Best AI tools for< Deploy Sota Model >
20 - AI tool Sites
Seldon
Seldon is an MLOps platform that helps enterprises deploy, monitor, and manage machine learning models at scale. It provides a range of features to help organizations accelerate model deployment, optimize infrastructure resource allocation, and manage models and risk. Seldon is trusted by the world's leading MLOps teams and has been used to install and manage over 10 million ML models. With Seldon, organizations can reduce deployment time from months to minutes, increase efficiency, and reduce infrastructure and cloud costs.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
Azure Static Web Apps
Azure Static Web Apps is a platform provided by Microsoft Azure for building and deploying modern web applications. It allows developers to easily host static web content and serverless APIs with seamless integration to popular frameworks like React, Angular, and Vue. With Azure Static Web Apps, developers can quickly set up continuous integration and deployment workflows, enabling them to focus on building great user experiences without worrying about infrastructure management.

PoplarML
PoplarML is a platform that enables the deployment of production-ready, scalable ML systems with minimal engineering effort. It offers one-click deploys, real-time inference, and framework agnostic support. With PoplarML, users can seamlessly deploy ML models using a CLI tool to a fleet of GPUs and invoke their models through a REST API endpoint. The platform supports Tensorflow, Pytorch, and JAX models.

ClawOneClick
ClawOneClick is an AI tool that allows users to deploy their own AI assistant in seconds without the need for technical setup. It offers a one-click deployment of an always-on AI chatbot powered by the latest AI models. Users can choose from various AI models and messaging channels to customize their AI assistant. ClawOneClick handles all the cloud infrastructure provisioning and management, ensuring secure connections and end-to-end encryption. The tool is designed to adapt to various tasks and can assist with email summarization, quick replies, translation, proofreading, customer queries, report condensation, meeting reminders, voice memo transcription, deadline tracking, schedule organization, meeting action item capture, time zone coordination, task automation, expense logging, priority planning, content generation, idea brainstorming, fast topic research, book and article summarization, concept learning, creative suggestions, code explanation, document analysis, professional document drafting, project goal definition, team updates preparation, data trend interpretation, job posting writing, product and price comparison, meal plan suggestion, and more.
Vercel
Vercel is an AI-powered cloud platform that enables developers to build, deploy, and scale web applications quickly and securely. It offers a range of developer tools and cloud infrastructure to optimize performance and enhance user experience. Vercel's AI capabilities include AI Cloud, AI SDK, AI Gateway, and Sandbox AI workflows, providing seamless integration of AI models into web applications.
TurboClaw
TurboClaw is an AI-powered platform that allows users to deploy their own 24/7 OpenClaw instance in under a minute, eliminating technical hassles. Users can choose from different AI models and messaging channels, and the platform handles server management, Docker setup, SSL configuration, and OpenClaw deployment. With TurboClaw, users can quickly set up AI bots for various tasks such as drafting replies, translating messages, organizing inboxes, managing subscriptions, finding best prices online, generating content ideas, setting goals, and more.
Hanabi.rest
Hanabi.rest is an AI-based API building platform that allows users to create REST APIs from natural language and screenshots using AI technology. Users can deploy the APIs on Cloudflare Workers and roll them out globally. The platform offers a live editor for testing database access and API endpoints, generates code compatible with various runtimes, and provides features like sharing APIs via URL, npm package integration, and CLI dump functionality. Hanabi.rest simplifies API design and deployment by leveraging natural language processing, image recognition, and v0.dev components.

Superflows
Superflows is a tool that allows you to add an AI Copilot to your SaaS product. This AI Copilot can answer questions and perform tasks for users via chat. It is designed to be easy to set up and configure, and it can be integrated into your codebase with just a few lines of code. Superflows is a great way to improve the user experience of your SaaS product and help users get the most out of your software.
Dreamlab
Dreamlab is a multiplayer game creation platform that allows users to build and deploy great 2D multiplayer games quickly and effortlessly. It features an in-browser collaborative editor, easy integration of multiplayer functionality, and AI assistance for code generation. Dreamlab is designed for indie game developers, game jam participants, Discord server activities, and rapid prototyping. Users can start building their games instantly without the need for downloads or installations. The platform offers simple and transparent pricing with a free plan and a pro plan for serious game developers.
