
zeta
Build high-performance AI models with modular building blocks
Stars: 365

Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.
README:

 Build SOTA AI Models 80% faster with modular, high-performance, and scalable building blocks!
Build SOTA AI Models 80% faster with modular, high-performance, and scalable building blocks!









After building out thousands of neural nets and facing the same annoying bottlenecks of chaotic codebases with no modularity and low performance modules, Zeta needed to be born to enable me and others to quickly prototype, train, and optimize the latest SOTA neural nets and deploy them into production.
Zeta places a radical emphasis on useability, modularity, and performance. Zeta is now currently employed in 100s of models across my github and across others. Get started below and LMK if you want my help building any model, I'm here for you 😊 💜
$ pip3 install -U zetascaleCreating a model empowered with the aforementioned breakthrough research features is a breeze. Here's how to quickly materialize the renowned Multi Query Attention
import torch
from zeta import MultiQueryAttention
# Model
model = MultiQueryAttention(
dim=512,
heads=8,
)
# Input
text = torch.randn(2, 4, 512)
# Output
output, _, _ = model(text)
print(output.shape)
print(output)The SwiGLU activation function takes an input tensor and applies a gating mechanism to selectively pass information. It consists of two parts: the "switch" gate and the "glu" gate. The switch gate controls the flow of information, while the glu gate performs a non-linear transformation on the input.
import torch
from zeta.nn import SwiGLUStacked
x = torch.randn(5, 10)
swiglu = SwiGLUStacked(10, 20)
swiglu(x).shapeIn this example, we first import the necessary modules, including torch for tensor operations and SwiGLUStacked from zeta.nn for the SwiGLU activation function.
We then create a random input tensor x with a shape of (5, 10). Next, we instantiate an instance of SwiGLUStacked with an input size of 10 and an output size of 20.
Finally, we pass the input tensor x to the swiglu module, which applies the SwiGLU activation function to it. The resulting output tensor is stored in the output variable. We print the shape of the output tensor to see the
-
RelativePositionBiasquantizes the distance between two positions into a certain number of buckets and then uses an embedding to get the relative position bias. This mechanism aids in the attention mechanism by providing biases based on relative positions between the query and key, rather than relying solely on their absolute positions.
import torch
from torch import nn
from zeta.nn import RelativePositionBias
# Initialize the RelativePositionBias module
rel_pos_bias = RelativePositionBias()
# Example 1: Compute bias for a single batch
bias_matrix = rel_pos_bias(1, 10, 10)
# Example 2: Utilize in conjunction with an attention mechanism
# NOTE: This is a mock example, and may not represent an actual attention mechanism's complete implementation.
class MockAttention(nn.Module):
def __init__(self):
super().__init__()
self.rel_pos_bias = RelativePositionBias()
def forward(self, queries, keys):
bias = self.rel_pos_bias(queries.size(0), queries.size(1), keys.size(1))
# Further computations with bias in the attention mechanism...
return None # Placeholder
# Example 3: Modify default configurations
custom_rel_pos_bias = RelativePositionBias(
bidirectional=False, num_buckets=64, max_distance=256, num_heads=8
)The FeedForward module performs a feedforward operation on the input tensor x. It consists of a multi-layer perceptron (MLP) with an optional activation function and LayerNorm. Used in most language, multi-modal, and modern neural networks.
import torch
from zeta.nn import FeedForward
model = FeedForward(256, 512, glu=True, post_act_ln=True, dropout=0.2)
x = torch.randn(1, 256)
output = model(x)
print(output.shape)- The BitLinear module performs linear transformation on the input data, followed by quantization and dequantization. The quantization process is performed using the absmax_quantize function, which quantizes the input tensor based on the absolute maximum value, from the paper
import torch
from torch import nn
import zeta.quant as qt
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = qt.BitLinear(10, 20)
def forward(self, x):
return self.linear(x)
# Initialize the model
model = MyModel()
# Create a random tensor of size (128, 10)
input = torch.randn(128, 10)
# Perform the forward pass
output = model(input)
# Print the size of the output
print(output.size()) # torch.Size([128, 20])- This is an implementation of the multi-modal Palm-E model using a decoder llm as the backbone with an VIT image encoder to process vision, it's very similiar to GPT4, Kosmos, RTX2, and many other multi-modality model architectures
import torch
from zeta.structs import (
AutoRegressiveWrapper,
Decoder,
Encoder,
Transformer,
ViTransformerWrapper,
)
class PalmE(torch.nn.Module):
"""
PalmE is a transformer architecture that uses a ViT encoder and a transformer decoder.
