
MotionLLM
[Arxiv-2024] MotionLLM: Understanding Human Behaviors from Human Motions and Videos
Stars: 212

MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.
README:

Ling-Hao Chen😎 1, 3, Shunlin Lu😎 2, 3, Ailing Zeng3, Hao Zhang3, 4, Benyou Wang2, Ruimao Zhang2, Lei Zhang🤗 3
😎Co-first author. Listing order is random. 🤗Corresponding author.
1Tsinghua University, 2School of Data Science, The Chinese University of Hong Kong, Shenzhen (CUHK-SZ), 3International Digital Economy Academy (IDEA), 4The Hong Kong University of Science and Technology
- [2024-06-17]: MoVid dataset Video data is now available at HuggingFace. Have a quick view on our data here.
- [2024-06-11]: CLI mode is supported. MotionLLM is running on A100 GPU on 🤗HuggingFace demo (Posts on Twitter).
- [2024-05-31]: Paper, demo, and codes are released (Posts on Twitter).
This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.


We provide a simple online demo for you to try MotionLLM. Below is the guidance to deploy the demo on your local machine.
pip install -r requirements.txt2.1 Download the LLM
Please follow the instruction of Lit-GPT to prepare the LLM model (vicuna 1.5-7B). These files will be:
./checkpoints/vicuna-7b-v1.5
├── generation_config.json
├── lit_config.json
├── lit_model.pth
├── pytorch_model-00001-of-00002.bin
├── pytorch_model-00002-of-00002.bin
├── pytorch_model.bin.index.json
├── tokenizer_config.json
└── tokenizer.modelFor how to get lit_model.pth, please refer to issue 9.
If you have any confusion, we will update a more detailed instruction in couple of days.
2.2 Dowload the LoRA and the projection layer of the MotionLLM
We now release one versions of the MotionLLM checkpoints, namely v1.0 (download here). Opening for the suggestions to Ling-Hao Chen and Shunlin Lu.
wget xxxKeep them in a folder named and remember the path (LINEAR_V and LORA).
Choice 1: gradio demo
GRADIO_TEMP_DIR=temp python app.py --lora_path $LORA --mlp_path $LINEAR_VIf you have some error in downloading the huggingface model, you can try the following command with the mirror of huggingface.
HF_ENDPOINT=https://hf-mirror.com GRADIO_TEMP_DIR=temp python app.py --lora_path $LORA --mlp_path $LINEAR_VThe GRADIO_TEMP_DIR=temp defines a temporary directory as ./temp for the Gradio to store the data. You can change it to your own path.
After thiess, you can open the browser and visit the local host via the command line output reminder. If it is not loaded, please change the IP address as your local IP address (via command ifconfig).
Choice 2: CLI demo
We also provide a CLI demo for you to try the MotionLLM. You can run the following command to try the MotionLLM.python cli.py --lora_path $LORA --mlp_path $LINEAR_VDuring inference, you can input the video path and your question to get the answer.
# Example here
Input video path: xxx.mp4
Your question: what xxx ?
================================
The man plan to xxx.
================================- [x] Release the CLI demo of MotionLLM.
- [x] Release the video demo of MotionLLM.
- [ ] Release the motion demo of MotionLLM.
- [ ] Release the MoVid dataset and MoVid-Bench.
- [ ] Release the tuning instruction of MotionLLM.
The author team would like to deliver many thanks to many people. Qing Jiang helps a lot with some parts of manual annotation on MoVid Bench and resolves some ethics issues of MotionLLM. Jingcheng Hu provided some technical suggestions for efficient training. Shilong Liu and Bojia Zi provided some significant technical suggestions on LLM tuning. Jiale Liu, Wenhao Yang, and Chenlai Qian provided some significant suggestions for us to polish the paper. Hongyang Li helped us a lot with the figure design. Yiren Pang provided GPT API keys when our keys were temporarily out of quota. The code is on the basis of Video-LLaVA, HumanTOMATO, MotionGPT. lit-gpt, and HumanML3D. Thanks to all contributors!
This code is distributed under an IDEA LICENSE. Note that our code depends on other libraries and datasets which each have their own respective licenses that must also be followed.
If you have any question, please contact at: thu [DOT] lhchen [AT] gmail [DOT] com AND shunlinlu0803 [AT] gmail [DOT] com.
@article{chen2024motionllm,
title={MotionLLM: Understanding Human Behaviors from Human Motions and Videos},
author={Chen, Ling-Hao and Lu, Shunlin and Zeng, Ailing and Zhang, Hao and Wang, Benyou and Zhang, Ruimao and Zhang, Lei},
journal={arXiv preprint arXiv:2405.20340},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MotionLLM
Similar Open Source Tools
MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
Endia
Endia is a dynamic Array library for Scientific Computing, offering automatic differentiation of arbitrary order, complex number support, dual API with PyTorch-like imperative or JAX-like functional interface, and JIT Compilation for speeding up training and inference. It can handle complex valued functions, perform both forward and reverse-mode automatic differentiation, and has a builtin JIT compiler. Endia aims to advance AI & Scientific Computing by pushing boundaries with clear algorithms, providing high-performance open-source code that remains readable and pythonic, and prioritizing clarity and educational value over exhaustive features.
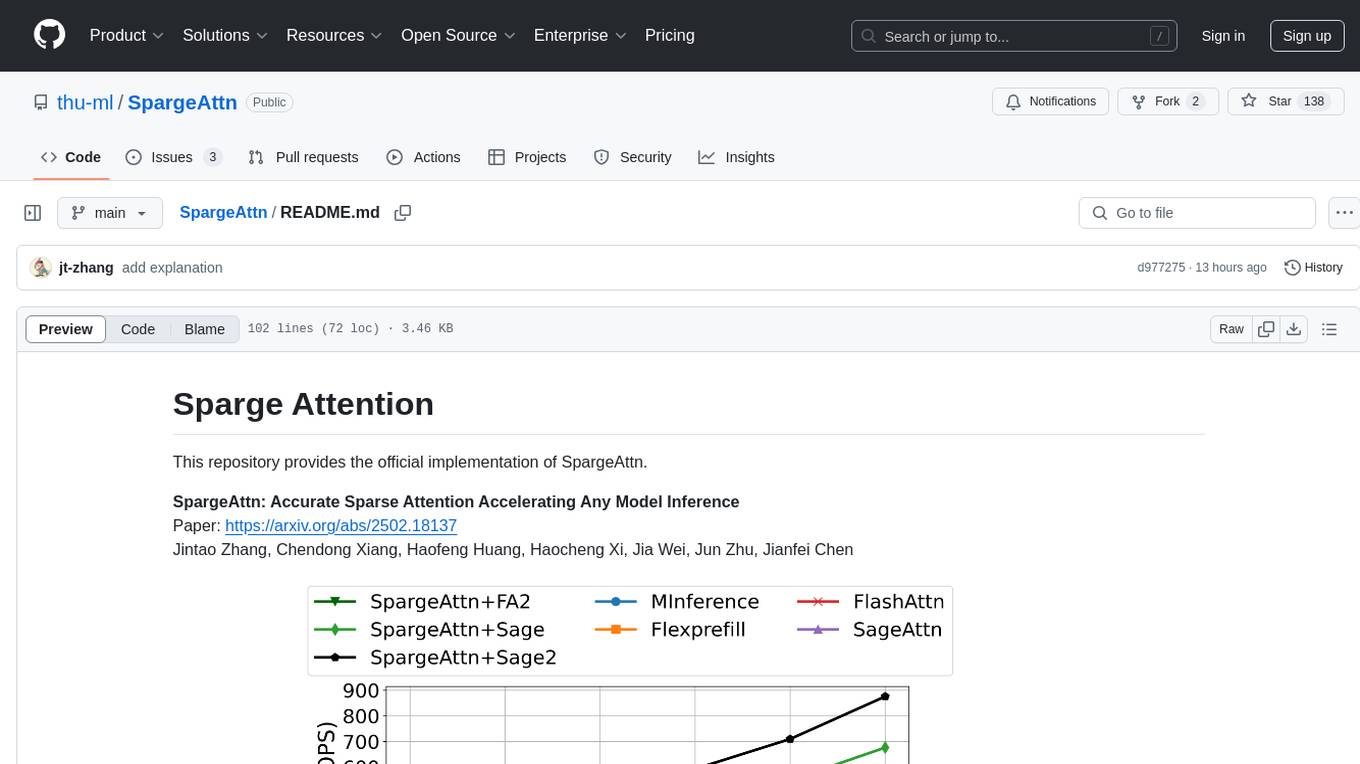
SpargeAttn
SpargeAttn is an official implementation designed for accelerating any model inference by providing accurate sparse attention. It offers a significant speedup in model performance while maintaining quality. The tool is based on SageAttention and SageAttention2, providing options for different levels of optimization. Users can easily install the package and utilize the available APIs for their specific needs. SpargeAttn is particularly useful for tasks requiring efficient attention mechanisms in deep learning models.