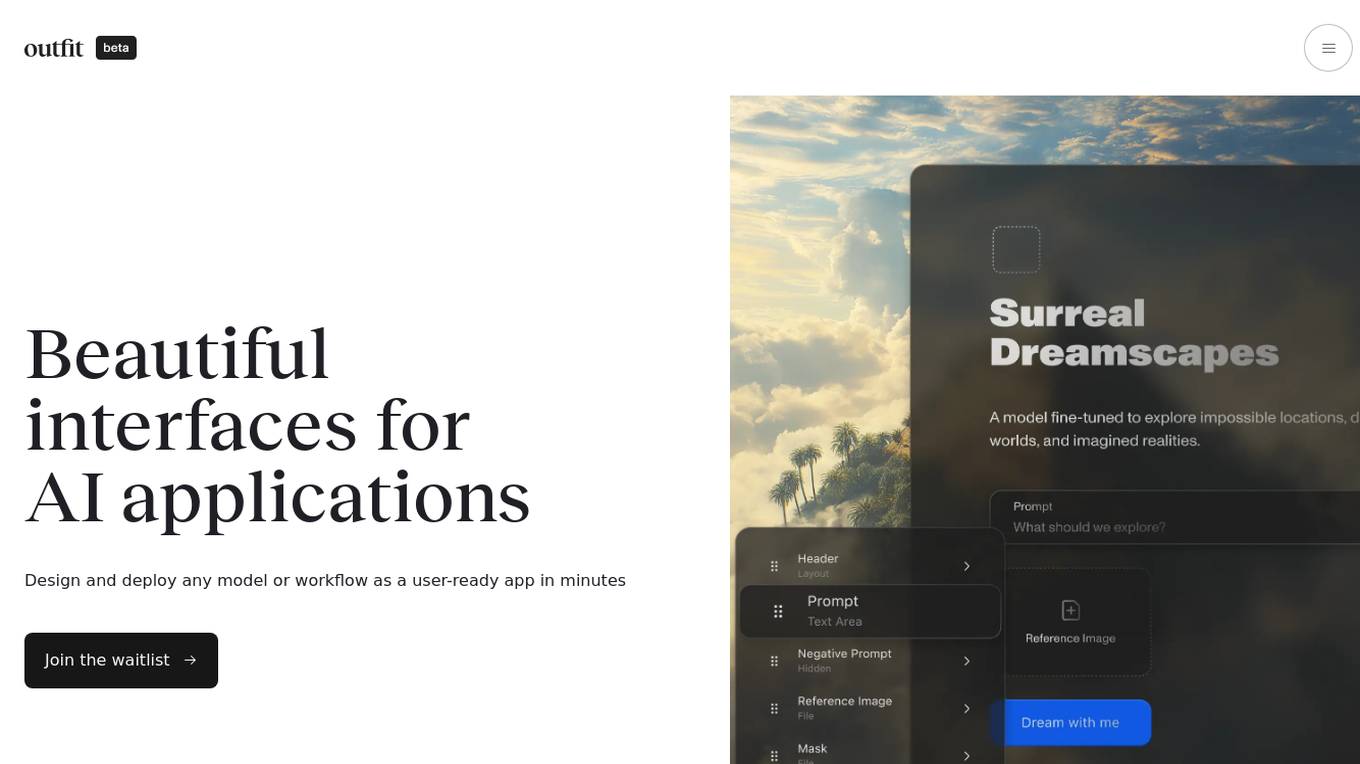
Outfit AI
Outfit AI is an AI tool that enables users to design and deploy AI models or workflows as user-ready applications in minutes. It allows users to create custom user interfaces for their AI-powered apps by dropping in an API key from Replicate or Hugging Face. With Outfit AI, users can have creative control over the design of their apps, build complex workflows without any code, and optimize prompts for better performance. The tool aims to help users launch their models faster, save time, and enhance their AI applications with a built-in product copilot.