Args:
image_size (int): Size of the image.
patch_size (int): Size of the patch.
encoder_dim (int): Dimension of the encoder.
encoder_depth (int): Depth of the encoder.
encoder_heads (int): Number of heads in the encoder.
num_tokens (int): Number of tokens.
max_seq_len (int): Maximum sequence length.
decoder_dim (int): Dimension of the decoder.
decoder_depth (int): Depth of the decoder.
decoder_heads (int): Number of heads in the decoder.
alibi_num_heads (int): Number of heads in the alibi attention.
attn_kv_heads (int): Number of heads in the attention key-value projection.
use_abs_pos_emb (bool): Whether to use absolute positional embeddings.
cross_attend (bool): Whether to cross attend in the decoder.
alibi_pos_bias (bool): Whether to use positional bias in the alibi attention.
rotary_xpos (bool): Whether to use rotary positional embeddings.
attn_flash (bool): Whether to use attention flash.
qk_norm (bool): Whether to normalize the query and key in the attention layer.
Returns:
torch.Tensor: The output of the model.
Usage:
img = torch.randn(1, 3, 256, 256)
text = torch.randint(0, 20000, (1, 1024))
model = PalmE()
output = model(img, text)
print(output)
"""
def __init__(
self,
image_size=256,
patch_size=32,
encoder_dim=512,
encoder_depth=6,
encoder_heads=8,
num_tokens=20000,
max_seq_len=1024,
decoder_dim=512,
decoder_depth=6,
decoder_heads=8,
alibi_num_heads=4,
attn_kv_heads=2,
use_abs_pos_emb=False,
cross_attend=True,
alibi_pos_bias=True,
rotary_xpos=True,
attn_flash=True,
qk_norm=True,
):
super().__init__()
# vit architecture
self.encoder = ViTransformerWrapper(
image_size=image_size,
patch_size=patch_size,
attn_layers=Encoder(
dim=encoder_dim, depth=encoder_depth, heads=encoder_heads
),
)
# palm model architecture
self.decoder = Transformer(
num_tokens=num_tokens,
max_seq_len=max_seq_len,
use_abs_pos_emb=use_abs_pos_emb,
attn_layers=Decoder(
dim=decoder_dim,
depth=decoder_depth,
heads=decoder_heads,
cross_attend=cross_attend,
alibi_pos_bias=alibi_pos_bias,
alibi_num_heads=alibi_num_heads,
rotary_xpos=rotary_xpos,
attn_kv_heads=attn_kv_heads,
attn_flash=attn_flash,
qk_norm=qk_norm,
),
)
# autoregressive wrapper to enable generation of tokens
self.decoder = AutoRegressiveWrapper(self.decoder)
def forward(self, img: torch.Tensor, text: torch.Tensor):
"""Forward pass of the model."""
try:
encoded = self.encoder(img, return_embeddings=True)
return self.decoder(text, context=encoded)
except Exception as error:
print(f"Failed in forward method: {error}")
raise
# Usage with random inputs
img = torch.randn(1, 3, 256, 256)
text = torch.randint(0, 20000, (1, 1024))
# Initiliaze the model
model = PalmE()
output = model(img, text)
print(output)Unet is a famous convolutional neural network architecture originally used for biomedical image segmentation but soon became the backbone of the generative AI Mega-revolution. The architecture comprises two primary pathways: downsampling and upsampling, followed by an output convolution. Due to its U-shape, the architecture is named U-Net. Its symmetric architecture ensures that the context (from downsampling) and the localization (from upsampling) are captured effectively.
import torch
from zeta.nn import Unet
# Initialize the U-Net model
model = Unet(n_channels=1, n_classes=2)
# Random input tensor with dimensions [batch_size, channels, height, width]
x = torch.randn(1, 1, 572, 572)
# Forward pass through the model
y = model(x)
# Output
print(f"Input shape: {x.shape}")
print(f"Output shape: {y.shape}")The VisionEmbedding class is designed for converting images into patch embeddings, making them suitable for processing by transformer-based models. This class plays a crucial role in various computer vision tasks and enables the integration of vision data into transformer architectures!