LLM-Blender
LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.

chromem-go
chromem-go is an embeddable vector database for Go with a Chroma-like interface and zero third-party dependencies. It enables retrieval augmented generation (RAG) and similar embeddings-based features in Go apps without the need for a separate database. The focus is on simplicity and performance for common use cases, allowing querying of documents with minimal memory allocations. The project is in beta and may introduce breaking changes before v1.0.0.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.
For similar tasks
MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
awesome-sound_event_detection
The 'awesome-sound_event_detection' repository is a curated reading list focusing on sound event detection and Sound AI. It includes research papers covering various sub-areas such as learning formulation, network architecture, pooling functions, missing or noisy audio, data augmentation, representation learning, multi-task learning, few-shot learning, zero-shot learning, knowledge transfer, polyphonic sound event detection, loss functions, audio and visual tasks, audio captioning, audio retrieval, audio generation, and more. The repository provides a comprehensive collection of papers, datasets, and resources related to sound event detection and Sound AI, making it a valuable reference for researchers and practitioners in the field.
AI-Competition-Collections
AI-Competition-Collections is a repository that collects and curates various experiences and tips from AI competitions. It includes posts on competition experiences in computer vision, NLP, speech, and other AI-related fields. The repository aims to provide valuable insights and techniques for individuals participating in AI competitions, covering topics such as image classification, object detection, OCR, adversarial attacks, and more.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.