aims to enhance the causal analysis process by leveraging the capabilities of LLMs.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.