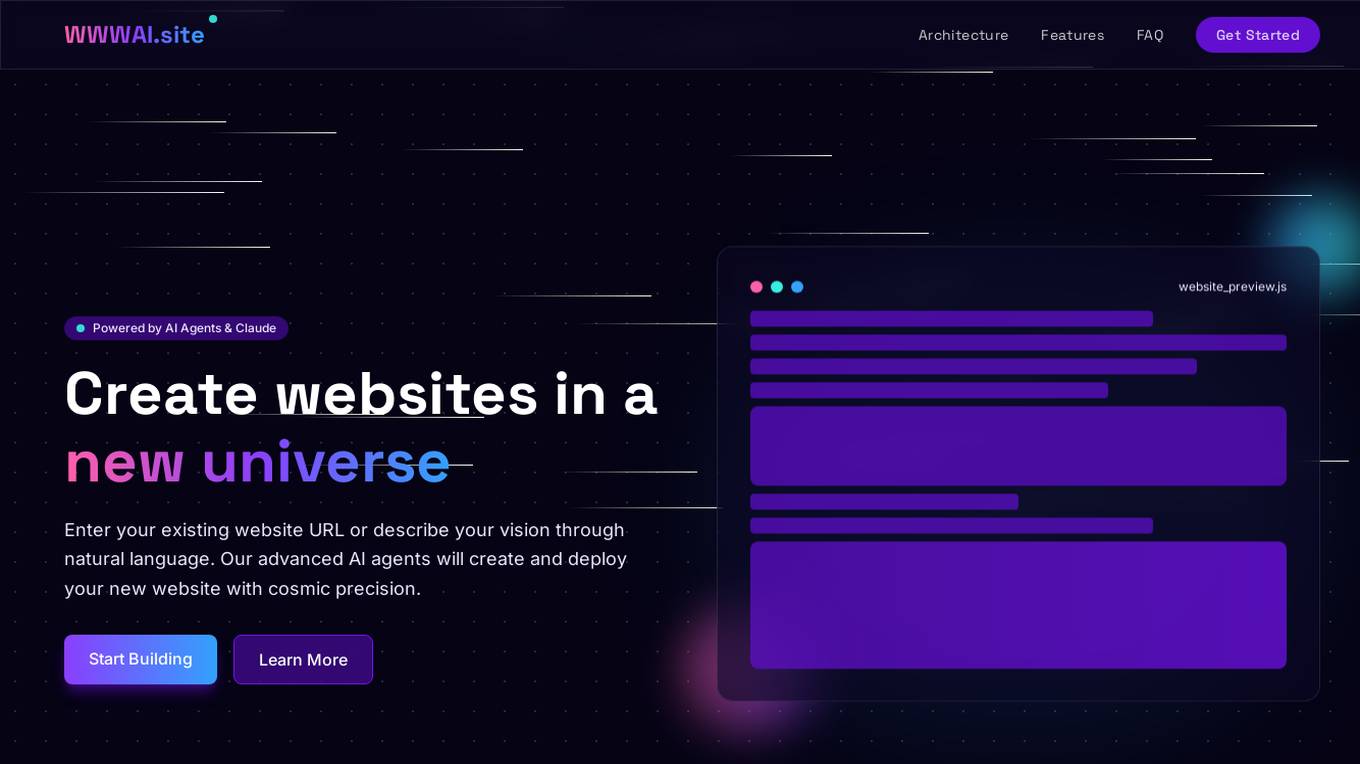
WWWAI.site
WWWAI.site is an AI-powered platform that revolutionizes web creation by allowing users to create and deploy websites using natural language input and advanced AI agents. The platform leverages specialized AI agents, such as Code Creation, Requirement Analysis, Concept Setting, and Error Validation, along with Claude API for language processing capabilities. Model Context Protocol (MCP) ensures consistency across all components, while users can choose between GitHub or CloudFlare for deployment. The platform is currently in beta testing with limited availability, offering users a seamless and innovative website creation experience.
