
AI-Competition-Collections
AI比赛经验帖子 & 训练和测试技巧帖子 集锦(收集整理各种人工智能比赛经验帖)
Stars: 365
AI-Competition-Collections is a repository that collects and curates various experiences and tips from AI competitions. It includes posts on competition experiences in computer vision, NLP, speech, and other AI-related fields. The repository aims to provide valuable insights and techniques for individuals participating in AI competitions, covering topics such as image classification, object detection, OCR, adversarial attacks, and more.
README:
从他人比赛经验中,总是可以学到很多东西
欢迎您贡献看到的AI比赛经验帖子,可以通过点击🌈贡献AI比赛经验帖子,或扫码填写。(当然直接提PR更欢迎)

- CV赛事经验帖
- NLP赛事经验帖
- 语音赛事经验帖
- Others (推荐系统|数据挖掘|知识图谱|图网络|多智能体决策|蛋白质结构预测|智能机器人等)
- 比赛经验分享
- 语言大模型比赛经验分享
| 公众号名称 | 简单介绍 |
|---|---|
| Kaggle竞赛宝典 | 数据竞赛Top方案,竞赛黑科技,竞赛到入职的一些感想。 |
| DataFountain | DF平台 (www.datafountain.cn) 官方公众号,有趣有料的大数据社群,从今天起,爱上这碗数据汤。 |
| Datawhale | 一个专注于AI领域的开源组织,汇聚了众多优秀学习者,愿景:for the learnner,和学习者一起成长。 |
| 世界AI创新大赛 | 世界人工智能创新大赛(AIWIN),是世界人工智能大会的组成部分之一。 |
| 平台名称 | 简单介绍 |
|---|---|
| Kaggle Solutions | 列出了过去Kaggle比赛中顶尖选手分享的几乎所有可用解决方案和想法。 |
| nlp-competitions-list-review | 复盘所有NLP比赛的TOP方案,只关注NLP比赛 |
| 平台名称 | 简单介绍 |
|---|---|
| CompHub | 实时聚合国内外技术比赛,一个页面,全知道。 |
| 科大讯飞 A.I.开发者大赛 | 全平台比赛信息汇总平台,涵盖CV/NLP/Speech/数据挖掘等比赛,短平快 |
| Coggle数据科学 | 全平台比赛信息汇总平台 |
| DataFountain | 涉及CV、NLP、数据挖掘等全面的比赛平台 |
| 和鲸社区 | 综合性比赛平台,侧重数据科学、机器人一些 |
| FlyAI | 涉及视觉计算、自然语言处理、语音、结构化数据等 |
| CodaLab | 多数为学术型的竞赛平台,包括一些学术会议的附赛 |
| 天池 | 比较有名,不作过多说明 |
| 同花顺算法平台 | 来源于真实场景业务问题,CV\NLP\语音都有涉及 |
| Kaggle | 比较有名,不作过多说明 |
| AIWIN | 一个比较小众的平台,涉及CV较多一些,每年有两次(春季赛|秋季赛) |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AI-Competition-Collections
Similar Open Source Tools
AI-Competition-Collections
AI-Competition-Collections is a repository that collects and curates various experiences and tips from AI competitions. It includes posts on competition experiences in computer vision, NLP, speech, and other AI-related fields. The repository aims to provide valuable insights and techniques for individuals participating in AI competitions, covering topics such as image classification, object detection, OCR, adversarial attacks, and more.
ZhiLight
ZhiLight is a highly optimized large language model (LLM) inference engine developed by Zhihu and ModelBest Inc. It accelerates the inference of models like Llama and its variants, especially on PCIe-based GPUs. ZhiLight offers significant performance advantages compared to mainstream open-source inference engines. It supports various features such as custom defined tensor and unified global memory management, optimized fused kernels, support for dynamic batch, flash attention prefill, prefix cache, and different quantization techniques like INT8, SmoothQuant, FP8, AWQ, and GPTQ. ZhiLight is compatible with OpenAI interface and provides high performance on mainstream NVIDIA GPUs with different model sizes and precisions.
END-TO-END-GENERATIVE-AI-PROJECTS
The 'END TO END GENERATIVE AI PROJECTS' repository is a collection of awesome industry projects utilizing Large Language Models (LLM) for various tasks such as chat applications with PDFs, image to speech generation, video transcribing and summarizing, resume tracking, text to SQL conversion, invoice extraction, medical chatbot, financial stock analysis, and more. The projects showcase the deployment of LLM models like Google Gemini Pro, HuggingFace Models, OpenAI GPT, and technologies such as Langchain, Streamlit, LLaMA2, LLaMAindex, and more. The repository aims to provide end-to-end solutions for different AI applications.