import torch
from zeta.nn import VisionEmbedding
# Create an instance of VisionEmbedding
vision_embedding = VisionEmbedding(
img_size=224,
patch_size=16,
in_chans=3,
embed_dim=768,
contain_mask_token=True,
prepend_cls_token=True,
)
# Load an example image (3 channels, 224x224)
input_image = torch.rand(1, 3, 224, 224)
# Perform image-to-patch embedding
output = vision_embedding(input_image)
# The output now contains patch embeddings, ready for input to a transformer model- Niva focuses on weights of certain layers (specified by quantize_layers). Ideal for models where runtime activation is variable. 👁️ Example Layers: nn.Embedding, nn.LSTM.
import torch
from zeta import niva
# Load a pre-trained model
model = YourModelClass()
# Quantize the model dynamically, specifying layers to quantize
niva(
model=model,
model_path="path_to_pretrainedim_weights.pt",
output_path="quantizedim.pt",
quant_type="dynamic",
quantize_layers=[nn.Linear, nn.Conv2d],
dtype=torch.qint8,
)- Increase model speed by 2x with this module that fuses together 2 hyper-optimized dense ops from bits and bytes and a gelu together!
import torch
from zeta.nn import FusedDenseGELUDense
x = torch.randn(1, 512)
model = FusedDenseGELUDense(512, 1024)
out = model(x)
out.shape- FusedDropoutLayerNorm is a fused kernel of dropout and layernorm to speed up FFNs or MLPS by 2X
import torch
from torch import nn
from zeta.nn import FusedDropoutLayerNorm
# Initialize the module
model = FusedDropoutLayerNorm(dim=512)
# Create a sample input tensor
x = torch.randn(1, 512)
# Forward pass
output = model(x)
# Check output shape
print(output.shape) # Expected: torch.Size([1, 512])- Pytorch implementation of the new SSM model architecture Mamba
import torch
from zeta.nn import MambaBlock
# Initialize Mamba
block = MambaBlock(dim=64, depth=1)
# Random input
x = torch.randn(1, 10, 64)
# Apply the model to the block
y = block(x)
print(y.shape)
# torch.Size([1, 10, 64])import torch
from zeta.nn import Film
# Initialize the Film layer
film_layer = Film(dim=128, hidden_dim=64, expanse_ratio=4)
# Create some dummy data for conditions and hiddens
conditions = torch.randn(10, 128) # Batch size is 10, feature size is 128
hiddens = torch.randn(
10, 1, 128
) # Batch size is 10, sequence length is 1, feature size is 128
# Pass the data through the Film layer
modulated_features = film_layer(conditions, hiddens)
# Print the shape of the output
print(modulated_features.shape) # Should be [10, 1, 128]- A single wrapper for torch.fx, torch.script, torch.compile, dynamic quantization, mixed precision through torch.amp, with execution time metrics all in once place!
import torch
from zeta.nn import hyper_optimize
@hyper_optimize(
torch_fx=False,
torch_script=False,
torch_compile=True,
quantize=True,
mixed_precision=True,
enable_metrics=True,
)
def model(x):
return x @ x
out = model(torch.randn(1, 3, 32, 32))
print(out)Direct Policy Optimization employed for many RLHF applications for LLMs.
import torch
from torch import nn
from zeta.rl import DPO
# Define a simple policy model
class PolicyModel(nn.Module):
def __init__(self, dim, output_dim):
super().__init__()
self.fc = nn.Linear(dim, output_dim)
def forward(self, x):
return self.fc(x)
dim = 10
output_dim = 5
policy_model = PolicyModel(dim, output_dim)
# Initialize DPO with the policy model
dpo_model = DPO(model=policy_model, beta=0.1)
# Sample preferred and unpreferred sequences
preferred_seq = torch.randint(0, output_dim, (3, dim))
unpreferred_seq = torch.randint(0, output_dim, (3, dim))
# Compute loss
loss = dpo_model(preferred_seq, unpreferred_seq)
print(loss)- A decorator that logs the execution of the pytorch model, including parameters, gradients, and memory usage.
from zeta.utils import verbose_execution
import torch
from torch import nn
from zeta.utils.verbose_execution import verbose_execution
# # Configure Loguru (optional)
@verbose_execution(log_params=True, log_gradients=True, log_memory=True)
class YourPyTorchModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, 3)
self.relu = nn.ReLU()
self.flatten = nn.Flatten()
self.fc = nn.Linear(64 * 222 * 222, 10) # Adjusted input size
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.flatten(x)
x = self.fc(x)
return x
# Create and use your model
model = YourPyTorchModel()
input_tensor = torch.randn(1, 3, 224, 224)
output = model(input_tensor)
# If you want to see gradient information, you need to perform a backward pass
loss = output.sum()
loss.backward()All classes must have documentation if you see a class or function without documentation then please report it to me at [email protected],
Documentation is at zeta.apac.ai
You should install the pre-commit hooks with pre-commit install. This will run the linter, mypy, and a subset of the tests on every commit.