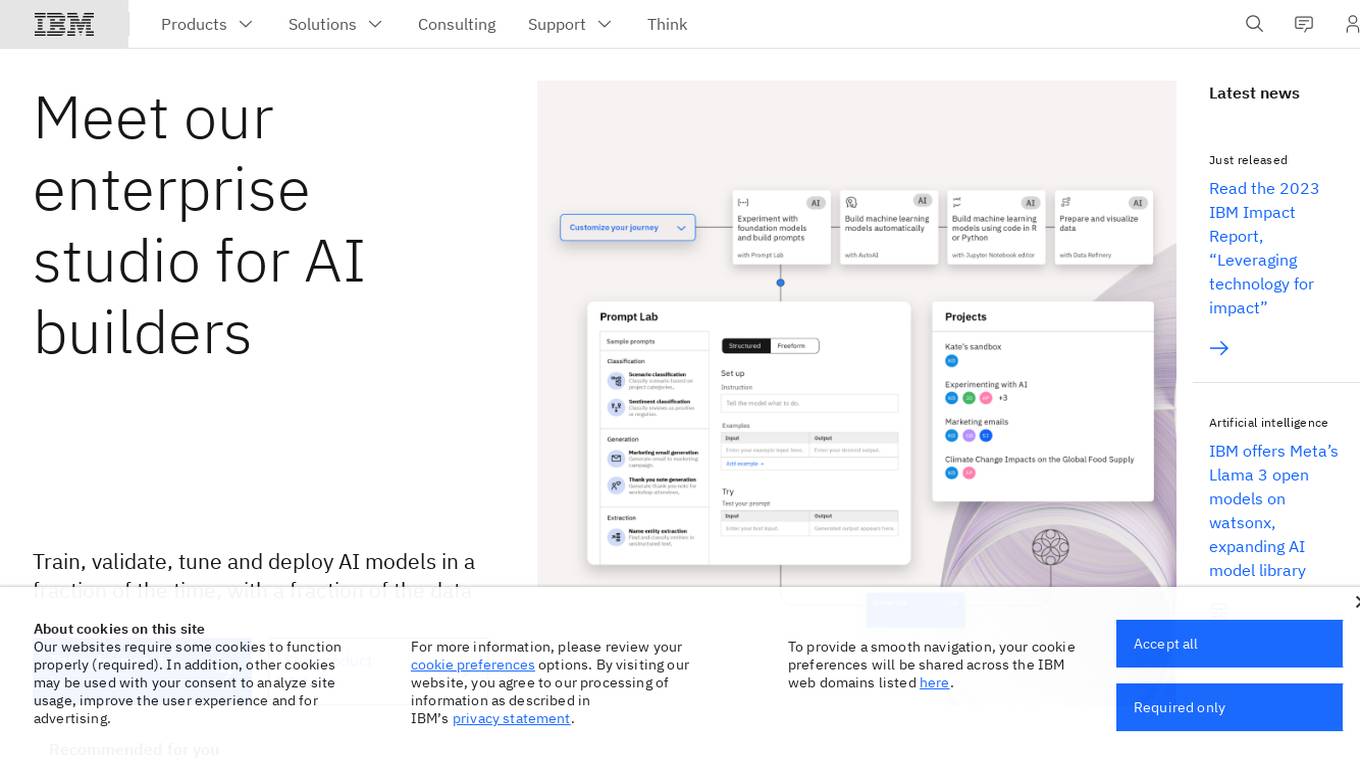
IBM Watsonx
IBM Watsonx is an enterprise studio for AI builders. It provides a platform to train, validate, tune, and deploy AI models quickly and efficiently. With Watsonx, users can access a library of pre-trained AI models, build their own models, and deploy them to the cloud or on-premises. Watsonx also offers a range of tools and services to help users manage and monitor their AI models.
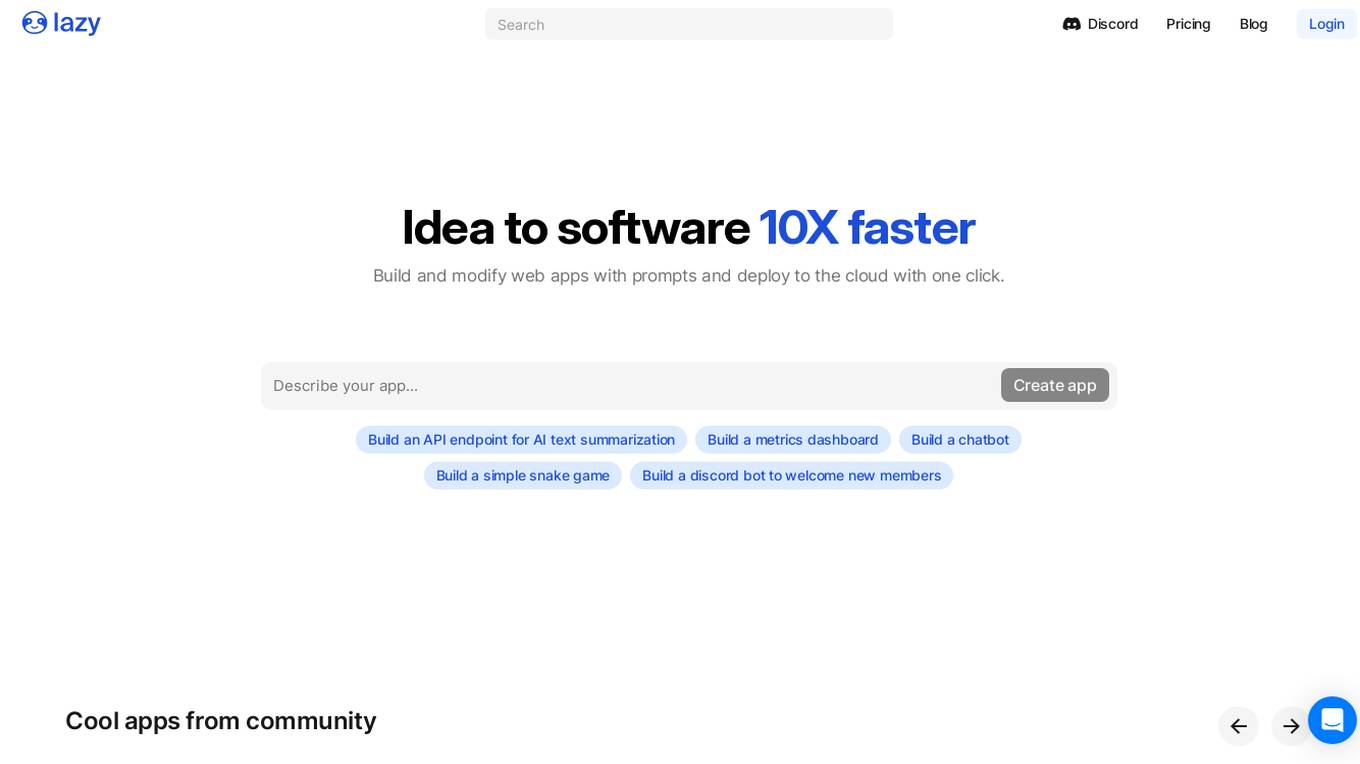
Lazy AI
Lazy AI is a platform that enables users to build full stack web applications 10 times faster by utilizing AI technology. Users can create and modify web apps with prompts and deploy them to the cloud with just one click. The platform offers a variety of features including AI Component Builder, eCommerce store creation, Crypto Arbitrage Scraper, Text to Speech Converter, Lazy Image to Video generation, PDF Chatbot, and more. Lazy AI aims to streamline the app development process and empower users to leverage AI for various tasks.
PixieBrix
PixieBrix is an AI engagement platform that allows users to build, deploy, and manage internal AI tools to drive team productivity. It unifies AI landscapes with oversight and governance for enterprise scale. The platform is enterprise-ready and fully customizable to meet unique needs, and can be deployed on any site, making it easy to integrate into existing systems. PixieBrix leverages the power of AI and automation to harness the latest technology to streamline workflows and take productivity to new heights.
Datature