Prompt-Engineering-Holy-Grail
The Prompt Engineering Holy Grail repository is a curated resource for prompt engineering enthusiasts, providing essential resources, tools, templates, and best practices to support learning and working in prompt engineering. It covers a wide range of topics related to prompt engineering, from beginner fundamentals to advanced techniques, and includes sections on learning resources, online courses, books, prompt generation tools, prompt management platforms, prompt testing and experimentation, prompt crafting libraries, prompt libraries and datasets, prompt engineering communities, freelance and job opportunities, contributing guidelines, code of conduct, support for the project, and contact information.
AI0x0.com
AI 0x0 is a versatile AI query generation desktop floating assistant application that supports MacOS and Windows. It allows users to utilize AI capabilities in any desktop software to query and generate text, images, audio, and video data, helping them work more efficiently. The application features a dynamic desktop floating ball, floating dialogue bubbles, customizable presets, conversation bookmarking, preset packages, network acceleration, query mode, input mode, mouse navigation, deep customization of ChatGPT Next Web, support for full-format libraries, online search, voice broadcasting, voice recognition, voice assistant, application plugins, multi-model support, online text and image generation, image recognition, frosted glass interface, light and dark theme adaptation for each language model, and free access to all language models except Chat0x0 with a key.

Awesome-Knowledge-Distillation-of-LLMs
A collection of papers related to knowledge distillation of large language models (LLMs). The repository focuses on techniques to transfer advanced capabilities from proprietary LLMs to smaller models, compress open-source LLMs, and refine their performance. It covers various aspects of knowledge distillation, including algorithms, skill distillation, verticalization distillation in fields like law, medical & healthcare, finance, science, and miscellaneous domains. The repository provides a comprehensive overview of the research in the area of knowledge distillation of LLMs.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.