For more examples on how to run the full test suite please refer to the CI workflow.
Some examples of running tests locally:
python3 -m pip install -e '.[testing]' # install extra deps for testing
python3 -m pytest tests/ # whole test suiteJoin our growing community around the world, for real-time support, ideas, and discussions on how to build better models 😊
- View our official Docs
- Chat live with us on Discord
- Follow us on Twitter
- Connect with us on LinkedIn
- Visit us on YouTube
- Join the Swarms community on Discord!
Want to train a custom AI model for a real-world task like General Multi-Modal Models, Facial Recognitions, Drug Discovery, Humanoid Robotics? I'll help you create the model architecture then train the model and then optimize it to meet your quality assurance standards.
Book a 1-on-1 Session with Kye here., the Creator, to discuss any issues, provide feedback, or explore how we can improve Zeta for you or help you build your own custom models!
The easiest way to contribute is to pick any issue with the good first issue tag 💪. Read the Contributing guidelines here. Bug Report? File here | Feature Request? File here
Zeta is an open-source project, and contributions are VERY welcome. If you want to contribute, you can create new features, fix bugs, or improve the infrastructure. Please refer to the CONTRIBUTING.md and our contributing board to participate in Roadmap discussions!
Help us accelerate our backlog by supporting us financially! Note, we're an open source corporation and so all the revenue we generate is through donations at the moment ;)

- Apache
@misc{zetascale,
title = {Zetascale Framework},
author = {Kye Gomez},
year = {2024},
howpublished = {\url{https://github.com/kyegomez/zeta}},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for zeta
Similar Open Source Tools
zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.
Endia
Endia is a dynamic Array library for Scientific Computing, offering automatic differentiation of arbitrary order, complex number support, dual API with PyTorch-like imperative or JAX-like functional interface, and JIT Compilation for speeding up training and inference. It can handle complex valued functions, perform both forward and reverse-mode automatic differentiation, and has a builtin JIT compiler. Endia aims to advance AI & Scientific Computing by pushing boundaries with clear algorithms, providing high-performance open-source code that remains readable and pythonic, and prioritizing clarity and educational value over exhaustive features.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.
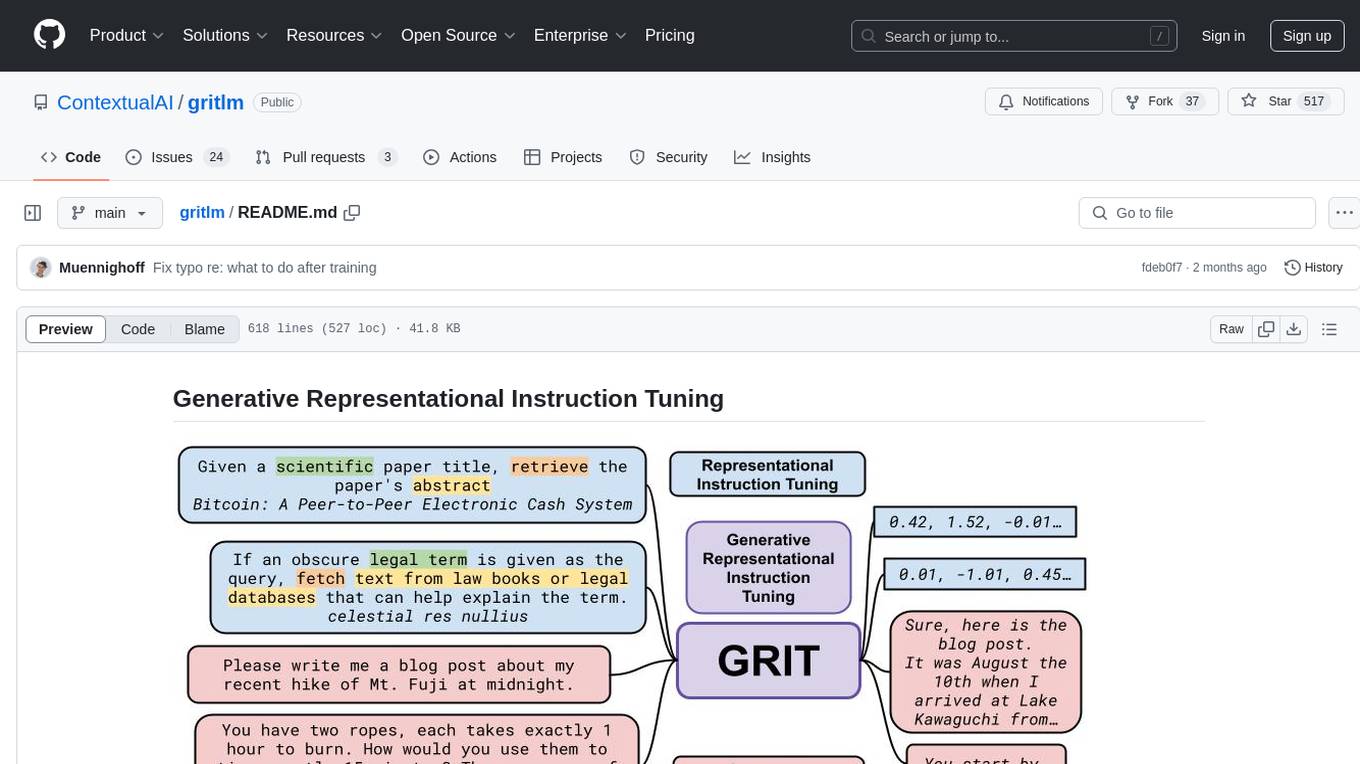
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.

Jlama
Jlama is a modern Java inference engine designed for large language models. It supports various model types such as Gemma, Llama, Mistral, GPT-2, BERT, and more. The tool implements features like Flash Attention, Mixture of Experts, and supports different model quantization formats. Built with Java 21 and utilizing the new Vector API for faster inference, Jlama allows users to add LLM inference directly to their Java applications. The tool includes a CLI for running models, a simple UI for chatting with LLMs, and examples for different model types.