Datature is an all-in-one platform for building and deploying computer vision models. It provides tools for data management, annotation, training, and deployment, making it easy to develop and implement computer vision solutions. Datature is used by a variety of industries, including healthcare, retail, manufacturing, and agriculture.

Amazon Bedrock
Amazon Bedrock is a cloud-based platform that enables developers to build, deploy, and manage serverless applications. It provides a fully managed environment that takes care of the infrastructure and operations, so developers can focus on writing code. Bedrock also offers a variety of tools and services to help developers build and deploy their applications, including a code editor, a debugger, and a deployment pipeline.
TitanML
TitanML is a platform that provides tools and services for deploying and scaling Generative AI applications. Their flagship product, the Titan Takeoff Inference Server, helps machine learning engineers build, deploy, and run Generative AI models in secure environments. TitanML's platform is designed to make it easy for businesses to adopt and use Generative AI, without having to worry about the underlying infrastructure. With TitanML, businesses can focus on building great products and solving real business problems.
Unified DevOps platform to build AI applications
This is a unified DevOps platform to build AI applications. It provides a comprehensive set of tools and services to help developers build, deploy, and manage AI applications. The platform includes a variety of features such as a code editor, a debugger, a profiler, and a deployment manager. It also provides access to a variety of AI services, such as natural language processing, machine learning, and computer vision.