llms-from-scratch-cn
This repository provides a detailed tutorial on how to build your own large language model (LLM) from scratch. It includes all the code necessary to create a GPT-like LLM, covering the encoding, pre-training, and fine-tuning processes. The tutorial is written in a clear and concise style, with plenty of examples and illustrations to help you understand the concepts involved. It is suitable for developers and researchers with some programming experience who are interested in learning more about LLMs and how to build them.
ai-app
The 'ai-app' repository is a comprehensive collection of tools and resources related to artificial intelligence, focusing on topics such as server environment setup, PyCharm and Anaconda installation, large model deployment and training, Transformer principles, RAG technology, vector databases, AI image, voice, and music generation, and AI Agent frameworks. It also includes practical guides and tutorials on implementing various AI applications. The repository serves as a valuable resource for individuals interested in exploring different aspects of AI technology.
SpinQuant
SpinQuant is a tool designed for LLM quantization with learned rotations. It focuses on optimizing rotation matrices to enhance the performance of quantized models, narrowing the accuracy gap to full precision models. The tool implements rotation optimization and PTQ evaluation with optimized rotation, providing arguments for model name, batch sizes, quantization bits, and rotation options. SpinQuant is based on the findings that rotation helps in removing outliers and improving quantization, with specific enhancements achieved through learning rotation with Cayley optimization.
MindChat
MindChat is a psychological large language model designed to help individuals relieve psychological stress and solve mental confusion, ultimately improving mental health. It aims to provide a relaxed and open conversation environment for users to build trust and understanding. MindChat offers privacy, warmth, safety, timely, and convenient conversation settings to help users overcome difficulties and challenges, achieve self-growth, and development. The tool is suitable for both work and personal life scenarios, providing comprehensive psychological support and therapeutic assistance to users while strictly protecting user privacy. It combines psychological knowledge with artificial intelligence technology to contribute to a healthier, more inclusive, and equal society.
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.
Awesome-Jailbreak-on-LLMs
Awesome-Jailbreak-on-LLMs is a collection of state-of-the-art, novel, and exciting jailbreak methods on Large Language Models (LLMs). The repository contains papers, codes, datasets, evaluations, and analyses related to jailbreak attacks on LLMs. It serves as a comprehensive resource for researchers and practitioners interested in exploring various jailbreak techniques and defenses in the context of LLMs. Contributions such as additional jailbreak-related content, pull requests, and issue reports are welcome, and contributors are acknowledged. For any inquiries or issues, contact [email protected]. If you find this repository useful for your research or work, consider starring it to show appreciation.
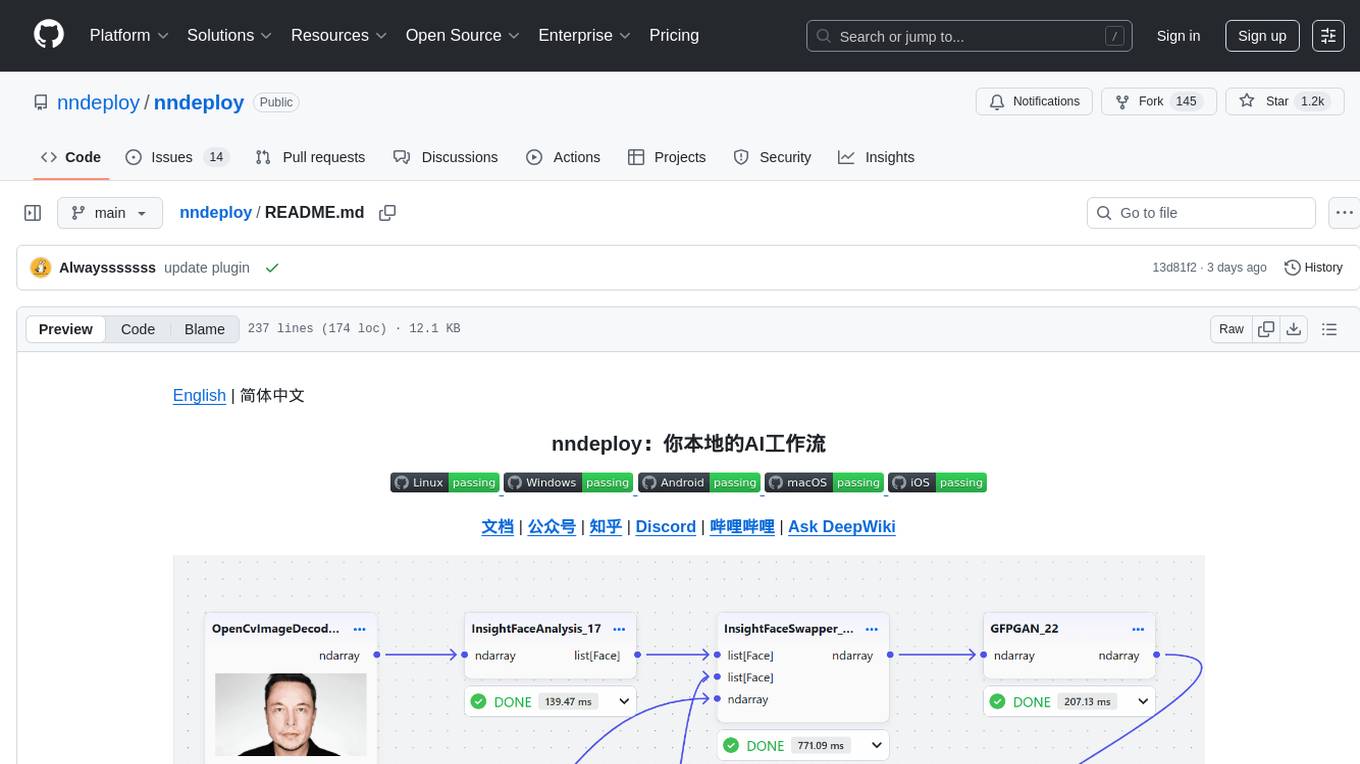
nndeploy
nndeploy is a tool that allows you to quickly build your visual AI workflow without the need for frontend technology. It provides ready-to-use algorithm nodes for non-AI programmers, including large language models, Stable Diffusion, object detection, image segmentation, etc. The workflow can be exported as a JSON configuration file, supporting Python/C++ API for direct loading and running, deployment on cloud servers, desktops, mobile devices, edge devices, and more. The framework includes mainstream high-performance inference engines and deep optimization strategies to help you transform your workflow into enterprise-level production applications.

Open-dLLM
Open-dLLM is the most open release of a diffusion-based large language model, providing pretraining, evaluation, inference, and checkpoints. It introduces Open-dCoder, the code-generation variant of Open-dLLM. The repo offers a complete stack for diffusion LLMs, enabling users to go from raw data to training, checkpoints, evaluation, and inference in one place. It includes pretraining pipeline with open datasets, inference scripts for easy sampling and generation, evaluation suite with various metrics, weights and checkpoints on Hugging Face, and transparent configs for full reproducibility.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.