aigverse
aigverse is a Python infrastructure framework that bridges the gap between logic synthesis and AI/ML applications. It allows efficient representation and manipulation of logic circuits, making it easier to integrate logic synthesis and optimization tasks into machine learning pipelines. Built upon EPFL Logic Synthesis Libraries, particularly mockturtle, aigverse provides a high-level Python interface to state-of-the-art algorithms for And-Inverter Graph (AIG) manipulation and logic synthesis, widely used in formal verification, hardware design, and optimization tasks.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

WordLlama
WordLlama is a fast, lightweight NLP toolkit optimized for CPU hardware. It recycles components from large language models to create efficient word representations. It offers features like Matryoshka Representations, low resource requirements, binarization, and numpy-only inference. The tool is suitable for tasks like semantic matching, fuzzy deduplication, ranking, and clustering, making it a good option for NLP-lite tasks and exploratory analysis.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.

embodied-agents
Embodied Agents is a toolkit for integrating large multi-modal models into existing robot stacks with just a few lines of code. It provides consistency, reliability, scalability, and is configurable to any observation and action space. The toolkit is designed to reduce complexities involved in setting up inference endpoints, converting between different model formats, and collecting/storing datasets. It aims to facilitate data collection and sharing among roboticists by providing Python-first abstractions that are modular, extensible, and applicable to a wide range of tasks. The toolkit supports asynchronous and remote thread-safe agent execution for maximal responsiveness and scalability, and is compatible with various APIs like HuggingFace Spaces, Datasets, Gymnasium Spaces, Ollama, and OpenAI. It also offers automatic dataset recording and optional uploads to the HuggingFace hub.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.
For similar tasks
zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.

llm_qlora
LLM_QLoRA is a repository for fine-tuning Large Language Models (LLMs) using QLoRA methodology. It provides scripts for training LLMs on custom datasets, pushing models to HuggingFace Hub, and performing inference. Additionally, it includes models trained on HuggingFace Hub, a blog post detailing the QLoRA fine-tuning process, and instructions for converting and quantizing models. The repository also addresses troubleshooting issues related to Python versions and dependencies.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.
For similar jobs
zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.