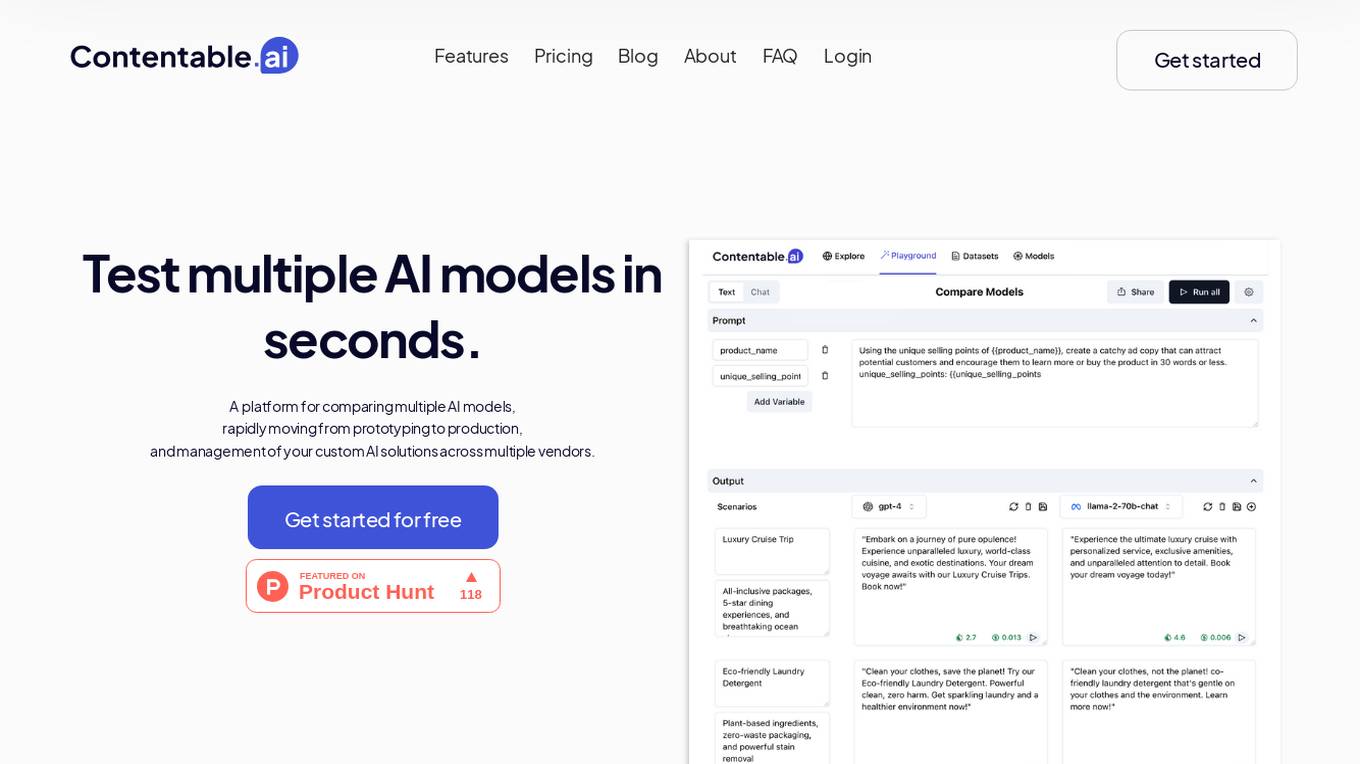
Contentable.ai
Contentable.ai is a platform for comparing multiple AI models, rapidly moving from prototyping to production, and management of your custom AI solutions across multiple vendors. It allows users to test multiple AI models in seconds, compare models side-by-side across top AI providers, collaborate on AI models with their team seamlessly, design complex AI workflows without coding, and pay as they go.
1 - Open Source AI Tools

zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.
20 - OpenAI Gpts
Frontend Developer
AI front-end developer expert in coding React, Nextjs, Vue, Svelte, Typescript, Gatsby, Angular, HTML, CSS, JavaScript & advanced in Flexbox, Tailwind & Material Design. Mentors in coding & debugging for junior, intermediate & senior front-end developers alike. Let’s code, build & deploy a SaaS app.





Azure Arc Expert
Azure Arc expert providing guidance on architecture, deployment, and management.


Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.

Docker and Docker Swarm Assistant
Expert in Docker and Docker Swarm solutions and troubleshooting.



Cloudwise Consultant
Expert in cloud-native solutions, provides tailored tech advice and cost estimates.